







Gradient Descent
1.手动调整learning rate
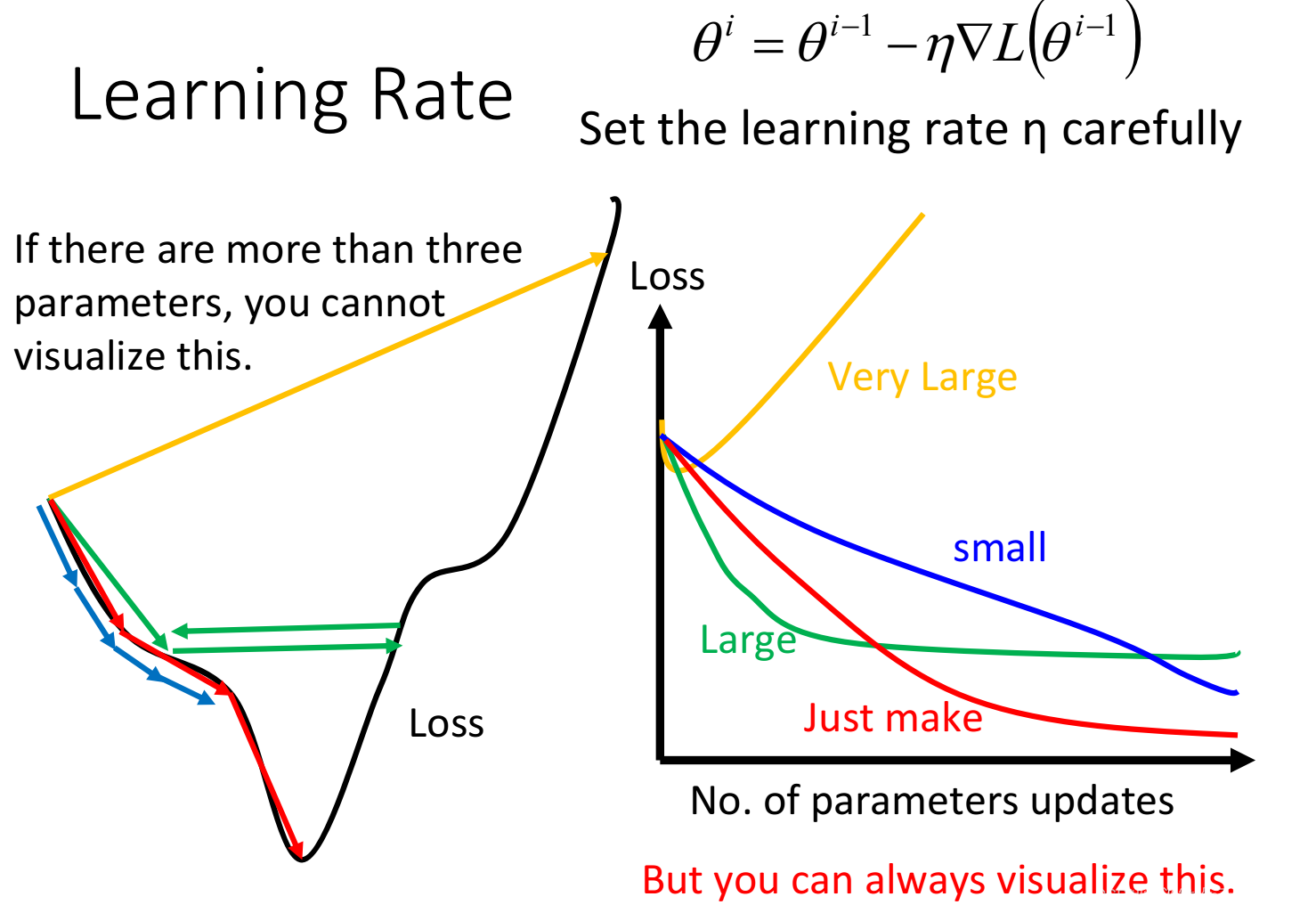
在前面的Loss函数里,用梯度下降找到最小值,梯度下降求解用到的公式里面减去一个η乘上偏微分,那这个η的取值就决定了梯度下降的幅度了,如果η太大,我们可能永远无法走到最小值,如果η太小,那可能非常费时,所以要手动调整η的大小,找到一个最好的
2.Adagrad
随机梯度下降对所有的参数都使用的固定的学习率进行参数更新,但是不同的参数梯度可能不一样,所以需要不同的学习率才能比较好的进行训练,但是这个事情又不能很好地被人为操作,所以想找到一个自动调整learning rate的方法,也就是Adagrad,称作自适应学习率优化算法

