










ABSTRACT
利用患者的诊断结果来开具药物处方是一项具有挑战性的任务。制药公司的数量、药品库存以及推荐剂量给医生带来了信息和认知过载的问题。为了帮助医生在给患者开处方时做出明智的决策,研究人员利用电子健康记录(EHRs)来自动推荐药物。近年来,利用 EHRs 进行药物推荐已成为一个重要的研究方向,吸引了众多研究人员将各种深度学习(DL)模型应用于患者的 EHRs 来推荐处方。然而,由于缺乏全面的综述文章,研究人员需要花费大量精力和时间来研读这些文献,以了解研究现状、确定表现最佳的模型以及研究趋势和挑战。为了填补这一研究空白,本文对基于深度学习的药物推荐方法进行了综述。文中回顾了基于深度学习的药物推荐(MR)模型的分类,比较了它们的性能和面临的不可避免的问题,报告了用于评估 MR 模型的最常见数据集和指标。这项研究的结果对研究 MR 模型的人员具有重要意义。
1. INTRODUCTION
推荐系统作为信息检索与过滤机制,意在缓解因信息库规模持续扩张,引发信息与认知过载这类常见问题所带来的负面影响 。在海量信息面前,医学领域不容忽视,制药公司数量众多、药品种类持续增长,这对医生依据患者诊断结果和病史开具药方造成了巨大冲击。
为应对这一难题,研究者借助电子健康记录(EHRs)自动推荐药物,辅助医生在开处方选药时做出明智决策。EHRs 全方位呈现患者病史,涵盖既往用药、诊断结果、实验室检查、治疗计划,还有 X 光、超声、磁共振成像(MRI)等医学影像,是个性化医学研究的关键数据载体。近期,EHRs 质量提升,因其潜在的医学诊断与推荐应用,吸引了众多研究者。它语义丰富,以患者一系列临床事件(包含手术、诊断、用药等)的时间入院序列形式呈现。把这些记录与患者当下临床状况(事件、诊断等)整合,输入药物推荐系统,就能生成个性化的用药推荐,助力医生依患者当前健康状况精准开方。
不过,药物推荐任务并不轻松,在机器辅助医学诊断与治疗的漫长历程里,它极具挑战性且相当复杂。药物推荐系统可采用基于内容(CB)、协同(CF)或混合过滤的方式,但由于存在数据稀疏、冷启动、缺乏个性化等问题,传统过滤方法效果欠佳。于是,研究者引入深度学习(DL)来生成高质量的药物推荐,一些知名的基于 DL 的药物推荐(MR)模型范例可见于 [9, 10, 11, 12, 13, 3, 14, 15]。
已有多篇综述文章涉足医疗保健与药物推荐领域:
Sezgin 和 Ozkan [6] 探讨了运用信息过滤方法的传统 MR 模型,却未阐述基于 DL 的 MR 模型现状及其面临的问题。
Hors - Fraile 等人 [16] 概述了 2007 - 2016 年发表的 MR 模型技术要点,包括过滤方法与配置文件适配技术,但涉及 MR 模型的内容极少,大多研究关乎健康与生活方式,未分析基于 DL 的 MR 模型,对最新 DL - MR 模型的覆盖也很有限。
Zhang 等人 [17] 回顾了用于个性化医疗的机器学习(ML)和深度学习模型,稍稍提及 MR 任务,提到了个性化医疗的挑战与未来机遇,但没涉及过滤方法、信息来源等技术层面,也未分析 ML 与 DL - MR 模型及优化方法 。
Rajkomar 等人 [18] 概述了 ML 在医学中的应用方式、运行原理,以及为 ML 算法提供动力的输入输出医药数据类型,探讨了应用难点,却没讨论用于 MR 任务的 ML 算法相关内容。
Ngiam 和 Khor [19] 列举了基于 ML 的医疗服务模型的优势与挑战,探讨了一些能提供推荐及其他服务的 ML 平台与工具,但没汇报推荐相关的具体细节,如过滤方法、信息源和影响因素,涉及 MR 模型的研究很少,大多与医疗服务输送有关。
Su 等人 [20] 汇报了生物医学领域常用的网络嵌入模型及其性能,介绍了相关软件工具、面临的挑战与改进方向,但未涉及推荐相关细节,像过滤方法、来源、因素和优化方法。
Etemadi 等人 [7] 对 2010 - 2021 年发表的药物推荐技术文献进行系统综述,含过滤方法(CB、CF、混合、基于知识和情境的),却没覆盖信息来源与因素,涉及 MR 模型的研究不多,大多关联健康与生活方式,对 DL - MR 模型的分析有限,未涉及优化方法。
总体而言,上述多数研究要么关乎普通医学、医疗保健、生活方式,要么涉及 MR 特定细节,如信息过滤方法、来源、因素。然而,这些研究都无法深入、全面剖析基于 DL 的 MR 模型各方面,包括信息过滤方法、来源、因素、评估及对比分析。即便涉及 DL - MR 模型,内容也很少,无法呈现该领域当下状况,对 DL - MR 模型面临的问题探究也十分有限。鉴于此,对最新的基于 DL 的 MR 模型展开详尽回顾与深度分析,正是本文的核心目标。
Motivation to conduct this survey.已有文献表明,七项调查研究 [6, 7, 16, 17, 18, 19, 20] 对药物推荐(MR)领域进行过探究。表1将我们当前的研究与这些综述论文做了对比,以明确本研究的贡献。
其中,Sezgin和Özkan的研究 [6] 是一项相对较早的调查,无法考察基于深度学习的前沿MR模型。由于它仅涵盖了截至2014年的文献,所以只探讨了少数几个基于深度学习的MR模型。该研究没有探究信息因素、基于深度学习的过滤方法,也未针对相关问题给出推荐建议,而且没有涉及数据集和评估方法。
与之相反,Hors - Fraile等人的研究 [16] 通过考察19个医疗保健推荐系统(HRS)的信息过滤和用户画像表示方法,审视了HRS领域。他们主要聚焦于生活方式推荐,对基于深度学习的药物推荐关注极少。他们没能探究基于深度学习的MR模型领域中的信息因素以及所涉及的问题。此外,这项研究只关注期刊文章,但众所周知,多个新颖的MR模型 [5, 21, 12, 22] 已在著名学术会议上被提出,这些都有待分析。该研究仅报道了2007 - 2016年间发表的19个模型,不可否认的是,过去五年中提出的新的基于深度学习的MR模型需要深入研究。
Etemadi、Maryam等人的研究 [7] 是最新的一项工作,对HRS进行了系统综述。这项工作考察了基于信息过滤方法(即基于内容、协同、基于知识和混合式)的系统,还审视了所使用的数据集和存在的问题。然而,和 [16] 一样,该研究侧重于医疗保健推荐模型,对基于深度学习的MR关注不足。此外,这项调查没有依据信息因素、优化方法来考察模型,也未针对模型所面临的问题给出推荐建议。 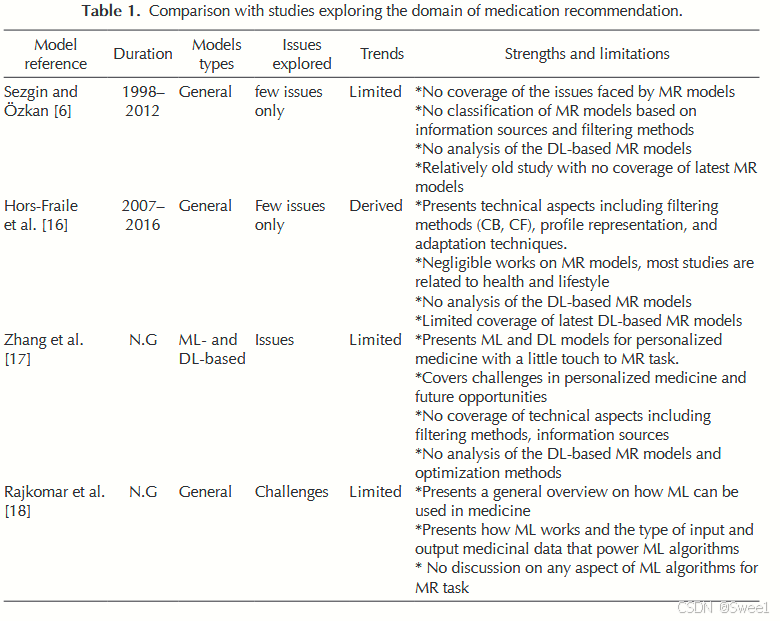
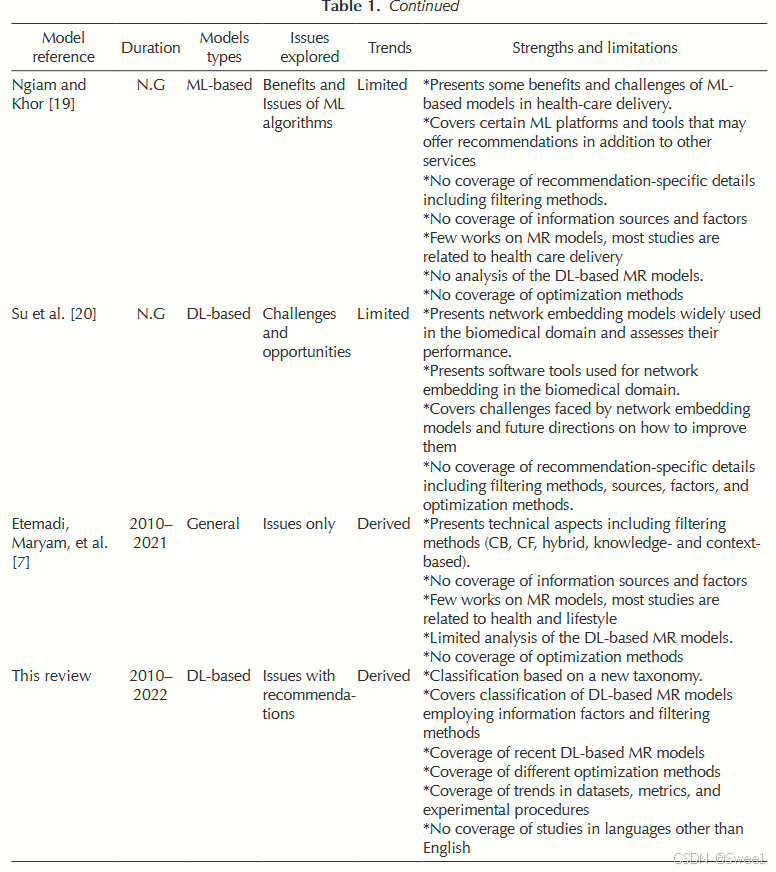
考虑到上述讨论和最近出现的新的基于DL的MR模型,需要进行包容性和全面的分析,以分析该领域,发现有趣的趋势,并突出主要问题。在本研究中,我们对使用DL方法的MR模型的领域进行了探索。
Coverage and contributions本研究全面回顾了基于深度学习(DL)的药物推荐(MR)系统相关文献,介绍了 37 个在 2013 - 2022 年间发表、采用深度神经网络的 MR 模型 。依据平台、所解决的问题、基于 DL 的信息过滤方式、利用的信息因素、采用的优化方法,以及推荐类型(即个性化推荐与非个性化推荐),对这些 DL 模型进行了分类。这一综述为从事基于 DL 的 MR 领域研究的人员提供了参考,报告了基于 DL 的 MR 模型的优势、局限与发展趋势,还指出了该类模型中尚未解决的研究问题、面临的挑战以及潜在的研究机会。
Structure of this article.
