







InstructRAG: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationales
InstructRAG: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationales | OpenReview
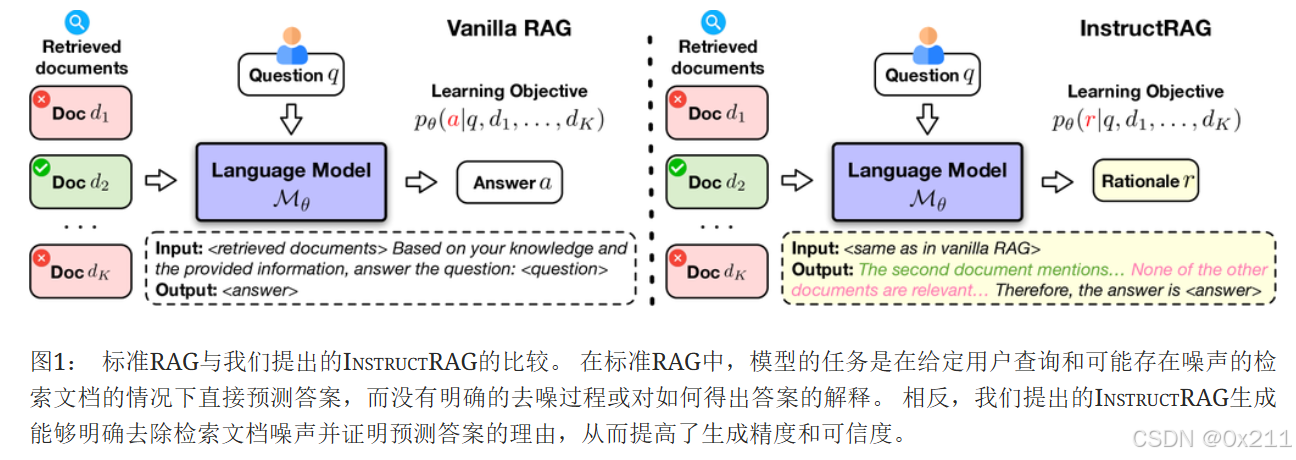
常规的RAG系统就是简单地把检索结果扔进去,获得一个输出,没有明显的去噪过程,并且没有对答案进行一个解释。InstructRAG方案生成能够明确去除检索文档噪声并且证明预测答案的理由。
不完美的检索器或嘈杂的语料库可能会将误导性甚至错误的信息引入检索到的内容,这对生成质量构成重大挑战。现有的 RAG 方法通常通过直接预测最终答案来应对这一挑战,即使输入可能存在噪声,这导致了一个隐式的去噪过程,难以解释和验证。另一方面,获取显式去噪监督通常成本很高,需要大量人力。
引入了一个新的RAG框架,InstructRAG,它使LLM能够显式地去除检索信息的噪声,并通过生成去噪响应(即,基本原理)来证明其预测的最终答案
InstructRAG不需要任何额外的监督,同时具有更高的生成精度和可信度
两个步骤。 首先,给定一组问题-答案对和可能存在噪声的检索文档,我们提示一个指令调优的LLM来合成去噪的基本原理,这些原理分析文档并阐明它们如何得出真实答案。然后,这些合成基本原理可以作为上下文学习示例或作为监督微调数据,使LLM能够显式地学习去除检索内容的噪声。 InstructRAG 的有效性可以归因于LLM强大的指令遵循能力,这是一个在RAG环境下仍然未被充分探索的重要特征。这种自合成的基本原理不仅为领域内RAG任务提供了高质量的显式去噪监督,而且促进了更好的领域外泛化。 这一发现强调了指令调优的LLM如何合成可泛化的监督来克服RAG中不可避免的噪声。
