






文章来源 微信公众号 EW Frontier
摘要

卷积神经网络(CNN)是环境声音分类中性能最好的神经网络结构之一。最近,时间注意力机制已被用于CNN中,以从音频分类的相关时间帧中捕获有用的信息,特别是对于不应用声音事件的开始和偏移时间的弱标记数据。然而,在这些方法中,在获得深度特征时,没有明确地利用固有的光谱特性和变化。在本文中,我们提出了一种新的并行时间-频谱注意机制,用于CNN学习有区别的声音表示,通过捕获不同时间帧和频带的重要性来增强时间和频谱特征。并行分支被构造为允许分别应用时间注意力和频谱注意力,以便在不存在声音事件的情况下减轻来自片段的干扰。在三个环境声音分类(ESC)数据集和两个声学场景分类(ASC)数据集上的实验表明,该方法不仅提高了分类性能,而且对噪声具有较好的鲁棒性。
索引术语:环境声音分类,卷积神经网络,注意力机制,声音事件
1.介绍
环境声音分类(ESC)是人机交互中的一个重要研究领域,旨在通过环境声音对环境进行分类,具有各种潜在应用,如音频监控[1]和智能房间监控[2]。由于声学环境的动态和非结构化的性质,这是一个实际的挑战,设计适当的功能,环境声音分类。在许多现有的ESC方法中,通常基于声学环境的先验知识来设计特征,然后用特征训练分类器以获得每个环境声音信号的类别概率。
在这些方法中,由于训练数据量的增加和数据增强技术的可用性,深度学习已被广泛用于ESC。基于卷积神经网络(CNN)的方法[3-8]提供了最先进的性能,其中频谱图和梅尔尺度频率倒谱系数(MFCC)通常用作网络的输入。然而,与视觉识别任务中的图像不同,声谱图所代表的时间和频谱信息在声音识别中将具有不同的特征和重要程度。虽然时域中局部模式的平移对声音事件的分类影响不大,但差异跨频带的噪声对声音分类的性能具有显著影响[9]。为了捕获关于特征的哪些部分与声音事件更相关的信息,已经提出了注意力机制[10-17],特别是对于弱标记数据,其中关于声音事件的定时信息在训练数据中不可用。在这些方法中,应用时间注意力[11,14]来获得用于在不同时间步长组合特征向量的权重,然而,没有考虑不同频带的重要性。空间注意力[17]表征了具有空间权重的区域对声音事件位置的重要性,但忽略了固有的时频特性。
为了解决上述问题,我们提出了一种并行的时间-频谱注意机制,用于CNN学习区分性的时间-频率表示,这使得网络能够意识到时间帧和频率通道中的各种信息。具体而言,时间注意力被用来捕捉声音事件出现的特定帧,并提出了一种频谱注意力方法,以支付不同程度的注意到不同的频带。频谱注意力的想法受到人类初级听觉皮层中频率选择性注意力过滤器的研究的启发[18],该研究表明,人类大脑通过加强整个上级颞叶皮层中的细粒度活动模式来促进选择性地收听场景中感兴趣的频率。此外,在我们的方法中应用的并行结构,这减轻了时间和频谱特征之间的干扰,通过关注两个不同的分支,也提高了鲁棒性时,一个单一的分支被干扰的片段不存在的声音事件。在三个基准数据集(ESC-10 [19],ESC-50 [19]和UrbanSound 8 k [20])上评估了所提出的方法,并分别达到了95.8%,88.6%和88.5%的最新分类准确率。此外,我们的方法被应用到另一个音频分类任务,即声学场景分类(ASC),也提高了性能。
2.该方法
在本节中,介绍了时间注意力和频谱注意力方法,这些方法增强了来自相关时间帧和频带的特征。为了同时获得时间和频谱特征,然后引入并行的时间-频谱注意机制。
2.1.时间注意与光谱注意
CNN在音频分类任务中得到了广泛的应用,它表现出强大的从低层特征中提取高层特征的能力,如对数梅尔谱图。为了从大小为T×F×1的输入频谱图开始,卷积层由C通道滤波器组成的卷积层输出一个T × F × C特征图,然后将其馈送到下一个卷积层以提取平移不变特征。在这种情况下,特征图的空间区域被同等对待,其可能包含声音事件的噪声或不相关信息。
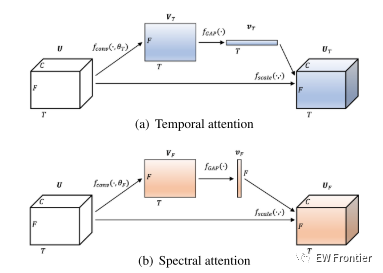
图1:时间注意力和光谱注意力机制的图解。
为了增强来自相关时间帧和频带的特征,我们提出了时间注意力和频谱注意力。对时间帧和频带应用不同的权值,可以引导网络对环境声音的时间和频谱特性给予不同的关注。两种注意力机制的结构如图1所示。具体地,对于输入特征图U ∈ RT×F×C,采用1 × 1 × 1卷积层fconv来获得跨通道的全局特征图,即全局时间特征图VT ∈ RT×F×1和全局频谱特征图VF ∈ RT×F×1。

其中θT和θF分别表示时间注意力和频谱注意力中卷积层的模型参数。1 × 1滤波器用于将通道的数量压缩为1,其可以从局部特征图U学习通道方式的全局信息。然后通过全局平均池化fGAP压缩提取的全局时间和谱特征图,以获得时间方向激活vT ∈ RT×1×1和频率方向激活vF ∈ R1×F×1。
