






目录
介绍
在研究了YOLOv8、YOLOv9、YOLOv10甚至YOLOv11之后,我们很高兴地推出 YOLO 系列的最新版本:YOLOv12!这个新版本采用了以注意力为中心的架构,改变了实时对象检测的方式。它还为准确性和效率树立了新标准。
YOLOv12 有什么新功能?
由于注意力机制效率低下,大多数对象检测架构传统上都依赖于卷积神经网络 (CNN),注意力机制需要应对二次计算复杂度和低效的内存访问操作。因此,在 YOLO 框架中,基于 CNN 的模型通常优于基于注意力的系统,因为高推理速度至关重要。
YOLOv12试图通过三项关键改进来克服这些限制:
区域注意模块(A2):
- YOLOv12 引入了简单高效的区域注意力模块(A2),将特征图分割成多个片段,以保留较大的感受野,同时降低传统注意力机制的计算复杂度。这一简单的修改使模型在提高速度和效率的同时,保留了较大的视野。
残差高效层聚合网络(R-ELAN):
- YOLOv12 利用R-ELAN解决注意力机制带来的优化挑战。R-ELAN 在之前的ELAN架构基础上进行了改进,具体如下:
- 块级残差连接和缩放技术,确保稳定的训练。
- 重新设计的特征聚合方法,可提高性能和效率。
建筑改进:
- FlashAttention:集成FlashAttention,解决注意力机制的内存访问瓶颈,优化内存操作,提升速度。
- 去除位置编码:通过消除位置编码,YOLOv12 简化了模型,使其更快、更干净,同时又不牺牲性能。