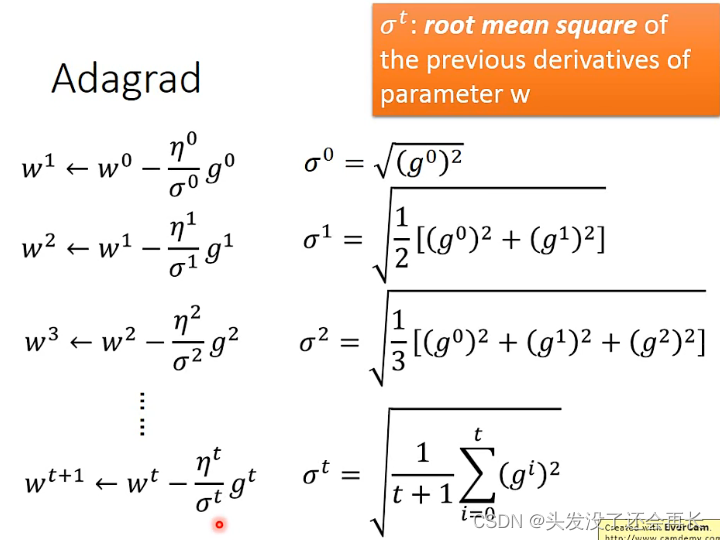
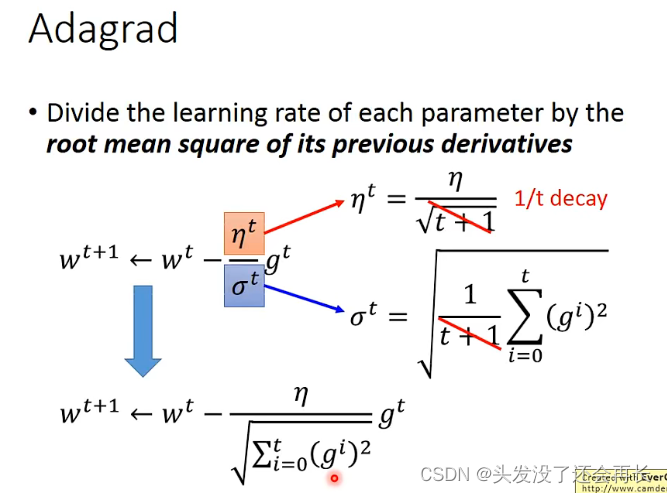
在这里有一个问题,通过Adagrad给出的公式,可以发现gradient越大,分母越大,那么step就会变小,这与手动调整时gradient变大,step也变大相矛盾了。
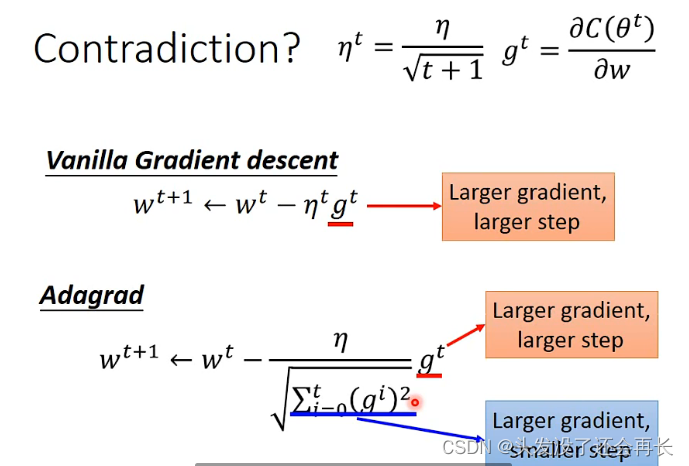
在只一个参数的情况下,gradient越大,这个点距离最低点越远,那么step就应该越大,才能更快到达最低点,这是合理的
但是当有多个参数时,就不一定成立了
比如说a和b相对于参数w1,gradien越大,最好的step也越大,c和d相对于参数w2,gradient越大,最好