







FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
Abstract
- 输入:音频信号,目标短视频剪辑
- 输出:具有与输入音频信号同步的自然嘴唇运动、头部姿势和眨眼的目标面部照片逼真视频
Introduction
- 动态说话面部所包含的信息:
- 显式属性:需要与输入音频同步的属性,如与听觉语音信号有很强相关性的嘴唇运动
- 隐式属性:与语音信号相关性较弱的属性,如与说话的语境和个性化的说话方式都有关的头部运动,主要由个人健康状况和外界刺激决定的眨眼次数
- 困难:
- 显式属性和隐式属性是如何潜在地相互影响的?
- 如何对既依赖语音信号又依赖语音语境信息和个性化说话风格的隐式属性,如头部姿势和眨眼等进行建模?
- 提出FACLAL框架:

整体框架由FACIAL(用于编码联合显隐属性的面部生成对抗网络)和渲染视频网络(用于合成具有同步唇动、自然头部姿势和逼真眨眼的输出说话面部视频)组成。在给定输入音频的情况下,提出的FACIAL-GAN算法旨在生成同时具有时间相关性和局部语音特征的显式属性(表情)和隐式属性(眨眼、头部姿势)。对参考视频进行3D人脸重构,获得人脸的身份、纹理、光线参数。将FACIAL-GAN得到的头部姿势和表情参数以及重构所得参数输入GPU渲染器得到渲染后的面部。部分敏感编码以眨眼动作单元为输入,获得眼睛注意映射。二者被联合起来,以提供给渲染视频网络。 - 贡献:
- 我们提出了一个联合显隐属性学习框架,用于合成具有音频同步的嘴唇运动、个性化和自然的头部运动和逼真的眨眼动作的照片-逼真的谈话面部视频。
- 设计了一个FACIAL-GAN模块,将上下文信息与每个帧的语音信息进行编码,以建模合成自然头部动作所需的隐式属性。
- 将由FACIAL-GAN生成的眨眼AU嵌入到渲染人脸的眼-注意力图中,实现了渲染-视频模块生成的视频中逼真的眨眼动作。
Approach
问题公式化
输入音频
A
A
A和参考视频
V
V
V,输出语音视频
S
S
S
{
F
l
i
p
,
M
p
o
s
e
,
M
e
y
e
}
=
G
(
E
(
A
)
)
,
S
=
R
(
F
l
i
p
,
M
p
o
s
e
,
ε
⊙
,
M
e
y
e
,
V
)
(2)
\{F_{lip},M_{pose},M_{eye}\}=G(E(A)),\\ S=R(F_{lip},M_{pose},\varepsilon\odot,M_{eye},V) \tag{2}
{Flip,Mpose,Meye}=G(E(A)),S=R(Flip,Mpose,ε⊙,Meye,V)(2)
其中
F
l
i
p
F_{lip}
Flip表示由对抗性生成器G合成的显式特征,E表示音频特征提取网络,R表示将合成特征转换为输出视频的渲染网络,
M
p
o
s
e
M_{pose}
Mpose表示头部姿势,
M
e
y
e
M_{eye}
Meye表示眨眼,
ε
\varepsilon
ε表示眼部注意映射。
FACIAL-GAN
目标:
- 生成与每一帧语音特征相对应的显式表达式
- 将上下文信息(即时间相关性)嵌入到网络中进行隐性属性学习

提出的FACIAL-GAN由三个基本部分组成:建立上下文关系的时间相关生成器
G
t
e
m
G^{tem}
Gtem和提取每一帧特征的局部语音生成器
G
l
o
c
G^{loc}
Gloc以及判别器网络
D
f
D^f
Df(见生成对抗网络(GAN)教程 - 多图详解,深度学习:GAN 对抗网络原理详细解析(零基础必看),图解 生成对抗网络GAN 原理 超详解)。如上图所示,输入音频A通过T帧滑动窗口采样,并用DeepSpeech(音频转文本的命令或库)预存,生成特征
A
∈
R
29
×
T
A∈R^{29×T}
A∈R29×T。设
f
f
f表示面部表情参数,
p
p
p表示头部姿势特征,
e
e
e表示眨眼AU估计,分别用
f
t
f_t
ft、
p
t
p_t
pt和
e
t
e_t
et表示第t帧的特征。
- 时间相关生成器
G
t
e
m
G^{tem}
Gtem
- 目的:提取整个输入序列的时间相关性