- 调整MLP比例:多层感知器(MLP)的扩展比例从4降低到1.2,以平衡注意力和前馈网络之间的计算负荷,提高效率。
- 减少块深度:通过减少架构中堆叠块的数量,YOLOv12 简化了优化过程并提高了推理速度。
- 卷积算子: YOLOv12 充分利用卷积算子来提高其计算效率,进一步提高性能并减少延迟。
架构概述
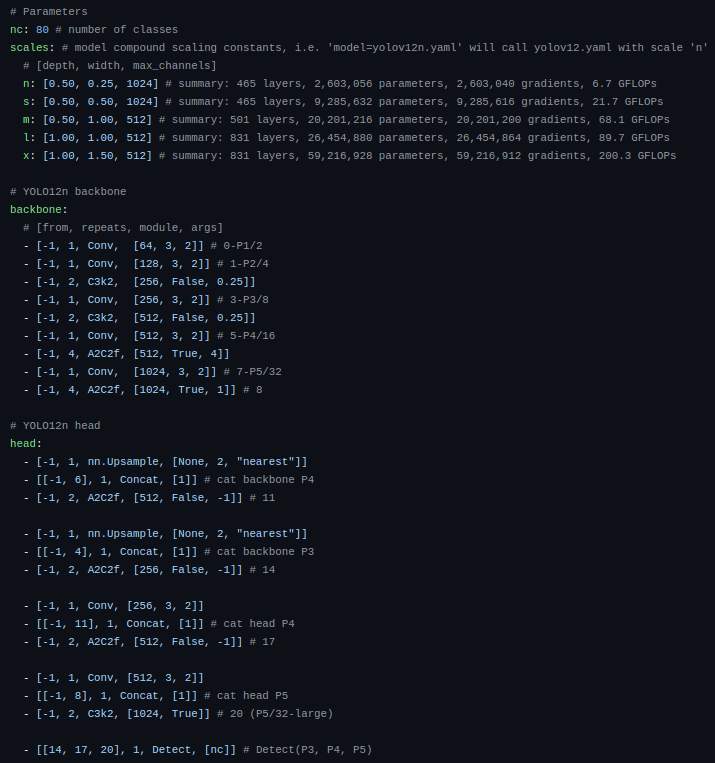
YOLOv12 框架。如上一节所述,我们现在将详细说明三个关键改进,即区域注意模块、残差高效层聚合网络 (R-ELAN) 模块和原始注意机制的改进。
区域注意模块

残差高效层聚合网络(R-ELAN)
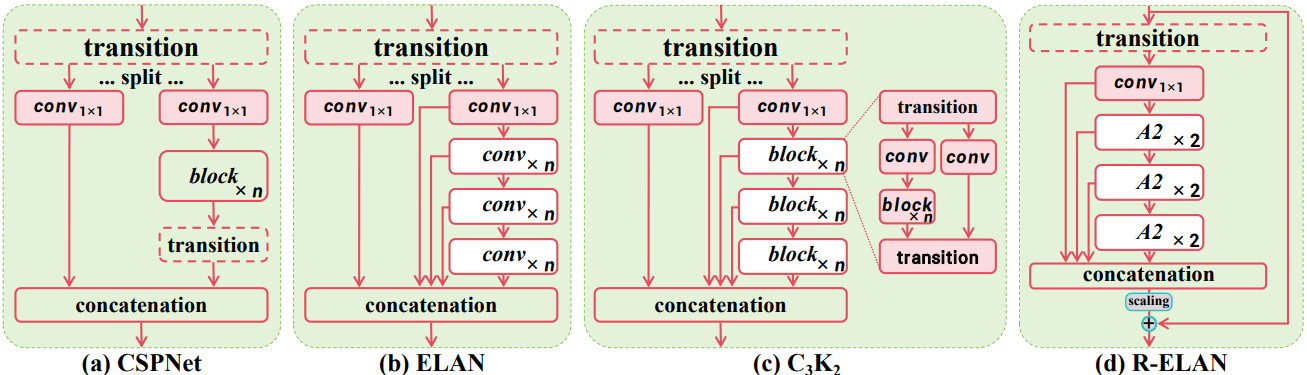
ELAN 概述:
早期的 YOLO 模型中使用了高效层聚合网络 (ELAN)来改进特征聚合。ELAN 的工作原理如下:
- 分割1×1 卷积层的输出。
- 通过多个模块处理这些分割。
- 在应用另一个 1×1 卷积之前连接输出以对齐最终维度。
ELAN 的问题:
- 梯度阻塞:由于缺少从输入到输出的残差连接而导致不稳定。
- 优化挑战:注意力机制和架构可能导致收敛问题,即使使用 Adam 或 AdamW 优化器,L 和 X 规模模型也无法收敛或保持不稳定。
建议的解决方案——R-ELAN:
- 残差连接:引入从输入到输出的残差快捷方式,并带有缩放因子(默认值为 0.01),以提高稳定性。
- 层缩放类比:类似于深度视觉变换器中使用的层缩放,但避免了将层缩放应用于每个区域注意模块而导致的速度减慢。
新的聚合方法:
- 修改后的设计:新方法不再在过渡层后分割输出,而是调整通道尺寸并创建单个特征图。
- 瓶颈结构:在连接之前通过后续块处理特征图,形成更高效的聚合方法。
架构改进
- FlashAttention:YOLOv12 利用 FlashAttention,最大限度地减少内存访问开销。这解决了注意力机制的主要内存瓶颈,缩小了与 CNN 的速度差距。
- MLP 比例调整:前馈网络扩展比例从 Transformers 中常见的 4 降低到 YOLOv12 中的 1.2 左右,避免 MLP 独霸运行时间,从而提高整体效率。
- 删除位置编码:YOLOv12 在其注意层中省略了显式位置编码。这使得模型“快速而干净”,并且检测性能没有任何损失。
- 减少堆叠块:最近的 YOLO 主干在最后阶段堆叠了三个注意力/CNN 块;而 YOLOv12 在该阶段仅使用单个 R-ELAN 块。较少的连续块可简化优化并提高推理速度,尤其是在更深的模型中。
- 卷积运算符:该架构还使用具有批量规范的卷积而不是具有层规范的线性层,以充分利用卷积运算符的效率。
YOLOv12 的基准测试
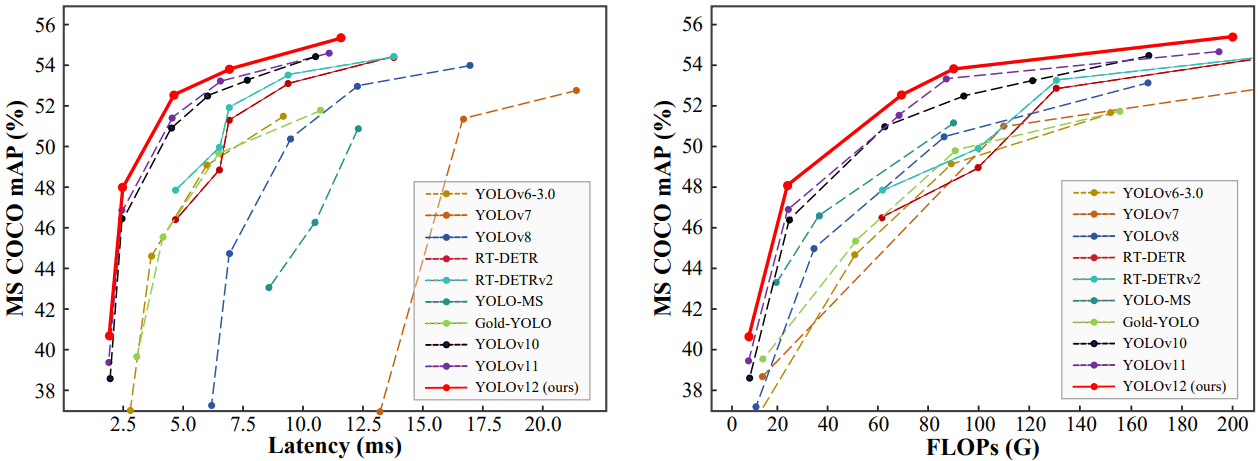
