






 本文记录了一位深度学习初学者在复现Google的Dreamfusion网络过程中遇到的困难,包括使用stabledreamfusion的部署配置、安装步骤,以及解决nvdiffrast、CLIP和tinycudann等库的问题和HuggingFace连接问题的实践经验。
本文记录了一位深度学习初学者在复现Google的Dreamfusion网络过程中遇到的困难,包括使用stabledreamfusion的部署配置、安装步骤,以及解决nvdiffrast、CLIP和tinycudann等库的问题和HuggingFace连接问题的实践经验。
深度学习小白,毕设要用到这个网络,复现遇到了挺多困难,记录一下解决过程。
dreamfusion是google开发的text to 3D的网络,不管是dreamfusion还是他使用的文本到二维生成网络imagen都是不开源的,因此想尝试dreamfusion,只能用他的模仿品stable dreamfusion,stable dreamfusion的作者提到,他无法复现出dreamfusion这么好的效果,但在paper with code上,他在T**3 数据集上,表现依然很靠前。
部署配置
4060,vs2022,cuda11.8
建议在GPU内存大于24G的服务器上部署,这样可以用他的各种可选功能,效果也会更好。其他无过多要求,我开始用的显卡是4060,不太够用,后面就换服务器上跑了。
网址
安装
下载源码
git clone https://github.com/ashawkey/stable-dreamfusion.git
cd stable-dreamfusion创建conda/venv环境
先检查下cuda,torch,python这个对应,建议单独拿出来装
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118剩下的直接装(建议注释掉requirements.txt中的torch,一是已经装过了,二是按他那个默认的装可能下载成cpu版本的)
pip install -r requirements.txt随后下载三个权重,第一个放在pretrained/zero123里,第二三个放在pretrained/omnidata里。
第一个下载地址:https://zero123.cs.columbia.edu/assets/zero123-xl.ckpt
第二三个下载地址(当然用gdown下载也是一样的):https://drive.usercontent.google.com/download?id=1wNxVO4vVbDEMEpnAi_jwQObf2MFodcBR&authuser=0
https://drive.usercontent.google.com/download?id=1Jrh-bRnJEjyMCS7f-WsaFlccfPjJPPHI&authuser=0
讲道理,按说这样就ok了,确实ok的就不用往下看了,我记录一下不ok的问题(可能有点蠢)。
问题
1. requirements中有三个库是可能出现问题的nvdiffrast,CLIP,tinycudann。
他们都基本是网络问题导致的,前两个很简单,第三个要稍微费点劲。
前两个,先开个总文件夹lib存他们,然后直接去github上搜一下,git clone下来,然后在你开的环境里运行(这个其实就是pip的工作流程)
python setup.py install第三个,如果要是一遍安装成功就不用来看这个了。
- 还在新建的lib文件夹下把他下载下来,网址:GitHub - NVlabs/tiny-cuda-nn: Lightning fast C++/CUDA neural network framework
- 然后tinycudann的dependencies的文件是不全的,要自己去下载。下载完解压到dependencies对应的文件夹就好。
fmt:https://github.com/fmtlib/fmt/tree/b0c8263cb26ea178d3a5df1b984e1a61ef578950
cutlass:
https://github.com/NVIDIA/cutlass/tree/1eb6355182a5124639ce9d3ff165732a94ed9a70
- 以管理者身份打开"x64 Native Tools Command Prompt for VS 2022"终端,cd到你tinycudann的这个路径,一直cd到./tiny-cuda-nn/bindings/torch这里
- my_venv是你为stable dreamfusion创建的conda/venv环境,随后运行
activate tiny-cuda-nn python setup.py install
2.三个需要在运行时才编译的库(我很不理解,为啥不能pip的时候就给人安装好)
gridencoder,raymarching,freqencoder
我测试出来的方法是首先分别进入他们仨的文件夹,找到setup.py,注释掉nvcc_flag中的'-O3', '-std=c++14',以及如果你的visual studio不装在c盘,记得改下下面那个路径

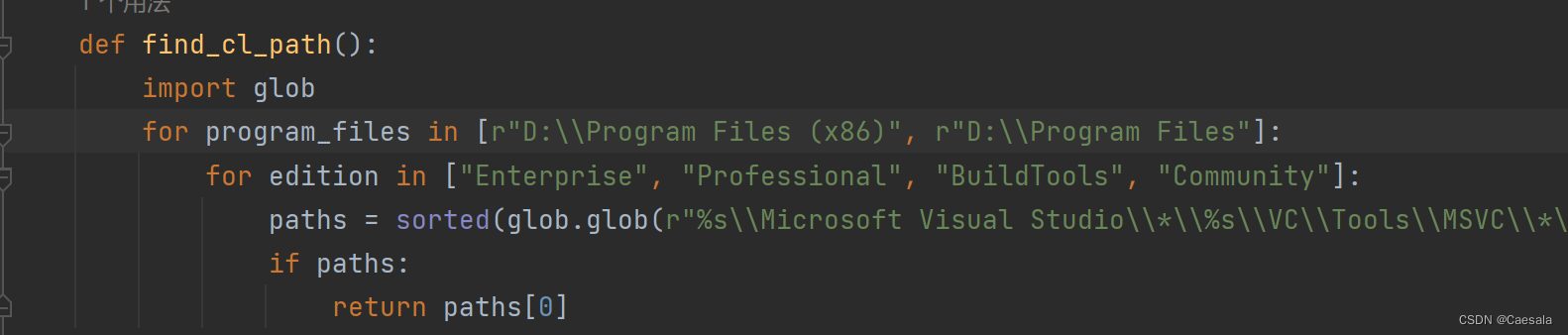 随后直接在你的环境中python setup.py install就好
随后直接在你的环境中python setup.py install就好
3. 出现huggingface的连接问题。
这个问题见仁见智了,爱怎么解决怎么解决,stackflow和github上有很多解法。
这个工程是用from_pretrained()方法下载的,我不会看他到底下在哪,虽然他提示了C:/User/xx/.cache/huggingface/.......这样的路径,但我把下载好的东西放过去他提示找不到,所以还是一劳永逸。
断开你的梯子,然后设置环境变量
setx HF_ENDPOINT=https://hf-mirror.com随后就可以根据readme里的usage测试训练啦!


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











