







碎碎念:最近考试临近,实在没精力学习新知识了。因果分析一直是我的弱项,而在医学数据分析和用户活跃数据研究中,因果分析确实很重要。如果有感兴趣的读者,建议可以自行深入学习和研究。关于数据本身,我个人认为可能是虚拟生成的,曾有人留言询问作者,但未收到回复。一些平台的性别分布存在明显问题,加上这是我第一次遇到读取数据就出问题的情况,因此在写这个项目时,我尽可能将自己的思路贯穿其中,让分析过程更加流畅、不显突兀,欢迎大家在评论区讨论交流,但请勿发布广告内容。此外,本项目可无偿分享供学习参考,但不得用于商业倒卖。一经发现,若情节严重,将依法追究责任。
本数据集的下载地址,读者可以自行下载。
公众号(可以与我取得联系):蓝皮怪的数据坊
知乎:知乎ID—蓝皮怪
CSDN:CSDN—蓝皮怪

1.项目背景
在当今社会,社交媒体已深刻改变了人们的沟通方式和社会文化,同时也引发了对其心理健康影响的关注,本项目基于 AI 发明者 Emirhan BULUT 精心准备的数据集,探讨社交媒体使用模式与情绪状态的关系。分析发现,用户年龄、性别、使用平台、每日使用时长及互动行为(点赞、评论、消息数量)与主导情绪状态显著相关,其中,Instagram 用户更活跃,情绪多为开心,而 LinkedIn 用户较为低调,反映了平台特性的差异,并且建立随机森林和 CatBoost 模型可以预测用户当天的主导情绪状态,为心理健康管理提供了参考依据。
2.数据说明
| 字段 | 说明 |
|---|---|
| User_ID | 用户的唯一标识符 |
| Age | 用户的年龄 |
| Gender | 用户的性别(女性、男性、非二元性别) |
| Platform | 使用的社交媒体平台(如 Instagram、Twitter、Facebook、LinkedIn、Snapchat、Whatsapp、Telegram) |
| Daily_Usage_Time (minutes) | 每天在该平台上的使用时间(分钟) |
| Posts_Per_Day | 每天发布的帖子数量 |
| Likes_Received_Per_Day | 每天收到的点赞数量 |
| Comments_Received_Per_Day | 每天收到的评论数量 |
| Messages_Sent_Per_Day | 每天发送的消息数量 |
| Dominant_Emotion | 用户当天的主导情绪状态(如快乐、悲伤、愤怒、焦虑、无聊、中性) |
3.导入必要的Python库
!pip install imblearn -i https://pypi.tuna.tsinghua.edu.cn/simple/
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple/
Requirement already satisfied: imblearn in /opt/conda/lib/python3.11/site-packages (0.0)
Requirement already satisfied: imbalanced-learn in /opt/conda/lib/python3.11/site-packages (from imblearn) (0.12.4)
Requirement already satisfied: numpy>=1.17.3 in /opt/conda/lib/python3.11/site-packages (from imbalanced-learn->imblearn) (1.26.4)
Requirement already satisfied: scipy>=1.5.0 in /opt/conda/lib/python3.11/site-packages (from imbalanced-learn->imblearn) (1.12.0)
Requirement already satisfied: scikit-learn>=1.0.2 in /opt/conda/lib/python3.11/site-packages (from imbalanced-learn->imblearn) (1.4.1.post1)
Requirement already satisfied: joblib>=1.1.1 in /opt/conda/lib/python3.11/site-packages (from imbalanced-learn->imblearn) (1.3.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.11/site-packages (from imbalanced-learn->imblearn) (3.4.0)
(3.4.0)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import ks_2samp,chi2_contingency,ttest_ind,kruskal
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from catboost import CatBoostClassifier
from imblearn.over_sampling import SMOTE
4.数据读取及预处理
train_data = pd.read_csv('/home/mw/input/11151624/train.csv') # 训练集数据