贡献:(1) 我们提出了InstructRAG,这是一个简单而有效的RAG框架,它允许LLM通过生成基本原理来显式地去除检索内容的噪声,从而提高可验证性和可信度。 (2) InstructRAG是一种自合成方法,与标准RAG方法相比,它不需要额外的监督,并且可以无缝地应用于上下文学习和监督微调设置。 (3) InstructRAG始终优于最先进的RAG方法,与五个知识密集型基准测试中最好的基线方法相比,平均相对改进率为8.3%。 广泛的分析和消融研究进一步证实了自合成去噪基本原理的优越性,并证明了InstructRAG在各种无训练和可训练场景中强大的去噪能力和强大的任务迁移能力。
InstructRAG
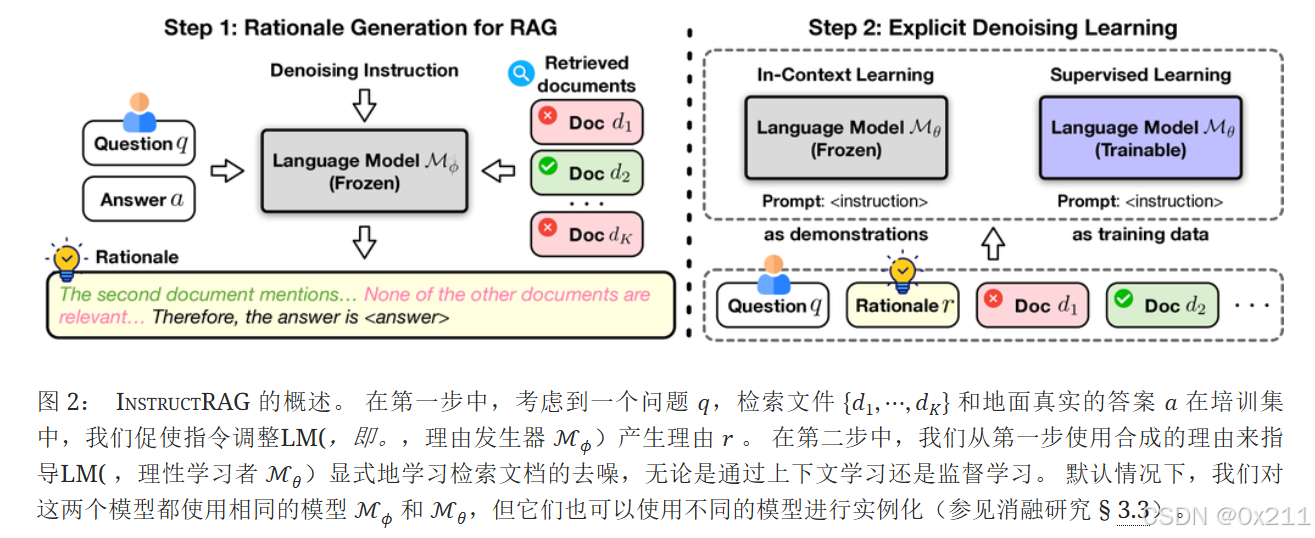
我们的方法包括两个步骤。
提示一个指令微调的语言模型(理由生成器)来合成提供去噪监督的理由,理由用以解释如何从每个训练样本中检索到可能嘈杂的文档中的正确答案。然后 引导语言模型(理由学习器)通过利用这些理由为文本学习演示或被监督的微调数据来学习明确的去噪过程
问题设定
使用标准的RAG设置,理由学习器可以访问下游任务的标注数据集(比如问答任务)𝒯={⟨q,a⟩}和具有现成检索器的外部知识库。 ℛ 用于检索。 与之前的工作不同(Asai et al., 2023b; Yoran et al., 2024),这些工作利用了来自 GPT-3或 GPT-4的额外监督,我们假设模型严格限制了对上述两个信息源的访问。 给定一个问题 q,检索器 ℛ 从外部知识库返回一组可能存在噪声的文档。 D={d1,⋯,dK} 然后,模型的任务是预测给定问题的正确答案。 给定问题的正确答案 a 。 q 基于 D 及其自身的参数化知识,记为 pθ(a|q,D).