本文其余部分共分为四个章节:
第二章:介绍 MR 模型的分类体系,涵盖平台、信息因素、信息过滤方法、优化手段以及推荐类型。
第三章:讲述用于评估这些模型的数据集与评估指标。
第四章:利用不同数据集与评估指标,对所探究模型的实验结果展开比较。
第五章:讨论已提及的基于 DL 的 MR 模型面临的问题、挑战,以及应对这些难题的机会。第五章还会基于本研究得出的主要发现,指明未来方向,以此作为文章的总结。
2. TAXONOMY OF MODELS
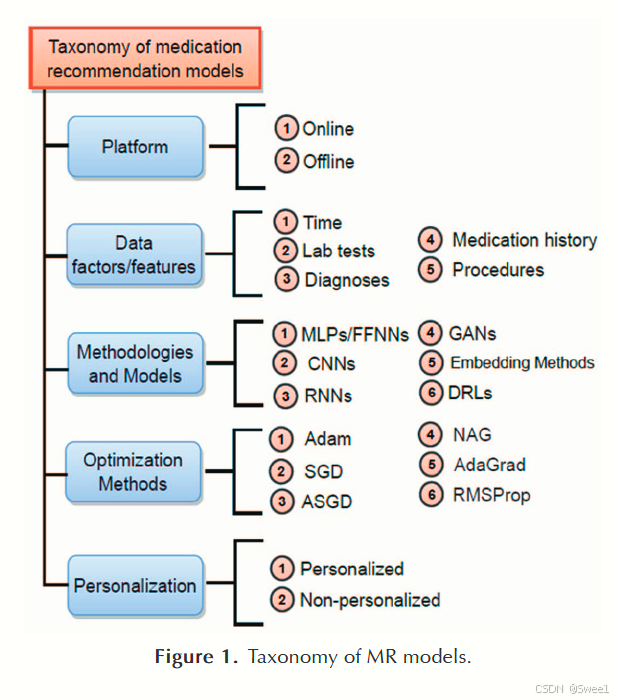
本节通过回顾37项精选的药物推荐相关研究,给出了基于深度学习(DL)的药物推荐(MR)模型分类,如图1所示。这种分类基于多个维度,包括所使用的平台(离线与在线)、考虑的数据特征、采用的深度神经网络、面临的问题与挑战、采用的优化方法,以及推荐类型,诸如个性化推荐和非个性化推荐。以下各小节将介绍这一分类体系。
2.1 Platform
“平台”一词指的是药物推荐(MR)模型是否已部署在真实的在线推荐系统中。这为我们提供了一个线索,即有多少MR研究成果实际应用于实践当中。查看表2便能清楚发现,仅有一个模型[23]被应用于在线系统,其他模型均为离线工作,这表明大多数已提出的模型并未在实际应用中得到使用。 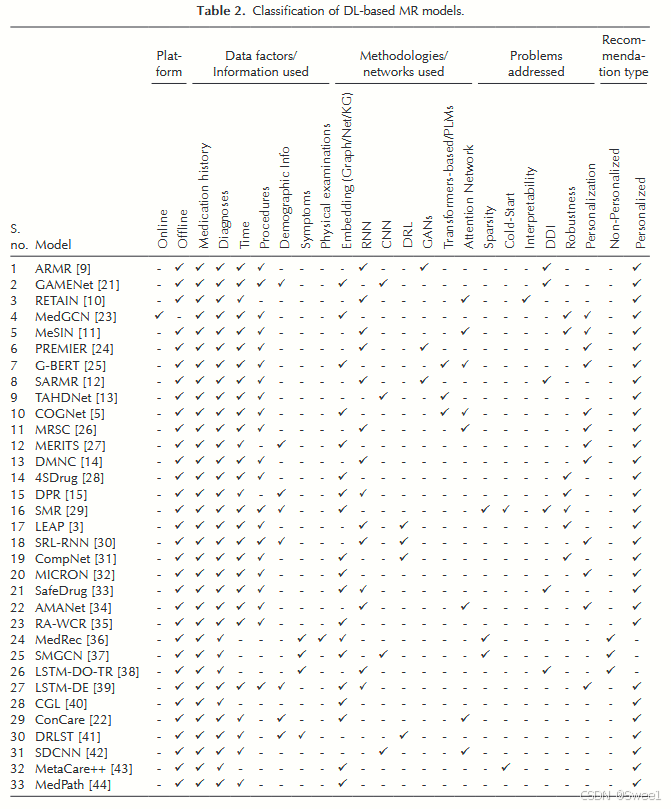
2.2 Information Factors
本节报告了所综述的基于DL的MR模型所使用的信息源和特征。
Medication history准确的用药史为评估某种药物是否适合患者当前的治疗方案奠定了基础,并指导未来的治疗选择。它有助于预防用药处方中的错误,还能避免其他药学问题,诸如未按推荐剂量用药或用药依从性差等情况。这是所探究的用药审查(MRs)模型中采用的最重要因素,37 个模型均采用了该因素。
Time/Temporal dynamics时间是生成用药建议的关键维度之一[49]。患者感觉身体不适时会前往医院,医生在检查实验室检测结果后开药。这种临床实践导致医疗记录的生成并不规律。人们普遍且广泛认为,在预测患者当前健康状况时,患者近期的医疗记录比以往的记录更为重要[22]。然而,即便这些不规则的历史记录,也包含着可能在最新记录中不存在的有价值临床数据,例如血液中极为异常的血糖水平。因此,构建一个具备时间感知且适应性更强的机制至关重要,以便灵活了解每个临床特征的时间间隔所产生的影响。此外,在推荐用药时,还需考虑患者病情以及就医的时间因素。与此需求相符的是,已有文献报道(表2)显示,在37个模型里,有29个模型在推荐用药时运用了时间因素[9, 21, 10, 23, 11, 24, 25, 12, 13, 5, 26, 27, 14, 28, 15, 29, 3, 30, 31, 50, 32, 34, 35, 39, 22, 41, 44, 42, 47, 48] 。
Diagnoses医疗诊断过程有助于确定疾病与患者体征及症状之间的关系。诊断工作需借助一种或多种诊断程序(包括实验室检测)来收集患者的体格检查情况与病史。准确且及时的诊断极有可能为患者带来积极的健康结果,因为对健康问题的正确认知有助于制定出有效的决策[51] 。如表2所示,已有多项研究采用了这一因素。
Symptoms and signs症状是从患者的角度描述疾病,提供主观证据,反映促使患者前往医疗机构就诊的不适主诉;而体征则是医生察觉到的疾病表现。如表 2 所示,仅有少数模型 [37, 38, 41, 36] 采用了这一特征,因为症状可能无法为确诊某种疾病提供有力证据。
Procedure医疗检查程序是一种普遍的医疗干预手段,侵入性较小,无需开刀。例如尿液和血液等体液检测,以及磁共振成像(MRI)、X射线检查、计算机断层扫描(CT)和超声等无创扫描。医疗推荐系统利用这些检查程序数据来做出更精准的预测[5]。表2总结的文献显示,37个模型中有23个在推荐用药时使用了这类数据[9, 21, 10, 11, 24, 23, 25, 12, 13, 26, 5, 27, 14, 28, 15, 3, 29, 30, 31, 47, 48]。
Lab tests and physical examination实验室检测的作用和价值在医疗从业者做临床决策及考量相关临床结果时,得到了广泛认可[52]。这些检测对于疾病的预防、诊断和治疗意义重大,有助于避免治疗延误、促进康复、最大程度减轻残疾以及减缓疾病进展[52]。在体格检查中,医生会检查包括体温、心率、血压在内的生命体征,并通过望、触、叩、听来评估患者的身体状况。从文献分析来看,只有一个模型[36]在预测用药时考虑到了体格检查这一因素。
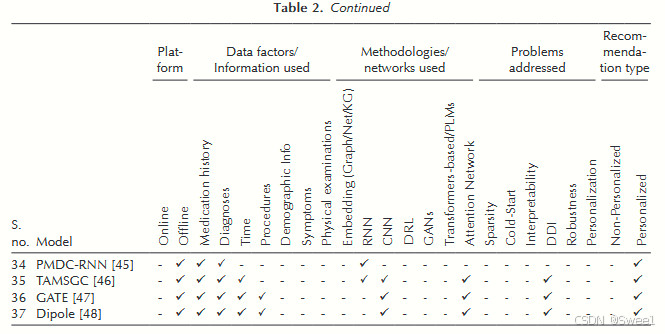
Demographic information人口统计学信息包括患者的性别、年龄、种族、住址、教育程度及其他相关细节。它们在临床决策中发挥着重要作用,例如治疗方案的设计以及剂量的选择。然而,在住院期间,这些信息通常保持不变。图2展示了长短期记忆网络-深度嵌入(LSTM-DE)[39]是如何结合诊断结果、体格检查和处方信息,利用人口统计学信息来推荐药物的。表2显示,只有少数模型[21, 22, 41, 27, 15, 29, 39]在推荐用药时使用了人口统计学信息。
2.3 Methodologies and Models
该部分报告了MR系统使用的各种基于DL的信息过滤方法。
Embedding methods.嵌入方法[53]通过将离散值编码为较低维度来发现连续表示形式。这些方法有不同用途,包括:(1) 作为另一个深度学习网络的输入;(2) 通过利用用户兴趣,基于最近邻生成推荐;(3) 助力可视化概念以及它们之间的关系。嵌入模型分为三类,即词/文档[54]、图/网络[55, 2]和知识图谱(KG)[56]嵌入。
词嵌入在自然语言处理(NLP)中被广泛用于学习单词和短语的潜在表示。到目前为止,人们已经提出了多个词嵌入模型,以捕捉关于单词和短语的丰富句法和语义信息。不过,其中最受认可且应用最广泛的包括word2vec[54]、doc2vec[57]和BERT[58]。它们已被用于将物品、用户、文档和位置[59]嵌入到潜在空间中。
在网络/图嵌入[55, 1]中,网络/图及其节点会被转换为低维表示,这一过程会考虑网络结构、拓扑配置、与节点的关系,以及包括内容和属性在内的其他辅助细节。利用图嵌入方法,可以捕捉节点(药物、患者、检查程序、诊断等)之间有意义的关系,这些关系取决于嵌入空间中的节点间差异[60]。




Deep reinforcement learning techniques.


这在图4中显示,“胰岛素"和"磺胺类药物"之间存在不利的DDI。通过去除"胰岛素”,“糖尿病"得不到治疗,如果去除"磺胺类药物”,"呼吸道细菌感染"得不到治疗。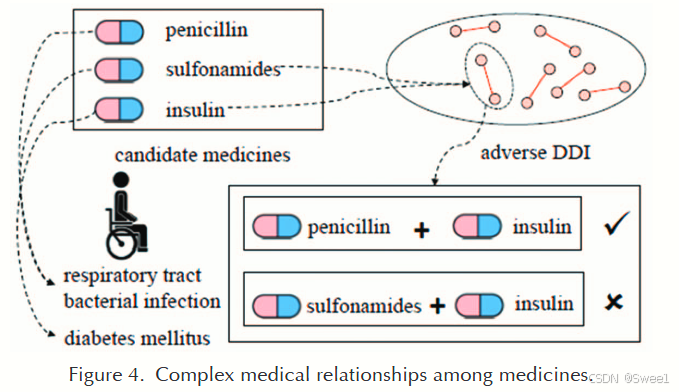


然而,医生的经验有限以及知识差距会导致在监督学习中 “好” 的治疗策略的真实情况不明确,这可能会导致不准确的预测。与 PMDC - RNN 和 LEAP 模型相比,SRL - RNN 由于使用了强化学习来推断最优策略(即使在非最优处方上也能很好地工作),所以能给出更好的预测。根据这项研究,只有四个模型采用了深度强化学习(DRL),其编号为 [30, 31, 41, 3]。
Recurrent neural networks.