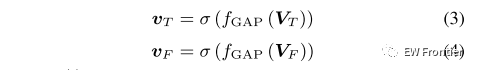
其中,σ(·)表示将值限制在(0,1)范围内的S形函数,并且分别沿时间轴和频率轴沿着应用全局平均池化。因此,可以通过利用时间方向激活vT和频率方向激活vF重新缩放U来获得时间方向特征图UT ∈ RT×F×C和频率方向特征图UF ∈ RT×F×C。
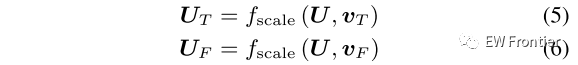
其中,fscale(·,·)是指特征图与激活(即,按时间的激活vT和按频率的激活vF)之间的乘法。
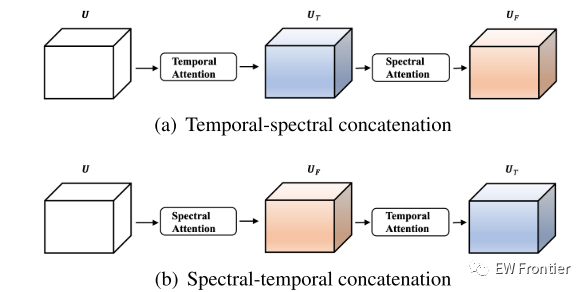
图2:时间注意力和频谱注意力的连接示意图。
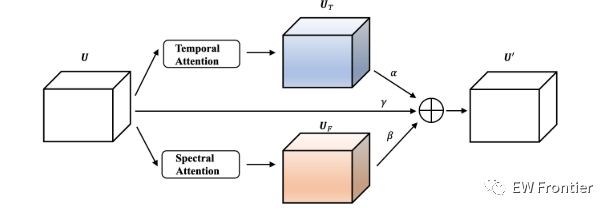
图3:并行时间-频谱注意机制的图示。
2.2.并行时间-谱注意
同时获得时间和频谱特征的一种直观方法是时间注意力和频谱注意力的级联,如图2所示。然而,在级联的方法中存在缺点,即时间注意力和频谱注意力可能彼此干扰。例如,当应用图2(a)中的时间-频谱级联时,一些噪声帧的激活将被时间注意力抑制,而另一方面,噪声帧的一些切片可以被频谱注意力增强。因此,时间注意的效果受到频谱注意的干扰。
为了减轻时间注意和频谱注意的干扰,我们提出了一种并行的时间-频谱注意机制。如图3所示,时间和频谱特征被关注两个不同的分支,而没有相互传播的信息。在这种情况下,每个表示学习集中在特定的有区别的局部区域上,而不是均匀地分布在整个特征图上,这导致当单个分支被声学环境中没有声音事件出现的部分干扰时具有更好的鲁棒性。
具体而言,应用三个分支(即时间注意力、频谱注意力和捷径)的总和来获得最终的时频特征。由于对时域和频谱特性的关注程度不同,因此求和的权重也不相同。给定系数为α、β、γ,时频特征图U ∈ RT×F×C由以下公式计算:
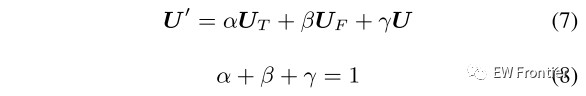
其中,α、β、γ是具有相同初始值的可学习参数,并应用softmax函数对其进行归一化。
在这种情况下,网络可以自适应地对时间特性和频谱特性给予不同的关注。
3.实验
我们的方法在三个ESC数据集(ESC-10 [19],ESC-50 [19]和UrbanSound 8 k [20])和两个ASC数据集(DCASE 2018 task 1A数据集[21]和DCASE 2019 task 1A数据集[21])上进行了评估,这是ESC和ASC常用的数据集。从音频信号中提取对数梅尔频谱图作为网络的输入。实验设置和结果详述如下。
3.2.网络结构
我们在相同的实验设置下设置了包括基线模型(CNN 10 [23])和十个比较模型的实验,以评估所提出的注意力机制。
CNN 10由4个卷积块组成,分别有64、128、256和512个输出通道。每个卷积块包含2个卷积层,内核大小为3 × 3,然后进行下采样,平均池大小为2 × 2。批量归一化[24]和ReLU [25]函数应用于所有卷积层。然后应用全局池化层和两个全连接层,然后应用softmax非线性进行分类。[23]关于CNN 10的更多细节。TS-CNN 10 TS-CNN 10是我们基于CNN 10提出的模型,其中对每个卷积块采用并行时间-频谱注意机制。所有其他设置都与CNN 10相同。
TS-CNN 10 -1、TS-CNN 10 -2、TS-CNN 10 -3和TS-CNN 10 -4是TS-CNN 10的变体,它们分别仅将并行时间-频谱注意机制应用于第1、第2、第3和第4卷积块。TS-CNN 10-fixed是TS-CNN 10的另一种变体,其中(7)中的参数α,β和γ固定为相同的值(α = β = γ = 0.33)。T-CNN 10和S-CNN 10分别应用图1(a)中的时间注意力和图1(B)中的频谱注意力。此外,TS-CNN 10-concat和ST-CNN 10-concat分别应用图2(a)中的时间-频谱级联和图2(B)中的频谱-时间级联的注意机制。
表1:ESC-10、ESC-50和UrbanSound 8 k(US 8 k)数据集的准确度比较

表2:DCASE 2018 task1A数据集(DCASE2018 1A)和DCASE 2019 task1A数据集(DCASE2019 1A)的准确性比较

3.3.实验设置