通过指令遵循进行基本原理生成
建议利用大语言模型强大的指令遵循能力来生成显式的去噪响应(即,基本原理)用于检索增强生成(RAG).


还验证了使用基于 LM 的生成器(即 Mφ)而不是采用简单的启发式方法来创建理由的必要性--如果没有生成器,则可以通过对真实答案简单的子串匹配来粗略识别相关检索文档,从而以基于模板的方式创建理由(表 6)。这种方法遭受了相关文档的语义不准确匹配,从而导致绩效降低。基于LM的生成器的另一个优点是可以产生高质量的理由,而无需参考真实答案,这只会导致较小的性能下降。

在RAG中学习去噪基本原理
利用增强基本原理的数据集 𝒯+,可以开发出一种基本原理学习器 ℳθ ,该学习器直接学习针对 RAG 任务的有效去噪方法。 接下来,我们介绍了在无需训练和可训练RAG设置下的两种简单而有效的学习方法,即InstructRAG-ICL 和InstructRAG-FT。
1.无需训练InstructRAG-ICL
模型通过上下文学习 (ICL) 学习去噪基本原理
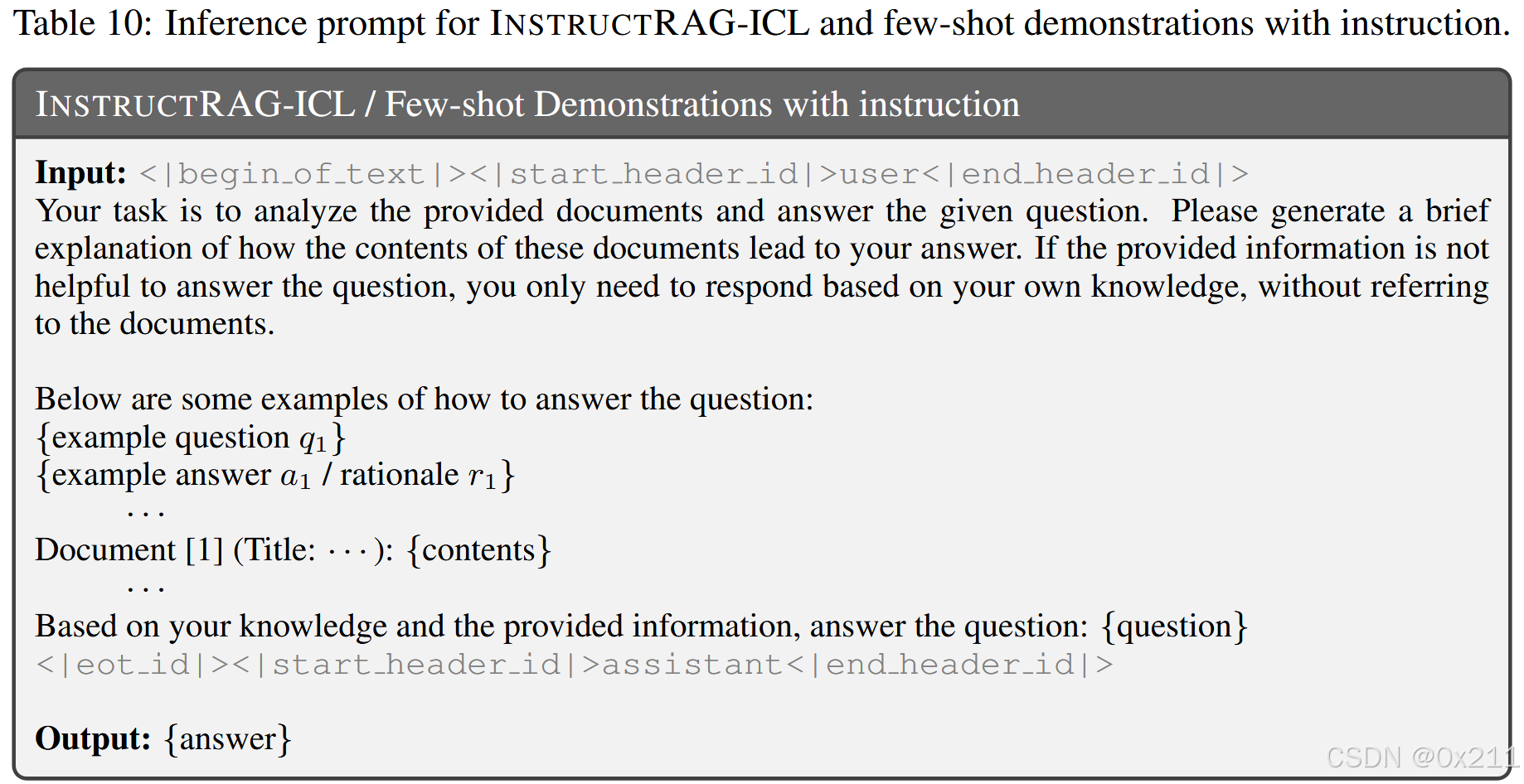
给定一个测试问题 q 和一组检索的文件 D={d1,⋯,dK},我们首先随机抽取 N 示例 ⟨qi,ri⟩∈𝒯+ 来自增强基本原理的训练数据集,然后提示模型遵循示例并生成基本原理 r. 为节省内存并提高推理效率,我们仅在这些ICL演示中展示示例性问题及其对应的基本原理。
2.可训练InstructRAG-FT
它通过使用标准语言建模目标的有监督微调 (FT) 来学习去噪基本原理。
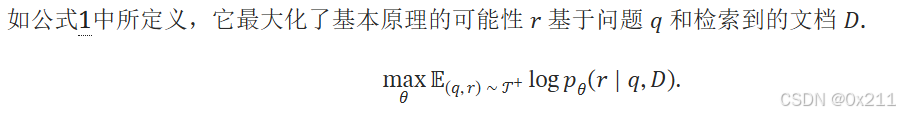
θ 代表模型参数。 InstructRAG-FT 的训练和推理共享相同的数据格式。

它将检索到的文档后跟问题作为输入,并输出去噪基本原理 r.