Recurrent neural networks。与前馈神经网络不同,循环神经网络(RNNs)使用诸如输入、输出、遗忘等门来保存有用的数据和长期依赖关系[53]。它们与卷积神经网络(CNNs)相近,但通过运用记忆的概念来保存先前学习到的数据,以便在后续操作中使用。这一特性使这些网络适合处理序列数据[71]。它们通过一个定向环路保存先前的数据,并将其反馈到输出中。考虑到问题的性质,它们有许多变体,但门控循环单元(GRU)[72, 73]和长短期记忆(LSTM)[53]被广泛应用。
为了解决传统循环神经网络(RNNs)所遇到的梯度消失问题[72],人们对RNN进行了扩展,引入了门控循环单元(GRU)和长短期记忆网络(LSTM)。其中,LSTM使用输入门、输出门和遗忘门来决定是保留还是丢弃信息。另一方面,GRU利用隐藏状态来传递信息,并采用重置门和更新门,其功能与LSTM的更新门和遗忘门类似,不过重置门是将重要信息传递到下一层。RNN模型及其变体能够捕捉长距离依赖关系和时间动态[72, 74],因此更适用于药物推荐,并被应用于多种模型中。例如,PMDC - RNN[45]通过在患者的诊断记录(即诊断账单代码)上应用一个三层的GRU模型[73]来预测多种药物。然而,由于药物中断或账单代码缺失,它可能会预测出不准确的药物。LSTM - DE[39]是下一个时期的处方预测模型,它使用带有多个隐藏时间序列的异构LSTM来捕捉医疗序列的动态。该模型构建一个隐藏时间序列来对预测序列进行建模,构建其他隐藏时间序列来对体检结果进行建模。相应地,每个隐藏序列分别反映了治疗过程和恢复进展。然后,三个异构LSTM模型利用各种医疗序列之间的相互作用,其中全连接异构LSTM使隐藏状态之间的相互作用保持双向和并行。部分连接异构LSTM保持从隐藏生理状态到治疗隐藏状态的相互作用。在分解的LSTM模型中,体检结果直接作用于治疗隐藏状态。最后,该模型结合隐藏状态中的人口统计学和诊断信息来预测下一次的用药。由于该模型利用了辅助信息源,因此与普通LSTM和其他基准相比,它在受试者工作特征曲线下面积(AUROC)和精确 - 召回曲线下面积(AUPR)的得分上有所提高。
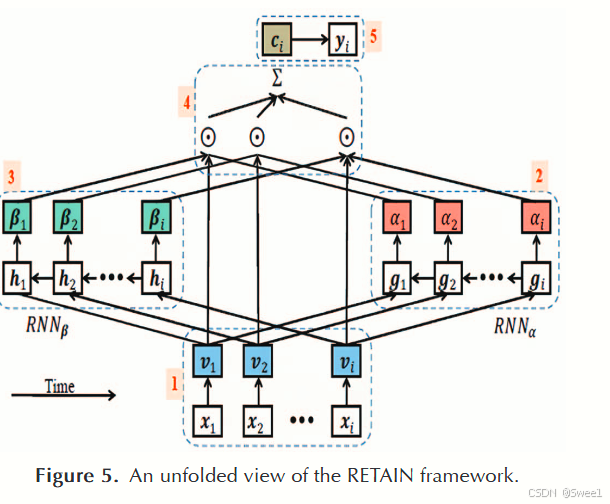
RETAIN模型[10]通过对序列数据采用两级神经注意力机制,解决了解释性问题。它在保持类似循环神经网络(RNN)的预测准确率的同时,还能为预测结果提供详细解读。为了生成更稳定的注意力,它通过逆时间顺序查看患者过往就诊记录,来呈现医生的诊疗行为。如此一来,它能够识别出重要的就诊经历,并量化那些有助于预测的特定就诊属性。由于利用了时间数据,该模型的性能优于基于多层感知机(MLP)的医疗推荐系统(MRS)以及未使用这类数据的普通门控循环单元(GRU) [5]。不过,仅考虑患者病史时,所生成的推荐质量较低[5]。图5展示了其展开后的架构视图。第一步生成嵌入向量;第二步和第三步分别使用
R
N
N
a
RNN_a
RNNa和
R
N
N
b
RNN_b
RNNb生成
α
\alpha
α和
β
\beta
β 值;第四步则利用第三步生成的注意力,依据公式9,为第
i
i
i个患者生成直至第
j
j
j次就诊的上下文向量
c
j
c_{j}
cj 。

其中,
v
i
v_i
vi、
v
i
−
1
v_{i - 1}
vi−1、… 、
v
1
v_1
v1 按逆序表示就诊嵌入,
⊙
\odot
⊙ 表示逐元素乘法。在第五步中,上下文向量
c
j
∈
R
n
c_j \in R^n
cj∈Rn 依据公式10预测真实标签
y
j
∈
{
0
,
1
}
y_j \in \{0, 1\}
yj∈{0,1}。

Le、Tran和Svetha [14]提出了DMNC,它使用记忆增强神经网络(MANN)来解决长期依赖和异步交互的问题。该模型采用了三个神经控制器和两个外部存储器,构成了一个双记忆神经计算机。为了对视图内交互进行建模,每个视图都有自己的控制器和存储器。控制器负责读取输入事件、更新存储器、在每个时间戳从存储器中读取向量,并结合其当前隐藏状态生成输出。视图内交互有两种类型,即早期融合和晚期融合存储器。在编码过程中,由于晚期融合模式使每个视图的存储空间保持独立和分离,这两个存储器之间不会交换任何信息。在解码过程中,存储器的读取值用于生成视图间知识。这里与晚期融合不同的是,视图共享存储器的寻址空间以确保信息共享。这种异步共享是通过将每个时间步的写入值临时保存在缓存中来实现的,以便不同时间步的信息可以同时写入存储器。解码过程在存储器上采用写保护机制来提高推理效率。每个编码器都使用长短期记忆网络(LSTM)将嵌入向量转换为h维向量。尽管DMNC使用了基于注意力的动态神经计算机(DNC)模块,使其能够识别序列之间的交互,但它忽略了历史就诊中的用药情况 [11]。同样,AMANet [34]也忽略了先前开过的药物。不过,它使用多个注意力网络捕捉异构序列的内部和相互相关性,这有助于实现相对更好的性能。
一些模型在推荐药物组合时,忽略了潜在的药物-药物相互作用(DDI),将药物视为相互独立的个体。例如,药物套餐推荐(DPR)模型[15] 在推荐药物套餐时,会考虑受患者病情影响的药物内部相互作用效应。更具体地说,该模型运用了一种预训练方法,即利用协同过滤获取药物和患者的初始嵌入向量。随后,结合领域知识与医疗记录生成一个DDI图。药物套餐推荐(DPR)框架有两种变体,分别是使用加权图的DPR-WG和使用属性图的DPR-AG,在这两种变体中,每一种相互作用分别由分配的权重或属性向量来描述。
在对药物套餐进行嵌入时,掩码层会捕捉患者病情的影响,然后图神经网络(GNNs)执行最终的图归纳。在预训练阶段,多层感知机(MLP)和字符长短期记忆网络(char-LSTM)[75]分别学习疾病文档和入院记录。药物套餐推荐(DPR)模型[15]的表现优于AMANet [34],因为后者无法通过时间序列学习网络捕捉演变信息,包括疾病进展情况,而这些信息对决策来说仍是重要的信息源。同样,MeSIN [11]模型为解决电子健康记录(EHR)数据的复杂性问题(这类数据包含大量患者记录、就诊记录以及连续的实验室检查结果),引入了一个交互式多层选择性网络来推荐药物。该模型使用交互式长短期记忆网络,通过增强的输入门和校准的记忆增强单元,强化EHR数据中多层次医疗序列之间的相互作用。注意力选择模块会依据每次入院时各医疗代码与推荐药物的相关性,为不同的医疗代码表示分配灵活的注意力分数。最后,全局选择性融合模块将来自多个信息源的嵌入整合到患者表示中,以便进行药物推荐。



据作者所述,公式11和13可以利用数据集中的药物组合作为监督来学习,然而,对公式13进行直接监督建模具有挑战性。因此,他们提出分别对药物集的增加和去除进行建模。因此,他们考虑通过无监督和有监督的正则化,从 m ^ ( t − 1 ) \hat{m}^{(t - 1)} m^(t−1)和 m ^ ( t ) \hat{m}^{(t)} m^(t)重构 u ( t ) u^{(t)} u(t)。MICRON与现有的医学推荐(MR)模型(例如,Gamenet [21]和Retain [10])不同,因为它局部地学习序列信息,而后者使用循环神经网络(RNNs)来利用全局序列模式。
ConCare [22]利用自注意力机制来捕捉特征之间的相互依赖关系[76],其中使用固定位置编码来为时间戳提供相对位置信息[77]。它通过使用多通道门控循环单元(GRU)分别对特征的时间序列进行嵌入,如公式14所示:
![[ h_{n,1},\cdots,h_{n,T} = GRU_{n}^{ln}(l_{n,1},\cdots,l_{n,T}) ] (14)](https://i-blog.csdnimg.cn/direct/6cc670a25a5843d08edbbba1081c0e56.png)
其中,特征(n)的时间序列表示为(l_{n} = l_{n,1},\cdots,l_{n,T} \in \mathbb{R}^{T})。这种隐藏表示是对整个时间跨度进行汇总的。为了捕捉每个序列中时间间隔的影响,采用了时间感知注意力机制。注意力函数将查询和一组键 - 值对映射到一个输出[76]。这种隐藏表示产生查询向量和键向量,前者是在最后一个时间步(T)生成的。具体地,这些向量用公式15和公式16来描述:

其中,
q
n
,
T
e
m
b
q_{n,T}^{emb}
qn,Temb和
k
n
,
t
e
m
b
k_{n,t}^{emb}
kn,temb分别是查询向量和键向量,
W
n
q
W_{n}^{q}
Wnq和
W
n
k
W_{n}^{k}
Wnk是获取它们的相应投影矩阵。公式17定义了时间感知注意力权重:
![[ \alpha_{n,1},\alpha_{n,2},\cdots,\alpha_{n,T} = \text{Softmax}(\xi_{n,1},\xi_{n,2},\cdots,\xi_{n,T}) ] (17)](https://i-blog.csdnimg.cn/direct/c8335aef36ce4136b3ac0d47442f5157.png)
其中,
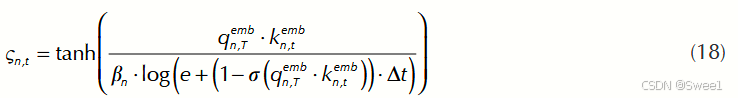
这种对齐模型量化了每个隐藏表示对每个特征的密集汇总表示的贡献。这里, Δ t \Delta t Δt是到最新记录的时间间隔, σ \sigma σ表示sigmoid函数, β n \beta_{n} βn是一个特定于特征的可学习参数,用于控制时间间隔对相应特征的影响。当出现以下情况时,注意力权重 α n , T \alpha_{n,T} αn,T会显著衰减:
- Δ t \Delta t Δt很长,这意味着该值是很久以前记录的。一个特征的最新值(即 Δ t = 0 \Delta t = 0 Δt=0)衰减很小,即 log ( e ) = 1 \log(e)=1 log(e)=1。
- 时间衰减率 β n \beta_{n} βn很高,这意味着只有特定特征的最近记录值才重要。如果一个临床特征的影响持续存在,即 β n \beta_{n} βn,它的衰减会很小。
- 历史记录对当前健康状况没有积极反应,即 q n , T e m b ⋅ k n , 1 e m b q_{n,T}^{emb} \cdot k_{n,1}^{emb} qn,Temb⋅kn,1emb。
所学的权重被用于导出时间感知上下文特征表示,即 f n = ∑ i = 1 T a n , t ⋅ h n , 1 f_{n}=\sum_{i= 1}^{T}a_{n,t}\cdot h_{n,1} fn=∑i=1Tan,t⋅hn,1。此外,人口基线数据被嵌入到相同的隐藏空间中,即 f n ⋅ f b a s e = W b a s e e m b f_{n}\cdot f_{base}=W_{base}^{emb} fn⋅fbase=Wbaseemb,其中 W b a s e e m b W_{base}^{emb} Wbaseemb是一个嵌入矩阵。因此,患者数据由 F F F表示为一系列向量,其中每个向量表示患者随时间变化的一个特征: F = ( f 1 , ⋯ , f n , f b a s e ) F=(f_{1},\cdots,f_{n},f_{base}) F=(f1,⋯,fn,fbase)。通过就诊和静态基线数据捕获动态特征之间的相互依赖关系,而自我注意力机制能够在个人背景下对特征嵌入进行进一步的重新编码。在ConCare的处理过程中,通过查看其他特征线索来尝试更好的编码。此外,它采用多头机制,通过多个表示子空间来改进注意力层。自注意力头有望从不同方面捕获依赖关系。然而,在实践中,它们可能倾向于学习相似的依赖关系[76],因此,通过最小化不同头之间隐藏激活的协方差来采用非冗余或多样化表示[78,79]。采用跨头解相关模块使模型能够关注不同的特征[78]。