test_data = pd.read_csv('/home/mw/input/11151624/test.csv') # 测试集数据
如果使用val_data = pd.read_csv('/home/mw/input/11151624/val.csv')的话,会报错,根据报错的原因如下:
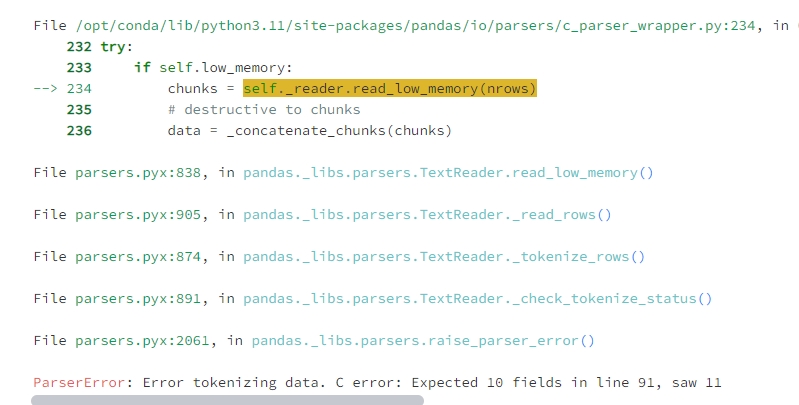
程序预期每一行都有10个字段(列),但是在第91行出现了11个字段,导致解析失败,通过查看文件发现第91行是这样的:

当然,仔细观察后,发现有问题的应该不止这一行,怎么解决呢?我发现val里有User_ID列,而train文件里也有User_ID列,如果val里的User_ID列都在train文件里出现,并且在报错行以前的User_ID对应的其他特征,也和train里是一致的,我可以认为这些数据实际上在模型训练时已经出现过,导致测试集的性能过于理想,造成数据泄露,因此,在后续的分析就不会管val了。
val_data_ids = pd.read_csv('/home/mw/input/11151624/val.csv', usecols=['User_ID'])
print("train.csv 中 ID 列的数据类型:", train_data['User_ID'].dtype)
print("test.csv 中 ID 列的数据类型:", test_data['User_ID'].dtype)
print("val.csv 中 ID 列的数据类型:", val_data_ids['User_ID'].dtype)
train.csv 中 ID 列的数据类型: object
test.csv 中 ID 列的数据类型: int64
val.csv 中 ID 列的数据类型: int64
发现train文件的ID列数据类型和其他的不一样,这里也改成int格式,结果很尴尬,运行train_data['User_ID'] = train_data['User_ID'].astype(int)竟然报错了:
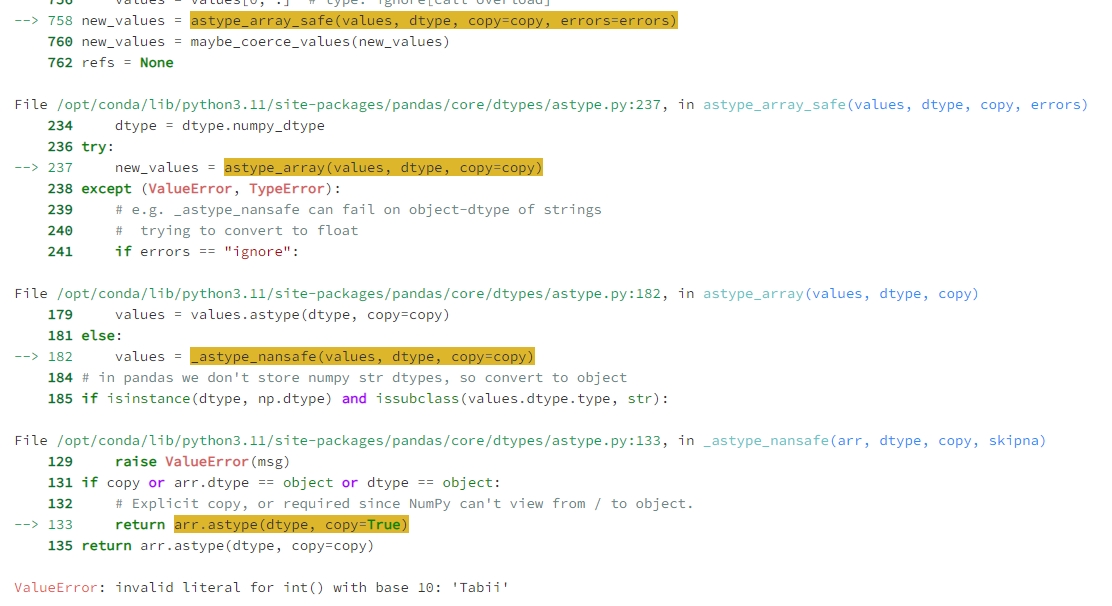
这个错误表明,train.csv 中的 User_ID 列有一些值不能转换为整数类型,具体是 Tabii 这样的字符串。这通常意味着 User_ID 列中除了数值,还有一些非数值的字符串,很烦,还要先处理这个问题。
# 检查 User_ID 列中无法转换为整数的值
non_numeric_ids = train_data[~train_data['User_ID'].apply(lambda x: x.isdigit())]
# 打印非数值的 ID
print("非数值的 User_ID:")
non_numeric_ids
非数值的 User_ID:
| User_ID | Age | Gender | Platform | Daily_Usage_Time (minutes) | Posts_Per_Day | Likes_Received_Per_Day | Comments_Received_Per_Day | Messages_Sent_Per_Day | Dominant_Emotion | |
|---|---|---|---|---|---|---|---|---|---|---|
| 641 | Tabii | işte mevcut veri kümesini 1000 satıra tamamlı... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
problem_row_index = train_data[train_data['User_ID'] == 'Tabii'].index[0]
# 打印该行以及前后几行
print("前后几行的情况:")
train_data.iloc[problem_row_index - 2 : problem_row_index + 3]
前后几行的情况:
| User_ID | Age | Gender | Platform | Daily_Usage_Time (minutes) | Posts_Per_Day | Likes_Received_Per_Day | Comments_Received_Per_Day | Messages_Sent_Per_Day | Dominant_Emotion | |
|---|---|---|---|---|---|---|---|---|---|---|
| 639 | 640 | 28 | Non-binary | 100.0 | 2.0 | 22.0 | 12.0 | 25.0 | Anxiety | |
| 640 | 641 | 31 | Male | 45.0 | 1.0 | 9.0 | 4.0 | 10.0 | Sadness | |
| 641 | Tabii | işte mevcut veri kümesini 1000 satıra tamamlı... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 642 | 642 | 25 | Female | 150.0 | 6.0 | 90.0 | 26.0 | 30.0 | Happiness | |
| 643 | 643 | 29 | Male | 95.0 | 4.0 | 50.0 | 22.0 | 22.0 | Anger |