图 4:YOLOv12 比较
数据集:所有模型均在 MS COCO 2017 对象检测基准上进行评估。
YOLOv12-N 性能:最小的 YOLOv12-N 与 YOLOv10-N(38.5%)或 YOLOv11-N(39.4%)相比,实现了 40.6% 更高的 mAP,同时保持了相似的推理延迟。
YOLOv12-S 与 RT-DETR: YOLOv12-S 模型也优于 RT-DETR 模型。值得注意的是,它的运行速度比 RT-DETR-R18 模型快约 42%,而使用的计算量仅为 RT-DETR-R18 的约 36%,参数仅为 RT-DETR-R18 的约 45% 。
strongsort介绍
三个要点
✔️ 改进了MOT任务中的早期深度模型DeepSORT,实现了SOTA!
✔️ 提出了两种计算成本较低的后处理方法AFLink和GSI,以进一步提高准确度!
✔️ AFLink和GSI提高了几个模型的准确性,不仅仅是所提出的方法!
性能指标图
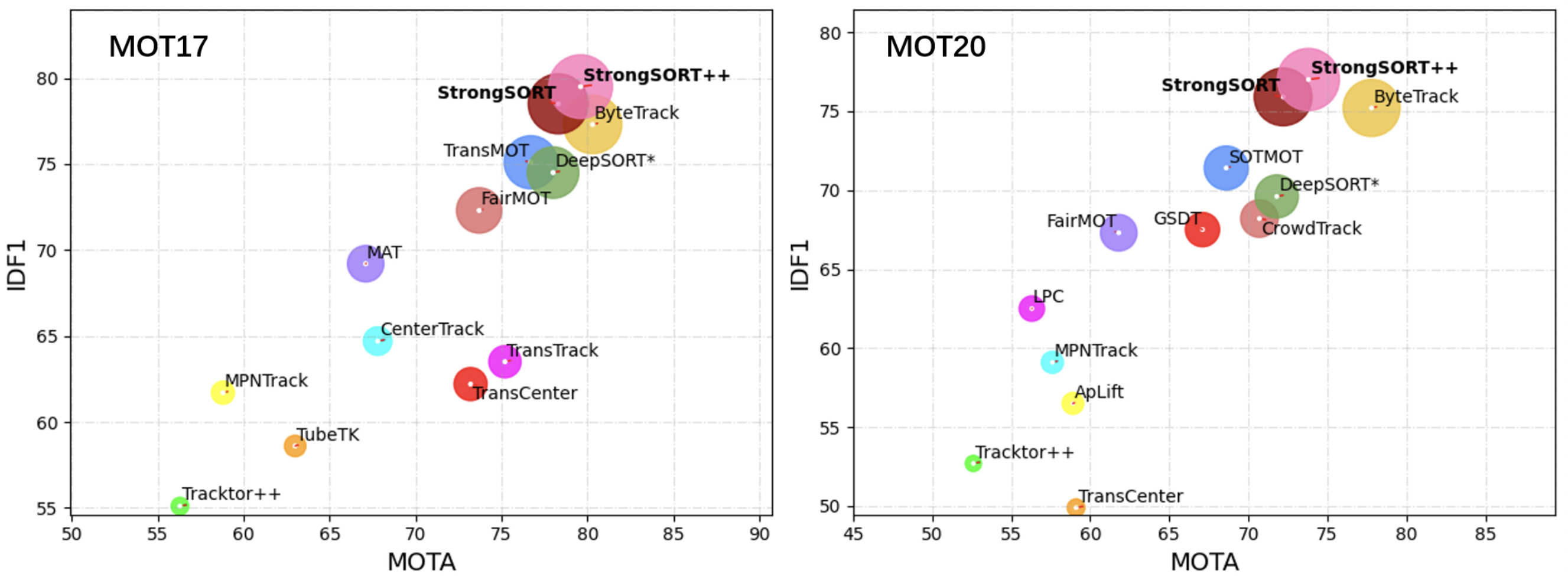
首先,我附上了MOT17和MOT20的准确性比较,这表明了StrongSORT的优越性。现在,VGGNet,一个著名的特征提取器,最近作为RepVGG,一个更强大的版本回归。以类似的标题回归的是StrongSORT:让DeepSORT再次伟大,其中DeepSORT是一个早期的基于深度学习的物体追踪模型,而StrongSORT是对这个早期模型的改进,采用最新的技术实现SOTAStrongSORT是一个通过用最新技术在初始模型上进行改进而实现SOTA的模型。让我们先快速看一下这些改进。