RETAIN模型[10]使用两个循环神经网络(RNNs)来学习时间和特征注意力,并结合加权的就诊嵌入进行预测。然而,它缺乏先进的特征提取能力,预测准确性有限[80, 81]。在这方面,Lee等人[82]提出了一种基于医学上下文注意力的RNN,它使用从条件变分自编码器中获得的个体信息。然而,这些研究无法从全局角度探索动态记录和静态基线数据之间的相互依赖关系。另一方面,ConCare能够自适应地捕捉临床特征之间的关系,以便在不同的健康状况下为患者提供个性化的建议。它的表现优于基于位置编码的方法(如SAnD [77]、Transformer - Encoder)和基于注意力的方法(如RETAIN [10]、T - LSTM [74]),这表明从全局角度分别考虑每个特征的时间衰减影响远比直接衰减所有就诊的隐藏记忆要好。研究表明,大量作者使用RNNs及其变体[11, 45, 24, 10, 34, 39, 14, 38, 30, 9, 12, 26, 33, 3, 15, 47, 48]。
Convolutional neural network卷积神经网络(CNN)[83]是一种基于深度学习的模型,与循环神经网络(RNNs)相比,它只需很少的预处理就能产生高效的结果,并且训练所需的内存更少。CNN结构有若干层,包括输入层、卷积层、下采样层、全连接层和输出层,其功能分别是接收输入数据、执行卷积、池化、学习特征间的非线性组合以及产生最终预测。CNN模型创建一个特征图,该特征图被实现为一个非线性函数,并使用公式19计算:
![[ C_i = f(h * x_{i:i + l - 1} + b) ] (19)](https://i-blog.csdnimg.cn/direct/e7f2ddeaf6c848088a1667b238e6a1c6.png)
其中,* 表示卷积运算符。假设一个长度为n的句子有一个原始键
x
1
:
n
x_{1:n}
x1:n,并且一个滤波器(h)应用于词嵌入矩阵
x
1
:
n
x_{1:n}
x1:n,其中
l
(
l
≤
n
)
l (l \leq n)
l(l≤n)是滤波器的窗口长度,
b
∈
R
b \in \mathbb{R}
b∈R是一个偏差。通过这种方式,随着层数的减少,执行成本也会降低。这些类似的操作在各个层上反复进行,以便找到有用的特征,这使得CNN能够作为分类器工作。倒数第二层计算每个项目被分类到每个类别的概率。最后一层使用softmax函数产生最终的分类结果[53]。采用了不同的目标函数,包括交叉熵。
SD_CNN [42]使用CNN [83]框架来学习患者的相似性[84]。该框架通过嵌入层将患者A的独热特征矩阵映射到一个低维稀疏矩阵。对这些矩阵中的每一个都应用最大池化和卷积操作,并将它们的特征向量聚合起来形成一个复合向量。对患者B获取相同的嵌入和CNN参数。通过匹配矩阵和转换层,这些患者的复合向量获得一个相似性特征向量,该向量通过softmax层用于获取他们的相似性概率。另一方面,GAMENet [21]将药物 - 药物相互作用知识图谱(DDI KG)与一个实现为图卷积网络(GCN)的记忆模块相结合,在推荐药物时将患者的纵向记录作为查询。
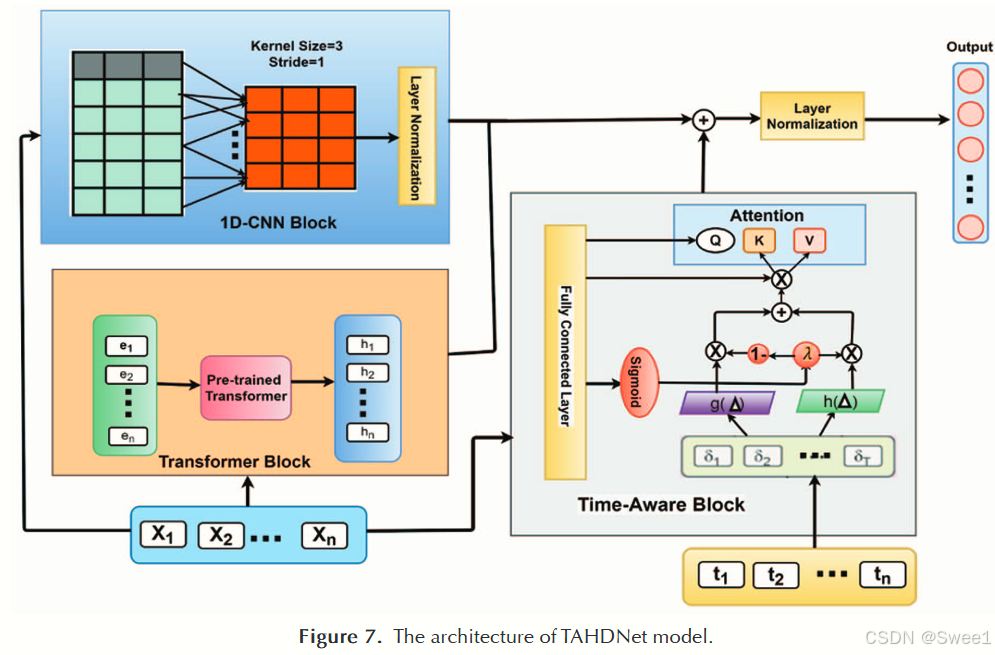
TAHDNET [13]的框架包含三个模块,即一维卷积神经网络(1D - CNN)、变换器(transformer)和时间感知模块。该模型使用1D - CNN处理局部依赖关系,使用变换器处理全局依赖关系,并使用时间感知模块通过动态时间感知注意力来学习基于纵向电子健康记录(EHR)数据(其中每条记录表示为一个多元序列)的层级依赖关系。通过连接这些模块的输出为每个患者生成一个新的表示,然后将其输入到预测层以推荐药物。该模型使用药物 - 药物相互作用(DDI)损失来共同确定最终推荐。它调整变换器结构,并使用一个基于预训练变换器的模块,遵循G - BERT[25]来对考虑整个患者记录的全局依赖关系进行建模。每个患者的输入数据表示为
E
=
(
e
1
,
e
2
,
⋯
,
e
t
)
E=(e_1, e_2, \cdots, e_t)
E=(e1,e2,⋯,et)。然后使用一个预训练变换器来学习医学本体之间的相互作用,即
h
T
=
T
r
a
n
s
f
o
r
m
e
r
(
e
1
,
e
2
,
⋯
,
e
t
)
h_T = Transformer(e_1, e_2, \cdots, e_t)
hT=Transformer(e1,e2,⋯,et),其中
h
T
∈
R
h
^
h_T \in \mathbb{R}^{\hat{h}}
hT∈Rh^是具有全局依赖关系的潜在空间表示。一维卷积神经网络(1D - CNN)模块将一次就诊的多元序列
[
X
1
,
X
2
,
⋯
,
X
T
]
∈
R
T
×
∣
c
∗
∣
[X_1, X_2, \cdots, X_T] \in \mathbb{R}^{T \times |c^*|}
[X1,X2,⋯,XT]∈RT×∣c∗∣作为输入,以学习相邻就诊之间的依赖关系,从而对局部依赖信息进行建模。公式20计算了该过程的嵌入:

其中,
h
c
′
∈
R
h
^
×
∣
c
∗
∣
h_c' \in \mathbb{R}^{\hat{h} \times |c^*|}
hc′∈Rh^×∣c∗∣是1D - CNN’s隐藏层的输出,
h
^
\hat{h}
h^表示其隐藏层大小。
TAHDNET通过在1D - CNN中引入层归一化来避免内部协变量偏移:
h
c
=
LayerNorm
(
h
c
′
)
=
α
⊙
x
−
μ
σ
2
+
ϵ
+
β
h_c= \text{LayerNorm}(h_c') = \alpha \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta
hc=LayerNorm(hc′)=α⊙σ2+ϵx−μ+β
其中
μ
\mu
μ是层的均值,
σ
2
\sigma^2
σ2是方差,
α
\alpha
α和
β
\beta
β分别是用于缩放和平移的参数向量。
在时间感知模块中,TAHDNET引入了一个融合衰减函数来考虑周期性和单调性衰减,然后利用变换器的自注意力机制[76],计算注意力权重并生成时间间隔的潜在空间表示:
ϕ
t
=
Attention
(
Q
,
K
,
V
)
=
Q
K
T
d
k
V
\phi_t= \text{Attention}(Q, K, V) = \frac{Q K^T}{\sqrt{d_k}} V
ϕt=Attention(Q,K,V)=dkQKTV,其中
Q
Q
Q、
K
K
K和
V
V
V是分别由
[
q
1
,
q
2
⋯
q
T
]
[q_1, q_2 \cdots q_T]
[q1,q2⋯qT]、
[
k
1
,
k
2
⋯
k
T
]
[k_1, k_2 \cdots k_T]
[k1,k2⋯kT]和
[
v
1
,
v
2
⋯
v
T
]
[v_1, v_2 \cdots v_T]
[v1,v2⋯vT]组成的矩阵。这些矩阵基于潜在空间表示进行拼接,以生成患者表示
h
′
=
Concat
(
h
r
,
h
c
,
h
1
)
h' = \text{Concat}(h_r,h_c, h_1)
h′=Concat(hr,hc,h1),其中
h
′
∈
R
5
×
h
^
h' \in \mathbb{R}^{5 \times \hat{h}}
h′∈R5×h^。最后,TAHDNET使用一个基于多层感知机(MLP)的预测层来预测MR代码。我们从表2中的观察结果表明,只有三个模型[42, 13, 84]采用了卷积神经网络(CNN)。
Generative adversarial networks.生成对抗网络(GANs)采用无监督学习方法,自动发现并学习数据中的模式或规律,使模型能够输出或生成可能来自原始数据的新样本 [85]。这些模型采用一种智能方法,通过使用包括生成器和判别器在内的两个子模型来训练生成模型。前者生成新样本,后者将它们分类为真实(即来自数据域)或虚假(即生成的)。它们以对抗方式进行训练,直到判别器大约有一半的时间被愚弄,这意味着生成器正在生成合理的样本 [53]。
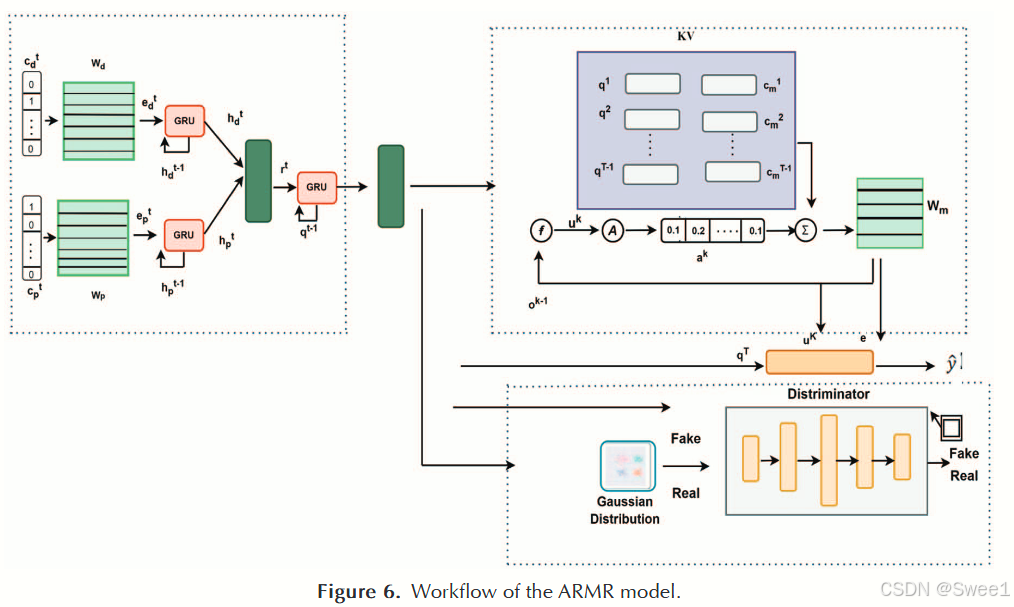
为此,ARM R [9] 模型使用两个门控循环单元(GRU)网络 [71] 构建一个编码器,利用患者的诊断和治疗过程来生成可靠的患者表征。然后,它使用一个键值记忆网络 [86] 来保存历史表征和相关药物作为配对,并对记忆网络进行多跳读取,以从历史电子健康记录(EHRs)中获取基于案例的相似信息,用于更新患者的嵌入。它将编码器和记忆网络 [86] 结合起来构建药物推荐(MedRec)模块。该模型通过将编码器作为生成器与判别器融合来构建一个 GAN 模型,并将 DDI 率小于预设阈值的患者表征视为真实数据,使 GAN 模型能够调整编码器生成的患者表征分布以减少 DDI。MedRec 和 GAN 在每个小批量内联合训练,有两个目标:一个与推荐药物相对应的传统误差准则和一个用于规范分布的对抗训练准则。通过这种方式,ARM R 同时学习有意义的患者表征并规范数据分布以保持低 DDI。
对于患者的第t次就诊,模型通过使用嵌入矩阵
W
d
W_d
Wd和
W
p
W_p
Wp生成对应于操作
c
p
t
c_p^t
cpt的嵌入
e
d
t
e_d^t
edt和
e
p
t
e_p^t
ept,这些嵌入矩阵作为输入提供给两个循环神经网络(RNNs)。然后,模型使用线性嵌入层整合
h
d
t
h_d^t
hdt和
h
p
t
h_p^t
hpt来学习表征
r
t
r_t
rt,该表征通过使用单独的门控循环单元(GRU)单元进行处理,产生最终的嵌入
q
t
q^t
qt。
接下来,模型使用所有
q
t
(
t
∈
[
1
,
T
−
1
]
)
q^t(t\in[1,T - 1])
qt(t∈[1,T−1])构建一个键 - 值记忆网络(KV),其中KV的键是历史表征
q
t
q_t
qt,值是使用相关药物
c
m
′
c_m^{'}
cm′表示的。同时,ARMR使用
q
T
q^T
qT来拟合高斯分布,这为生成对抗网络(GAN)提供了真实数据,而编码器负责生成虚假数据。
在正则化过程中,首先,GAN模型更新判别器以区分真实数据(p(z))和虚假数据
q
f
T
q_f^T
qfT,然后通过更新生成器来混淆判别器,其中用于正则化GAN的成本函数由公式21 [85]定义:
![[ \min \max_{\mathcal{D},\mathcal{G}} \mathbb{E}_{z \sim p(z)}[\log \mathcal{D}(Z)] + \mathbb{E}_{x \sim p(x)}[\log (1 - \mathcal{D}(\mathcal{G}(x)))] ]](https://i-blog.csdnimg.cn/direct/b5d98b018daa4c7b9addd7a49b7d40a8.png)
其中,
D
\mathcal{D}
D和
G
\mathcal{G}
G分别表示判别器和生成器网络。实验表明,与其他竞争基准(如LAEP、DMNC、RETAIN、GAMENet和MedRec)相比,ARM R在药物 - 药物相互作用(DDI)率和药物预测方面取得了更好的结果,因为所提出的模型调节了患者表征的分布,从而提高了性能。
为了应对药物 - 药物相互作用(DDI)的致命副作用,SARM R [12]处理原始电子健康记录(EHRs),以获得特征空间中与药物安全组合相关的患者表征的概率分布。然后,它通过将知识作为真实数据应用,对这些分布进行对抗性正则化,以降低DDI率。该模型将不同DDI率的患者视为不同的群体进行处理和正则化,这样,该模型避免了将他们作为单一群体处理时对泛化产生的不利影响。与SARM R相比,基于循环神经网络(RNN)的基准方法,包括LEAP、RE - TAIN和DMNC,在最大程度地捕捉影响患者健康状态的重要因素方面存在局限性。GAMENet使用额外的DDI知识作为记忆组件来缓解DDI,然而,其对患者和医生之间相互作用的推理能力有限,并且在使用Jaccard和F - score时结果较低。最后,如果我们查看所研究工作的统计数据,我们会注意到这个领域仍需要进一步研究,因为在医学推荐模型(MRMs)中只有极少数模型[24, 9, 12]使用了生成对抗网络(GANs)。