实验
实验设置
五个知识密集型基准:PopQA、TriviaQA、NQ、SAQA和2WikiMultHopQA
使用维基百科语料库作为检索源并使用稀疏和密集的现有检索器:BM25、DPR、GTR和Contriever
检索质量使用Recall@ K来衡量,表明是否检索到的K个文档中包含正确答案
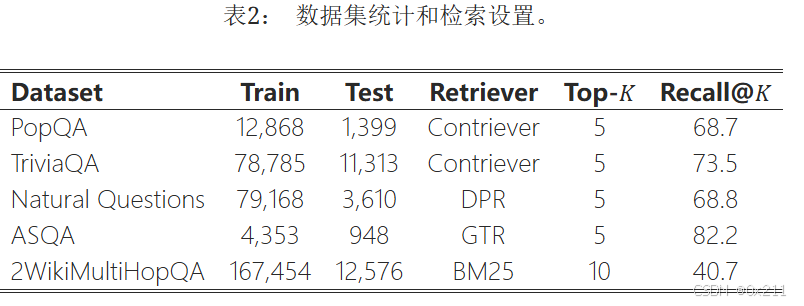
遵循标准评估设置 (Asai et al., 2023b),我们采用 ASQA (Gao et al., 2023a) 的正确性 (str-em)、引用精确率 (pre) 和召回率 (rec) 的官方指标,并对其他任务使用 准确率,该指标衡量的是模型生成的答案中是否包含真实答案
还采用 LLM 作为评判标准进行进一步评估,因为上述标准指标受模式匹配限制,无法准确处理语义等价性。
基线:
一个非检索基线的性能(即 普通的零样本提示)作为参考。
无训练的 RAG 基线包括:(1)上下文检索增强语言模型 (RALM) (Ram et al., 2023),这是一种通过向模型呈现检索到的文档来扩展非检索基线的提示方法;(2)带有指令的少样本演示,这是一种 ICL 方法,使用从训练集中采样的真实问答对作为演示示例。
可训练的 RAG 基线包括:(1)普通的监督微调 (SFT),这是一种监督方法,其训练目标是在给定可能存在噪声的输入的情况下最大化真实答案的数据似然性;(2)RetRobust (Yoran et al., 2024),它在相关和不相关的上下文中混合微调 RAG 模型,使其对不相关的上下文具有鲁棒性;(3)Self-RAG (Asai et al., 2023b),一个强大的可训练基线,专注于由特殊反射符元控制的自适应检索。 RetRobust 和 Self-RAG 最初都是基于 Llama-2 (Touvron et al., 2023) 构建的,并增加了额外的监督。 例如,RetRobust 通过提示 GPT-3 将原始查询分解并生成中间子查询来增强多跳推理任务(例如,2WikiMultiHopQA)的训练数据,而 Self-RAG 需要 GPT-4 生成额外的反射符元来增强训练样本。