预处理:所有原始音频都被重新采样到44. 1 kHz,然后通过补零或截断固定到特定长度(即ESC-10和ESC-50为5s,UrbanSound 8 k为4s,DCASE 2018 task 1A数据集和DCASE 2019 task 1A数据集为10 s)。然后对音频信号应用短时傅立叶变换(STFT)以计算频谱图,其中窗口大小为40 ms,跳变大小为20 ms。对频谱图应用40个mel滤波器组,随后进行对数运算以提取对数mel频谱图。
训练描述:在训练阶段,Adam算法[26]被用作具有默认参数的优化器。该模型是端到端训练的,初始学习率为0.01,每5次迭代的指数衰减率为0.98。网络参数的学习使用分类交叉熵损失。批量大小设置为64,训练在2000次迭代后终止。在我们的实验中应用了数据增强方法mixup [27]和Specaugment [28],以防止系统过拟合并提高性能。
3.4.实验结果及分析
表1展示了我们提出的TSCNN 10和其他最先进方法在ESC数据集(ESC-10 [19],ESC-50 [19]和UrbanSound 8 k [20])上的性能。在[12,33]中应用了时间注意力来关注语义相关的帧,这比CNN模型实现了更高的准确性[19,29,30]。然而,这些方法没有考虑环境声音的频谱特性。其他方法[31,32,34]设计的滤波器组学习,然而,使用这种方法而不是将对数梅尔谱图馈送到网络,几乎没有研究深层时频特性。实验结果表明,TSCNN 10的性能优于所有的对比方法,从而证实了该方法在增强相关帧和频带特征以获得有区别的声音表示方面的有效性。值得一提的是,TS-CNN 10在ESC-10数据集和ESC-50数据集上的表现都超过了人类。

图4:四个输入对数梅尔频谱图(第1行)和CNN 10(第2行)和TS-CNN 10(第3行)中第一个卷积块的平均特征图的可视化。(a)ESC-50数据集的原始音频。(b)高斯随机噪声被添加到第50和第64个时间帧(红框)中。(c)高斯随机噪声被添加到第25 - 30频带(红框)。(d)在整个音频中加入高斯随机噪声,信噪比为10 dB。
我们观察到,时间注意力(T-CNN 10)和频谱注意力(S-CNN 10)都提高了ESC的性能,并且它们的组合(TS-CNN 10)带来了更多的改善。此外,TS-CNN 10 -1,TS-CNN 10 -2,TSCNN 10 -3,TS-CNN 10 -4的性能都优于CNN 10,这表明我们提出的并行时间谱注意力机制可以应用于任何卷积层以增强特征。在更深层中使用的并行时间-频谱注意力显示出更多的性能增益,并且当更多的层应用并行时间-频谱注意力机制(TS-CNN 10-fixed和TS-CNN 10)时可以实现更高的性能。TS-CNN 10实现了比TS-CNN 10-fixed更高的精度,这是因为(7)中的可学习参数被设置为自适应地对时间和频谱特性给予不同的关注。此外,TS-CNN 10的性能优于TSCNN 10-concat和ST-CNN 10-concat,这验证了并行结构的优势,以减轻时间特征和频谱特征的干扰。
我们的方法也适用于另一个音频分类任务(即ASC),并在DCASE 2018 task1A数据集[21]和DCASE 2019 task1A数据集[21]上进行评估。如表2所示,我们的注意力机制也可以提高ASC的性能。
为了进一步测试TS-CNN 10的鲁棒性,将具有不同SNR(即20 dB,10 dB和0 dB)的三种不同类型的噪声(即高斯随机,总线和电车)应用于ESC-50数据集中的原始音频。CNN 10和TS-CNN 10使用原始数据进行训练,然后在噪声数据上进行测试,结果如表3所示。TS-CNN 10对三种噪声都表现出较好的鲁棒性,且随着信噪比的降低,这种鲁棒性表现得更加明显。
此外,可视化分析,以显示我们的方法如何增强在复杂和动态的声学环境中的时频表示。如图4所示,CNN 10和TS-CNN 10的输入对数梅尔频谱图和特征图被可视化。图4(a)是ESC-50数据集的原始音频。很明显,TSCNN 10更多地关注于相关的时间帧和频带,并且衰减了与TSCNN 10相比不太相关的信息与CNN相比。
表3:不同噪声类型和不同SNR的ESC-50数据集的准确度比较

图4(B)和图4(c)示出了噪声音频,其中高斯随机噪声被添加到若干时间帧和频带中。CNN 10不能很好地处理嘈杂的音频,并且特征图在嘈杂的部分中被激活。而对于我们的TS-CNN 10,噪声部分的特征图则少得多。这是因为在两个不同的分支中引入了时间谱注意力,使得表示学习的计算集中在特定的有区别的局部区域,而不是分散在整个特征图上,这使得当单个分支受到噪声部分的干扰时具有更好的鲁棒性。具体而言,当添加若干时间帧中的随机噪声时,频谱关注可以通过沿时间轴沿着应用全局平均池化来减轻噪声部分的影响。同样,我们可以解释TS-CNN 10在噪声频带中的性能。此外,高斯随机噪声被添加到整个音频中,SNR为10 dB,如图4(d)所示。实验结果表明,本文提出的TS-CNN 10算法仍能获得声音事件发生段的时频信息。然而,CNN 10很难捕捉到有效的信息,特征图看起来很嘈杂。