Attention networks and transformer-based models。注意力网络和基于变换器的模型。注意力网络在研究人员中非常受欢迎[87, 88],因为它们通过更多地关注显著信息来产生可靠的推荐[89, 90]。它们在生成可解释和可说明的药物推荐方面取得了成功[91]。为此,RE-TAIN [10]采用了注意力机制和门控循环单元(GRU)[71]来利用序列信息并提高预测的可解释性。特别是,它依赖于一种注意力机制模型来描绘医生在接诊时的行为。为了对医生的行为进行编码,RETAIN以逆时间顺序分析患者的过往就诊记录,从而能够更稳定地生成注意力。因此,RETAIN确定最显著的就诊记录并量化有助于药物预测的特定就诊特征。大多数现有模型,例如PREMIER [24]、GAMENet [21]和SRL - RNN [30],都是从多次就诊的少数患者中提出纵向电子健康记录(EHRs),但忽略了许多只就诊一次的患者,这导致了选择偏差。此外,从推荐角度来看很重要的层次知识,例如诊断的层次结构,在表征学习中并未被考虑。G - BERT [25]通过采用图注意力网络[65]来表示医学代码的层次结构,解决了这些问题。它使用BERT [76]对电子健康记录(EHR)中的每次就诊进行预训练,以便考虑到即使只有单次就诊的患者的EHR数据。它对预训练的就诊和表示进行微调,以便对有多次就诊患者的纵向EHR(就诊次数)进行下游预测。一次就诊是医学诊断代码 C d t C_d^t Cdt和药物代码 C m t C_m^t Cmt的组合,表示为 X t = C d t ∪ C m t X_t= C_d^t \cup C_m^t Xt=Cdt∪Cmt。该模型将之前诊断就诊嵌入、最后诊断就诊嵌入和药物就诊嵌入的平均值进行拼接,并将其输入多层感知机(MLP),通过优化分类交叉熵损失函数来推荐药物代码。实验结果表明,G - BERT在精度、召回率、AUC(PR - AUC)、F1和Jaccard分数方面优于包括RETAIN、LEAP和GAMENet在内的竞争基准。
在这个方向上,COGNet [5]通过一个编码器 - 解码器生成网络来推荐药物组合,该网络会考虑患者的当前健康状况。编码器包含两个基于Transformer的网络[76],它们使用多头自注意力机制对诊断和治疗过程信息进行编码,还包含两个图卷积编码器[63]来对药物之间的关系进行建模。复制模块会根据当前健康状况与之前就诊情况的对比来评估可复用的药物,从而为当前就诊情况开药。一种分层选择机制结合了就诊和药物层面的分数来计算每种药物的复制概率。复制模块的表现优于其他同类模型,包括LEAP、RETAIN、DMNC、GAMENet、MICRON和SafeDrug,因为在临床实践中,针对同一患者的推荐是密切相关的。与COGNet相比,这些基准模型忽略了患者的历史就诊信息。此外,它们没有考虑同一患者的药物推荐之间的关系,也无法捕捉长程就诊依赖性。最后,我们可以注意到近年来有十个模型[11, 42, 10, 34, 22, 25, 26, 5, 47, 48]采用了基于BERT和注意力网络的正向趋势。
Hybrid and other networks。混合网络整合了两种或更多种深度学习方法,以发挥它们各自的内在优势,并缓解它们在生成可靠的药物推荐时可能存在的局限性。例如,由于多个序列的非对齐性质,学习跨视图交互是一项不可避免的挑战。AMANet [34]这一混合模型通过采用三个主要组件来解决这一问题,这些组件包括一个神经控制器,该控制器通过对输入序列进行编码来利用自注意力机制捕获视图内交互。通过采用交互注意力机制来学习视图间交互,这种机制学习的是跨视图交互。为了将位置连接成一个单一序列,要么使用自注意力机制,要么使用交互注意力机制。在这里,视图内注意力获取同一序列中不同元素之间的关系。此外,交互注意力将两个序列中的位置连接起来。具体来说,在交互注意力中,一个输入嵌入项目是查询,另一个则投影键和值。然后通过连接交互注意力向量和自注意力向量来生成序列的编码向量。历史注意力记忆保留同一对象的先前编码向量。动态外部记忆存储关于数据的通用知识,并由所有训练对象共享。预测是通过连接编码向量、读取向量和历史注意力向量生成的。然而,AMANet模型无法充分利用通过时间序列学习网络捕获的疾病进展等演变信息,若能利用这些信息,可能会产生更可靠的推荐[11]。
ARM R [9]模型提出了一个带有两个门控循环单元(GRU)网络[73]的编码器,用于利用诊断和治疗过程来生成患者表征。该模型通过在键值记忆网络[93]中存储历史表征和相关药物来更新患者表征,并通过多跳读取从历史电子健康记录(EHRs)中提取基于案例的相似数据来更新患者表征。这一结果应用于一个由编码器和记忆网络组成的药物推荐(MedRec)模块。该模型将编码器作为生成器与判别器整合来生成生成对抗网络(GAN)模型[85]。GAN模型通过利用药物 - 药物相互作用(DDI)率小于预设阈值的患者表征作为真实数据来塑造编码器生成的患者表征分布,从而减少DDI。MedRec和GAN在每个小批量内联合训练,以获得用于推荐药物的传统误差准则和用于规范分布的对抗训练准则。这种策略使模型能够学习有意义的患者表征,同时保持较低的DDI,从而产生高质量的药物推荐。
避免致命的药物 - 药物相互作用(DDI)是药物推荐中的主要挑战之一。SARM R模型[12]通过处理原始电子健康记录(EHRs)来获取患者对于安全药物组合的表征概率分布,以此来解决这个问题。它通过将知识作为真实数据对患者表征分布进行对抗性正则化来降低DDI。它将具有不同DDI率的患者作为不同的群体进行处理和正则化,以避免将他们作为单一群体处理时可能出现的对泛化的负面影响。
首先,它通过用门控循环单元(GRUs)[73]对EHRs进行编码来模拟患者和医生之间的交互,然后构建一个键值记忆神经网络(KVNN)[93],其中键表示入院情况,值表示相应的药物。其次,它将最近一次入院的表征作为查询,对记忆神经网络(MemNN)[93]的读取结果进行多跳读取,并结合图卷积网络(GCN)[63]嵌入模块。根据更新后的查询推荐药物。
接着,它使用所有患者的记录(不考虑他们的DDI率)来推荐药物,并基于从第一步获得的表征,利用生成对抗网络(GAN)[85]对对抗分布进行正则化,以实现DDI的减少和有效药物组合。最终结果由公式22预测:
![[ \hat{y} = S(g(\left[q^{T}, v^{M}, i\right])) ] (22)](https://i-blog.csdnimg.cn/direct/627747c5772543899cc0ed32f376d2bf.png)
其中
q
T
q^{T}
qT是患者表征,
v
M
v^{M}
vM是多跳读取结果,
i
i
i是加权嵌入的药物,
g
(
.
)
g(.)
g(.)是全连接层,
S
(
.
)
S(.)
S(.)是sigmoid函数。
为了考虑动态处方历史中的连续相关性并理解不规则的时间序列依赖关系,MERITS [27]采用了神经常微分方程(Neural - ODE),以便更好地对连续内部过程进行建模。它采用了一种编码器 - 解码器架构,通过自注意力机制来预测下一个用药序列,并结合静态和动态嵌入,同时利用关于药物和医生经验的知识,通过利用三个图(即顺序图、药物 - 药物相互作用图和共现图)来表示药物顺序关系、冲突和共现情况。编码器有三个模块,即:一个采用自注意力模块[76]和循环神经网络(RNN)来捕捉顺序信息的医学嵌入模块;一个使用神经常微分方程在特定时间戳对不规则时间序列数据进行建模的动态编码模块;以及一个通过聚合顺序用药、静态特征和动态特征来利用简单线性映射对患者状态进行建模的患者聚合模块。编码器通过从不规则采样的时间序列数据中提取用药策略和患者状态来生成患者在当前时间戳的表征。解码器采用用药生成器和图注意力模块。它利用患者表征和在用药历史中建立药物间关系的图来推荐时间戳 t + 1 t + 1 t+1时的用药。
TAHDNET模型[13]通过采用分层学习来捕捉药物与患者在局部和全局层面的依赖关系。图7展示了其架构,由变换器、时间感知和1D - CNN模块组成。它采用1D - CNN [83]来学习患者的局部表征,并通过自监督预训练过程使用基于变换器的学习[25]来学习其全局表征。它通过采用融合时间衰减函数(兼具单调衰减和周期衰减)来进行动态时间感知注意力,从而对疾病进展进行建模,这使得对疾病进展的评估更加符合实际。该模型在性能上优于一些基准模型,如LEAP [3]、RETAIN [10]、G - BERT [25]和GAMENet [21]。在这里,LEAP是基于实例的,其在时间方法上的表现低于RETAIN。这表明了电子健康记录(EHRs)中时间数据的重要性。然而,G - BERT由于没有时间信息,因此无法了解疾病进展信息,这是其性能欠佳的主要原因之一。TAHDNET由于能够从EHRs中尽可能多地提取细节并减少噪声,因此能得到更好的结果。
推荐药物对于有经验的医疗从业者来说是一个耗时的过程,对于没有经验的从业者来说更是容易出错,尤其是在复杂病例中。COGNet模型[5]通过采用基于编码器 - 解码器的生成网络来按顺序推荐合适的药物,从而解决了这个问题。它通过对之前就诊的所有医疗代码进行编码来表示患者的当前健康状况。它通过对第t次就诊的诊断和治疗过程进行编码来表示患者的当前健康状况。它采用一个解码器逐个生成第t次就诊的药物治疗方案代码,以表示患者当前的药物组合建议。解码器在每个解码步骤通过程序、诊断和药物来收集信息,以建议下一个药物。当当前就诊的病症与之前的就诊病症一致时,复制模块会直接从历史记录中复制相关药物。换句话说,复制模块通过比较历史和当前的健康状况,并根据病情变化复制可复用的药物来扩展基本模型,从而为当前就诊开具处方。诊断和治疗过程编码器是基于变换器的网络[76],具有不同的参数。
患者的症状和药物集合定义了药物推荐器的输入,然而,这种输入仍然缺乏能够将这两个实体联系起来的足够细节。MedRec [36]通过在其模型中包含药物及其属性图的知识来解决这个问题,以将药物与症状联系起来。创建了一个关于症状和药物的医学知识图谱(KG),这使得它们的表示更加丰富。这个KG包含四个关键节点,包括体格检查、症状、疾病和药物。一条边连接两个相关节点。例如,一种疾病有特定的症状并需要特定的药物,这三者都通过不同的边相连。属性图模型模拟了药物之间的相互关系。如果两种药物属于同一类别或具有相同的亚分子结构,那么它们是相关的。
在推荐药物时,MedRec首先应用多关系图卷积网络(GCN)[63]来学习实体和关系的嵌入,并使用链接预测任务的目标函数来优化模型。同样,也生成了药物和症状的嵌入。它将注意力机制与每个症状的嵌入相结合,以生成症状表征。MedRec采用GCN [63]来获取属性图的嵌入,该嵌入与医学KG相结合,生成药物的整体表征。最后,它通过学习药物和症状的相互作用来生成预测分数。图8展示了MedRec的架构,显示了它使用属性和医学KGs针对患者症状集推荐带有嵌入矩阵的药物。从数学上讲,对于症状集表征
e
s
c
e_{sc}
esc和药物
M
M
M的嵌入矩阵
e
M
e_M
eM,公式23描述了药物推荐。

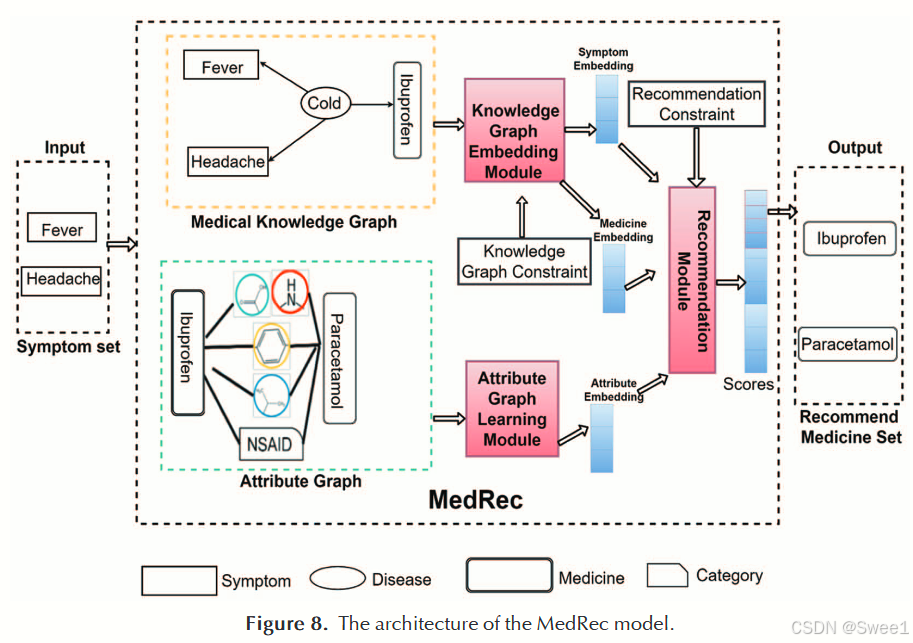
分数(症状集合, 药物)表征了推荐药物时的排名分数。给定症状集合sc,真实集合表示为维度为|M|的多热向量mc,分数(症状集合, 药物)是所有药物的输出概率向量,其均方损失在分数(症状集合, 药物)和mc之间,通过公式24计算。
![[ L_{RS} = \sum_{j = 1}^{|M|} (mc_j - score(sc, M)_j)^2 ] (24)](https://i-blog.csdnimg.cn/direct/4b0af589cb024e75aded2f3b33ede8d7.png)
通常,药物推荐器将药物视为单个项目,因此忽略了将药物作为一组项目进行推荐的独特需求,同时尽可能地保留药物 - 药物相互作用(DDIs)。4SDrug [28]通过对药物和症状进行集合 - 集合比较来解决这个问题,它为药物和症状设计了面向集合的表示和相似性度量。它将药物集合
D
i
D^i
Di和症状集合
S
i
S^i
Si作为输入,并在针对症状推荐药物时采用三个模块。集合 - 集合比较模块采用
h
s
i
h^i_s
hsi表示第
i
i
i个症状集合,
h
D
i
h^i_D
hDi表示第
i
i
i个药物集合,通过面向集合的表示来表示
S
i
S^i
Si和
D
i
D^i
Di,并通过面向集合的相似性度量
g
.