主要结果
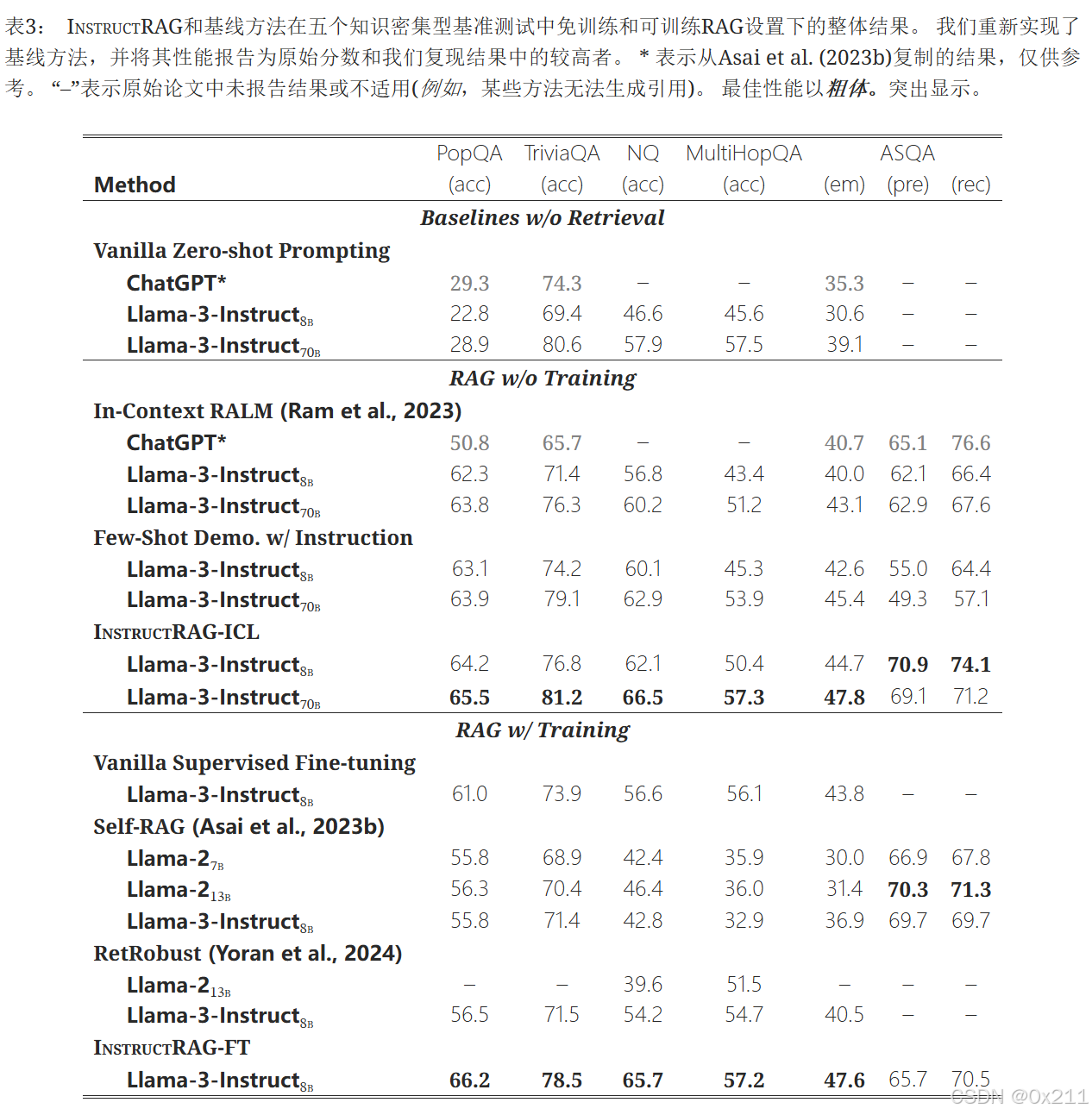
无检索的基线方法。 如第一部分所示,基本的指令微调模型(Llama-3-Instruct8B 和Llama-3-Instruct70B)在所有五个基准测试中均取得了显著的性能,其中70B模型在TriviaQA上的表现令人惊讶地具有竞争力,达到了80.6%。 这一观察结果表明,这些任务所需的知识大多属于LM的参数化知识,这可能是由于所谓的数据污染(即,下游任务的测试数据出现在LM的预训练数据中)
无需训练的RAG。第二部分显示了免训练RAG方法之间的比较。 基于上下文信息的RALM和使用指令方法的少样本演示通常比非检索基线取得更高的性能,突显了检索对于知识密集型任务的重要性。InstructRAG-ICL在各种指标上始终优于所有免训练基线,证实了自合成去噪理由的有效性。从8B模型到70B模型的提升表明,InstructRAG-ICL能够有效地随着更大规模的骨干模型进行扩展,验证了我们方法的泛化能力。
具有训练功能的RAG。底部所示,我们的InstructRAG-FT不仅在所有五个基准测试中都超越了所有非检索和免训练基线,而且在几乎所有指标上都显著优于可训练的RAG基线。 唯一的例外是ASQA任务,其中我们的方法在引用方面(i.e.,pre和rec)略逊于Self-RAG。 这是因为我们的工作主要关注RAG的显式去噪以提高生成的正确性,这是由em衡量的。 尽管没有针对引用指标进行显式优化,但我们的方法仍然取得了具有竞争力的引用性能,显著提高了生成精度和可信度。RetRobust在涉及多跳推理的2WikiMultiHopQA上取得了具有竞争力的性能。 