的step也越大,但是当比较a和c的时候,c的gradient比a的大,但事实上,a距离最低点的step比c大
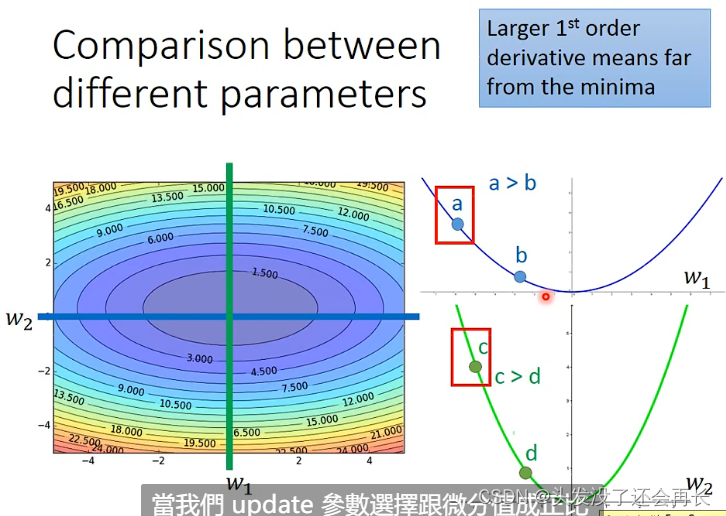 所以,当说的
所以,当说的gradient越大,step越大,是在没有跨参数的情况下才成立的,所以当同时考虑好几个参数的时候,这么想就不够了
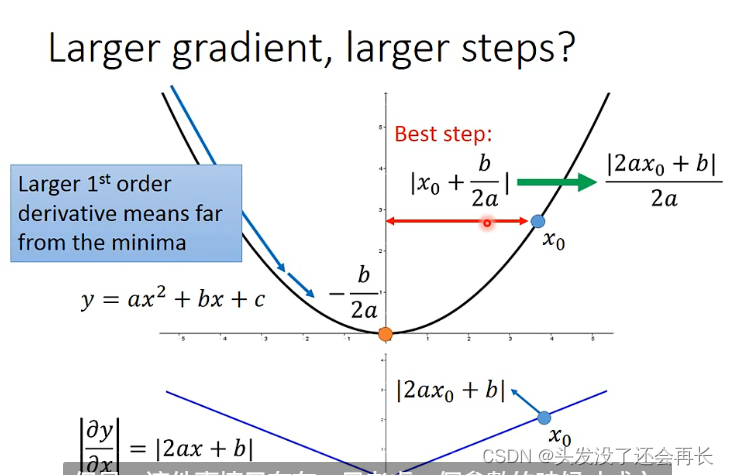
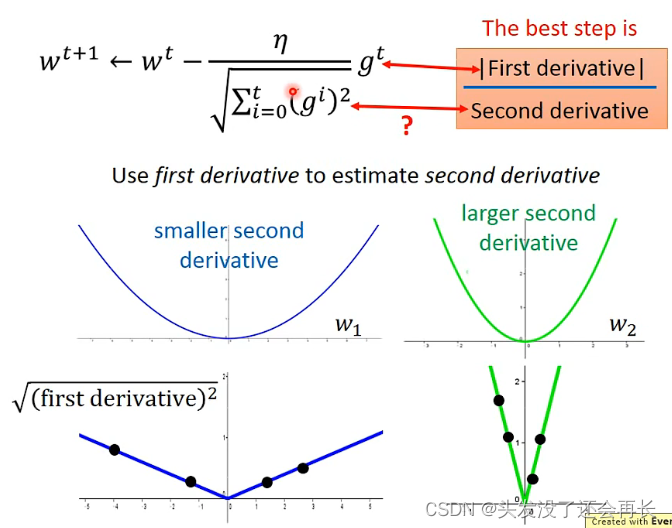
可以发现y=ax^2+bx+c最好的step是|2ax+b|/2a,而2a其实是二次微分,2ax+b是一次微分,所以最好的step就是|一次微分|/|二次微分|
在gradient里面,如何体现的?
