






目录
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
介绍
在研究了YOLOv8、YOLOv9、YOLOv10甚至YOLOv11之后,我们很高兴地推出 YOLO 系列的最新版本:YOLOv12!这个新版本采用了以注意力为中心的架构,改变了实时对象检测的方式。它还为准确性和效率树立了新标准。
YOLOv12 有什么新功能?
由于注意力机制效率低下,大多数对象检测架构传统上都依赖于卷积神经网络 (CNN),注意力机制需要应对二次计算复杂度和低效的内存访问操作。因此,在 YOLO 框架中,基于 CNN 的模型通常优于基于注意力的系统,因为高推理速度至关重要。
YOLOv12试图通过三项关键改进来克服这些限制:
区域注意模块(A2):
- YOLOv12 引入了简单高效的区域注意力模块(A2),将特征图分割成多个片段,以保留较大的感受野,同时降低传统注意力机制的计算复杂度。这一简单的修改使模型在提高速度和效率的同时,保留了较大的视野。
残差高效层聚合网络(R-ELAN):
- YOLOv12 利用R-ELAN解决注意力机制带来的优化挑战。R-ELAN 在之前的ELAN架构基础上进行了改进,具体如下:
- 块级残差连接和缩放技术,确保稳定的训练。
- 重新设计的特征聚合方法,可提高性能和效率。
建筑改进:
- FlashAttention:集成FlashAttention,解决注意力机制的内存访问瓶颈,优化内存操作,提升速度。
- 去除位置编码:通过消除位置编码,YOLOv12 简化了模型,使其更快、更干净,同时又不牺牲性能。
- 调整MLP比例:多层感知器(MLP)的扩展比例从4降低到1.2,以平衡注意力和前馈网络之间的计算负荷,提高效率。
- 减少块深度:通过减少架构中堆叠块的数量,YOLOv12 简化了优化过程并提高了推理速度。
- 卷积算子: YOLOv12 充分利用卷积算子来提高其计算效率,进一步提高性能并减少延迟。
架构概述
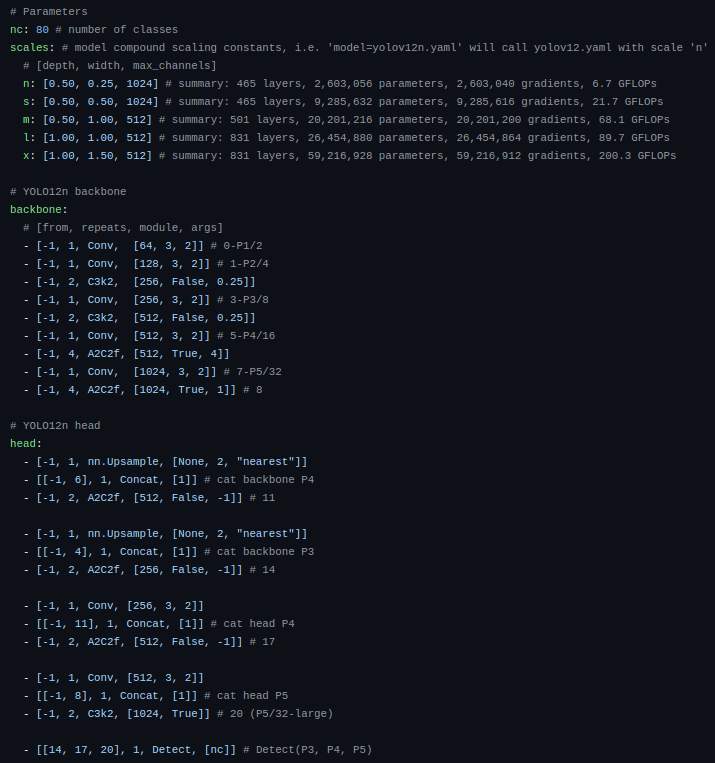
YOLOv12 框架。如上一节所述,我们现在将详细说明三个关键改进,即区域注意模块、残差高效层聚合网络 (R-ELAN) 模块和原始注意机制的改进。
区域注意模块