,
.
g_{{.,}.}
g.,.来衡量
S
i
S^i
Si和
D
i
D^i
Di之间的关系。症状集合模块使用基于重要性的集合聚合来重新构建
h
s
i
h^i_s
hsi。
药物集合模块使用基于交集的集合增强和混合药物 - 药物相互作用(DDI)惩罚机制来推荐药物集合,以确保小而安全的药物集合原则。图9展示了这样一个推荐示例,显示两位患者杰克(Jack)和丽莎(Lisa)有相似的症状,如发烧、咳嗽、发冷和头痛,并且患有相同的疾病,即病毒性流感,因此他们将被推荐相同的药物,如布洛芬(Ibuprofen)、氨溴索(Ambroxol)和奥司他韦(Oseltamivir)。这样,无需披露任何个人数据就能从症状判断患者的身体状况[94, 95]。因此,基于症状的药物推荐器可以在药物处方中广泛采用,以避免隐私问题。使用症状集合
S
(
j
)
S^{(j)}
S(j)和药物集合
D
(
j
)
D^{(j)}
D(j)可以分别通过
h
s
(
j
)
h_{s}^{(j)}
hs(j)和
h
d
(
j
)
h_{d}^{(j)}
hd(j)来表示,并使用公式25计算它们之间的相似度,其中
d
i
d_i
di表示训练阶段中的一种药物。
![[ \text{Sim}{h_{s}^{(i)}, h_{d}^{(i)}} = \frac{1}{|D^{(i)}|} \sum_{j = 1}{|D{(i)}|} f{h_{s}^{(i)}, d_j} ] (25)](https://i-blog.csdnimg.cn/direct/ac5b090ba2ab4027a8e4bae3a9d126d4.png)
该模型使用公式26来优化目标函数。
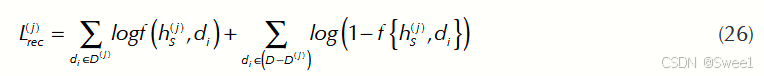
其中,
D
(
j
)
D^{(j)}
D(j)是用于治疗症状
S
(
j
)
S^{(j)}
S(j)的药物。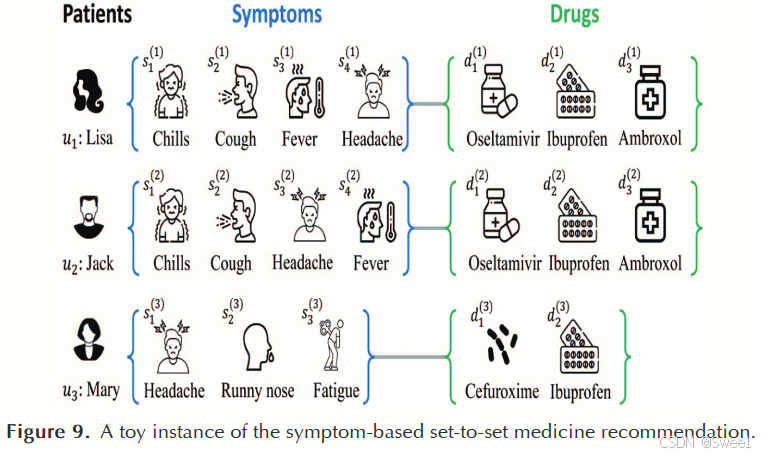
实验结果表明,4SDrug的性能优于包括GAMENet和LEAP在内的其他竞争对手。也就是说,它优于GAMENet是因为后者没有考虑推荐药物的数量,并且产生了不理想的药物 - 药物相互作用(DDI)率,这与当前研究[33]的结果一致。此外,由于4SDrug所需的复杂神经架构相对较少,它能提供更好的计算空间和复杂度,并且与高效的小批量训练兼容。GAMENet [21]由于需要大型存储库而需要更多空间,而LEAP [3]由于采用顺序建模且逐个推荐药物,因此计算复杂。综合考虑这些因素,4SDrug更适合实际的工业应用,因为它更高效且适应性更强。
2.4 Optimization Methods
深度学习模型利用其算法对数据进行泛化,以便能够对未见过的数据进行预测。因此,始终需要找到一种算法,这种算法不仅能做出这样的预测,还能对结果进行优化。所谓优化,是指找到一种方法来确定参数或权重的值,在将输入映射到输出时,这种方法能减少出错的可能性并提高模型的准确性。这种优化能加速训练,并在从数据中学习时有助于提高性能。然而,由于深度学习模型内部有数百万个参数,找到其最优权重具有挑战性。因此,选择合适的优化算法是成功的关键 [96]。本节讨论在使用深度学习算法进行药物推荐时最广泛使用的优化算法。
梯度下降。梯度下降是一种迭代的一阶算法,它试图找到给定函数的局部最小值/最大值[97]。
随机梯度下降。随机梯度下降通过降低计算强度扩展了梯度下降,因为后者每次计算一个点的导数[96]。
动量。梯度下降算法发现穿越峡谷(即不同维度间表面曲线更陡峭的区域,在局部最优值附近最为常见)具有挑战性。为解决此问题,随机梯度下降在向局部最优值试探性前进时会在峡谷的斜坡上振荡。动量扩展了梯度下降,以在合适方向上加速随机梯度下降,并将噪声梯度的振荡降至最低[97, 96]。
RMSProp。均方根传播(RMSProp)是另一种自适应学习率方法,它试图改进AdaGrad [98](AdaGrad采用梯度平方的累积和)。RMSProp采用指数移动平均。两者的第一步相同,但RMSProp将学习率除以指数衰减平均[99]。
Adam。Adam [99, 97]结合了动量和RMSProp的优点,为每个参数计算自适应学习率。它存储先前梯度平方的衰减平均值,并保持与动量类似的过去梯度的平均值。表3显示,大多数模型(即37个模型中的24个)使用了Adam及其变体。使用Adam的可能原因是它能够更快地收敛。梯度下降及其变体排在第二位,有8个模型使用。只有一个模型使用了AdaGrad,而其他模型未提供其优化方法的细节。

2.5 Recommendation Types
药物推荐可以是个性化的,也可以是非个性化的。在第一种情况下,推荐是基于用户档案和个人兴趣做出的。例如,患者的病史、诊断、治疗过程、症状以及与他们就诊相关的时间动态,这些都用于了解他们的医疗状况并生成个性化的预测。非个性化的药物推荐系统只考虑通用特征,不利用与患者相关的额外丰富语义信息。表2显示,大多数模型采用了个性化的方法。
3. EVALUATION METHODS
本部分简要介绍了MR模型在评估其实验结果时所采用的评估方法(数据集和评价指标)。
3.1 Evaluation Metrics
我们详细介绍了药物推荐文献中常用的评估指标。
召回率(Recall):根据相关推荐在其前k个结果中出现的百分比来评估药物推荐(MR)模型的重要性。大多数模型选择k值为{20, 40, 60, 80, 100}。公式27从数学上描述了召回率。
![[ \text{Recall} = \frac{1}{|Q|} \sum_{p \in Q} \frac{R_p \cap T_p}{T_p} ] (27)](https://i-blog.csdnimg.cn/direct/e382ac7e484d48cb8aaa9036fedecc68.png)
其中,Q表示所有目标药物,
R
p
R_p
Rp表示针对种子药物
p
p
p给出的前k个推荐药物列表。
平均精度(Mean Average Precision):通过检查相关药物是否出现在前k个推荐列表中来评估药物推荐模型的重要性。此外,对出现在前k个推荐中的错误进行惩罚。
![[ \text{AP}@k = \frac{1}{k} \sum_{i = 1}^{k} \frac{\text{TP}_{seen}}{i} ] (28)](https://i-blog.csdnimg.cn/direct/d4fa216a46d74bd297aea16cdee66fca.png)
其中,
TP
s
e
e
n
\text{TP}_{seen}
TPseen表示直到k为止的总真正例数。通常,将
AP
@
10
\text{AP}@10
AP@10设置为平均精度(AP)的截断值。
归一化折损累积增益(Normalized discounted cumulative gain):nDCG [100]评估在前N个推荐列表中真实相关药物的位置/排名。它采用分级相关性来评估药物推荐(MR)模型的有效性,使用公式29。
![[ nDCG_g = \frac{DCG_g}{IDCG_g} ] (29)](https://i-blog.csdnimg.cn/direct/e77d88d6e01e41cfa45ec1efc5041e4b.png)
其中,
n
D
C
G
g
nDCG_g
nDCGg表示排名g的累积归一化增益。G是截至位置g的相关药物列表。为确保最相关的药物出现在推荐列表的顶部,定义了推荐药物的相关性程度的加权总和,称为折损累积增益(DCG)。这引出了
I
D
C
G
g
IDCG_g
IDCGg,它表示理想排序的DCG,用于归一化DCG分数。
平均倒数排名(Mean reciprocal rank):分析药物推荐模型在前k个结果中推荐相关药物的能力,并使用公式30计算。
![[ MRR = \frac{1}{|Q_{test}|} \sum_{q \in Q_{test}} \frac{1}{rank_{q}} ] (30)](https://i-blog.csdnimg.cn/direct/4f4e63fa86fc4246a5686a5b357c54c2.png)
其中,
Q
T
Q_{T}
QT是测试集,
r
a
n
k
q
rank_{q}
rankq是其第一个真实药物的排名。
准确率(Accuracy):计算药物预测的优越性,即对下一个推荐药物的正确/错误猜测[101]。公式31计算它。

其中,
∣
D
t
e
s
t
∣
|D_{test}|
∣Dtest∣是测试集,n表示针对查询药物的前n个建议的数量。
F - 度量(F - measure):通过调和平均结合精度和召回率[102]。相比之下,它对推荐药物给出了比准确率更好的评估,并且可以使用公式32计算。
![[ F - Measure = \frac{2 * Precision * Recall}{Precision + Recall} ] (32)](https://i-blog.csdnimg.cn/direct/ce949bb58942416d80c4a8f6f6c5723f.png)
曲线下面积(Area under curve):对于将推荐作为分类任务的药物推荐(MR)模型,会考虑曲线下面积。公式33用于计算它。
![[ AUC = \frac{|{(i, j) | (Rank(p_j)) < (Rank(n_k))}|}{N_p N_n} ] (33)](https://i-blog.csdnimg.cn/direct/4ba513ada7ce4c819707aeb201d9f433.png)
其中,
p
j
p_j
pj表示第
j
j
j个正样本的预测分数,而
n
k