4.结论
提出了一种新的并行时间-频谱注意机制来获得环境声音的辨别性声音表征。ESC和ASC任务的实验结果和可视化分析验证了我们的方法的优点。在未来的工作中,我们希望将其应用于其他音频分类任务。
PYHTON代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.nn.utils import weight_norm
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ConvBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1), bias=False)
self.conv2 = nn.Conv2d(in_channels=out_channels,
out_channels=out_channels,
kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1), bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def show(self, input, pool_size=(2, 2), pool_type='avg'):
x = input
x = F.relu_(self.bn1(self.conv1(x)))
x = F.relu_(self.bn2(self.conv2(x)))
return x
def forward(self, input, pool_size=(2, 2), pool_type='avg'):
x = input
x = F.relu_(self.bn1(self.conv1(x)))
x = F.relu_(self.bn2(self.conv2(x)))
if pool_type == 'max':
x = F.max_pool2d(x, kernel_size=pool_size)
elif pool_type == 'avg':
x = F.avg_pool2d(x, kernel_size=pool_size)
else:
raise Exception('Incorrect argument!')
return x
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class TFBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(TFBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1), bias=False)
self.conv2 = nn.Conv2d(in_channels=out_channels,
out_channels=out_channels,
kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1), bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.alpha = nn.Parameter(torch.cuda.FloatTensor([.1, .1, .1]))
self.bnx = nn.BatchNorm2d(1)
self.bny = nn.BatchNorm2d(1)
self.bnz = nn.BatchNorm2d(out_channels)
self.bna = nn.BatchNorm2d(out_channels)
self.bnb = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(in_channels=out_channels,
out_channels=1,
kernel_size=(1, 1), stride=(1, 1),
padding=(0, 0), bias=False)
self.conv4 = nn.Conv2d(in_channels=out_channels,
out_channels=1,
kernel_size=(1, 1), stride=(1, 1),