OK,前后两行是没问题的,那就可以放心的删除这个异常行了,并且将ID列转为int格式。
train_data = train_data[train_data['User_ID'] != 'Tabii']
train_data['User_ID'] = train_data['User_ID'].astype(int)
# 获取 train 和 val 中的 ID 集合
train_ids = set(train_data['User_ID'])
val_ids = set(val_data_ids['User_ID'])
# 找出 val 中不在 train 中的 ID
uncommon_ids = val_ids - train_ids
# 输出不一致的 ID
if uncommon_ids:
print(f"以下 ID 在 val.csv 中但不在 train.csv 中:")
print(uncommon_ids)
else:
print("val.csv 中的所有 ID 都在 train.csv 中。")
val.csv 中的所有 ID 都在 train.csv 中。
OK,现在已经证实了,val中的所有ID都是在train中的,现在只要提取不报错的数据和对应ID的train数据进行对比。
val_data_skip = pd.read_csv('/home/mw/input/11151624/val.csv', on_bad_lines='skip') # 使用该参数跳过错误行
# 从 val_data_skip 提取 ID 列,并筛选对应的行
val_ids = val_data_skip['User_ID']
# 从 train_data 提取对应的行
train_matching_data = train_data[train_data['User_ID'].isin(val_ids)]
# 按 'User_ID' 排序,确保对应的行顺序一致
train_matching_data_sorted = train_matching_data.sort_values(by='User_ID').reset_index(drop=True)
val_data_sorted = val_data_skip[val_data_skip['User_ID'].isin(val_ids)].sort_values(by='User_ID').reset_index(drop=True)
本来我想的是把train里对应val的id数据提取出来,然后按ID排序再对比两个数据的特征是否一致,结果发现,val里的行数竟然比train里的行数多!这就说明val文件里存在重复值,需要处理。

print(f'查看重复值:{
val_data_sorted.duplicated().sum()}')
查看重复值:7
# 删除重复的行
val_data_sorted = val_data_sorted.drop_duplicates()
本来按理说删除了重复值,应该就能对比了,结果又报错了,还是说val行数比train里的多,这就说明有些是ID重复了。

# 查看重复 ID
duplicate_ids_in_val = val_data_sorted[val_data_sorted['User_ID'].duplicated(keep=False)]
# 打印重复的 User_ID 行
print("重复的 User_ID 行:")
duplicate_ids_in_val
重复的 User_ID 行:
| User_ID | Age | Gender | Platform | Daily_Usage_Time (minutes) | Posts_Per_Day | Likes_Received_Per_Day | Comments_Received_Per_Day | Messages_Sent_Per_Day | Dominant_Emotion | |
|---|---|---|---|---|---|---|---|---|---|---|
| 26 | 185 | 29 | Non-binary | 65 | 2 | 27 | 11 | 22 | Anxiety | |
| 27 | 185 | 29 | Non-binary | 75 | 2 | 20 | 8 | 20 | Boredom | |
| 50 | 352 | 24 | Female | 75 | 3 | 33 | 12 | 26 | Anger | |
| 51 | 352 | Female | 24 | 72 | 3 | 42 | 19 | 40 | Anger | |
| 55 | 372 | Male | 28 | 100 | 4 | 23 | 19 | 20 | Neutral | |
| 56 | 372 | 35 | Male | 70 | 1 | 13 | 8 | 10 | Boredom | |
| 66 | 429 | 28 | Male | 190 | 5 | 49 | 12 | 15 | Boredom | |
| 67 | 429 | 28 | Female | 190 | 7 | 80 | 30 | 35 | Happiness | |
| 68 | 463 | 34 | Non-binary | 60 | 4 | 23 | 14 | 30 | Happiness | |