我们认为这是由于GPT-3提供的额外训练监督,使模型能够显式地生成中间子查询和子答案。与Vanilla SFT相比,SelfGRAG始终表现出较低的性能,甚至在所有基准测试中都表现不佳,甚至表现不佳。 我们推测原因可能是这些RAG任务更偏向于特定领域的知识而不是通用知识。 但是,自身的直接利用现有培训数据中的内域特征是一个挑战,因为它要求GPT-4在这些基准测试中生成反射 Token ,这在我们的问题设置中不可用
消融实验
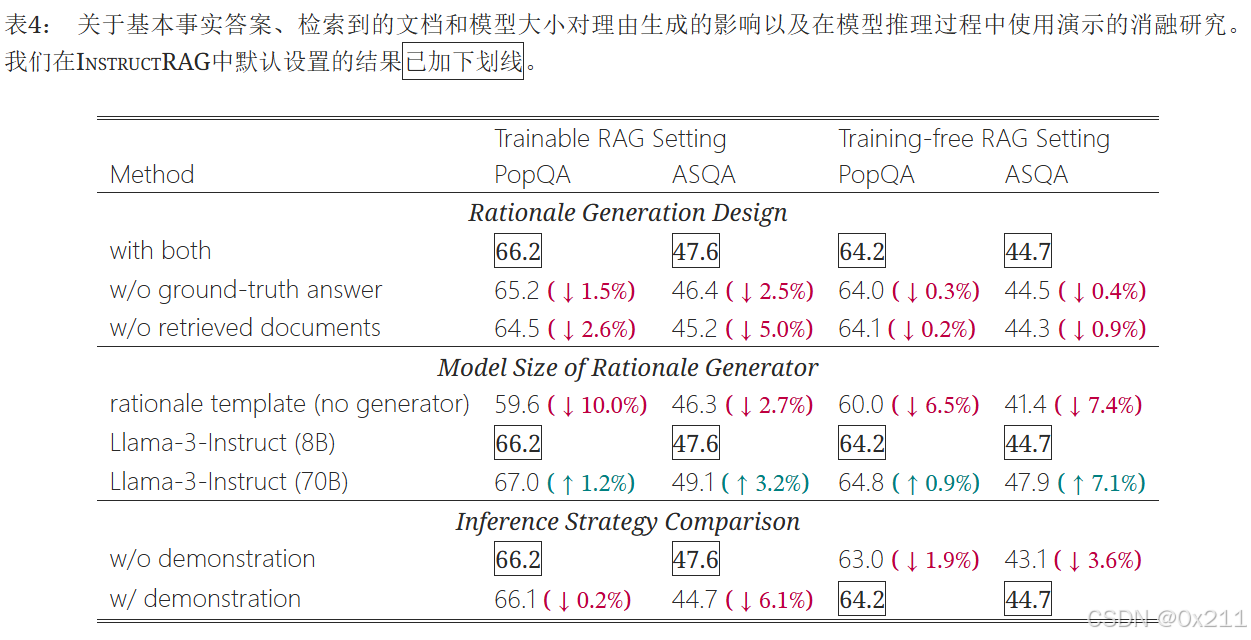
提供真实答案和检索到的文档对于推理生成非常重要。第一部分所示,从两个方面消融了推理生成设计:(1)无真实答案,其中模型在推理生成过程中无法访问真实答案,必须仅基于检索到的文档预测答案并解释其推导方式;(2)无检索文档,其中模型在推理生成过程中没有提供任何检索到的文档,在这种情况下,它必须根据自身的知识来解释给定的答案。即使无法访问检索到的文档或真实答案,我们的方法仍然运行良好,表明InstructRAG在完全无监督的方式下运行具有巨大的潜力
更大的推理生成器会产生更好的结果。中间部分显示了不同大小的推理生成器如何影响我们方法的性能。基于模板的推理生成方法明显逊于我们的方法,这突出了推理生成器的必要性。因为基于模板的方法依赖于模式匹配来识别包含真实答案的相关文档,它只考虑词汇相似性而忽略语义含义。 对语义的忽略不可避免地在基于模板生成的推理中引入噪声,使其与大语言模型生成的推理相比效率较低。
还比较了使用Llama-3-Instruct8B 和Llama-3-Instruct70B 的两种InstructRAG变体作为推理生成器。 结果表明,在无训练和可训练设置下,使用70B生成器的模型始终优于其8B的对应模型,这表明当由更强大的模型生成时,自合成的去噪推理可以提供更好的监督。