残差高效层聚合网络(R-ELAN)
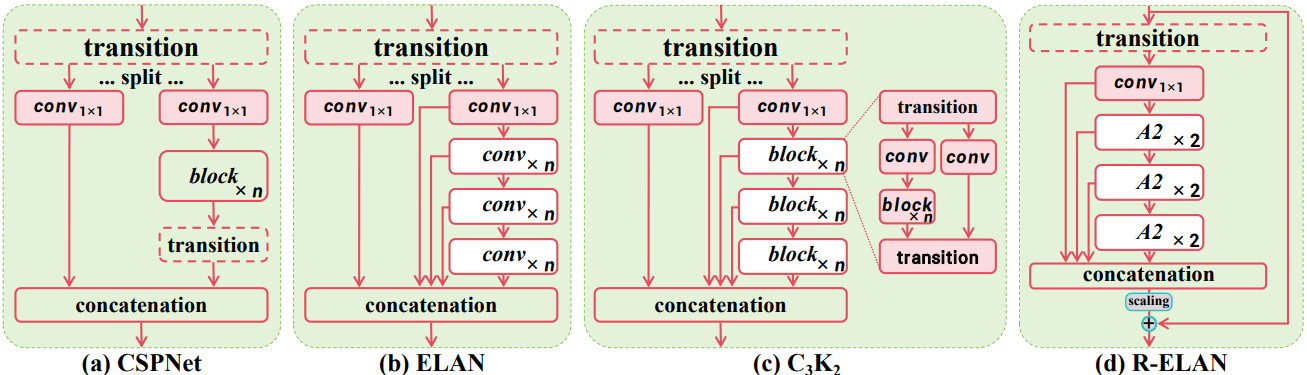
ELAN 概述:
早期的 YOLO 模型中使用了高效层聚合网络 (ELAN)来改进特征聚合。ELAN 的工作原理如下:
- 分割1×1 卷积层的输出。
- 通过多个模块处理这些分割。
- 在应用另一个 1×1 卷积之前连接输出以对齐最终维度。
ELAN 的问题:
- 梯度阻塞:由于缺少从输入到输出的残差连接而导致不稳定。
- 优化挑战:注意力机制和架构可能导致收敛问题,即使使用 Adam 或 AdamW 优化器,L 和 X 规模模型也无法收敛或保持不稳定。
建议的解决方案——R-ELAN:
- 残差连接:引入从输入到输出的残差快捷方式,并带有缩放因子(默认值为 0.01),以提高稳定性。
- 层缩放类比:类似于深度视觉变换器中使用的层缩放,但避免了将层缩放应用于每个区域注意模块而导致的速度减慢。
新的聚合方法:
- 修改后的设计:新方法不再在过渡层后分割输出,而是调整通道尺寸并创建单个特征图。
- 瓶颈结构:在连接之前通过后续块处理特征图,形成更高效的聚合方法。
架构改进
- FlashAttention:YOLOv12 利用 FlashAttention,最大限度地减少内存访问开销。这解决了注意力机制的主要内存瓶颈,缩小了与 CNN 的速度差距。
- MLP 比例调整:前馈网络扩展比例从 Transformers 中常见的 4 降低到 YOLOv12 中的 1.2 左右,避免 MLP 独霸运行时间,从而提高整体效率。
- 删除位置编码:YOLOv12 在其注意层中省略了显式位置编码。这使得模型“快速而干净”,并且检测性能没有任何损失。
- 减少堆叠块:最近的 YOLO 主干在最后阶段堆叠了三个注意力/CNN 块;而 YOLOv12 在该阶段仅使用单个 R-ELAN 块。较少的连续块可简化优化并提高推理速度,尤其是在更深的模型中。
- 卷积运算符:该架构还使用具有批量规范的卷积而不是具有层规范的线性层,以充分利用卷积运算符的效率。
YOLOv12 的基准测试
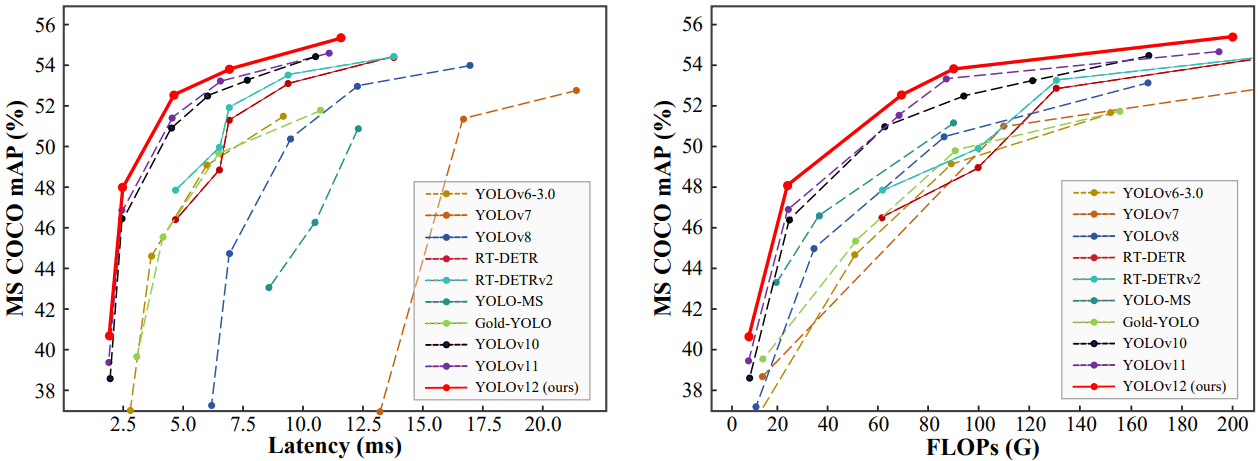
图 4:YOLOv12 比较
数据集:所有模型均在 MS COCO 2017 对象检测基准上进行评估。
YOLOv12-N 性能:最小的 YOLOv12-N 与 YOLOv10-N(38.5%)或 YOLOv11-N(39.4%)相比,实现了 40.6% 更高的 mAP,同时保持了相似的推理延迟。
YOLOv12-S 与 RT-DETR: YOLOv12-S 模型也优于 RT-DETR 模型。值得注意的是,它的运行速度比 RT-DETR-R18 模型快约 42%,而使用的计算量仅为 RT-DETR-R18 的约 36%,参数仅为 RT-DETR-R18 的约 45% 。
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
沿着多目标跟踪(MOT)中tracking-by-detection的范式,我们提出了一种简单高效的数据关联方法BYTE。 利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的物体(遮挡、模糊等困难样本),从而降低漏检并提高轨迹的连贯性。BYTE能轻松应用到9种state-of-the-art的MOT方法中,并取得1-10个点不等的IDF1指标的提升。基于BYTE我们提出了一个跟踪方法ByteTrack,首次以30 FPS的运行速度在MOT17上取得80.3 MOTA,77.3 IDF1和63.1 HOTA,目前位居MOTChallenge榜单第一。我们还在开源代码中加入了将BYTE应用到不同MOT方法中的教程以及ByteTrack的部署代码。
Paper: http://arxiv.org/abs/2110.06864