padding=(0, 0), bias=False)
if out_channels == 64:
self.globalAvgPool2 = nn.AvgPool2d((250,1), stride=1)
self.globalAvgPool3 = nn.AvgPool2d((1,40), stride=1)
self.globalMaxPool2 = nn.MaxPool2d((1,64), stride=1)
self.globalMaxPool3 = nn.MaxPool2d((64,1), stride=1)
self.fc1 = nn.Linear(in_features=40, out_features=40)
self.fc2 = nn.Linear(in_features=250, out_features=250)
elif out_channels == 128:
self.globalAvgPool2 = nn.AvgPool2d((125,1), stride=1)
self.globalAvgPool3 = nn.AvgPool2d((1,20), stride=1)
self.globalMaxPool2 = nn.MaxPool2d((1,128), stride=1)
self.globalMaxPool3 = nn.MaxPool2d((128,1), stride=1)
self.fc1 = nn.Linear(in_features=20, out_features=20)
self.fc2 = nn.Linear(in_features=125, out_features=125)
elif out_channels == 256:
self.globalAvgPool2 = nn.AvgPool2d((62,1), stride=1)
self.globalAvgPool3 = nn.AvgPool2d((1,10), stride=1)
self.globalMaxPool2 = nn.MaxPool2d((1,128), stride=1)
self.globalMaxPool3 = nn.MaxPool2d((128,1), stride=1)
self.fc1 = nn.Linear(in_features=10, out_features=10)
self.fc2 = nn.Linear(in_features=62, out_features=62)
elif out_channels == 512:
self.globalAvgPool2 = nn.AvgPool2d((31,1), stride=1)
self.globalAvgPool3 = nn.AvgPool2d((1,5), stride=1)
self.globalMaxPool2 = nn.MaxPool2d((1,128), stride=1)
self.globalMaxPool3 = nn.MaxPool2d((128,1), stride=1)
self.fc1 = nn.Linear(in_features=5, out_features=5)
self.fc2 = nn.Linear(in_features=31, out_features=31)
self.sigmoid = nn.Sigmoid()
self.sigmoid2 = nn.Sigmoid()
self.downsample = conv1x1(in_channels, out_channels)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.LeakyReLU(0.2)
def show(self, input, pool_size=(2, 2), pool_type='avg'):
x = input
x = self.bn1(self.relu(self.conv1(x)))
x = self.bn2(self.relu(self.conv2(x)))
out1 = x.clone()
res = x.clone()
y = x.clone()
y = self.bnx(self.relu(self.conv3(y)))
out6 = y.clone()
res_2 = x.clone()
z = x.clone()
z = self.bny(self.relu(self.conv4(z)))
res_3 = x.clone()
out7 = z.clone()
h = x.clone()
res_2 = res_2.transpose(1,3)