| 69 | 463 | 34 | Non-binary | Telegram | 80 | 2 | 21 | 8 | 20 | Neutral |
| 106 | 733 | 24 | Non-binary | 130 | 6 | 90 | 22 | 35 | Happiness | |
| 107 | 733 | 23 | Non-binary | 105 | 3 | 21 | 15 | 14 | Neutral | |
| 118 | 810 | 31 | Male | 170 | 7 | 90 | 35 | 40 | Happiness | |
| 119 | 810 | 31 | Male | 52 | 5 | 60 | 20 | 30 | Happiness |
做到这里还是很崩溃的,发现数据存在很多问题,像年龄里竟然有性别,性别里竟然有年龄和Non-binary,并且在val里面竟然有那么多ID重复的数据,这个时候,面临两种选择,继续探查val文件,或者先处理这些错误值,我这里还是选择探查val文件,不为别的,都到这一步了,再掉头朝着另一个方向,也不好,然后我突然想到一个解决的方法,既然后续建模的时候只需要考虑非ID列,那么为啥要管这个ID列重复的数据呢?直接拿特征去和train里的特征对比即可。
# 去掉 'User_ID' 列,保留其他特征列
val_data_features = val_data_sorted.drop(columns=['User_ID'])
train_data_features = train_data.drop(columns=['User_ID'])
# 将 train_data_features 转换为集合的形式,方便快速对比
train_set = set(tuple(row) for row in train_data_features.values)
# 检查 val_data_features 中的每一行是否存在于 train_set 中
val_in_train = val_data_features.apply(lambda row: tuple(row) in train_set, axis=1)
# 计算匹配的比例
match_percentage = val_in_train.mean() * 100 # 转换为百分比
print(f"匹配的占比: {
match_percentage:.2f}%")
匹配的占比: 0.00%
通过对比,发现了一个与之前猜想不同的结论,发现val里的数据均没有在train里出现过,这也就证明,后续建模的时候,可以将train里的数据全部训练进去,然后在val文件里来评估模型,现在开始处理train、test、val里的所以异常数据。
# 打开文件逐行检查字段数量
file_path = '/home/mw/input/11151624/val.csv'
with open(file_path, 'r') as file:
lines = file.readlines()
# 获取头部字段数目
header = lines[0].strip().split(',')
expected_fields = len(header)
# 找出字段数目不一致的行(忽略空行)
problem_lines = []
for i, line in enumerate(lines[1:], start=2): # 从第2行开始(数据行)1
# 跳过空行
if not line.strip():
continue
fields = line.strip().split(',')
if len(fields) != expected_fields:
problem_lines.append((i, line.strip()))
# 输出问题行
print(f"找到以下字段数不一致的行,共 {
len(problem_lines)} 行:")
for line_no, content in problem_lines[:]:
print(f"行号 {
line_no}: {
content}")
找到以下字段数不一致的行,共 4 行:
行号 91: 729,30,Female,Facebook,90,4,38,20,24,,Anger
行号 159: 390,Female,30,Female,Instagram,210,5,87,30,32,Happiness
行号 189: 27,Non-binary,Facebook,55,1,9,2,11,Anxiety
行号 201: 228,30,Female,Facebook,90,4,38,20,24,,Anger
发现数据有4行存在问题,首先行号91和201多了个空格,而且两个数据竟然是一样的,这样的话,只用处理其中一个,另一个到时候就直接删除吧,159行在年龄特征处多了个性别,直接删除,189行那里少了一个特征,不清楚是啥特征,直接删除行,总结就是:
- 行号 91:删除空格,补全缺失值。
- 行号 201:与行号 91 重复,删除。
- 行号 159:删除第一个
Female,因为该字段应为年龄。 - 行号 189:直接删除整行。
# 修复问题行
corrected_lines = []
for i, line in enumerate(lines):
if i + 1 == 91: # 修复行号 91:删除空格
corrected_line = "729,30,Female,Facebook,90,4,38,20,24,Anger"
