







集成学习(Ensemble Learning)是一种机器学习的方法,通过结合多个基本模型的预测结果来进行决策或预测。集成学习的目标是通过组合多个模型的优势,并弥补单个模型的不足,从而提高整体性能。
集成学习的主要策略
在集成学习中,有两个主要的策略:平均法和投票法。
- 平均法:平均法通过对多个模型的预测结果进行平均或加权平均,得到最终的预测结果。例如,对于回归问题,可以计算多个模型的预测值的平均值作为最终的预测结果;对于分类问题,可以采用投票法来进行决策。
- 投票法:投票法通过对多个模型的预测结果进行投票,选择得票最多的类别作为最终的预测结果。例如,对于分类问题,可以将每个模型的预测结果看作一个投票,并选择得票最多的类别作为最终的分类结果。
集成学习的优势
集成学习的优势在于:
- 提高泛化能力:集成学习能够通过结合多个模型的预测结果,减少单个模型的偏见和方差,从而提高整体的泛化能力,降低过拟合的风险。
- 提高预测准确性:通过集成多个模型,可以利用各自模型的优势,弥补单个模型的不足,从而提高最终的预测准确性。
- 增加稳定性:集成学习能够降低模型的不确定性,提高系统的稳定性和鲁棒性,对异常数据或噪声具有较好的抗干扰能力。
集成学习分类
目前的集成学习方法分为两类(Boosting类方法、Bagging类方法):
(1)个体学习器间存在强依赖关系、必须串行生成的序列化方法,代表算法Boosting类方法;
(2)个体学习器间不存在强依赖关系、可同时生成的并行化方法,代表算法Bagging类方法;bagging类方法又可分为:bagging、随机森林等。 boosting类方法又可分为:AdaBoost、GBDT等。
Bagging类方法
个体学习器间不存在强依赖关系、可同时生成的并行化方法
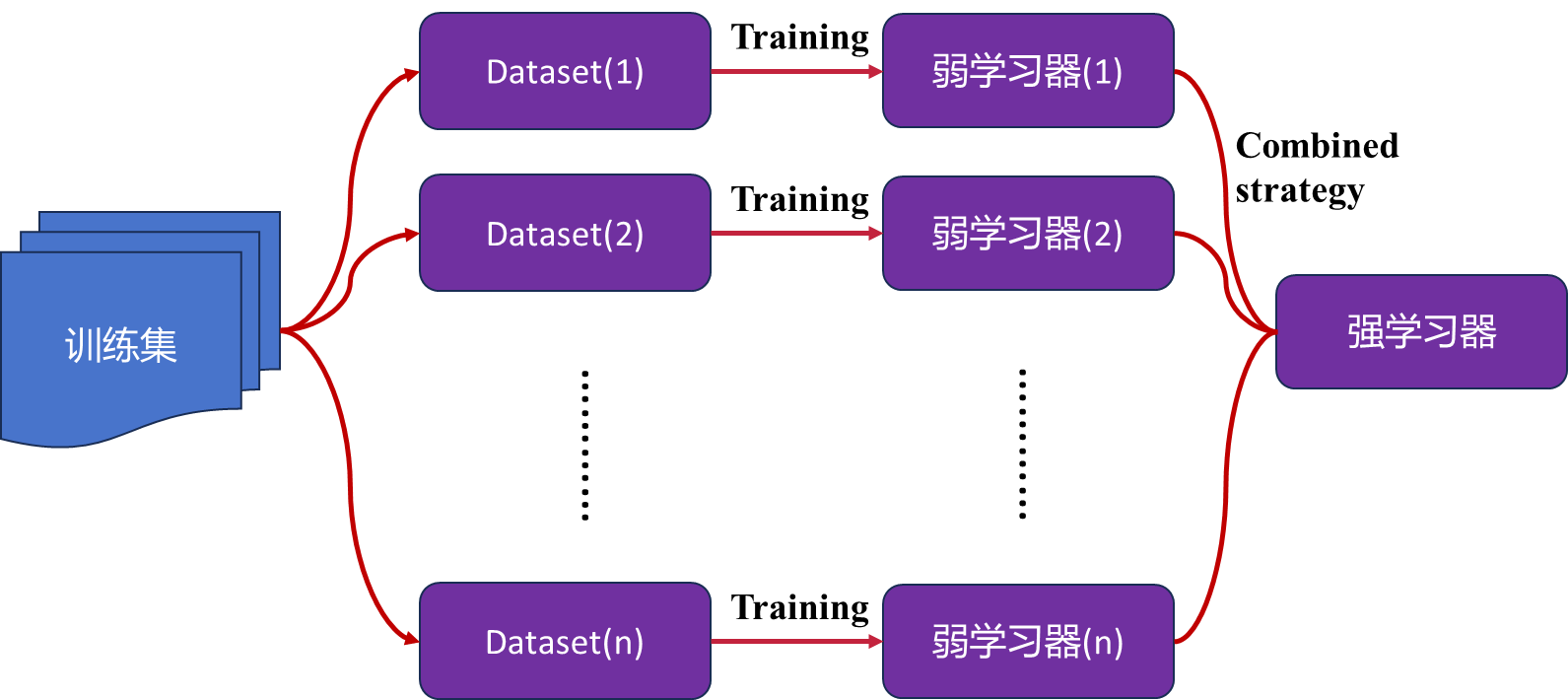