y = y.transpose(1,3)
y = self.globalAvgPool2(y)
y = y.view(y.size(0), -1)
y = self.sigmoid(y)
y = y.view(y.size(0), y.size(1), 1, 1)
y = y * res_2
y = y.transpose(1,3)
y = self.bna(y)
out2=y.clone()
res_3 = res_3.transpose(1,2)
z = z.transpose(1,2)
z = self.globalAvgPool3(z)
z = z.view(z.size(0), -1)
z = self.sigmoid(z)
z = z.view(z.size(0), z.size(1), 1, 1)
z = z * res_3
z = z.transpose(1,2)
z = self.bnb(z)
out3 = z.clone()
so_alpha = F.softmax(self.alpha,dim=0)
x = so_alpha[0]*h + so_alpha[1]*y + so_alpha[2]*z
x = self.relu(x)
out4 = x.clone()
if pool_type == 'max':
x = F.max_pool2d(x, kernel_size=pool_size)
elif pool_type == 'avg':
x = F.avg_pool2d(x, kernel_size=pool_size)
else:
raise Exception('Incorrect argument!')
out5 = x.clone()
out1 = torch.mean(out1, dim=1)
out2 = torch.mean(out2, dim=1)
out3 = torch.mean(out3, dim=1)
out4 = torch.mean(out4, dim=1)
out5 = torch.mean(out5, dim=1)
return out1, out2, out3, out4, out5, out6, out7
def forward(self, input, pool_size=(2, 2), pool_type='avg'):
x = input
x = self.bn1(self.relu(self.conv1(x)))
x = self.bn2(self.relu(self.conv2(x)))
res = x.clone()
y = x.clone()
y = self.bnx(self.relu(self.conv3(y)))
res_2 = x.clone()
z = x.clone()
z = self.bny(self.relu(self.conv4(z)))
res_3 = x.clone()
h = x.clone()
res_2 = res_2.transpose(1,3)
y = y.transpose(1,3)
y = self.globalAvgPool2(y)
y = y.view(y.size(0), -1)
y = self.sigmoid(y)
y = y.view(y.size(0), y.size(1), 1, 1)
y = y * res_2
y = y.transpose(1,3)
y = self.bna(y)
res_3 = res_3.transpose(1,2)
z = z.transpose(1,2)
z = self.globalAvgPool3(z)
z = z.view(z.size(0), -1)
z = self.sigmoid(z)
z = z.view(z.size(0), z.size(1), 1, 1)
z = z * res_3
z = z.transpose(1,2)
z = self.bnb(z)
so_alpha = F.softmax(self.alpha,dim=0)
x = so_alpha[0]*h + so_alpha[1]*y + so_alpha[2]*z
x = self.relu(x)
if pool_type == 'max':
x = F.max_pool2d(x, kernel_size=pool_size)
elif pool_type == 'avg':
x = F.avg_pool2d(x, kernel_size=pool_size)
else:
raise Exception('Incorrect argument!')
