







循环神经网络的参数可以通过梯度下降方法来进行学习。

循环神经网络中存在一个递归调用的函数 𝑓(⋅),因此其计算参数梯度的方式和前馈神经网络不太相同.在循环神经网络中主要有两种计算梯度的方式:
随时间反向传播
(
BPTT
)
算法和
实时循环学习
(
RTRL
)
算法
.
随时间反向传播算法
随时间反向传播
(
BackPropagation Through Time
,
BPTT
)
算法的主要思想是通过类似前馈神经网络的错误反向传播算法
来计算梯度
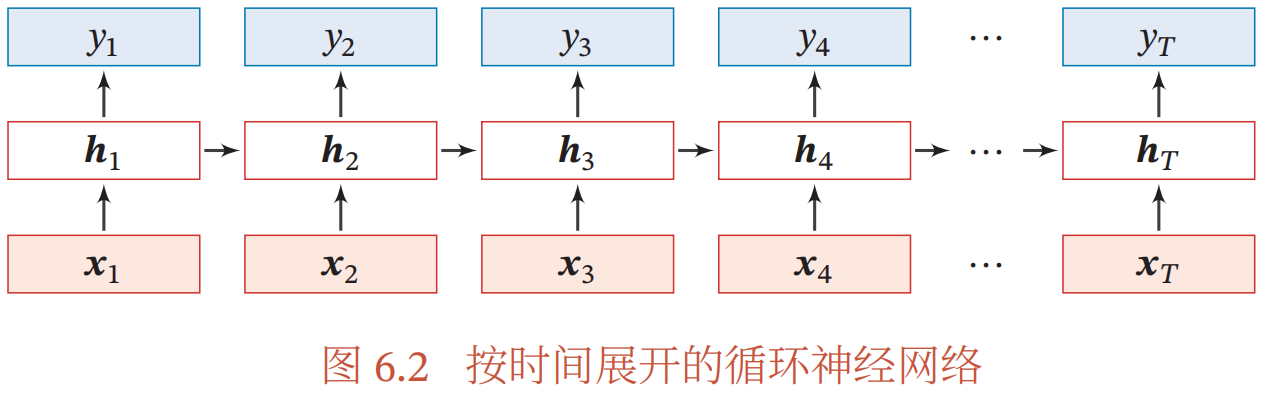
.BPTT算法将循环神经网络看作一个展开的多层前馈网络
,
其中
“
每一层
”
对应循环网络中的“
每个时刻
”(
见图
6.2
).
这样
,
循环神经网络就可以按照前馈网络中的反向传播算法计算参数梯度.
在
“
展开
”
的前馈网络中
,
所有层的参数是共享的,
因此参数的真实梯度是所有 “展开层” 的参数梯度之和。


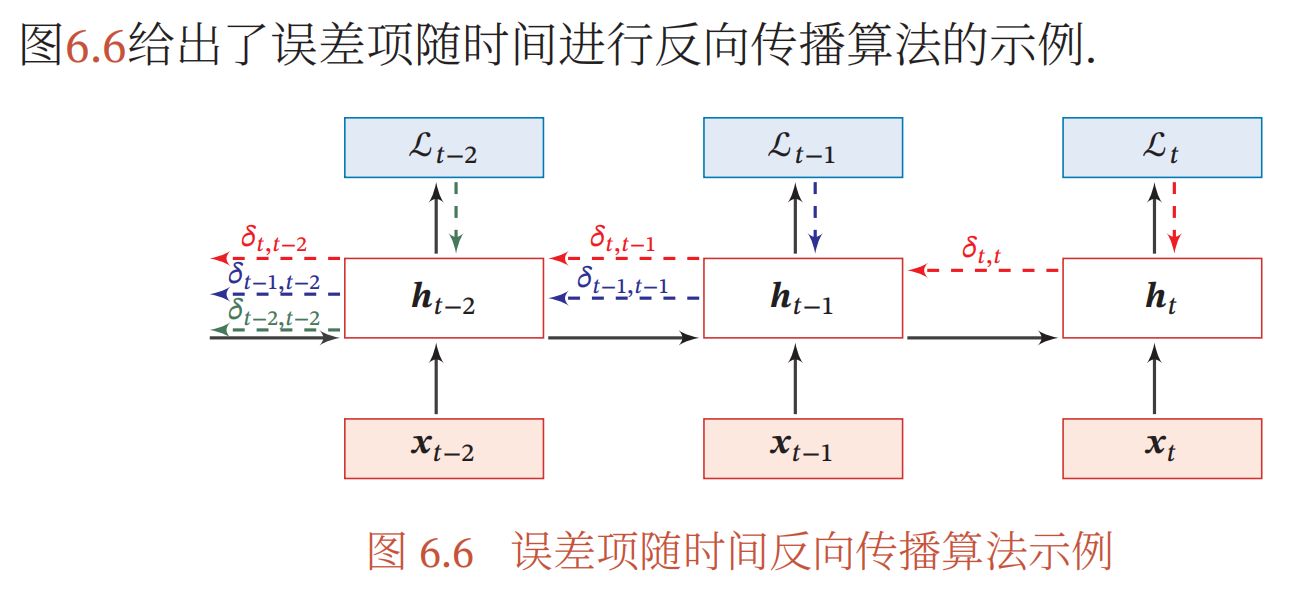

计算复杂度
在BPTT
算法中
,
参数的梯度需要在一个完整的
“
前向
”
计算和
“
反向”
计算后才能得到并进行参数更新
.
实时循环学习算法
与反向传播的 BPTT
算法不同的是
,
实时循环学习
(
Real-Time Recurrent Learning,
RTRL
)
是通过前向传播的方式来计算梯度。


两种算法比较
RTRL算法和BPTT算法都是基于梯度下降的算法,分别通过前 向模式和反向模式应用链式法则来计算梯度.
在循环神经网络中
,
一般网络输出维度远低于输入维度,
因此
BPTT
算法的计算量会更小
,
但是
BPTT
算法需要保 存所有时刻的中间梯度,
空间复杂度较高
.
RTRL
算法不需要梯度回传
,
因此非常适合用于需要在线学习或无限序列的任务中。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