主要代表方法
Bagging
定义:是通过不同模型的训练数据集的独立性来提高不同模型之间的独立性.我们在原始训练集上进行有放回的随机采样,得到𝑀 个比较小的训练集并训练𝑀 个模型,然后通过投票的方法进行模型集成。
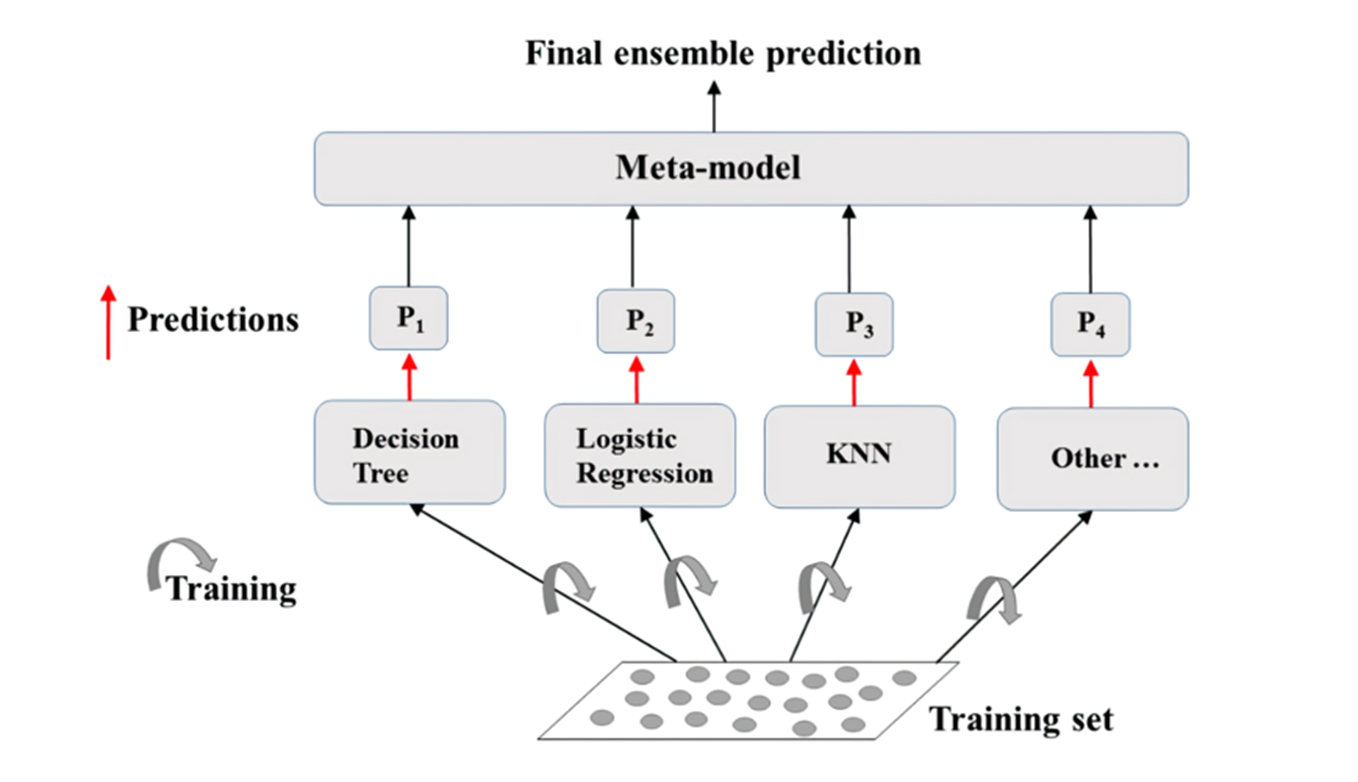
Bagging的步骤如下:
- 自助采样:从原始训练集中通过有放回地随机采样生成多个不同的采样集(有些样本可能会被重复采样,有些样本可能被遗漏),每个采样集的大小与原始训练集相同。
- 基本模型训练:使用每个采样集独立地训练一个基本模型,可以使用相同的学习算法或不同的学习算法。每个模型都是在略有差异的数据子集上进行训练的。
- 预测整合:对于回归问题,通常将每个基本模型的预测结果进行平均,得到最终的预测值;对于分类问题,则进行投票,选择得票最多的类别作为最终的预测结果。
Bagging的优势在于:
- 减小方差:由于每个基本模型都是在不同的数据子集上训练的,因此它们之间具有一定的差异性。通过平均或投票整合多个模型的结果,可以减小模型预测的方差,提高整体的泛化能力。
- 抗过拟合:自助采样会引入一些随机性和变化性,从而减少模型对训练数据的过度拟合。通过构建多个模型并平均它们的预测结果,可以降低过拟合风险。
- 并行化处理:每个基本模型的训练是相互独立的,因此可以并行地进行训练和预测,提高训练效率。
需要注意的是,Bagging并不能改善模型的偏差(bias),因此如果基本模型本身存在很大的偏差,Bagging可能无法有效提升性能。此外,Bagging方法可能增加模型的复杂度和计算资源消耗,因为需要构建多个模型并进行整合。因此,在使用Bagging时需要权衡集成效果和计算成本之间的平衡。
随机森林RF
定义:在Bagging的基础上再引入了随机特征,进一步提高每个基模型之间的独立性.在随机森林中,每个基模型都是一棵决策树。
