






 本文围绕Moco模型展开,先介绍论文思路和框架,接着对代码进行精读,涵盖builder.py、main_moco.py和main_lincls.py文件,详细讲解各文件中的函数、参数设置、模型定义、损失函数和优化器等内容,最后列出复现过程中关于ShuffleBN的问题及解决办法。
本文围绕Moco模型展开,先介绍论文思路和框架,接着对代码进行精读,涵盖builder.py、main_moco.py和main_lincls.py文件,详细讲解各文件中的函数、参数设置、模型定义、损失函数和优化器等内容,最后列出复现过程中关于ShuffleBN的问题及解决办法。
一、论文思路和框架
二、代码精读
代码总体结构如下:( a——>b表示a中调用了b方法或函数)

1 builder.py
该文件中主要定义的是Moco的整体模型,下面来看一下详细实现:
1.1 __init__()
class MoCo(nn.Module):
"""
Build a MoCo model with: a query encoder, a key encoder, and a queue
https://arxiv.org/abs/1911.05722
"""
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
"""
dim: feature dimension (default: 128)
K: queue size; number of negative keys (default: 65536)
m: moco momentum of updating key encoder (default: 0.999)
T: softmax temperature (default: 0.07)
"""
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))- base_encoder()是之前main_moco.py文件开头定义的model_names列表中选择的一个,也就是backbone. 默认为resnet50,如下图:

- 如果mlp=True,在encoder_q和encoder_k前面增加一个全连接层
- self.register_buffer()——pytorch框架中用来保存不更新参数的方法,第一个参数传入一个字符串,表示这组参数的名字,第二个参数是初始化值保存于模型中,不会有梯度传给它,也就是在训练过程中对该参数没有影响。
self.queue和self.queue_ptr分别如下图:
![]()
1.2 forward(self, im_q, im_k)
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
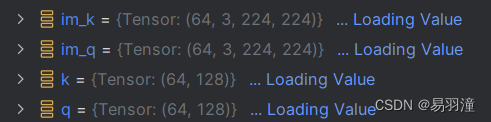
return logits, labels输入两个参数,分别是一个batch中的query image和key image(分别是什么大小?看Dataloader)
- im_q输入query_encoder得到q,大小为(batch_size=64, dim=128)
- 更新key_encoder()
- 将im_k打乱之后输入key_encoder再恢复到原来没打乱的顺序得到k
为什么要将key_img打乱之后再进入key_encoder呢? - 计算logits,也就是损失函数公式中红色方框部分,在代码里面使用的是torch.einsum()这个方法,也就是爱因斯坦简记法
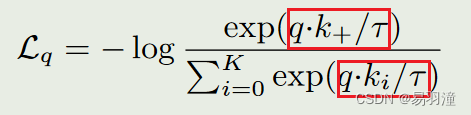
- labels为全0,为了方便使用Cross Entropy loss计算损失,也就是正确的标签为第一个key,对应的编号为0,这样计算出的损失和上图中的损失表达式一致
- 返回logits和labels
1.2.1 self._momentum_update_key_encoder()