n_k
nk是为第
k
k
k个负样本计算的预测分数。
N
p
N_p
Np和
N
n
N_n
Nn分别代表正样本和负样本的总数。
杰卡德相似性(Jaccard similarity):这是一种常见的邻近度量,用于计算两个节点/向量之间的相似性。它使用公式34定义,即真实结果(Y^t)与预测结果
Y
^
t
\hat{Y}^t
Y^t的交集与
Y
t
Y^t
Yt和
Y
^
t
\hat{Y}^t
Y^t的并集的比率,其中
N
N
N是患者总数。
![[ Jaccard = \frac{1}{N} \sum_{t = 1}^{N} \frac{|Y^t \cap \hat{Y}t|}{|Yt \cup \hat{Y}^t|} ] (34)](https://i-blog.csdnimg.cn/direct/f4d206633b834d40b1448e7bdf3d077f.png)
药物 - 药物相互作用(DDI)率:衡量模型的用药安全性,定义为包含DDI的药物推荐的百分比。
![[ \text{DDIRate} = \frac{\sum_{k = 1}^{N} \sum_{t = 1}^{T_k} \sum_{i, j} |{(c_{r, i}, c_{r, j}) \in \hat{Y}^{(k)} | (c_{r, i}, c_{r, j}) \in \epsilon_{D D I}}|}{\sum_{k = 1}^{N} \sum_{t = 1}^{T_k} \sum_{i, j} 1} ] (35)](https://i-blog.csdnimg.cn/direct/698ed76baa034bde9cfc108d94fcdb2f.png)
其中,若药物对
(
c
i
,
c
j
)
(c_{ i}, c_{ j})
(ci,cj)属于DDI图的边集
ϵ
D
D
I
\epsilon_{D D I}
ϵDDI,则在推荐集
Y
^
\hat{Y}
Y^中对每对药物进行计数。这里(N)是测试数据集的大小,
T
k
T_k
Tk是第
k
k
k个患者的就诊次数。
表4报告了最广泛使用的指标是F - Score(37个中有24个)和AUC(37个中有23个),这表明研究人员对生成准确的药物预测更感兴趣。其次是Jaccard(37个中有20个),这表明相当多的药物推荐(MR)模型将推荐视为分类问题。接着是DDI率(37个中有13个)和召回率(37个中有11个)。此外,大多数模型采用了多种指标的组合。
分类或排名准确性度量用于优化推荐,目的是为患者找到最相关的药物。大多数报告的药物推荐模型使用不同类型的准确性度量,包括覆盖范围和精确度(召回率、精确度)、基于排名的度量(nDCG或MRR)以及预测度量(RMSE)。最后,我们注意到大多数模型(37个中有21个)使用了三种或更多的评估指标,这表明基于多种指标的评估使药物推荐模型的实验更加稳健。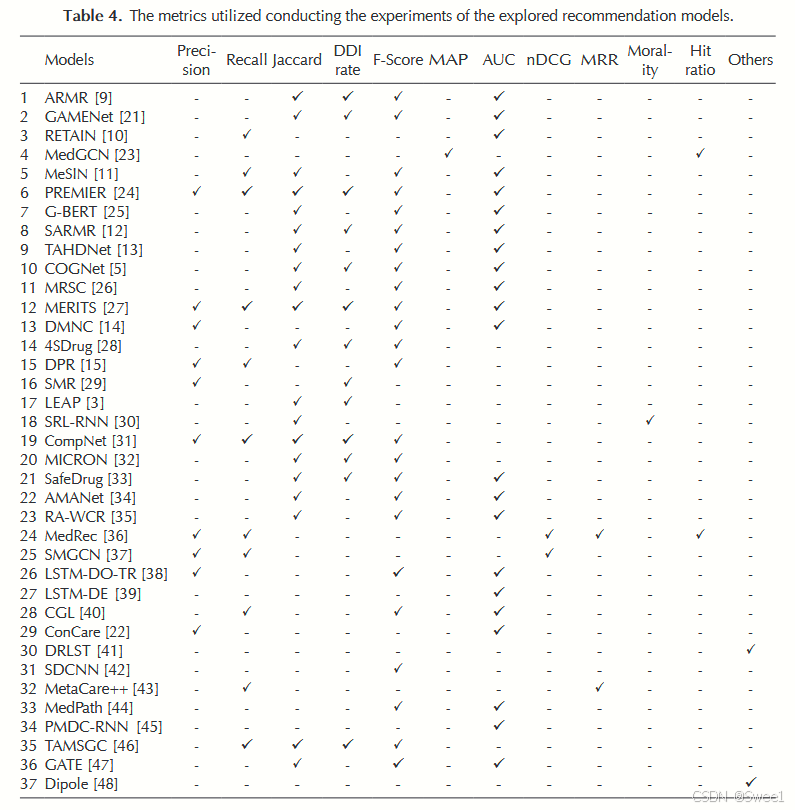
3.2 Datasets
表5报告了最广泛使用的药物推荐数据集。本节对这些数据集进行简要概述,以便研究人员能够为他们的实验选择合适的数据集。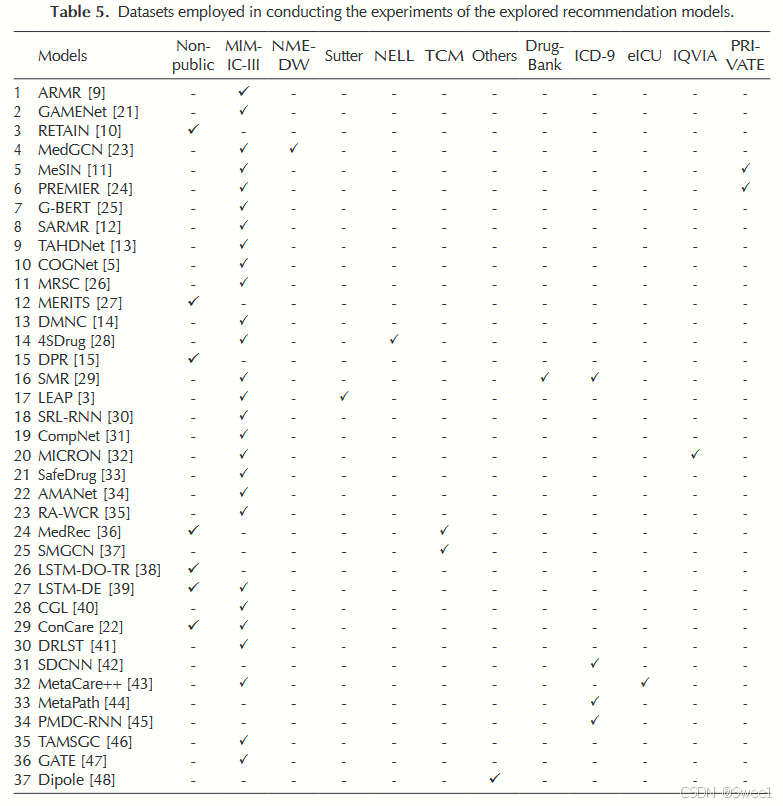
MIMIC - III:重症监护医学信息数据库(MIMIC - III)是最丰富的数据集,由麻省理工学院(MIT)的计算生理学实验室开发,提供了包括患者、诊断记录、临床事件、治疗过程、药物和症状在内的信息来源。因此,大多数模型(即37个模型中的24个)使用了这个数据集[9, 21, 23, 11, 24, 25, 45, 13, 5, 14, 28, 29, 103, 41, 46]。
NELL:NELL [104]是最新发布的数据集,仅被一个模型使用。该数据集提供了诸如2, 78, 388个临床事件和230种药物等信息来源。
ICD - 9:国际疾病分类第9版(ICD - 9)是诊断和治疗过程的官方标准代码。它以表格形式包含13000种疾病代码。这些代码规定每种疾病都有一个唯一的代码,并用于电子健康记录(EHR)的计费机制。有几个模型使用了基于ICD - 9的数据集[29, 42, 44]。
eICU:eICU [43]是一个协作研究数据库,其中存储了入住重症监护室(ICU)的危重患者的去标识化健康记录。该数据集中包含了不同的信息因素,如诊断、生命体征、护理计划、疾病严重程度和治疗信息。eICU数据集包含了全美超过200,000名患者的数据。该数据集是免费提供的,并被不同应用领域的许多研究团体广泛使用。
专有和非公开数据集:一些研究开发了专有和非公开数据集来评估他们的药物推荐(MR)模型。表5报告了六个模型使用了此类数据集,这使得研究人员难以将这些模型的结果与其他模型进行比较[10, 27, 15, 36, 39, 22]。其他一些被探索模型采用的数据集包括Sutter [3]、中医(TCM)[36, 371]、DrugBank [29]、IQVIA [90]和PRIVATE [11, 24]。由于这些数据集只能获取有限的信息来源,因此只有少数研究使用。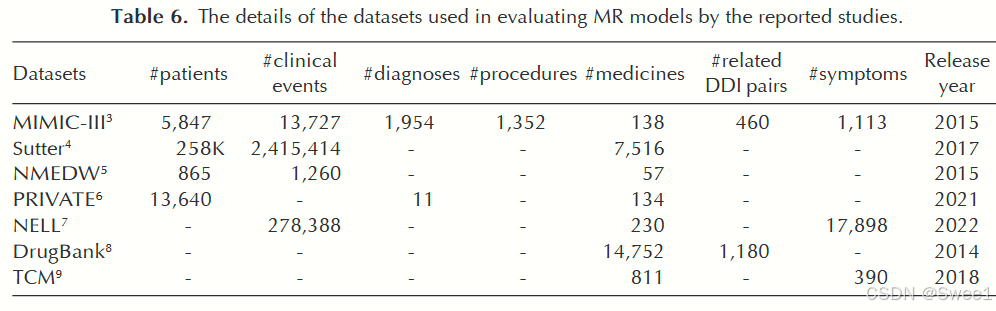
4. COMPARATIVE ANALYSIS OF THE EXPERIMENTAL RESULTS OF THE MODELS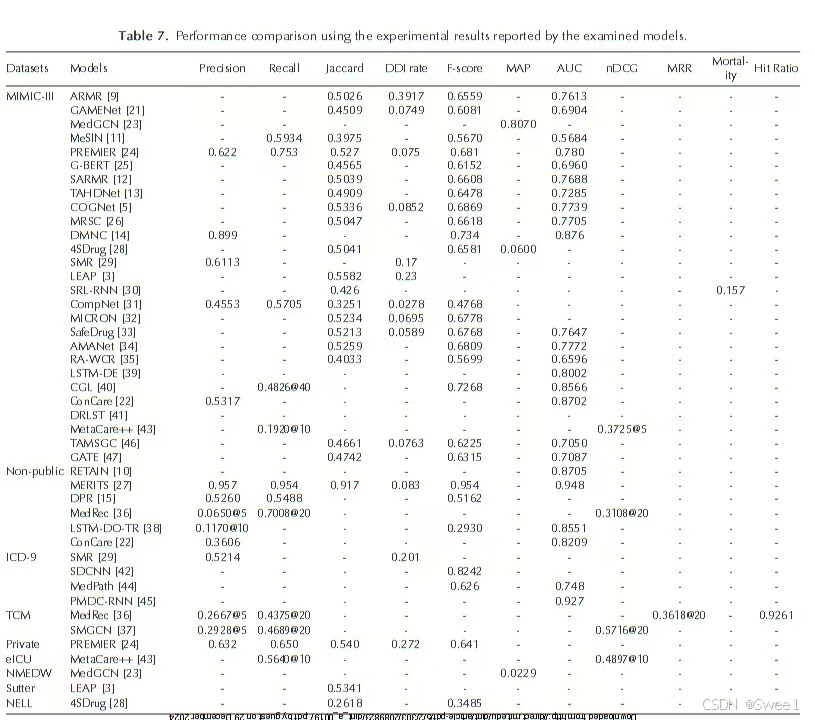
本节致力于比较被检验模型使用不同评估指标和数据集所生成的实验结果。如果我们查看表7中使用MIMIC - III数据集的模型结果,在MIMIC - III上表现最佳的是DMNC [14]。DMNC之所以能取得最佳性能,是因为它引入了一种新的记忆增强神经网络模型,旨在对两个异步顺序视图之间的复杂交互进行建模。DMNC使用两个编码器对两个外部存储器进行读写操作,以对输入视图进行编码。在编码过程中,通过使用存储器来捕获视图内交互和长期依赖关系。DMNC [14]系统中有两种存储器访问模式:后期融合和前期融合,分别对应后期和前期视图间交互。在后期融合模式下,两个存储器是分离的,仅包含特定于视图的内容。在前期融合模式下,两个存储器共享相同的寻址空间,允许跨存储器访问。在这两种情况下,来自存储器的知识将由解码器组合,以便对输出空间进行预测。
性能第二好的是COGNet模型[5],因为它利用基于编码器 - 解码器的生成网络按顺序推荐合适的药物。它通过对之前就诊的所有医疗代码进行编码来表示患者的历史健康状况。它通过对患者就诊的诊断和治疗过程代码进行编码来表示患者的当前健康状况。它采用一个解码器逐个生成就诊的药物治疗过程代码,以表示患者当前的药物组合建议。解码器通过治疗过程、诊断和药物收集信息,以便在每个解码步骤中推荐下一种药物。如果当前就诊的疾病与之前的就诊疾病一致,复制模块会立即从历史用药组合中复制相关药物。
诊断和程序编码器是基于变换器的网络[76],具有不同的参数。在这个数据集上,表现第三好的是PREMIER [24]模型。PREMIER [24]是一个两阶段推荐系统,包括基于注意力的循环神经网络(RNN)来对患者就诊进行建模,以及图网络来对电子健康记录(EHR)中的药物共现和已知的药物相互作用进行建模。PREMIER采用图注意力网络(GAT)来结合药物相互作用的不同重要性,以学习用于药物推荐任务的有效药物嵌入。PREMIER [24]通过提供诊断、程序和先前开具的药物之间的贡献百分比来解释推荐特定药物的关键原因。
相反,与其他基于精度、召回率、F - 分数和AUC指标的模型相比,MERITS [27]模型在非公开数据集上产生了更优的结果。这归功于它使用神经常微分方程(Neural ODE)来表示不规则的时间序列依赖关系,能够更好地学习连续的内部过程。此外,它通过自注意力机制结合静态和动态特征,并使用编码器 - 解码器架构来预测下一个用药序列。同样,基于中医(TCM)数据集,在精度和召回率指标方面,SMGCN [37]比对应的MedRec [36]产生了更好的结果。SMGCN结果改进的可能原因是它结合了多层感知器(MLP)和图卷积网络(GCN),将症状表示融合到整体的隐式综合征嵌入中,并分别学习症状和草药表示。另一方面,MedRec使用知识图谱来连接症状、疾病、药物和检查。利用相似的特性和分子结构,使用属性图来连接多种药物。然后将症状和药物的联合学习表示用于药物推荐。
最后,如果我们查看在其他数据集(即Private、eICU、NMEDW、Sutter和NELL)上报告的结果,我们无法得出有意义的结论,因为这些数据集都只有一个模型用于报告其性能。
5. OPEN ISSUES AND OPPORTUNITIES
本部分报告了所选择的MR方法所面临的问题,并通过考察本文的研究提出了解决这些问题的研究机会。
5.1 Cold-start Problem
药物推荐(MR)方法遇到的一个众所周知的问题是“冷启动”问题[53],它进一步分为冷启动患者和冷启动药物。在这些情况下,由于对患者和药物缺乏足够的了解,该方法无法提供可靠的药物推荐。例如,当出现一名新患者时,系统没有足够的患者信息,因此无法做出合理的推荐。为了解决冷启动问题,大多数模型都采用了用药历史、时间、诊断和治疗过程。例如,SMR [29]首先将医学知识和电子病历(EMR)图相连接,以构建一个更优的异构图。然后,该方法在一个常见的低维空间中对患者、疾病、药物及其相关关系进行编码。最后,为了将药物推荐构建为一个链接预测任务,SMR还考虑了患者对药物不良反应的诊断。同样地,MetaCare++ [43]引入了一种元学习技术来解决冷启动诊断任务,该技术动态地预测不常见患者的未来诊断和时间戳,并将疾病随时间进展的影响明确编码为一种先验泛化。
5.2 Sparsity