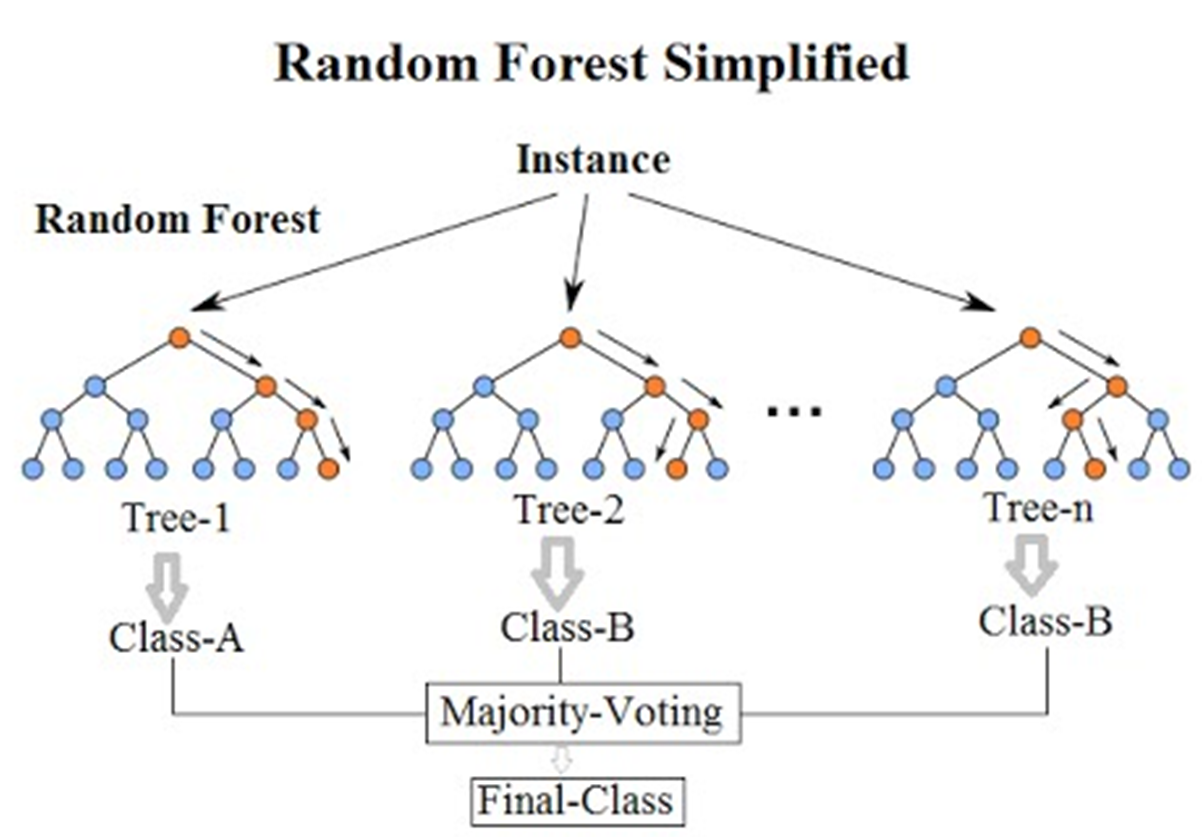
随机森林的主要步骤如下:
- 随机采样:从原始训练集中通过有放回地随机采样得到多个不同的训练子集。每个子集的大小与原始训练集相同,但是可能包含一些重复样本和遗漏样本。
- 决策树训练:使用每个训练子集独立地训练一个决策树模型。在构建决策树时,对于每个节点的划分,随机选择一部分特征子集作为候选划分特征,从中选择最优特征进行划分。这样可以增加决策树之间的差异性,提高整体集成模型的多样性。
- 预测整合:对于回归问题,随机森林通过对多个决策树的预测结果进行平均,得到最终的预测值;对于分类问题,则进行投票,选择得票最多的类别作为最终的预测结果。
随机森林的优势在于:
- 高性能:随机森林在处理大规模数据时具有较好的效率和性能。通过并行训练多个决策树,可以有效利用计算资源。
- 鲁棒性:随机森林对于缺失值和异常值具有一定的鲁棒性,它可以处理不完整或有噪声的数据集,并且不容易过拟合。
- 变量重要性评估:通过随机森林,可以对特征的重要性进行评估,帮助选择最相关的特征,并进行特征选择。
需要注意的是,随机森林的参数设置也会影响模型的性能。例如,决策树中的候选划分特征数目、每棵树的最大深度以及随机采样的次数等。合理地选择这些参数可以进一步提高随机森林的性能与泛化能力。
总之,随机森林是一种强大的集成学习方法,可应用于回归、分类和特征选择等任务,且在许多实际问题中取得了优异的表现。
Boosting类方法
个体学习器间存在强依赖关系、必须串行生成的序列化方法
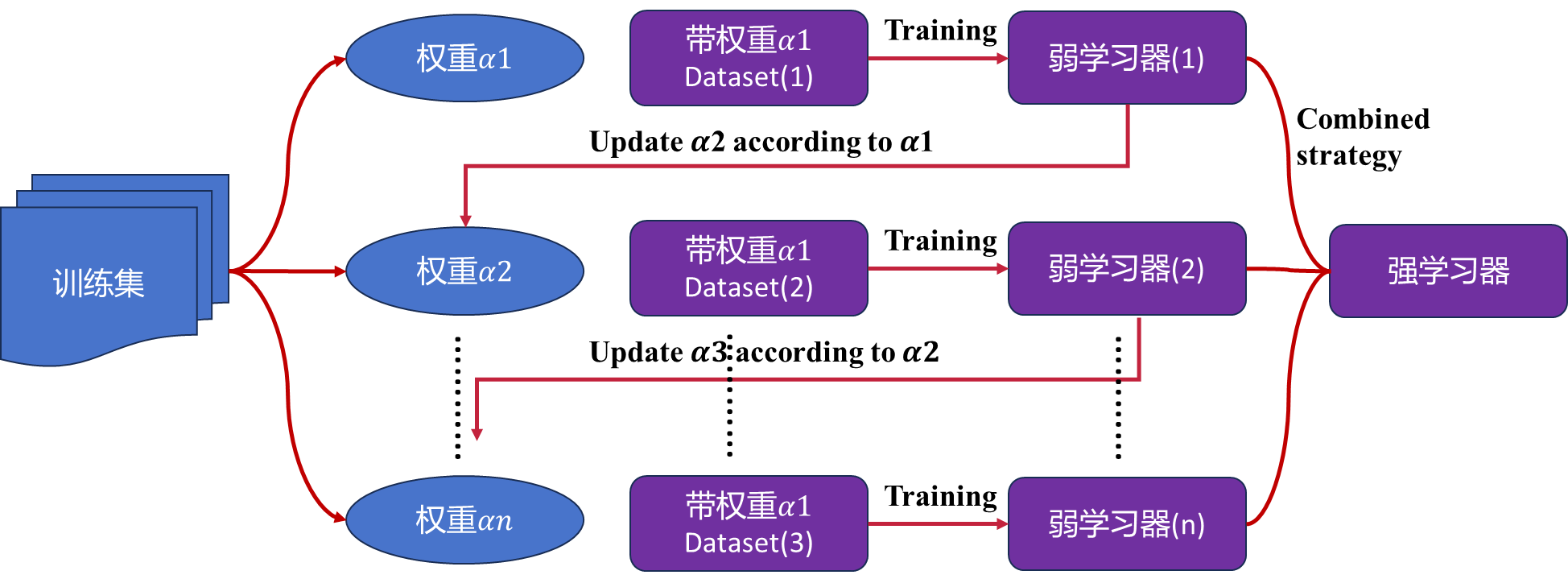
Boosting 类方法是一种集成学习的方法。它通过迭代地训练基本模型,并加权整合它们的预测结果来提高整体模型的性能。相比于 Bagging 类方法, Boosting 方法更注重弱分类器之间的关联。
