







DNN(Deep Neural Network)
关于深度神经网络(Deep Neural Network)训练过程中的一些方法和技巧
机器学习三步骤
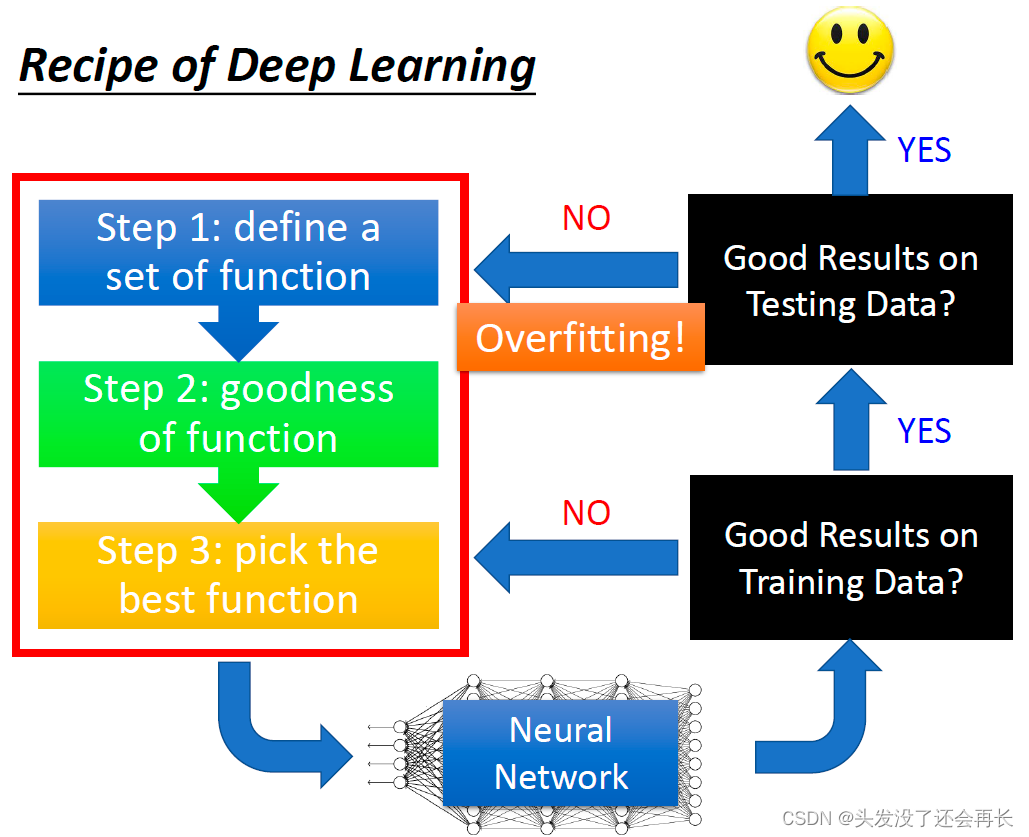
如果model在testing data上得到的结果不好就一定是过拟合吗?
并不是,我们要回到training data上进行测试
- 如果在training data上的结果就是不好的,那说明这个model本身就不好,并不是因为overfitting
- 如果在training data上的结果是好的,在testing data上得到的结果不好,此时才叫overfitting
关于testing/training data不好的解决方案
不同情况下的解决方法:
- 当训练结果不好时,可以考虑:
①新的激活函数(New activation function)
②自动调整学习率(Adaptive Learning Rate)- 当测试结果不好时,可以考虑:
①提前终止(Early Stopping)
②正则化(Regularization)
③Dropout
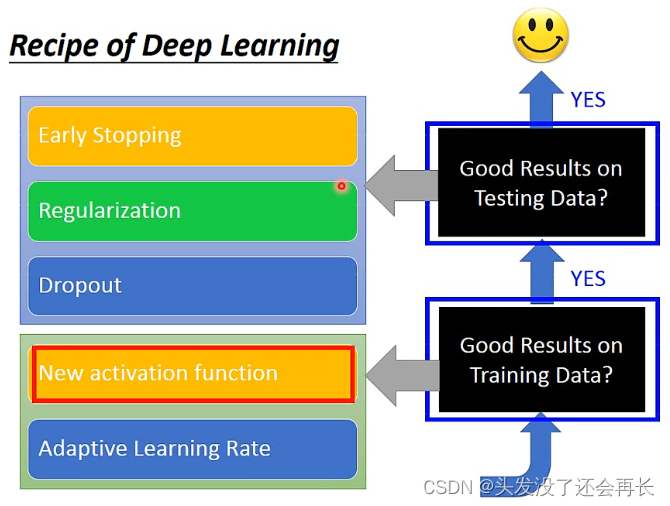
具体介绍这些对应方法
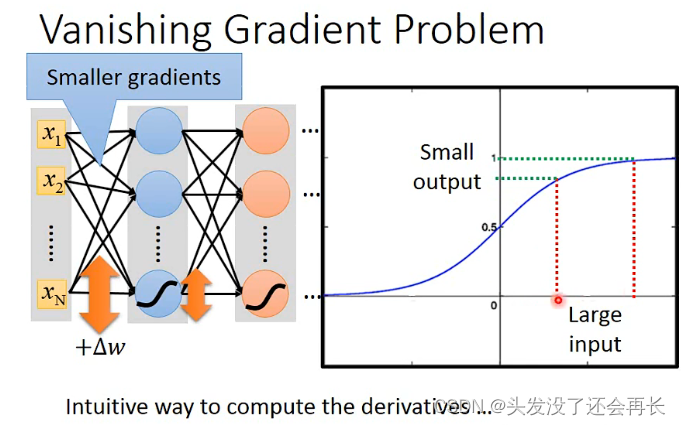