return x
class TFNet(nn.Module):
def __init__(self, classes_num=10, activation='logsoftmax'):
super(TFNet, self).__init__()
self.activation = activation
self.tfblock1 = TFBlock(in_channels=1, out_channels=64)
self.tfblock2 = TFBlock(in_channels=64, out_channels=128)
self.tfblock3 = TFBlock(in_channels=128, out_channels=256)
self.tfblock4 = TFBlock(in_channels=256, out_channels=512)
self.fc = nn.Linear(512, classes_num, bias=True)
def show(self, input):
x = input[:,None,:,:]
'''(batch_size, 1, times_steps, freq_bins)'''
out1, out2, out3, out4, out5, out6, out7 = self.conv_block1.show(x)
x = self.tfblock1(x, pool_size=(2, 2), pool_type='avg')
x1 = torch.mean(x, dim=1)
x = self.tfblock2(x, pool_size=(2, 2), pool_type='avg')
x2 = torch.mean(x, dim=1)
x = self.tfblock3(x, pool_size=(2, 2), pool_type='avg')
x3 = torch.mean(x, dim=1)
x = self.tfblock4(x, pool_size=(2, 2), pool_type='avg')
x4 = torch.mean(x, dim=1)
return x1, x2, x3, x4, out1, out2, out3, out4, out5, out6, out7
def forward(self, input):
'''
Input: (batch_size, seq_number, times_steps, freq_bins)'''
x = input[:, 0 , : , :]
x = x[:, None, :, :]
'''(batch_size, 1, times_steps, freq_bins)'''
x = self.tfblock1(x, pool_size=(2, 2), pool_type='avg')
x = self.tfblock2(x, pool_size=(2, 2), pool_type='avg')
x = self.tfblock3(x, pool_size=(2, 2), pool_type='avg')
x = self.tfblock4(x, pool_size=(2, 2), pool_type='avg')
'''(batch_size, feature_maps, time_steps, freq_bins)'''
x = torch.mean(x, dim=3) # (batch_size, feature_maps, time_stpes)
(x, _) = torch.max(x, dim=2) # (batch_size, feature_maps)
x = self.fc(x)
if self.activation == 'logsoftmax':
output = F.log_softmax(x, dim=-1)
elif self.activation == 'sigmoid':
output = torch.sigmoid(x)
return output
class Cnn(nn.Module):
def __init__(self, classes_num=50, activation='logsoftmax'):
super(Cnn, self).__init__()
self.activation = activation
self.conv_block1 = ConvBlock(in_channels=1, out_channels=64)
self.conv_block2 = ConvBlock(in_channels=64, out_channels=128)
self.conv_block3 = ConvBlock(in_channels=128, out_channels=256)
self.conv_block4 = ConvBlock(in_channels=256, out_channels=512)
self.fc2 = nn.Linear(512, 512, bias=True)
self.dropout = nn.Dropout(p=0.5)
self.fc = nn.Linear(512, classes_num, bias=True)
def forward(self, input):
'''
Input: (batch_size, seq_number, times_steps, freq_bins)'''
x = input[:, 0, :, :]
x = x[:, None, :, :]
'''(batch_size, 1, times_steps, freq_bins)'''
x = self.conv_block1(x, pool_size=(2, 2), pool_type='avg')
x = self.conv_block2(x, pool_size=(2, 2), pool_type='avg')
x = self.conv_block3(x, pool_size=(2, 2), pool_type='avg')
x = self.conv_block4(x, pool_size=(2, 2), pool_type='avg')
'''(batch_size, feature_maps, time_steps, freq_bins)'''
x = torch.mean(x, dim=3) # (batch_size, feature_maps, time_stpes)
(x, _) = torch.max(x, dim=2) # (batch_size, feature_maps)
x = self.fc(x)
if self.activation == 'logsoftmax':
output = F.log_softmax(x, dim=-1)
elif self.activation == 'sigmoid':
output = torch.sigmoid(x)
return output















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









