







informer模型架构解释
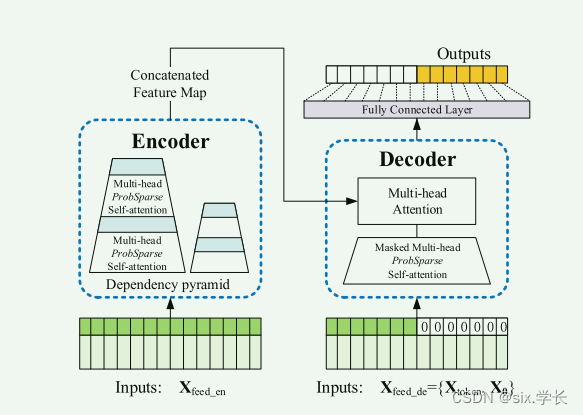
图片引用自论文Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
这张图片展示了一个Transformer模型的架构,这是在自然语言处理(NLP)和其他序列任务中广泛使用的一种模型。图片显示了一个典型的编码器-解码器结构,这种结构常用于序列到序列的模型,比如机器翻译。以下是详细解释及举例:
详细解释
1. 输入(左侧)
输入序列表示为 X_feed_cn。这可以是一个标记序列,例如一句话中的单词或字符。例如,在机器翻译任务中,输入可以是一个英文句子 “I love learning AI”。
2. 编码器(Encoder)
- 编码器部分接收输入序列
X_feed_cn并通过多个堆叠的层进行处理。这些层包括多头注意力机制(Multi-head Attention)、ProbSparse自注意力机制(ProbSparse Self-attention)等。 - 编码器的每一层都以依赖金字塔(Dependency pyramid)的形式逐步缩小输入序列的表示。
- 最终生成的编码器输出是一个特征图(Concatenated Feature Map)&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