- 思想:将T帧音频序列A输入上下文编码器生成全局特征 z z z,对 z z z进行分割,提取第t帧对应的特征 z t z_t zt,引入初始状态以保证生成序列之间的时间连续性。
- 局部语音生成器
G
l
o
c
G^{loc}
Gloc:
- 目的:生成第t帧的局部特征 c t c_t ct
- 思想:以第t帧为例, G l o c G^{loc} Gloc取音频特征 a t a_t at = a[t−8:t + 8]作为输入输出局部特征 c t c_t ct。
- FACIAL-GAN的编码过程:
z t = S ( G t e m ( E ( A ) ∣ s ) , t ) , c t = G l o c ( S ( E ( A ) , t ) ) , [ f t ^ , p t ^ , e t ^ ] = F C ( z t ⊕ c t ) (3) z_t=S(G^{tem}(E(A)|s),t),\\ c_t=G^{loc}(S(E(A),t)),\\ [\hat{f_t},\hat{p_t},\hat{e_t}]=FC(z_t \oplus c_t) \tag{3} zt=S(Gtem(E(A)∣s),t),ct=Gloc(S(E(A),t)),[ft^,pt^,et^]=FC(zt⊕ct)(3)
全连接层FC将 z t z_t zt和 c t c_t ct映射到预测的参数 f t ^ , p t ^ , e t ^ ∈ R 71 \hat{f_t},\hat{p_t},\hat{e_t}\in R^{71} ft^,pt^,et^∈R71,函数S(X, t)表示对特征X的第t个特征块进行分割和提取,⊕为特征拼接操作,E为音频特征提取。 - 学习目标:
-
G
t
e
m
G^{tem}
Gtem和
G
l
o
c
G^{loc}
Gloc的损失函数:
L R e g = ω 1 L e x p + ω 2 L p o s e + ω 3 L e y e + ω 4 L s (4) L_{Reg}=\omega_1 L_{exp}+\omega_2L_{pose}+\omega_3L_{eye}+\omega_4L_s \tag{4} LReg=ω1Lexp+ω2Lpose+ω3Leye+ω4Ls(4)- 其中
ω
1
、
ω
2
、
ω
3
、
ω
4
ω_1、ω_2、ω_3、ω_4
ω1、ω2、ω3、ω4为平衡权值,
L
s
L_s
Ls为初始状态值的L1范数损失,保证了生成的滑动窗口序列之间的连续性:
L s = ∣ ∣ f 0 − f 0 ^ ∣ ∣ 1 + ∣ ∣ p 0 − p 0 ^ ∣ ∣ 1 + ∣ ∣ e 0 − e 0 ^ ∣ ∣ 1 (5) L_s=||f_0-\hat{f_0}||_1+||p_0-\hat{p_0}||_1+||e_0-\hat{e_0}||_1 \tag{5} Ls=∣∣f0−f0^∣∣1+∣∣p0−p0^∣∣1+∣∣e0−e0^∣∣1(5) -
L
e
x
p
、
L
p
o
s
e
和
L
e
y
e
L_{exp}、L_{pose}和L_{eye}
Lexp、Lpose和Leye分别是面部表情、头部姿势和眨眼AU的L2范数损失。引入了运动损耗U保证帧间的连续性:
L e x p = ∑ t = 0 T − 1 v ( f t , f t ^ ) + ω 5 ∑ t = 1 T = 1 u ( f t − 1 , f t , f t − 1 ^ , f t ^ ) , L p o s e = ∑ t = 0 T − 1 v ( p t , p t ^ ) + ω 5 ∑ t = 1 T = 1 u ( p t − 1 , p t , p t − 1 ^ , p t ^ ) , L e y e = ∑ t = 0 T − 1 v ( e t , e t ^ ) + ω 5 ∑ t = 1 T = 1 u ( e t − 1 , e t , e t − 1 ^ , e t ^ ) v ( x t , x t ^ ) = ∣ ∣ x t − x t ^ ∣ ∣ 2 2 u ( x t − 1 , x t , x t − 1 ^ , x t ^ ) = ∣ ∣ x t − x t − 1 − ( x t ^ − x t − 1 ^ ) ∣ ∣ 2 2 (6) L_{exp}=\sum_{t=0}^{T-1}v(f_t,\hat{f_t})+\omega_5\sum_{t=1}^{T=1}u(f_{t-1},f_t,\hat{f_{t-1}},\hat{f_t}),\\ L_{pose}=\sum_{t=0}^{T-1}v(p_t,\hat{p_t})+\omega_5\sum_{t=1}^{T=1}u(p_{t-1},p_t,\hat{p_{t-1}},\hat{p_t}),\\ L_{eye}=\sum_{t=0}^{T-1}v(e_t,\hat{e_t})+\omega_5\sum_{t=1}^{T=1}u(e_{t-1},e_t,\hat{e_{t-1}},\hat{e_t}) \\ v(x_t,\hat{x_t})=||x_t-\hat{x_t}||_2^2 \\ u(x_{t-1},x_t,\hat{x_{t-1}},\hat{x_t})=||x_t-x_{t-1}-(\hat{x_t}-\hat{x_{t-1}})||_2^2 \tag{6} Lexp=t=0∑T−1v(ft,ft^)+ω5t=1∑T=1u(ft−1,ft,ft−1^,ft^),Lpose=t=0∑T−1v(pt,pt^)+ω5t=1∑T=1u(pt−1,pt,pt−1^,pt^),Leye=t=0∑T−1v(et,et^)+ω5t=1∑T=1u(et−1,et,et−1^,et^)v(xt,xt^)=∣∣xt−xt^∣∣22u(xt−1,xt,xt−1^,xt^)=∣∣xt−xt−1−(xt^−xt−1^)∣∣22(6)
- 其中
ω
1
、
ω
2
、
ω
3
、
ω
4
ω_1、ω_2、ω_3、ω_4
ω1、ω2、ω3、ω4为平衡权值,
L
s
L_s
Ls为初始状态值的L1范数损失,保证了生成的滑动窗口序列之间的连续性:
- 判别器
D
f
D_f
Df的损失定义为:
L F − G A N = a r g m i n G f m a x D f E f , p , e [ l o g D f ( f , p , e ) ] + E a , s [ l o g ( 1 − D f ( G f ( a , s ) ) ] (7) L_{F-GAN}=arg \quad min_{G^f}max_{D^f}E_{f,p,e}[logD^f(f,p,e)]+E_{a,s}[log(1-D^f(G^f(a,s))] \tag{7} LF−GAN=argminGfmaxDfEf,p,e[logDf(f,p,e)]+Ea,s[log(1−Df(Gf(a,s))](7)
其中生成器 G f G^f Gf由两个子生成器 G t e m G^{tem} Gtem和 G l o c G^{loc} Gloc组成,使该目标函数最小化,而判别器 D f D^f Df优化为最大化 - 总体损失函数定义为:
L f a c i a l = ω 6 L F − G A N + L R e g (8) L_{facial} = ω_6L_{F-GAN} + L_{Reg} \tag{8} Lfacial=ω6LF−GAN+LReg(8)
-
G
t
e
m
G^{tem}
Gtem和
G
l
o
c
G^{loc}
Gloc的损失函数:
Implicit Part-Sensitive Encoding
首先在3D模型中标记出眼睛区域的顶点。从3D变形模型(3DMM)的平均面几何中识别顶点,其标准如下:
(
v
x
−
c
e
n
t
e
r
x
)
2
/
4
+
(
v
y
−
c
e
n
t
e
r
y
)
2
<
t
h
(9)
(v_x − center_x)^2/4 + (v_y − center_y)^2 < th \tag{9}
(vx−centerx)2/4+(vy−centery)2<th(9)
x,y表示坐标,v是顶点,center是每个眼睛的地标中心点,阈值th调节眼睛区域的大小。在三维人脸渲染过程中,先对标记区域的相关像素进行定位,生成人脸图像的眼睛注意图,再将归一化眨眼值应用到眼睛注意图中的像素上。
Rendering-to-Video Network