corrected_lines.append(corrected_line)
elif i + 1 == 159: # 修复行号 159:删除第一个 Female
corrected_line = "390,30,Female,Instagram,210,5,87,30,32,Happiness"
corrected_lines.append(corrected_line)
elif i + 1 == 201: # 删除行号 201
continue
elif i + 1 == 189: # 删除行号 189
continue
else: # 其他行保持不变
corrected_lines.append(line.strip())
# 保存修复后的文件
corrected_file_path = file_path.replace('.csv', '_corrected.csv')
with open(corrected_file_path, 'w') as corrected_file:
corrected_file.write('\n'.join(corrected_lines))
print(f"修复后的文件已保存至:{
corrected_file_path}")
修复后的文件已保存至:/home/mw/input/11151624/val_corrected.csv
这样就得到了修复后的数据,便能正常的读取数据了。
val_data_corrected = pd.read_csv(corrected_file_path)
经过漫长的处理,还并不能开始分析数据,因为之前探索val文件的时候发现,这些文件里可能会存在位置不对版的情况,还需要进一步的去处理,大致思路如下:
- 先输出三个文件的基本信息,这样可以很好的查看缺失值、重复值(针对val的重复值,不应该考虑ID,因为他是验证集,重复的特征(即便 ID 不同)可能影响模型性能评估,导致偏倚或误导)。
- 输出每个特征中的异常信息,比如应该是数值型的数据,却存在一些字符型数据,就输出这些字符型数据。
- 输出字符型数据的唯一值,以便查看出现在数值型里的字符型数据的正确位置。
- 建立一个函数,处理这些值。
print('查看训练集数据信息:')
train_data.info()
查看训练集数据信息:
<class 'pandas.core.frame.DataFrame'>
Index: 1000 entries, 0 to 1000
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User_ID 1000 non-null int64
1 Age 1000 non-null object
2 Gender 1000 non-null object
3 Platform 1000 non-null object
4 Daily_Usage_Time (minutes) 1000 non-null float64
5 Posts_Per_Day 1000 non-null float64
6 Likes_Received_Per_Day 1000 non-null float64
7 Comments_Received_Per_Day 1000 non-null float64
8 Messages_Sent_Per_Day 1000 non-null float64
9 Dominant_Emotion 1000 non-null object
dtypes: float64(5), int64(1), object(4)
memory usage: 85.9+ KB
print('查看测试集数据信息:')
test_data.info()
查看测试集数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 103 entries, 0 to 102
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User_ID 103 non-null int64
1 Age 103 non-null object
2 Gender 103 non-null object
3 Platform 103 non-null object
4 Daily_Usage_Time (minutes) 103 non-null int64
5 Posts_Per_Day 103 non-null int64
6 Likes_Received_Per_Day 103 non-null int64
7 Comments_Received_Per_Day 103 non-null int64
8 Messages_Sent_Per_Day 103 non-null int64
9 Dominant_Emotion 103 non-null object
dtypes: int64(6), object(4)
memory usage: 8.2+ KB
print('查看验证集数据信息:')
val_data_corrected.info()
查看验证集数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 146 entries, 0 to 145
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