纵轴是MOTA,横轴是FPS,圆的半径代表IDF1的相对大小
1. Motivation
Tracking-by-detection是MOT中的一个经典高效的流派,通过相似度(位置、外观、运动等信息)来关联检测框得到跟踪轨迹。由于视频中场景的复杂性,检测器无法得到完美的检测结果。为了处理true positive/false positive的trade-off,目前大部分MOT方法会选择一个阈值,只保留高于这个阈值的检测结果来做关联得到跟踪结果,低于这个阈值的检测结果直接丢弃。但是这样做合理吗?答案是否定的。黑格尔说过:“存在即合理。”低分检测框往往预示着物体的存在(例如遮挡严重的物体)。简单地把这些物体丢弃会给MOT带来不可逆转的错误,包括大量的漏检和轨迹中断,降低整体跟踪性能。
2. BYTE
为了解决之前方法丢弃低分检测框的不合理性,我们提出了一种简单、高效、通用的数据关联方法BYTE (each detection box is a basic unit of the tracklet, as byte in computer program)。直接地将低分框和高分框放在一起与轨迹关联显然是不可取的,会带来很多的背景(false positive)。BYTE将高分框和低分框分开处理,利用低分检测框和跟踪轨迹之间的相似性,从低分框中挖掘出真正的物体,过滤掉背景。整个流程如下图所示:
(1)BYTE会将每个检测框根据得分分成两类,高分框和低分框,总共进行两次匹配。
(2)第一次使用高分框和之前的跟踪轨迹进行匹配。
(3)第二次使用低分框和第一次没有匹配上高分框的跟踪轨迹(例如在当前帧受到严重遮挡导致得分下降的物体)进行匹配。
(4)对于没有匹配上跟踪轨迹,得分又足够高的检测框,我们对其新建一个跟踪轨迹。对于没有匹配上检测框的跟踪轨迹,我们会保留30帧,在其再次出现时再进行匹配。
我们认为,BYTE能work的原因是遮挡往往伴随着检测得分由高到低的缓慢降低:被遮挡物体在被遮挡之前是可视物体,检测分数较高,建立轨迹;当物体被遮挡时,通过检测框与轨迹的位置重合度就能把遮挡的物体从低分框中挖掘出来,保持轨迹的连贯性。

3. ByteTrack
ByteTrack使用当前性能非常优秀的检测器YOLOX得到检测结果。在数据关联的过程中,和SORT一样,只使用卡尔曼滤波来预测当前帧的跟踪轨迹在下一帧的位置,预测的框和实际的检测框之间的IoU作为两次匹配时的相似度,通过匈牙利算法完成匹配。这里值得注意的是我们没有使用ReID特征来计算外观相似度:
(1)第一点是为了尽可能做到简单高速,第二点是我们发现在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高,能够代替ReID进行物体间的长时刻关联。实验中也发现加入ReID对跟踪结果没有提升。
(2)如果需要引入ReID特征来计算外观相似度,可以参考我们开源代码中将BYTE应用到JDE,FairMOT等joint-detection-and-embedding方法中的教程。
(3)ByteTrack只使用运动模型没有使用外观相似度能在MOT17,20取得高性能的本质原因是MOT数据集的运动模式比较单一
4.具体代码



UI界面设计


历史记录

5.完整代码实现+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章


















 3092
3092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