Boosting 的主要思想是按顺序构建多个基本模型,在每次迭代中关注前一个模型“错分”的样本,尝试对其进行更好的分类。通过不断调整样本权重,让后续模型着重处理前一个模型处理错误的样本。最终,将所有基本模型的预测结果进行加权平均得到最终的预测结果。
Boosting 的步骤如下:
- 初始化样本权重:将所有样本的权重初始化为相等值。
- 基本模型训练:迭代训练多个基本模型,每个模型都在上一个模型分类错误的样本上进行训练。
- 样本权重更新:根据每个基本模型对样本的分类结果,调整每个样本的权重。被错误分类的样本权重会被放大,而被正确分类的样本权重则会缩小。
- 集成模型整合:将所有基本模型的预测结果进行加权平均,得到最终的预测结果。
常见的 Boosting 方法有 AdaBoost(Adaptive Boosting)、GBDT(Gradient Boosting Decision Tree)等。AdaBoost 是 Boosting 方法的经典算法之一,它通过调整样本权重来训练基本模型的分类器。GBDT 是 Boosting 方法的另一种形式,它通过训练多个决策树并加权组合它们的预测结果来提高模型性能。
Boosting 的优势在于:
- 高性能: Boosting 可以构建具有很强泛化性能的集成模型,对于各种各样的机器学习问题都具有较好的适应性和表现。
- 改善偏差: Boosting 能够有效地处理高偏差问题。通过迭代地训练基本模型,并集成它们的结果,可以不断减少模型的偏差,从而提高模型的预测准确率。
- 可解释性: Boosting 中的基本模型通常是简单的分类器或回归器,这使得 Boosting 方法的结果更加可解释。
需要注意的是,Boosting 方法对数据噪声和离群值比较敏感,因此在使用时需要进行数据清洗和特征选择等预处理。同时,由于 Boosting 方法本身比较复杂,对于计算资源要求高,需要一定的时间和计算成本。