其实下面的分母,就是反映了二次微分的大小。
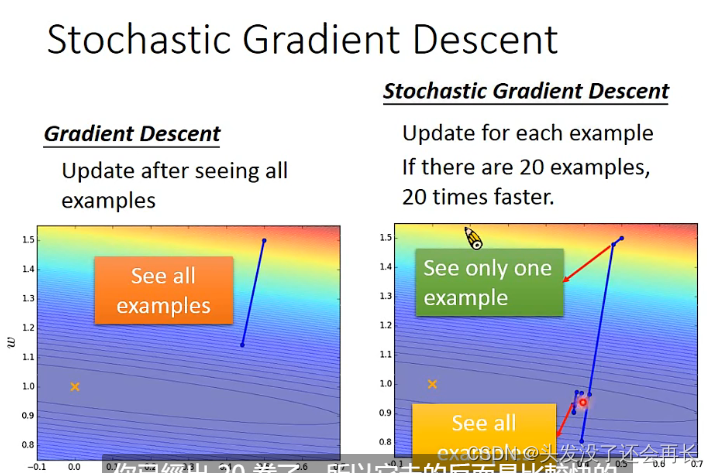
3.Stochastic Gradient Descent(SGD)
如何加快training的速度

4.特征放缩(Feature Scaling)归一化参数
当x2的变化
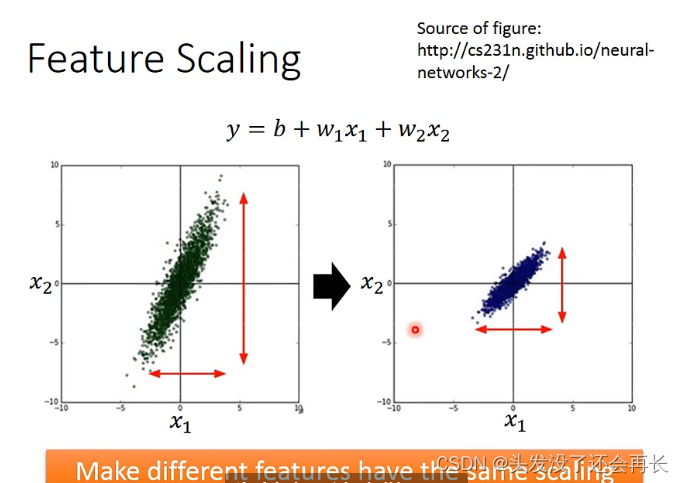
为什么要做scaling?
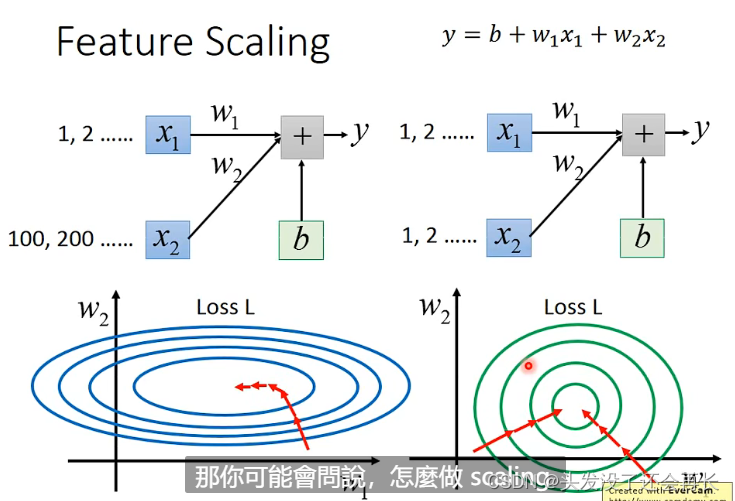
当x2变化的时候,变化较大,对y的影响也比较大(相较于x1),当做出来Loss函数图的时候,可能是个椭圆,那么在descent的时候,从随机一个点出发,它可能不能直接走到我们想要的最低点(会先绕一下),但是对x2做scaling,将它的特征值变化跟x1一样,Loss函数变化就是个圆,就不一样了,从任意一个点出发,一定会直接走到最低点,那么效率就会高















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