1.2.2 self._batch_shuffle_ddp() & self._batch_unshuffle_ddp()
1.2.3 self._dequeue_and_enqueue(k)
2 main_moco.py
这个文件主要是对比学习部分的训练代码,也就是Moco的主体部分,相对于后续的检测和线性分类任务这一块也可以认为是上游任务。
2.1 参数设置
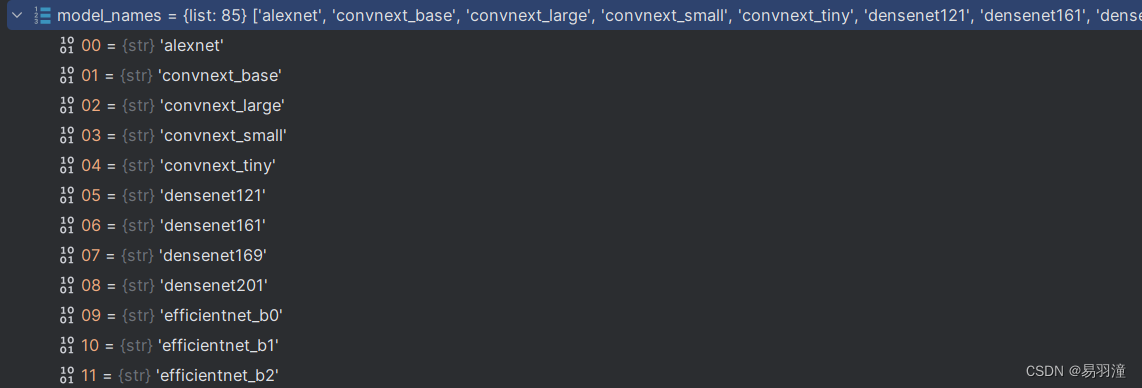
1. 定义model_names,即可以使用的模型
model_names = sorted(
name
for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name])
)model_names是一个列表,包含torch中不同的视觉骨干网络名,如下图所示:
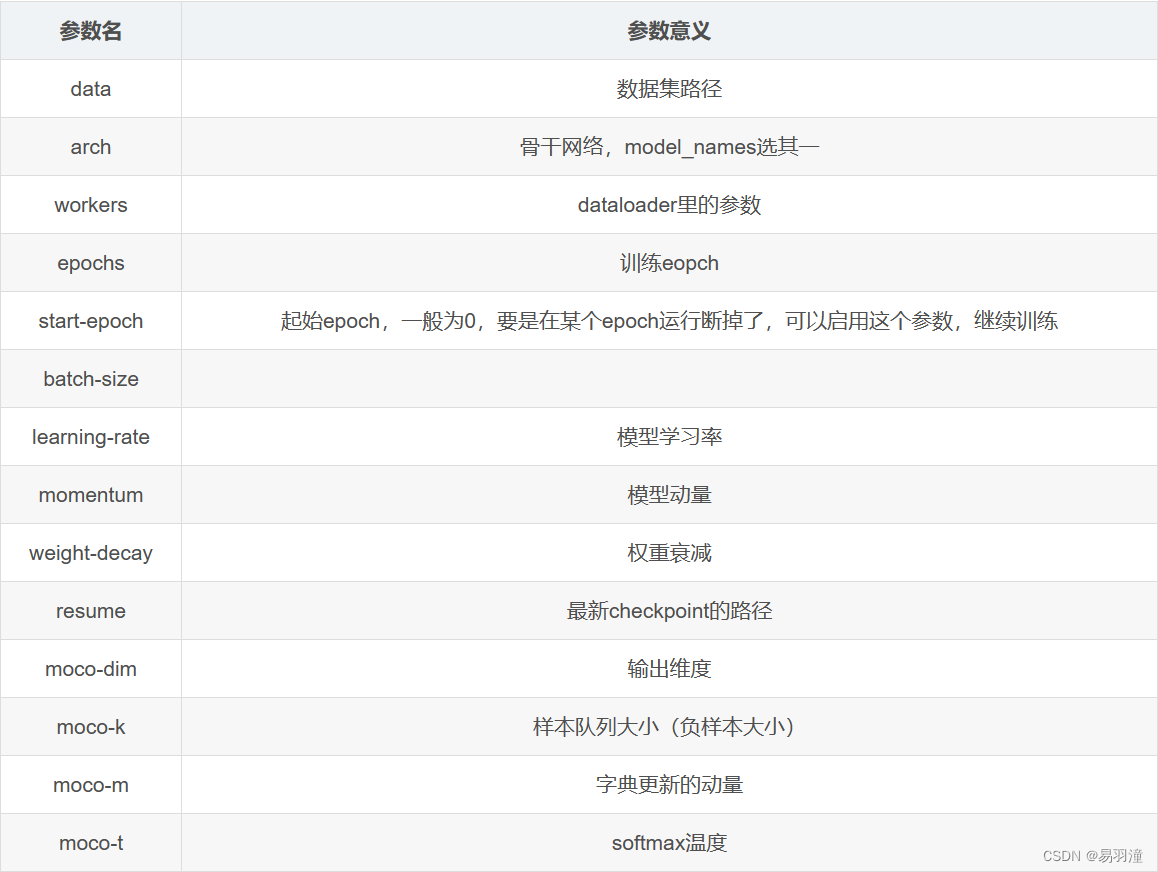
2. 设置训练时的参数
使用parser = argparse.ArgumentParser()定义命令行参数,详细使用方法参考argparse --- 命令行选项、参数和子命令解析器 — Python 3.12.3 文档
不同参数含义如下:
2.2 主要函数——main_worker(gpu, ngpus_per_node, args)
下面主要对除了跟GPU训练相关的代码进行解释。
2.2.1 定义模型
model = moco.builder.MoCo(
models.__dict__[args.arch],
args.moco_dim,
args.moco_k,
args.moco_m,
args.moco_t,
args.mlp,
)
print(model)模型结构的讲解参考2 builder.py。
![]()
定义模型,输入两组image分别为query_image和key_image,大小如下,其中64是batch_size:
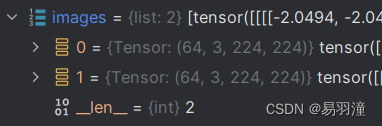
输出output和target大小如下,分别为logits值和全0的Tensor

2.2.2 定义损失函数和优化器
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
optimizer = torch.optim.SGD(
model.parameters(),
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
).cuda(args.gpu)——使用指定的GPU进行训练
2.2.3 定义训练数据集文件路径和数据增强(Data Augmentation)
# Data loading code
traindir = os.path.join(args.data, "train")
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
if args.aug_plus:
# MoCo v2's aug: similar to SimCLR https://arxiv.org/abs/2002.05709
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.0)),
transforms.RandomApply(
[transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8 # not strengthened
),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([moco.loader.GaussianBlur([0.1, 2.0])], p=0.5),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
else:
# MoCo v1's aug: the same as InstDisc https://arxiv.org/abs/1805.01978
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
train_dataset = datasets.ImageFolder(
traindir, moco.loader.TwoCropsTransform(transforms.Compose(augmentation))
)首先通过数据集文件夹得到训练集的路径,然后定义一个Normalize实例,最后定义augmentation的操作,它是包含众多transform中的实例,aug_plus是Moco v2使用的数据增强,下面的是Moco v1的数据增强,包括重置大小、调整灰度值等,主要transform操作的含义如下:
- transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.33333):A crop of the original image is made: the crop has a random area (H * W) and a random aspect ratio. This crop is finally resized to the given size.
- transforms.RandomApply(transforms, p=0.5):Apply randomly a list of transformations with a given probability.
- transforms.ColorJitter(brightness: Union[float, Tuple[float, float]] = 0, contrast: Union[float, Tuple[float, float]] = 0, saturation: Union[float, Tuple[float, float]] = 0, hue: Union[float, Tuple[float, float]] = 0): Randomly change the brightness, contrast, saturation and hue of an image.
- moco.loader.GaussianBlur([0.1, 2.0]):
class GaussianBlur: """Gaussian blur augmentation in SimCLR https://arxiv.org/abs/2002.05709""" def __init__(self, sigma=[0.1, 2.0]): self.sigma = sigma def __call__(self, x): sigma = random.uniform(self.sigma[0], self.sigma[1]) x = x.filter(ImageFilter.GaussianBlur(radius=sigma)) return xPIL.ImageFilter.GaussianBlur(radius=5)方法创建高斯模糊过滤器。
radius – 模糊半径。改变半径的值,可以得到不同强度的高斯模糊图像。
接下来使用train_dataset = datasets.ImageFolder()构建数据集,参数如下:
可以看到, moco.loader.TwoCropsTransform(transforms.Compose(augmentation))应该是一个transform变换,下面来看一下moco.loader.TwoCropsTransform()是什么?其实就是随机生成两张数据增强的图像,分别作为Moco中的query和key。也就是每一个图片对应地只返回两张图。
class TwoCropsTransform:
"""Take two random crops of one image as the query and key."""