主要代表方法
AdaBoost
AdaBoost(Adaptive Boosting)是一种著名的 Boosting 方法,旨在提高分类器的性能。它通过迭代地训练一系列弱分类器,并根据它们的分类错误情况动态调整样本权重,最终将这些弱分类器加权组合成一个强分类器。
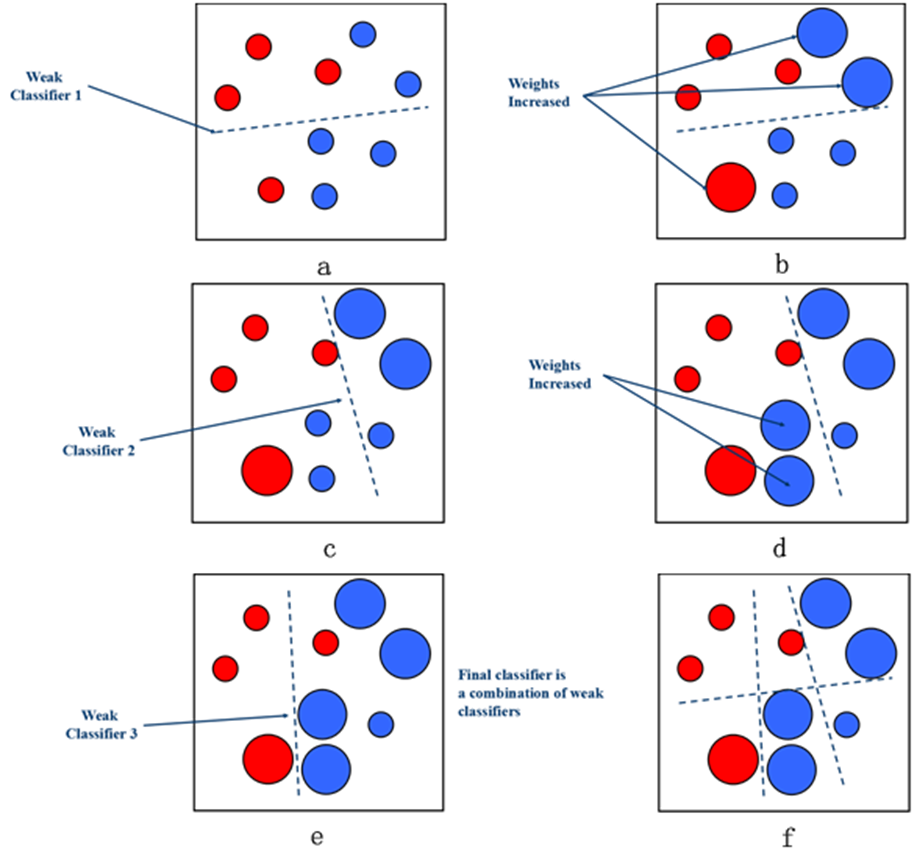
AdaBoost 的主要步骤如下:
- 初始化样本权重:将所有样本的权重初始化为相等值。
- 基本分类器训练:在每次迭代中,使用当前样本权重训练一个弱分类器(例如决策树、神经网络等)。
- 分类器权重计算:根据当前分类器在训练集上的分类错误率计算其对应的权重。
- 样本权重更新:根据分类器的权重和分类结果,调整样本的权重。被错误分类的样本权重会增加,而被正确分类的样本权重会减小。
- 终止条件判断:如果达到预设的迭代次数或分类错误率已满足要求,则停止迭代;否则返回第2步。
- 强分类器整合:将每个弱分类器的预测结果进行加权组合,得到最终的预测结果。
AdaBoost 的特点包括:
- 自适应调整:AdaBoost 根据每个基分类器的表现自适应地调整样本权重,使其更加关注容易被错分的样本。
- 集成模型权重:通过对每个弱分类器的分类错误率计算其权重,能有效地决定其在最终结果中的贡献程度。
- 顺序训练:AdaBoost 每次迭代都在前一轮的错误样本上进行训练,以此增强模型对错误样本的学习能力。
AdaBoost 在实际应用中表现出了良好的性能和泛化能力。然而,它也存在一些限制,比如对离群值、噪声和标签错误比较敏感,需要进行数据预处理和异常值处理。此外,AdaBoost 的计算复杂度较高,因为需要训练多个基本分类器并动态调整样本权重。