当training data结果不好的时候,一个可能的原因就是梯度下降
为什么会出现梯度消失?
拿激活函数sigmod来说,当输入改变很大的时候,输出的变化很小,神经网络的模型结构决定了:接近输出层y 的隐藏层,梯度大、学习快,当它们很快收敛的时候,接近输入层x 的隐藏层,梯度小、学习慢,参数几乎还是随机的。因此,模型训练后在训练集上的结果不好。
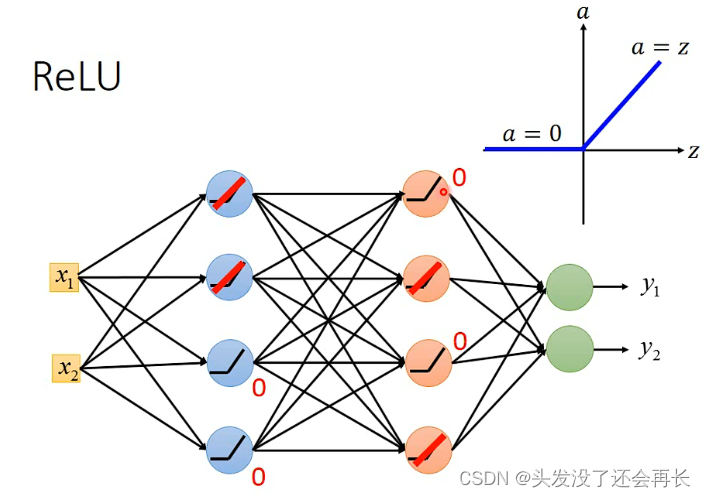
①新的激活函数
- ReLU
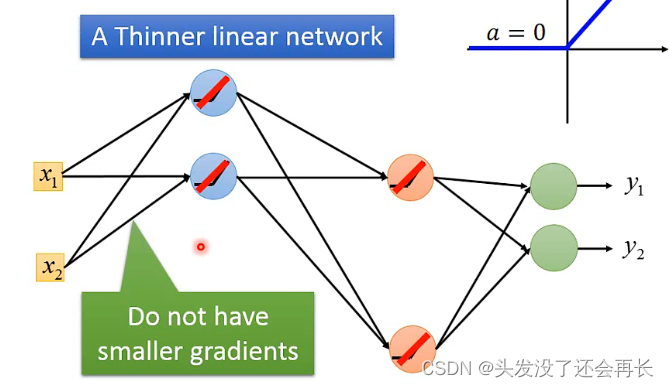
假设有这样一个network,部分neuron的输出是0,那么有ReLU函数可知,当某个neuron是0的时候,其实对最后的output没有影响,可以删去
那么最后的结果就变成一个Linear的function了,(但其实我们用deep就是不想要linear的,我们需要一个复杂的network structure)而且很不好的是,没有办法微分了
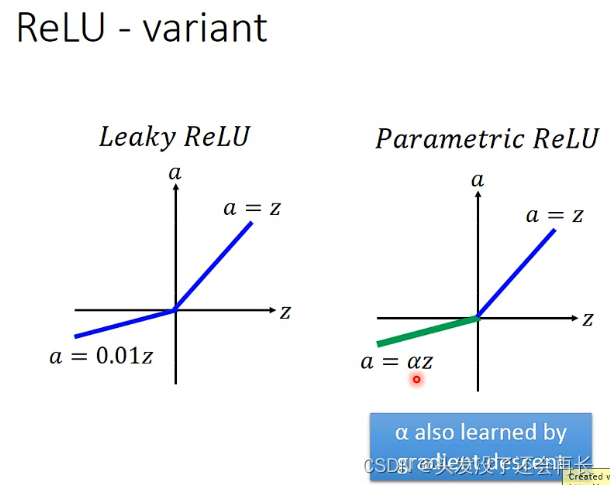
有些人为了是z小于0的时候也能微分,也能decent,就提出了下面的函数- ReLU的变体:Leaky ReLU、Parametric ReLU
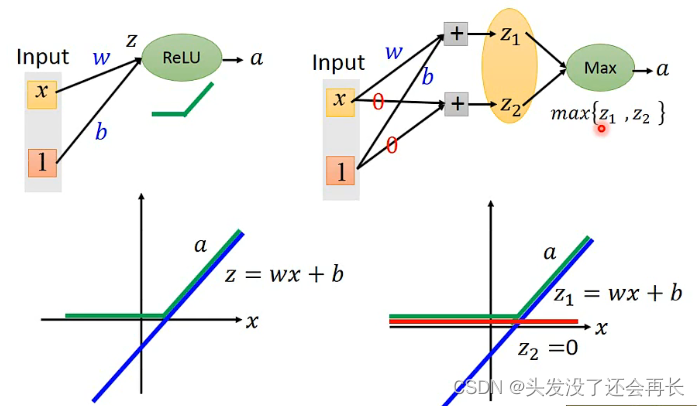