首先将渲染图像与眼睛注意图结合,生成大小为W × H × 4的训练输入数据 I ^ \hat I I^(渲染图像为3通道,注意图为1通道)。为了确保时间一致性,使用一个大小为 2 N w 2N_w 2Nw的窗口,当前帧位于窗口的中心。渲染到视频网络由生成器 G r G^r Gr和多尺度判别器 D r = ( D 1 r , D 2 r , D 3 r ) D^r = (D^r_1, D^r_2, D^r_3) Dr=(D1r,D2r,D3r)组成,它们以对抗方式交替优化。
- 生成器
G
r
G^r
Gr:
- 输入:堆叠张量 X t = { I ^ t } t − N ω t + N ω X_t = \{\hat I_t\}^{t+N_\omega}_{t−N_\omega} Xt={I^t}t−Nωt+Nω,大小为 W × H × 8 N ω W × H × 8N_\omega W×H×8Nω
- 输出:目标人物的真实感图像 G r ( X t ) G^r(X_t) Gr(Xt)。
- 条件判别器
D
r
D^r
Dr:
- 输入:堆叠张量 X t X_t Xt和一个检查帧(实像 I I I或生成的图像 G r ( X t ) G^r(X_t) Gr(Xt))为输入
- 输出:判别检查帧是否为实像。
- 损失函数:
L r e n d e r = ∑ D i r ∈ D r ( L R − G A N ( G r , D i r ) + λ 1 L F M ( G r , D i r ) ) + λ 2 L V G G ( G r ( X t ) , I ) + λ 3 L 1 ( G r ( X t ) , I ) (10) L_{render}=\sum_{D_i^r\in D^r}(L_{R-GAN}(G^r,D_i^r)+\lambda_1L_{FM}(G^r,D_i^r))+\lambda_2L_{VGG}(G^r(X_t),I)+\lambda_3L_1(G^r(X_t),I) \tag{10} Lrender=Dir∈Dr∑(LR−GAN(Gr,Dir)+λ1LFM(Gr,Dir))+λ2LVGG(Gr(Xt),I)+λ3L1(Gr(Xt),I)(10)
其中 L R − G A N ( G r , D r ) L_{R−GAN} (G^r, D^r) LR−GAN(Gr,Dr)为GAN对抗性损失, L F M ( G r , D r ) L_{FM}(G^r, D^r) LFM(Gr,Dr)表示判别器特征匹配损失, L V G G ( G r , I ) L_{VGG}(G^r, I) LVGG(Gr,I)为语义级别相似的VGG感知损失, L 1 ( G r , I ) L_1(G^r, I) L1(Gr,I)为绝对像素错误损失。 - 通过求解典型的min-max优化可以得到最优网络参数:
G r ∗ = a r g m i n G r m a x D r L r e n d e r ( G r , D r ) (11) G^{r*}=arg \quad min_{G^r}max_{D^r}L_{render}(G^r,D^r) \tag{11} Gr∗=argminGrmaxDrLrender(Gr,Dr)(11)
Dataset Collection
- 采用《 3d talking face with personalized pose dynamics》的说话头数据集
- 使用DeepSpeech提取语音特征
- 采用OpenFace来生成每一帧视频的面部参数
- 由一个具有N个顶点的模板三角形网格和一个定义了人脸几何形状 S ∈ R 3 N S∈R^{3N} S∈R3N和纹理 T ∈ R 3 N T∈R^{3N} T∈R3N的仿射模型组成的3DMM生成参数化人脸模型
- 按5:1:4划分训练集-验证集-测试集
Experiments

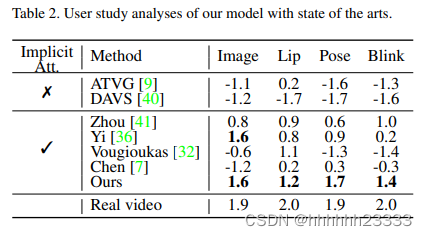
Discussion and Future Work
- 解决了显式属性(表情)和部分隐式属性(头部姿势、眨眼)的学习
- 其它隐式属性未解决,如注视动作、肢体和手势、微表情等















 1334
1334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