带有示例的推理应该只应用于InstructRAG-ICL。底部部分,我们研究了在模型推理过程中使用示例。虽然演示在InstructRAG-ICL中扮演着重要角色,但它们实际上损害了InstructRAG-FT的性能。这是可能因为InstructRAG-FT被优化为直接生成去噪的理由,给定潜在的噪声输入,而不参考任何演示。 因此,为InstructRAG-FT提供上下文演示是多余的,并且由于训练和推理之间的差异可能会影响其能力。
分析
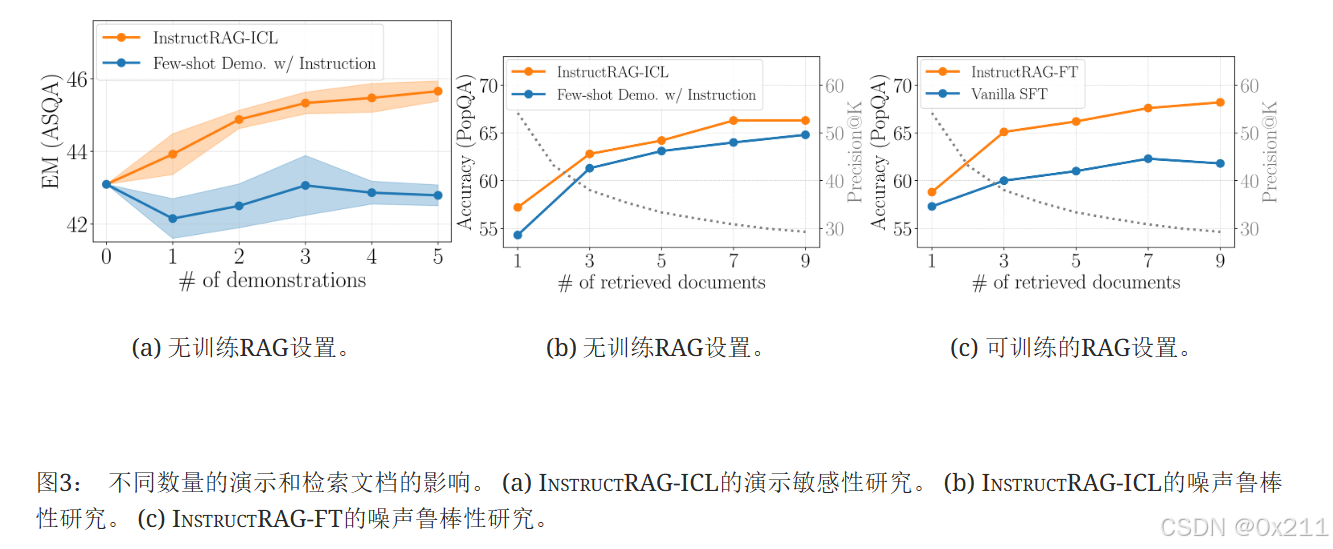
ICL无训练方案受益于更多的演示。a图,基线方法仅通过一个演示就达到了最佳性能,而呈现更多演示实际上会损害其性能。InstructRAG-ICL随着演示数量的增加而持续改进,这证实了在去噪方面,自合成理由优于普通答案。
InstructRAG-ICL和InstructRAG -FT 对增加的噪声比率具有鲁棒性。b图和c图,虽然检索更多文档为RAG模型提供了更丰富的外部知识,但它也引入了更多噪声并降低了检索精度。无训练和可训练基线都显示出改进减少甚至下降,因为文档数量的增加反映了它们对高噪声比率的脆弱性。InstructRAG-ICL和InstructRAG-FT不受此增加的噪声比率的负面影响,而是获得了进一步的改进,证明了它们强大的去噪能力。
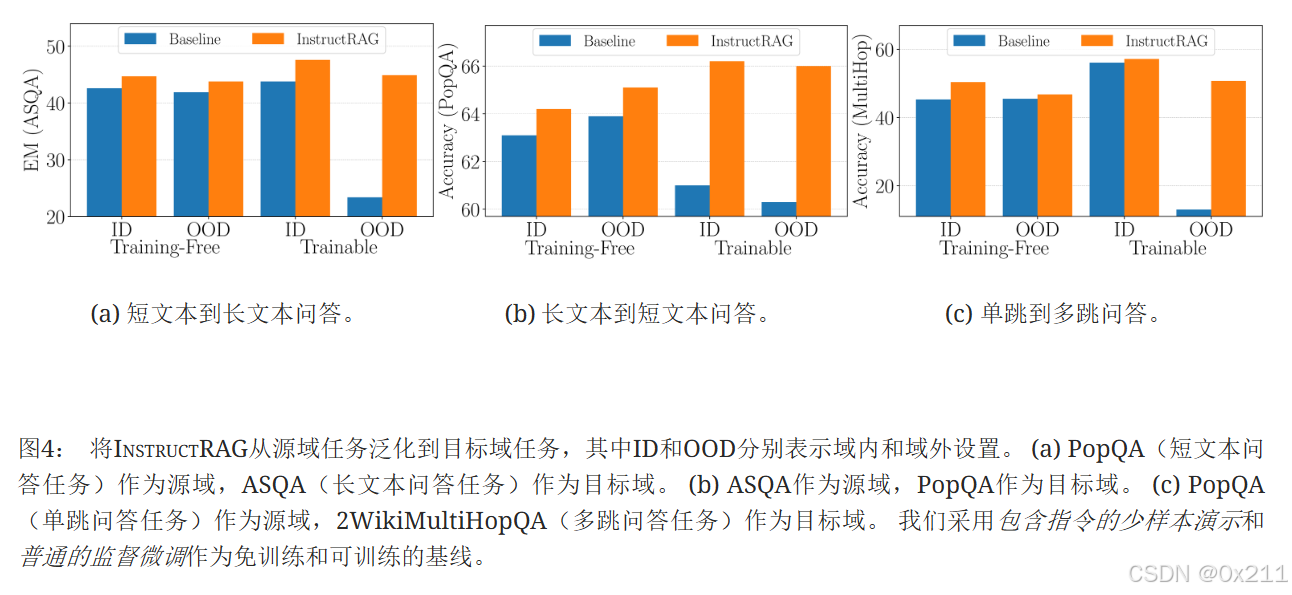
泛化能力:对于域内 (ID) 方法,它直接利用目标域演示(在免训练设置中)或在目标域任务上进行训练(在可训练设置中)。域外 (OOD) 方法只能从源域的演示或训练数据中学习,并且对目标域没有先验知识,模型必须利用从源域任务中学到的知识来解决未见的目标域任务。
InstructRAG在各种场景中始终优于基线,展示了强大的任务泛化能力。在从长形式到短形式问答任务的泛化场景中(图4(b)),免训练域外方法大大优于其域内对应方法。 我们推测,免训练域外方法之所以能够取得更好的性能,是因为它受益于源域 (ASQA) 中带有长答案的演示。 原因是ASQA中的问题模棱两可,可以有多种解释,而真实的长答案通常从各个角度解答问题,这可以被视为一种思维链演示的形式。