def __init__(self, base_transform):
self.base_transform = base_transform
def __call__(self, x):
q = self.base_transform(x)
k = self.base_transform(x)
return [q, k]ImageFolder生成的对象:(可以作为data_loader的参数来定义DataLoader)

![]()
2.2.4 定义训练时的DataLoader以及调用train函数
使用的都是一些之前定义好的参数,可以看到刚才ImageFolder生成的数据集作为DataLoader的一个参数。train函数在下一小节讲解。
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
pin_memory=True,
sampler=train_sampler,
drop_last=True,
)
train(train_loader, model, criterion, optimizer, epoch, args)2.3 训练主体函数train()
def train(train_loader, model, criterion, optimizer, epoch, args):
batch_time = AverageMeter("Time", ":6.3f")
data_time = AverageMeter("Data", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses, top1, top5],
prefix="Epoch: [{}]".format(epoch),
)
# switch to train mode
model.train()
end = time.time()
for i, (images, _) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.gpu is not None:
images[0] = images[0].cuda(args.gpu, non_blocking=True)
images[1] = images[1].cuda(args.gpu, non_blocking=True)
# compute output
output, target = model(im_q=images[0], im_k=images[1])
loss = criterion(output, target)
# acc1/acc5 are (K+1)-way contrast classifier accuracy
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images[0].size(0))
top1.update(acc1[0], images[0].size(0))
top5.update(acc5[0], images[0].size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
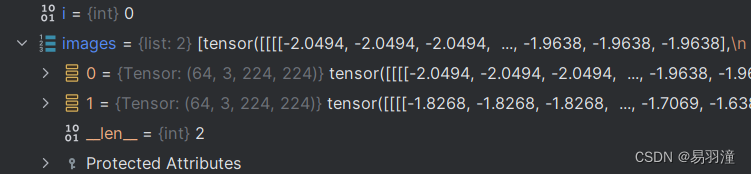
progress.display(i)从train_loader中取出的image如下图,含有两组图片,分别是query_image和key_image,每组图片中有64张图片,即batch_size
2.3.1 AverageMeter() 和 ProgressMeter() 类
AverageMeter() 用于计算并存储平均值和当前值,主要方便之后loss等数值的更新:
-
__init__方法:这是类的初始化方法。它接受两个参数:name:表示要计算的值的名称。fmt:是一个格式化字符串,用于指定如何格式化输出结果。默认值为":f",表示使用浮点数格式化。
-
reset方法:用于重置所有计数器,将值重置为初始状态。 -
update方法:用于更新计算器的值。它接受两个参数:val:表示要更新的值。n:表示更新值的次数,默认为 1。这对于累积多个值并更新平均值很有用。
-
__str__方法:用于生成对象的字符串表示。它使用了预定义的格式化字符串fmtstr,将对象的名称、当前值和平均值格式化成字符串并返回。
ProgressMeter() 用于在训练过程中显示进度信息:
-
__init__方法:这是类的初始化方法。它接受三个参数:num_batches:表示总共有多少批次需要进行处理。meters:是一个列表,包含了每个批次需要跟踪的进度信息的对象。
在train()中,显示的进度信息为