DeepSORT
+BoT:改进的外观特征提取器
+EMA:带有惯性项的特征更新
+NSA:用于非线性运动的卡尔曼滤波器
+MC:包括运动信息的成本矩阵
+ECC:摄像机运动更正
+woC:不采用级联算法
=StrongSORT
+AF链接:仅使用运动信息的全局链接
=StrongSORT+
+GSI内插:通过高斯过程对检测误差进行内插
=StrongSORT++
与其说从根本上改变了结构,不如说是改进了跟踪所需的特征提取、运动信息和成本矩阵的处理。StrongSORT++将AFLink(离线处理)和GSI插值(后处理)应用于改进的StrongSORT,是一个更加精确的模型。我个人认为关键在于此,所以如果你能读到最后,我将很高兴。让我们快速了解一下StrongSORT。
系统定位
本节首先解释了这一方法的系统定位。想了解该方法细节的人可以跳过这一节。深度学习跟踪方法始于DeepSORT。后来,出现了FairMOT和ByteTrack等新方法,并超越了DeepSORT的准确性。在提出新的追踪方法的过程中,出现了两种追踪方法。DeepSORT属于SDE,其检测器是单独准备的。它属于SDE。然而,在本文中,DeepSORT的低准确性并不是因为方法不好,而只是因为它的年龄,其动机是,如果根据此后提出的最新元素技术进行改进,就可以使它变得足够准确。我们有动力去改进它。