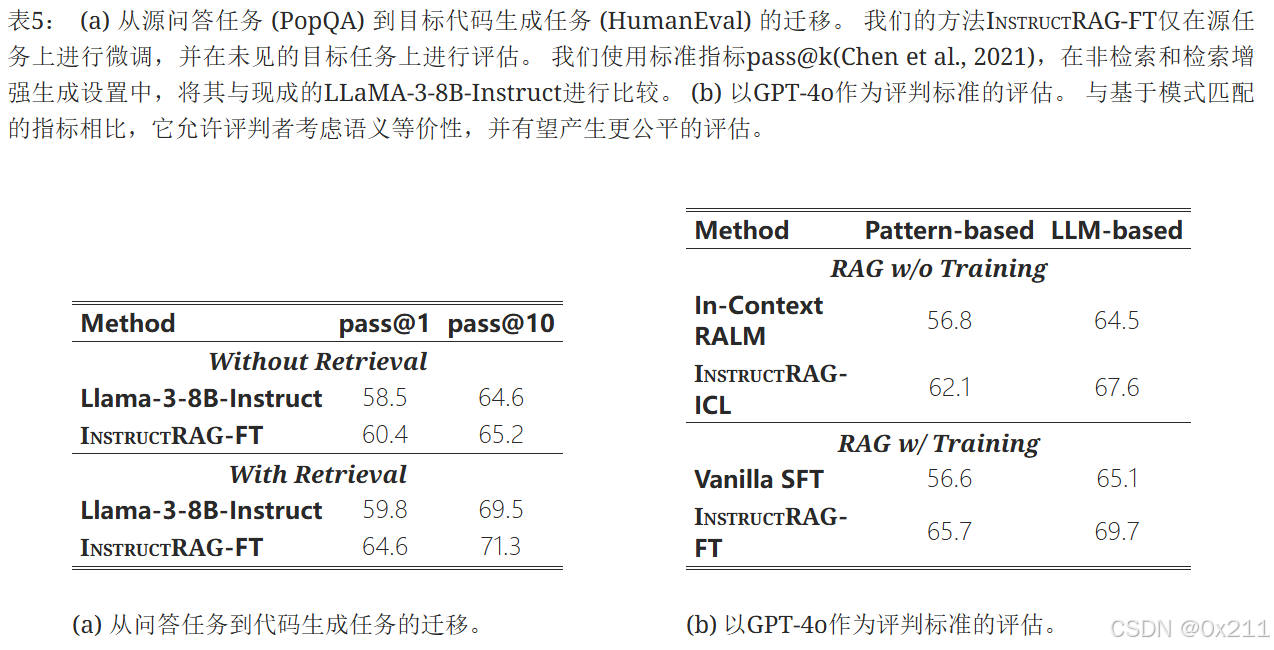
还研究了InstructRAG对非问答知识密集型任务(例如代码生成)的泛化能力。
a表格直接应用在问答任务 (PopQA) 上训练的InstructRAG-FT 来解决未见的代码生成任务。在未见的代码生成任务中,在非检索和RAG设置下都始终取得更好的泛化性能。在问答任务上训练的InstructRAG倾向于生成更多基于文本的注释,这些注释阐述了编码解决方案的设计,相比于现成的Llama-3-8B-Instruct,从而导致更准确的代码生成。
使用大语言模型作为评判标准并使用GPT-4o来评估预测结果,这允许评判者考虑语义等价性,并有望产生更公平的评估。与基于模式匹配的指标相比,以大语言模型作为评判标准通常会产生更高的评估结果,这主要是因为它能够准确匹配语义上等效的短语。 值得注意的是,我们的方法在基于模式匹配和基于大语言模型的评估指标下始终优于基线模型,进一步验证了InstructRAG的有效性。
结论
介绍了一种简单的检索生成(RAG)方法 instructrag ,该方法明确地确定了检索的内容并产生准确的生成结果。
通过利用大型语言模型强大的指令遵循能力,InstructRAG生成详细的理由,阐明如何从检索到的文档中推导出真实答案。 这些合成的基本原理可以作为上下文学习示例或监督微调数据,使模型能够学习显式的去噪过程。 在五个知识密集型基准测试上的实验表明,InstructRAG始终优于最先进的RAG方法,在无需训练和可训练设置中均取得了显著改进。

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