prefix:是一个可选参数,表示在显示进度信息时的前缀字符串。
-
display方法:这个方法用于显示进度信息。它接受一个参数batch,表示当前批次的编号。它会构建一个包含进度信息的字符串列表,其中包括前缀、当前批次的字符串表示以及每个进度信息对象的字符串表示。然后将这些字符串连接起来并打印出来。 -
_get_batch_fmtstr方法:这个方法用于生成批次信息的格式化字符串。它接受一个参数num_batches,表示总共有多少批次。它计算出数字的位数,并生成一个格式化字符串,用来将当前批次编号和总批次数插入到方括号中。
class AverageMeter:
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)class ProgressMeter:
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print("\t".join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = "{:" + str(num_digits) + "d}"
return "[" + fmt + "/" + fmt.format(num_batches) + "]"2.3.2 accuracy方法
用于计算模型预测的准确率,函数返回的是一个和topk大小相同的列表,表示在top k相似度的key中包含有正确的那个key的正确率。比如![]() 表示如果取相似度最高的那个key作为预测结果,准确率只有23%,如果认为预测结果在相似度最高的五个key中,准确率为50%。
表示如果取相似度最高的那个key作为预测结果,准确率只有23%,如果认为预测结果在相似度最高的五个key中,准确率为50%。
-
output:表示模型的输出,也就是损失函数中的相似度logit. -
target:表示样本的真实标签。通常是一个张量,包含每个样本的真实类别。 -
topk:一个元组,指定了计算准确率时考虑的相似度最高的 k 个预测结果。默认值为(1,),即只考虑最高的预测结果的准确率。 -
with torch.no_grad():这是一个上下文管理器,用于关闭梯度计算,因为在计算准确率时不需要计算梯度。 -
maxk = max(topk):确定要考虑的最高预测结果的数量。 -
batch_size = target.size(0):获取batch_size的大小。 -
_, pred = output.topk(maxk, 1, True, True):使用torch.topk函数获取模型输出中概率最高的前maxk个预测结果。pred包含了每个样本的前maxk个预测类别的索引。 -
pred = pred.t():转置pred张量,使得每一列对应一个样本的所有预测结果。 -
correct = pred.eq(target.view(1, -1).expand_as(pred)):比较预测结果和真实标签,生成一个布尔张量,表示每个预测结果是否正确。 -
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True):取前 k 个预测结果的正确性,计算正确预测的数量,并将其转换为浮点数格式。 -
res.append(correct_k.mul_(100.0 / batch_size)):计算准确率,并将结果添加到res列表中。

def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res3 main_lincls.py
3.1 参数设置
这部分和main_coco.py文件大部分参数都是相同的,增加了一个"--pretrained"参数,指moco预训练好的模型路径。
3.2 主要函数——main_worker(gpu, ngpus_per_node, args)
3.2.1 定义全局变量,记录最高正确率
global best_acc13.2.2 构造模型(包含下游任务的模型)
模型的主体部分已经由前面的Moco训练好了,因此除了最后全连接层的w和b,网络前面部分的参数都冻住不变(freeze),也就是不需要梯度回传更新。最后再对全连接层的参数进行初始化。
# create model
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
# freeze all layers but the last fc
for name, param in model.named_parameters():