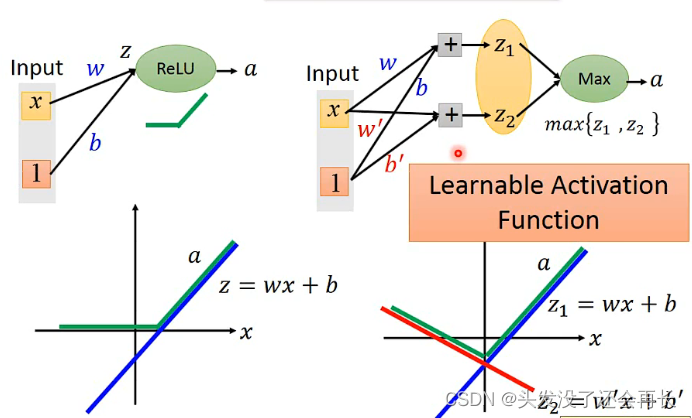
3. Maxout
将同一层的几个神经元(个数需要自己设定)绑定为一组,下一层的输入取每组里的输出的最大值。类似于卷积神经网络的Max Pooling(在CNN这一章会讲到)
Maxout也能用ReLU,即做到ReLU可以做的事
同时Maxout可以做的比ReLU更多



②自动调整学习率
- Adagrad
- RMSProp
可以改变α的值:α 小,倾向于相信新的梯度;α 大,倾向于相信旧的梯度
- Momentum
更新公式
- Adam
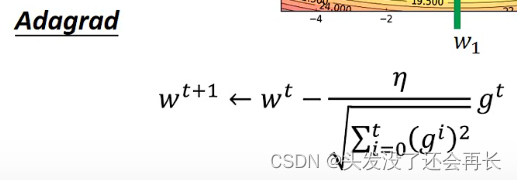
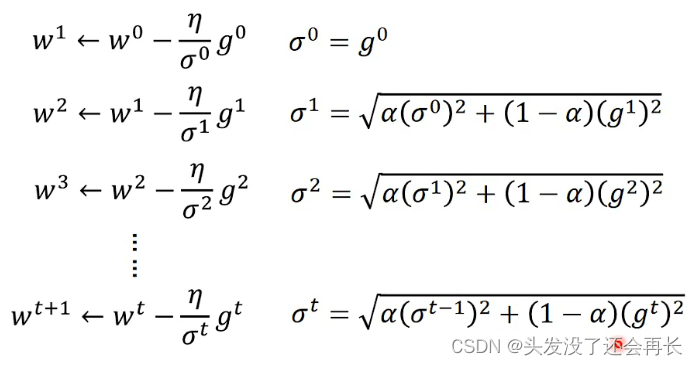
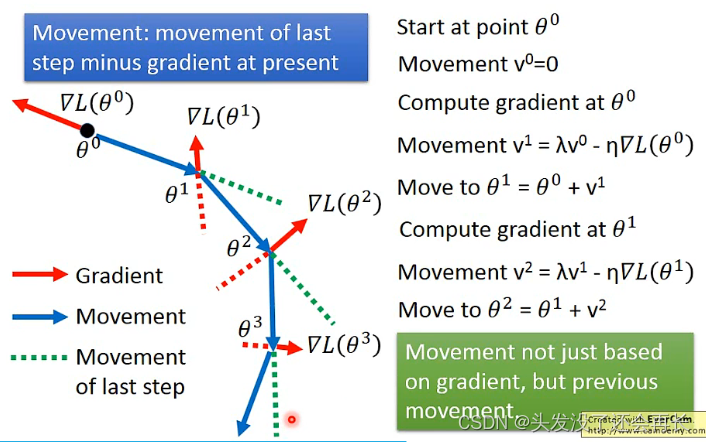


以上都是在testing data得到不好的结果的应对措施
接下来就是在training data上得到不好的结果的应对措施
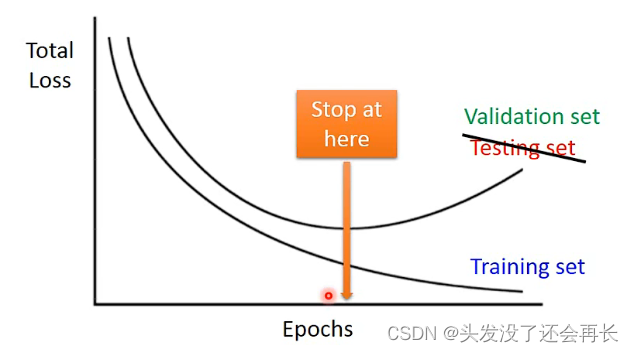
③提前终止(early stopping)
不是终止在training set最小的地方,是终止在testing最小的地方
补充:
训练集(train set) 验证集(validation set) 测试集(test set)