总体而言,AdaBoost 是一种强大的集成学习方法,广泛应用于分类问题,并且对于处理二分类和多分类任务都具有很好的效果。
GBDT
GBDT(Gradient Boosting Decision Tree)是一种基于梯度提升的集成学习方法,它通过训练多个决策树并加权组合它们的预测结果来提高模型性能。
GBDT 的主要步骤如下:
- 初始化模型:将整体模型的初始预测值设为一个常数,通常是目标变量的均值。
- 迭代训练决策树:在每次迭代中,训练一个新的决策树来拟合上一轮模型的残差(实际值与当前预测值之间的差异)。
- 更新模型预测:将新训练的决策树的预测结果乘以一个较小的学习率,并将其加入到总体模型的预测值中。
- 终止条件判断:重复进行第2步和第3步,直到达到预设的迭代次数或满足其他终止条件。
GBDT 的特点包括:
- 梯度提升:GBDT 通过迭代地拟合上一轮模型的残差来逐步改进模型的预测效果,这是一种贪心算法。
- 决策树集成:GBDT 中使用的基本模型是决策树,每次迭代都会训练一个新的决策树来捕捉模型的残差信息。
- 学习率控制:通过引入学习率,可以控制每个决策树对最终模型的贡献程度,避免过拟合。
GBDT 在实际应用中具有广泛的适用性和优势:
- 高预测性能:GBDT 能够很好地拟合复杂的非线性关系,并在各种类型的数据集上取得较高的预测准确率。
- 特征自动选择:GBDT 可以通过决策树的特性自动选择重要的特征,避免了手动特征工程的繁琐过程。
- 处理异构数据:GBDT 能够有效地处理混合类型的数据,包括连续型、离散型和类别型特征。
- 处理缺失值:GBDT 能够处理部分特征缺失的情况,不需要对缺失值进行额外的处理。
需要注意的是,由于 GBDT 是一种串行算法,不能进行并行计算,因此在大规模数据集上的训练速度相对较慢。此外,GBDT 对异常值和噪声比较敏感,可能会导致过拟合现象,因此在使用时需要进行数据清洗和调参等操作。