if name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
# init the fc layer
model.fc.weight.data.normal_(mean=0.0, std=0.01)
model.fc.bias.data.zero_()model.named_parameters(): 返回一个包含参数名称和对应参数张量的迭代器,以元组形式返回(一般需要冻结一些层的参数使用,可以学习)
3.2.3 加载预训练的模型
if args.pretrained:
if os.path.isfile(args.pretrained):
print("=> loading checkpoint '{}'".format(args.pretrained))
checkpoint = torch.load(args.pretrained, map_location="cpu")
# rename moco pre-trained keys
state_dict = checkpoint["state_dict"]
for k in list(state_dict.keys()):
# retain only encoder_q up to before the embedding layer
if k.startswith("encoder_q") and not k.startswith(
"encoder_q.fc"
):
# remove prefix
state_dict[k[len("encoder_q.") :]] = state_dict[k]
# delete renamed or unused k
del state_dict[k]
args.start_epoch = 0
msg = model.load_state_dict(state_dict, strict=False)
assert set(msg.missing_keys) == {"fc.weight", "fc.bias"}
print("=> loaded pre-trained model '{}'".format(args.pretrained))
else:
print("=> no checkpoint found at '{}'".format(args.pretrained))加载预训练模型之后得到的checkpoint结构如下图所示,为包含四个元素的字典,分别记录了训练次数、backbone网络、网络中所有的参数和优化器。

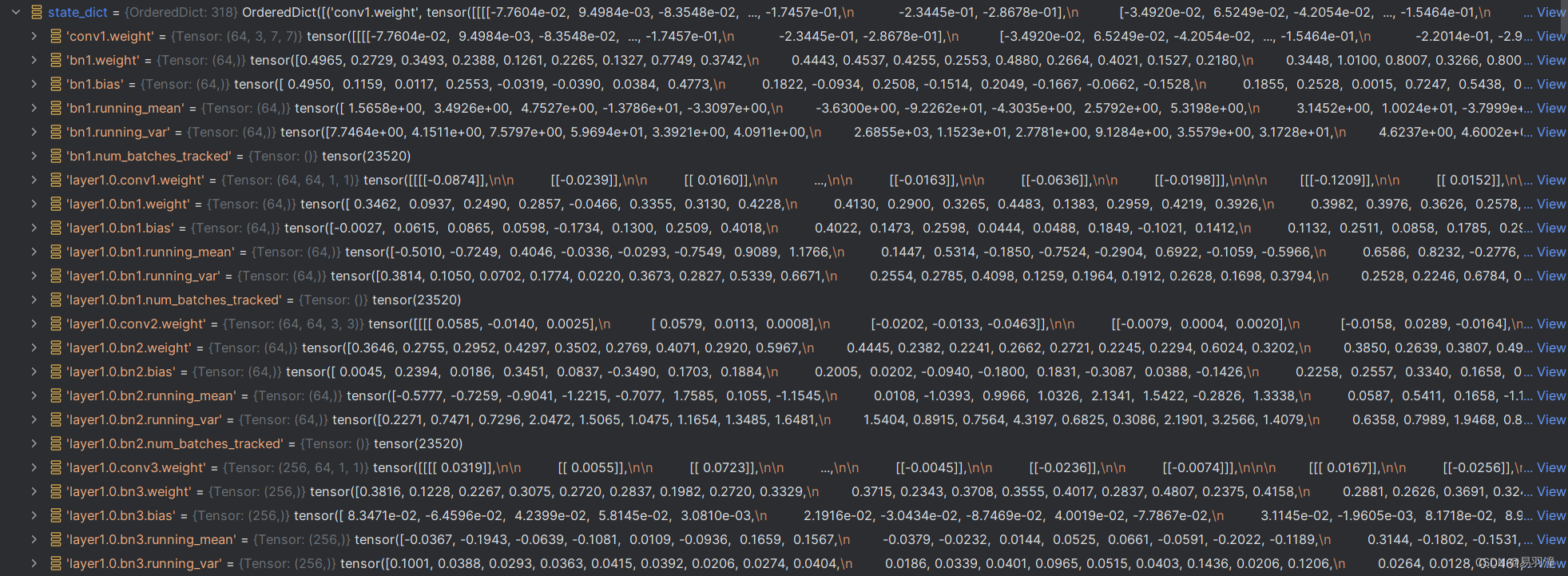
state_dict结构如下图,也就是将网络中每一层参数的值都记录下来。
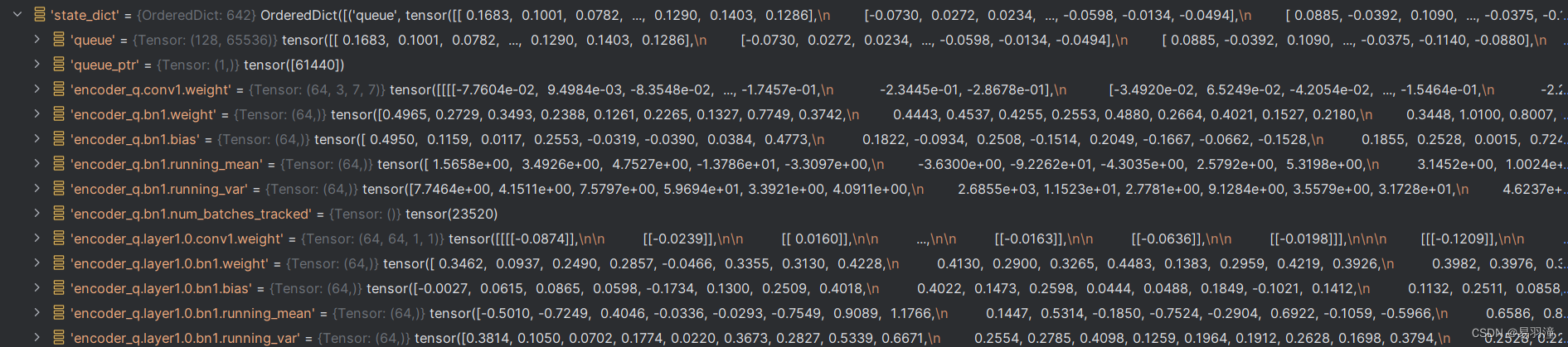
加载模型文件后,仅保留encoder_q部分的模型和参数,其他的参数都删除,并且将encoder.q中参数的键值(key)的前缀去掉。state_dict遍历完成之后的结构如下图。
使用model.load_state_dict(state_dict)方法将state_dict中的参数加载到即将训练的model里面,然而state_dict中没有最后FClayer的参数,因此需要对msg中missing_keys进行断言。
3.2.4 定义损失函数和优化器
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
# optimize only the linear classifier
parameters = list(filter(lambda p: p.requires_grad, model.parameters()))
assert len(parameters) == 2 # fc.weight, fc.bias
optimizer = torch.optim.SGD(
parameters, args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)损失函数的计算使用交叉熵损失。定义优化器之前将模型model中需要进行梯度的参数提取出来,通过断言确保优化的参数只有两个,从而优化器只会对线性层的参数进行梯度更新。
3.2.5 定义训练集和验证集对应的DataLoader
可以看到对训练和验证数据集简单进行了一些图像增强的工作。
traindir = os.path.join(args.data, "train")
valdir = os.path.join(args.data, "val")
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
),
