






 论文介绍了一种方法,通过优化LLM生成的合成数据,使其更接近真实世界数据(GoldData),以提高小模型的性能。方法包括生成种子数据、训练模型、反馈错误并迭代改进。实验结果显示,使用S3方法微调DistilBERT模型时效果最佳。
论文介绍了一种方法,通过优化LLM生成的合成数据,使其更接近真实世界数据(GoldData),以提高小模型的性能。方法包括生成种子数据、训练模型、反馈错误并迭代改进。实验结果显示,使用S3方法微调DistilBERT模型时效果最佳。

这篇论文是23年10月发表的,针对使用LLM合成数据来训练小模型这个场景进行了优化,使得合成数据和真实世界数据(gold data)更接近,以此提升小模型性能。

根据下图可以看到,直接用LLM生成的数据,也就是ZeroGen论文方法,训练和测试有很大准确度差异,这是因为这样的合成数据与真实世界数据存在一个分布上的gap。而GoldData是用真实世界数据来训练的,可以看到训练和测试的差异小了很多。
基于这点作者提出如果能让LLM合成的数据更接近真实世界数据,那么用这个数据来训练小模型的话效果就会更好。
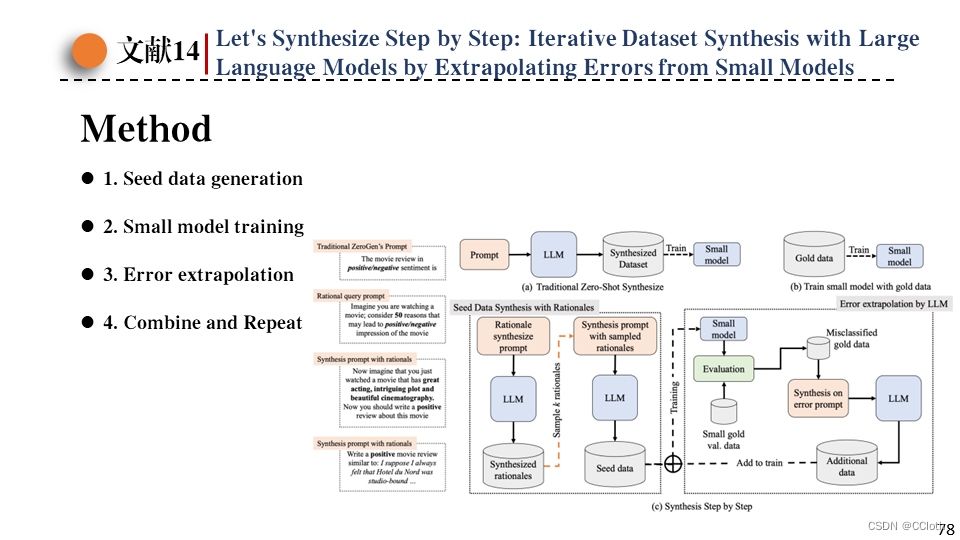
作者提出的方法分为四个步骤,第一步是先生成种子数据,第二步是用种子数据训练小模型,第三步是把验证集中小模型分类错误的数据给LLM让其生成类似的数据,然后添加到训练数据集中,第四步就是重复第二步和第三步,直到小模型性能收敛。

这里显示了第一步生成种子数据的伪代码,对于每个类别标签先利用LLM生成若干逻辑依据,然后让LLM考虑这些逻辑依据给出符合该标签的prompt。例如影评态度分类,对于积极这个类别,让LLM先给出若干依据,比如表现力强、剧情跌宕起伏等等,然后让LLM想象自己正在看表现力强、剧情跌宕起伏的这么一部电影,让它给出积极的影评。这一步收集到的所有数据作为种子数据集。

这里右图显示了剩下几步的伪代码,R为迭代轮数,人类标注的真实世界的数据叫做gold data,将gold data划分为验证集和测试集,每次迭代都需要用目前已有的数据训练小模型,然后用验证集验证小模型,分类失败的数据会交给LLM,让它再生成类似的数据并加入到训练数据中。R轮迭代之后就得到了最终的训练数据。左图是在影评态度分类这个任务上的prompt。
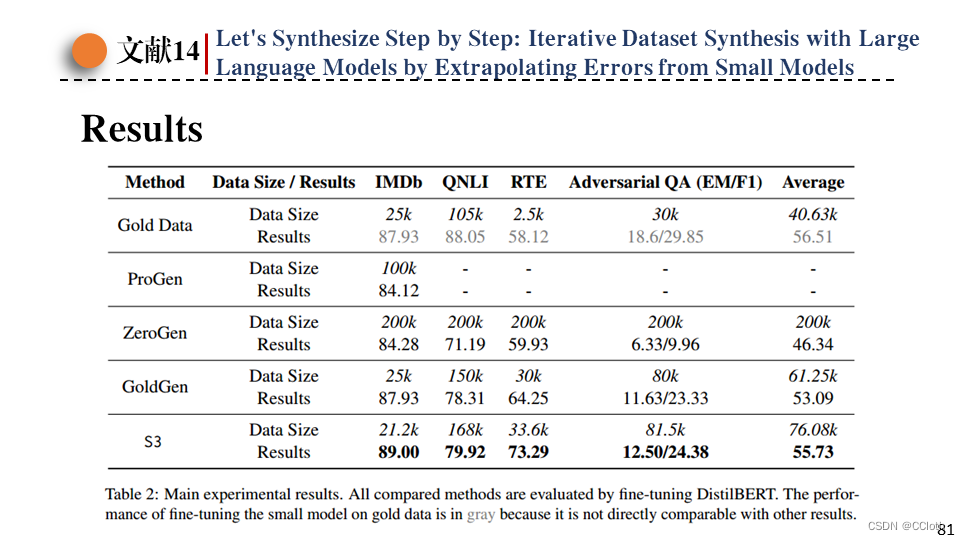
图里展示了对DistilBERT模型进行微调的结果,使用S3方法产生的数据集来微调效果最好,在四个数据集上都达到了最优表现。(但这里gold data直接标灰不参与对比我不认同,虽然这篇论文就是标榜只用少量gold data来合成大量近似gold data的数据,但是既然有更优质的数据为什么不用于训练,而且你这里合成的数据质量也达不到很好,也没有很接近gold data,毕竟用了那么多数据训练结果有些数据集上离gold data差挺远的)

















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