总的来说,GBDT 是一种强大而广泛应用的集成学习方法,适用于回归和分类问题,并在业界和学术界都有广泛的应用。
XGBoost
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升决策树的集成学习算法,它是GBDT的一种改进和扩展版本。XGBoost 在性能和扩展性上进行了优化,被广泛应用于机器学习和数据挖掘任务中。
XGBoost 在GBDT的基础上引入了以下几个创新点:
- 正则化:引入了正则化项,控制模型复杂度,减少过拟合风险。
- 分裂节点的方法:采用近似贪心算法,通过使用Hessian矩阵的二阶导数信息,提高了分裂节点的效率和准确性。
- 优化目标函数:使用了更加灵活的目标函数,可以根据具体问题调整代价函数,适应不同的任务需求。
- 并行化处理:支持多线程并行计算,加快了模型训练的速度。
XGBoost的特点和优势包括:
- 高效性能:XGBoost在内部实现上进行了许多优化,使用了稀疏特征存储、缓存块和并行计算等技术,使得其在大规模数据集上的训练速度更快。
- 准确性:XGBoost通过使用正则化和近似贪心算法等技术,能够更好地拟合复杂的非线性关系,提供更准确的预测结果。
- 可解释性:XGBoost能够输出特征的重要性信息,帮助用户进行特征选择和模型解释。
- 支持多种任务:XGBoost不仅适用于回归和分类问题,还可以处理排序、排名、推荐系统等其他类型的机器学习任务。
总之,XGBoost是一种强大而灵活的梯度提升算法,具有优秀的性能和广泛的应用领域。无论在竞赛中还是实际应用中,XGBoost都展现出了卓越的效果,并成为了机器学习领域中最受欢迎的算法之一。














 1497
1497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