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
pin_memory=True,
sampler=train_sampler,
)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(
valdir,
transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]
),
),
batch_size=args.batch_size,
shuffle=False,
num_workers=args.workers,
pin_memory=True,
)3.2.6 迭代训练
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
adjust_learning_rate(optimizer, epoch, args)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, args)
# evaluate on validation set
acc1 = validate(val_loader, model, criterion, args)
# remember best acc@1 and save checkpoint
is_best = acc1 > best_acc1
best_acc1 = max(acc1, best_acc1)
if not args.multiprocessing_distributed or (
args.multiprocessing_distributed and args.rank % ngpus_per_node == 0
):
save_checkpoint(
{
"epoch": epoch + 1,
"arch": args.arch,
"state_dict": model.state_dict(),
"best_acc1": best_acc1,
"optimizer": optimizer.state_dict(),
},
is_best,
)
if epoch == args.start_epoch:
sanity_check(model.state_dict(), args.pretrained)3.3 训练主体函数 train()
三、一些Q&A(自己在复现时的问题)
1. 关于ShuffleBN
原论文中的表述如下,其实就是将一个大的batch打乱之后再分配给不同的GPU进行训练,这样通过BN计算出来的均值和方差就和query_encoder不一样。但是如果不使用并行训练可能就无法使用这种方法
The model appears to “cheat” the pretext task and easily finds a low-loss solution. This is possibly because the intra-batch communication among samples (caused by BN) leaks information. We resolve this problem by shuffling BN. We train with multiple GPUs and perform BN on the samples independently for each GPU (as done in common practice). For the key encoder fk, we shuffle the sample order in the current mini-batch before distributing it among GPUs (and shuffle back after encoding); the sample order of the mini-batch for the query encoder fq is not altered. This ensures the batch statistics used to compute a query and its positive key come from two different subsets. This effectively tackles the cheating issue and allows training to benefit from BN.

















 2513
2513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