一般需要将样本分成独立的三部分训练集(train set),验证集(validation set)和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。
样本少的时候,上面的划分就不合适了。常用的是留少部分做测试集。然后对其余N个样本采用K折交叉验证法。就是将样本打乱,然后均匀分成K份,轮流选择其中K-1份训练,剩余的一份做验证,计算预测误差平方和,最后把K次的预测误差平方和再做平均作为选择最优模型结构的依据。特别的K取N,就是留一法(leave one out)。
training set是用来训练模型或确定模型参数的,如ANN中权值等; validation set是用来做模型选择(model selection),即做模型的最终优化及确定的,如ANN的结构;而 test set则纯粹是为了测试已经训练好的模型的推广能力。当然,test set这并不能保证模型的正确性,他只是说相似的数据用此模型会得出相似的结果。但实际应用中,一般只将数据集分成两类,即training set 和test set,大多数文章并不涉及validation set。
④正则化
L1 训练结果:权重会比较稀疏,有的参数很小,接近于0;有的参数很大。
L2 训练结果:平均都比较小。


⑤Dropout
训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
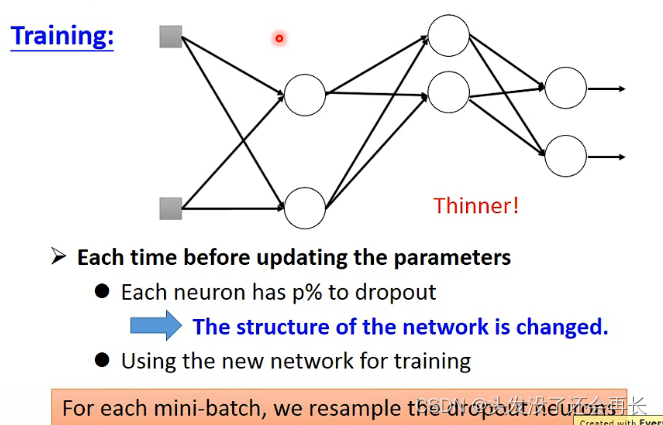
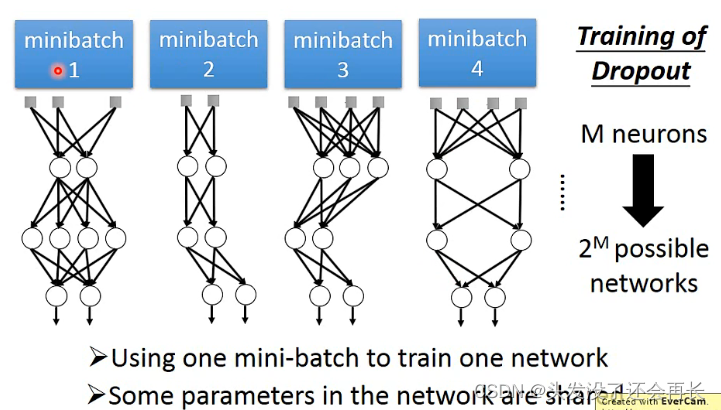
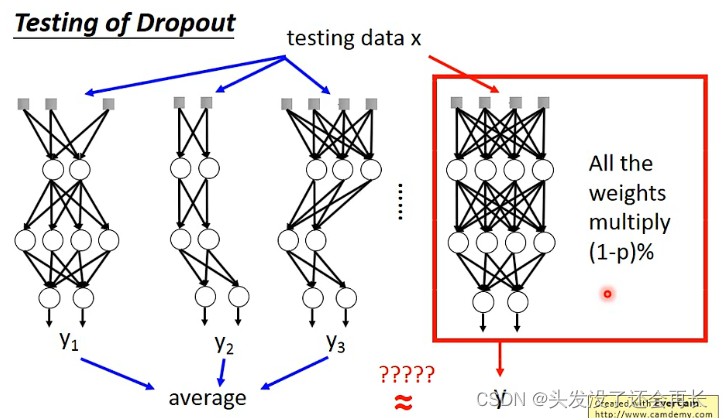
训练的时候,每次sample之前,都看一下每一个neuron会不会被丢掉,每个neuron被丢弃的概率是p%,当一个neuron被丢掉,跟它相邻的weight也失去作用被丢掉,network structure会改变,所以每一次调整参数的时候,拿来训练的network是不一样的,所以都要重新sample
在training的时候dropout效果会变差
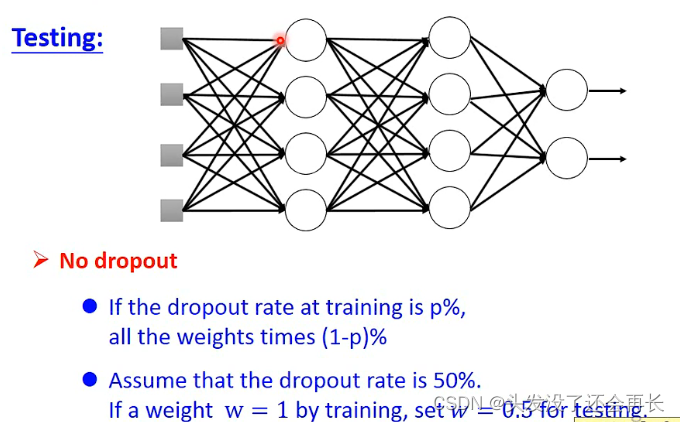
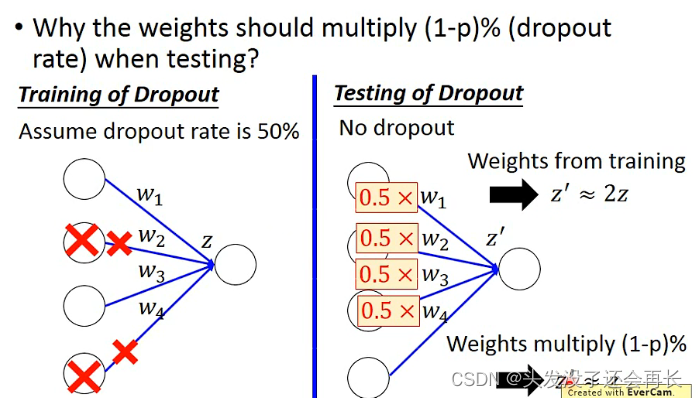
测试的时候,不需要 dropout,如果训练时,丢弃神经元的概率是p% ,测试时,所有权重都要乘(1−p%) .
Dropout 是一种集成学习方法:















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