这个问题在协同过滤(CF)技术中最为常见[8],当数据集或患者信息稀疏时,一些药物推荐(MR)模型会面临此问题。由于缺乏信息,该方法难以给出相关的推荐。如果数据库中的药物数量相对少于患者数量,那么药物推荐模型就会面临网络稀疏性或数据稀疏性问题。研究表明,通过采用辅助信息可以解决稀疏性问题。在网络稀疏性问题的情况下,辅助信息通过扩展与新对象和关系的连接网络来增强药物推荐模型对患者的了解。例如,新节点表示药物、患者、疾病、症状和实验室检查之间的关联。本研究中调查的大多数方法都采用了将协同过滤和基于内容(CB)相结合的混合策略来解决数据稀疏性问题。它们之间的主要区别在于用于生成个性化药物推荐的深度学习技术。对于推荐草药的任务,SMGCN [37]使用多层神经网络模型来模拟症候与草药之间的相互作用。然后使用多层感知器(MLP)将目标症候集中的症状表示进行组合,以生成整体隐含症候表示。该模型将症候表示与草药嵌入相结合以产生最终预测。
同样地,MedRec [36]使用知识图谱来连接药物、疾病、检查和症状。此外,它还通过属性图利用共同的分子结构和属性将药物联系起来。结果,这两个图改善了症状与治疗之间的关系,解决了数据稀缺的问题。
5.3 Drug-Drug Adverse Interactions
推荐模型应认真考虑药物之间的相互作用。如果一个模型推荐的药物存在不良相互作用,那么这可能会对患者的健康造成严重损害。文献中的不同模型提出了应对这一问题的解决方案。例如,GAMENet [21]使用一个作为图卷积网络(GCN)实现的记忆模块来整合药物 - 药物相互作用(DDI)知识图谱,该模块对患者的纵向记录进行建模,以生成安全且个性化的药物推荐。同样,4SDrug [28]引入了一个药物集模块,通过设计基于交集的集合增强、基于知识和数据驱动的惩罚机制,来确保推荐出规模小且安全的药物集。COGNet [5]使用一个基础模块,基于编码器 - 解码器架构,依据患者当前就诊的健康状况来推荐药物组合。此外,为考虑患者过往的就诊信息,该模型引入了一个复制模块,该模块会比对当前健康状况与过往就诊情况,在考虑健康状况变化的前提下,从过往就诊记录中复制可复用的药物,用于当前就诊的处方开具。一种分层选择机制结合就诊层面和药物层面的分数,来计算每种药物的复制概率。相比之下,ARMR [9]首先利用循环神经网络(RNN)生成患者表征,并采用键值记忆系统来存储历史表征及相关药物。因此,在药物推荐时,可以采用基于案例且带有相关结果的方法。为减少DDI,ARMR整合了一个生成对抗网络(GAN)模型,将患者表征的分布与先前的高斯分布对齐。MedRec组件和GAN模型则在小批量数据中以双重目标反向训练。大多数现有技术为解决DDI问题,会添加更多DDI知识,这反而给模型带来了阻碍。为克服这一问题,SARMR [12]从原始患者记录中提取与更安全药物组合相关联的目标分布,用于对抗正则化。通过这种方式,该技术能够改变患者表征分布,从而减少DDI。SafeDrug [33]具有很强的灵活性,它自适应地合并有监督损失和无监督的DDI约束。具体而言,在训练期间,如果单个样本的DDI率高于特定阈值/目标,负面的DDI信号将被突出显示并反向传播。
5.4 Capturing Temporal Dynamics
患者近期的健康状况和检查结果对于精准推荐药物起着至关重要的作用。此外,像流感这类疾病,依赖于患者近期的临床记录。而另一方面,诸如心血管疾病等某些疾病,则需要患者过往的记录来提供有价值的信息,以助力精准推荐预测。为此,RETAIN [10] 通过计算在时间 t 时一次就诊的注意力权重来预测未来诊断,该计算会考虑当前就诊的医疗信息以及时间 t 时循环神经网络的隐藏状态,从而预测时间 t + 1 的就诊情况。然而,它忽略了从时间 1 到 t 的所有就诊之间的关系。Dipole [48] 通过将高维医疗代码嵌入到低代码层级空间来处理这一问题。随后,这些代码表示被输入到一个基于注意力的双向门控循环单元(GRU)[71] 中,利用一个softmax层来生成隐藏状态表示,进而预测未来就诊的医疗代码。
另一方面,Concare [22] 提出了一种多通道医学特征嵌入架构,通过独立的GRU学习各类特征序列的表示,并使用时间感知注意力自适应地捕捉记录间时间间隔的影响。同样地,MeSIN [11] 采用了一种交互式时间序列学习网络,将单个医疗序列内多次就诊的内部相关性,以及电子健康记录(EHR)数据不同序列间的相互相关性整合起来。具体而言,改进后的实验室检查结果嵌入被输入到时间序列学习网络,即长短时神经网络(LSTM)中,以便与历史实验室结果相结合。为了给预测任务提供更精准的表示,TAHDNet [13] 融入了一个时间感知模块,以反映不规则的时间间隔。具体来说,利用一个间隔门融合两个衰减函数,以便同时考虑周期性衰减和单调衰减。
5.5 Personalized Patient’s Modeling
患者的医疗需求会随时间推移而发生变化。特别是,患者此次去医院可能是为了治疗流感,但下次就诊或许是为了医治肠胃问题。因此,利用这类动态变化的因素来捕捉患者近期的医疗需求十分关键。为此,ConCare [22] 运用多头自注意力机制,明确提取临床特征之间的依赖关系,以此学习个人健康背景,并在该背景下重新生成特征嵌入。通过跨头去相关性操作,鼓励各注意力头之间的多样性。采用多通道医学特征嵌入架构,借助独立的门控循环单元(GRU)学习不同特征序列的表征,并利用时间感知注意力自适应捕捉各特征记录之间时间间隔的影响。
同样地,G-BERT [25] 分别使用图卷积网络(GCN)[63] 和双向编码器表征变换器(BERT)[58] 来学习医疗代码表征与药物推荐。具体而言,该方法将图神经网络(GNN)表征整合进基于变换器的就诊编码器,并使用单次就诊患者的电子健康记录(EHR)数据对其进行预训练。为解决异步多视图学习问题,AMANet [34] 将注意力机制与记忆相结合。利用自注意力和互注意力机制,分别学习视图内交互与视图间交互。特定对象的信息由历史注意力记忆进行维护,并作为本地知识存储系统使用。与之相反,动态外部记忆用于保存每个视图的全局知识。MERITS [27] 使用神经常微分方程(Neural ODE)捕捉不规则的时间序列依赖关系。同时,该模型运用药物 - 药物相互作用(DDI)知识图谱以及两个学习到的药物关系图谱,来探究药物的共现与顺序相关性。它还应用基于注意力的编码器 - 解码器框架,整合来自电子病历(EMR)的患者与用药历史信息。
最后,ARMR [9] 模型使用两个门控循环单元(GRU)网络 [71] 构建编码器,利用患者诊断信息与治疗过程生成可靠的患者表征,这些表征将用于生成最终预测。
6. CONCLUSION AND IMPLICATIONS
本文探讨了基于深度学习(DL)的药物推荐(MR)模型,涉及平台、信息过滤、信息特征与因素、推荐类型、评估方法(包括数据集和指标)、这些模型面临的问题以及解决这些问题的机会。以下几点总结了本研究的一些主要发现:
•所研究的大多数模型在为患者进行个性化药物预测时,都将用药历史、诊断结果、时间和治疗过程作为数据因素,这些都是重要方面。此外,采用辅助信息(如用药历史、诊断结果、时间、治疗过程、症状和体检)的模型能够提供精确的推荐,并缓解稀疏性问题,因为这些技术利用了丰富的信息并丰富了对患者疾病的了解。
•在基于深度学习的药物推荐方法中,基于嵌入的方法最为常见,因为它们能够利用多种信息来源并捕捉用户偏好动态。由于循环神经网络(RNN)在自然语言处理(NLP)任务中的良好表现以及对长程依赖的捕捉能力,它们紧随其后。在考虑患者健康随时间变化的药物推荐领域,它们也很有用。卷积神经网络(CNN)的变体也很有用,因为它们能够利用上下文细节并捕捉局部相关特征。
•最近,基于注意力网络的Transformer模型越来越受欢迎,因为它们能够捕捉关于患者和药物的重要信息因素和特征,并考虑它们之间的复杂关系。我们发现37个药物推荐模型中有10个采用了Transformer来推荐药物。
•根据研究结果,大多数模型(37个中有24个)采用了Adam优化技术,而8个模型使用了梯度下降。有一个模型采用了Adagrad。同样,37个模型中有1个使用了RMSProp。使用Adam和随机梯度下降(SGD)的可能原因是它们相较于其他方法具有更好的收敛和泛化能力。
• 所研究模型面临的主要问题是个性化、利用时间动态和药物 - 药物相互作用(DDI)。由于缺乏关于患者疾病的足够信息,一些模型在稀疏性和冷启动问题上存在困难。所研究模型中最不被探索的是可解释性。根据研究结果,嵌入方法和RNN在更好地解决个性化、鲁棒性和DDI问题方面表现较好。主要原因是嵌入方法在电子健康记录(EHR)网络中利用了强大的语义关系。此外,RNN能够更好地捕捉长程依赖并在NLP任务中表现良好。相反,调查表明图/网络嵌入方法更好地解决了稀疏性和冷启动问题。主要原因是图卷积网络(GCN)将疾病、症状、药物、患者及其对应关系嵌入到一个共享的低维空间中。
•MIMIC - III数据集包含丰富的信息来源,即患者信息、诊断记录、临床事件、治疗过程、药物和症状。结果发现,MIMIC - III数据集是药物推荐领域最常用的数据集。一般来说,其他数据集仅被少数模型使用。例如,NELL是最新发布的数据集,且仅被一种方法使用。
我们希望本研究中确定的研究方向将有助于研究人员探索新兴趋势并设计出鲁棒的药物推荐系统。
ACKNOWLEDGMENTS本项目由东南大学-中国移动研究院联合创新中心资助,批准号:CMYJY - 202200475。


















 4883
4883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