改进DeepSORT的原因还有很多。首先,JDE方法的缺点是不容易训练:JDE同时训练检测和跟踪等不同任务的参数,所以模型容易发生冲突,从而限制了准确性。它还需要一个可以同时从检测到跟踪进行训练的数据集,这限制了训练的范围。相比之下,使用SDE,检测和跟踪模型可以被单独优化。最近,诸如ByteTrack这样的模型也被提出来,用于仅基于运动信息的高速跟踪,而没有任何外观信息,但这种模型指出了当目标的运动不简单时无法跟踪的问题。
因此,基于在基于DeepSORT的SDE方法中使用外观特征进行追踪是最佳的动机,提出了StrongSORT。
效果展示
训练与预测


UI设计
将本次的实验使用pyqt打包,方便体验
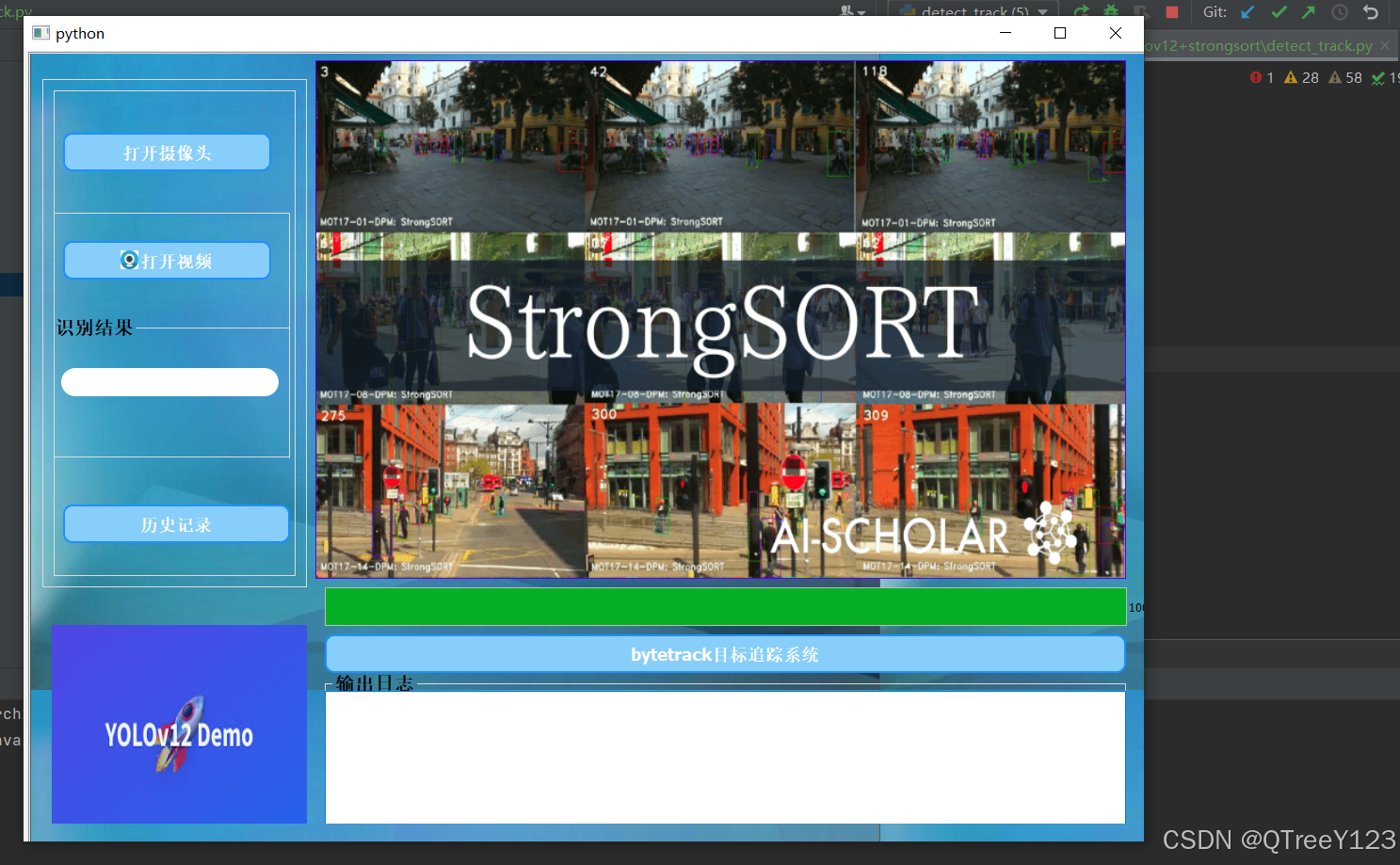
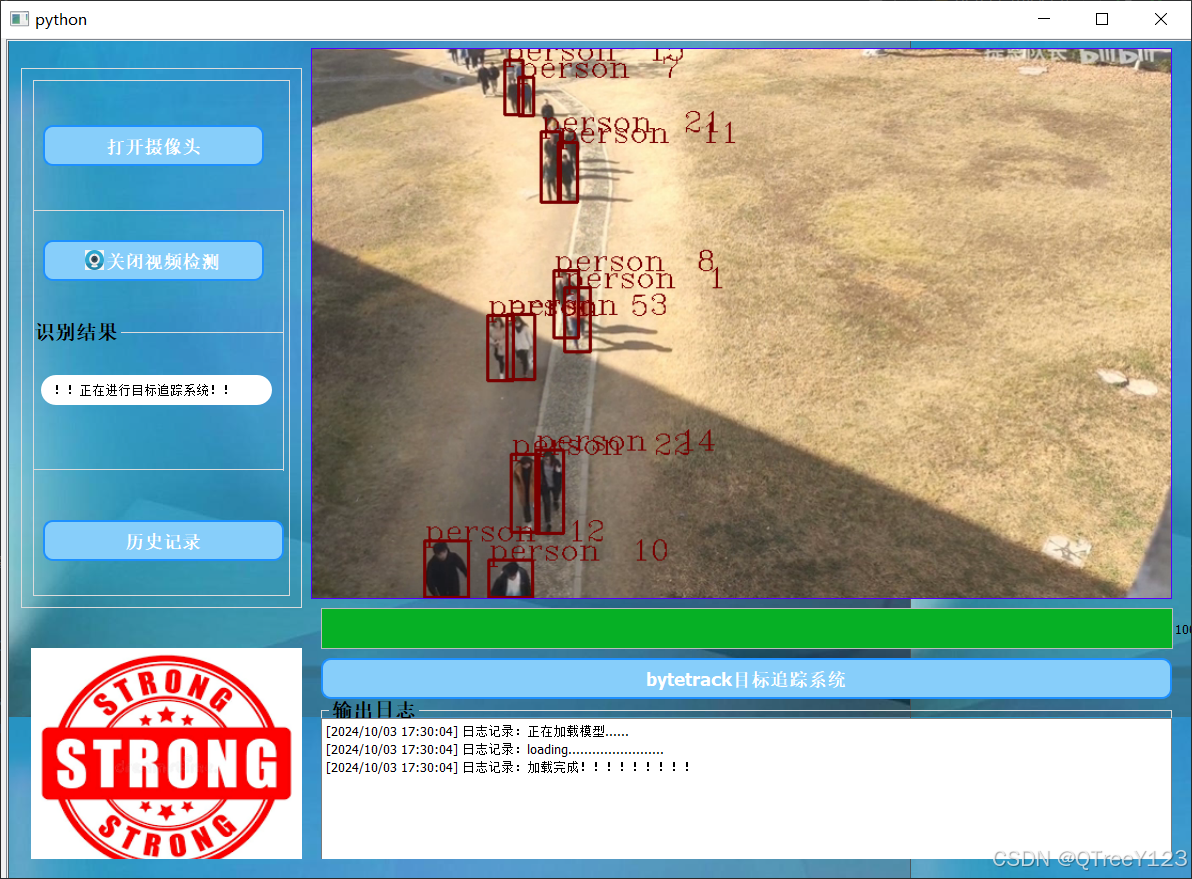
界面其他功能展示
其他功能演示参考yolov5+deepsort文章
两万字深入浅出yolov5+deepsort实现目标跟踪,含完整代码, yolov,卡尔曼滤波估计,ReID目标重识别,匈牙利匹配KM算法匹配_yolov5 deepsort-CSDN博客
完整代码实现+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









