






论文地址:https://arxiv.org/pdf/2406.08100
代码地址:https://github.com/SpursGoZmy/Multimodal-Table-Understanding
当大家进入研究生阶段后,常常需要阅读以及汇报论文,大家都会很头疼,我就以《Multimodal Table Understanding》这篇中科院发表在ACL2024上的论文为例子,跟大家说一下要如何快速精简的汇报一篇论文。(包含ppt及讲稿)
零、框架梳理
一般汇报论文都需要分为四个部分进行介绍:
- 一、研究背景
- 二、研究方法
- 三、实验结果
- 四、总结和讨论
一、研究背景
首先,我们来看看他的研究背景,从重要性来看,表格被广泛应用于金融分析、科学研究和政府报告等领域,用于存储和展示数据。在局限性上看,大部分模型依赖于将表格转换为特定文本序列(如Markdown或HTML)作为模型输入,不能直接理解表格。而且在实际应用中,高质量的文本格式难以获取,而表格图像则更容易获取。

二、研究方法
我们再来看他的研究思路,本文研究主要是探索多模态表格理解的问题,为此,作者构建了一个大规模数据集MMTab,和Table-LLaLA模型,并与其他的模型进行了比较。

我们具体来看一下这个MMTab数据集是什么,从数据规模和多样性来看:MMTab数据集包含150K个预训练样本(MMTab-pre),232K个指令调整样本(MMTab-instruct),以及49K个测试样本(MMTab-eval),覆盖了17个内部测试基准和7个外部测试基准。且数据集涵盖了多种表格结构、样式和领域,包括简单的平面表格和复杂的具有合并单元格和层级标题的表格。除了9个学术任务(如表格问答、表格事实验证和表格转文本生成)外,MMTab还包含6个基本表格结构理解任务,如表格大小检测、单元格提取、单元格定位、合并单元格检测和行/列提取,以获取更加精确的模型。

介绍完了MMTab是什么,我们接下来看一下作者是如何构建的,这就是一个样本的具体构建方式,首先是先试用python脚本将文本表格转化为高质量的表格图像。然后就是利用GPT-4生成新的指令模板,并将其与任务相关的输入(如表格相关问题)结合,以产生最终的输入请求.在做完这两步后,我将渲染的表格图像和处理后的输入输出对组合成统一格式的多模态指令调整样本。并对他进行数据增强,包括表格级增强、指令集增强、任务级增强。最后在一个样本中,就包含表格、任务描述、任务输入、输出格式、思维链、最终的答案。
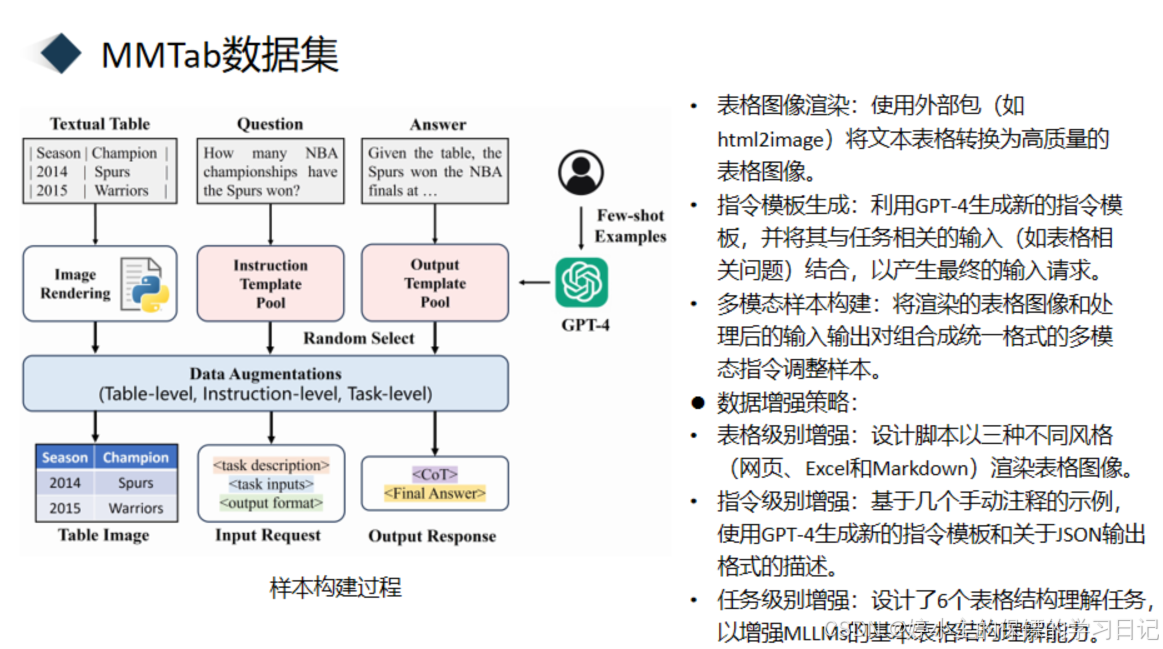
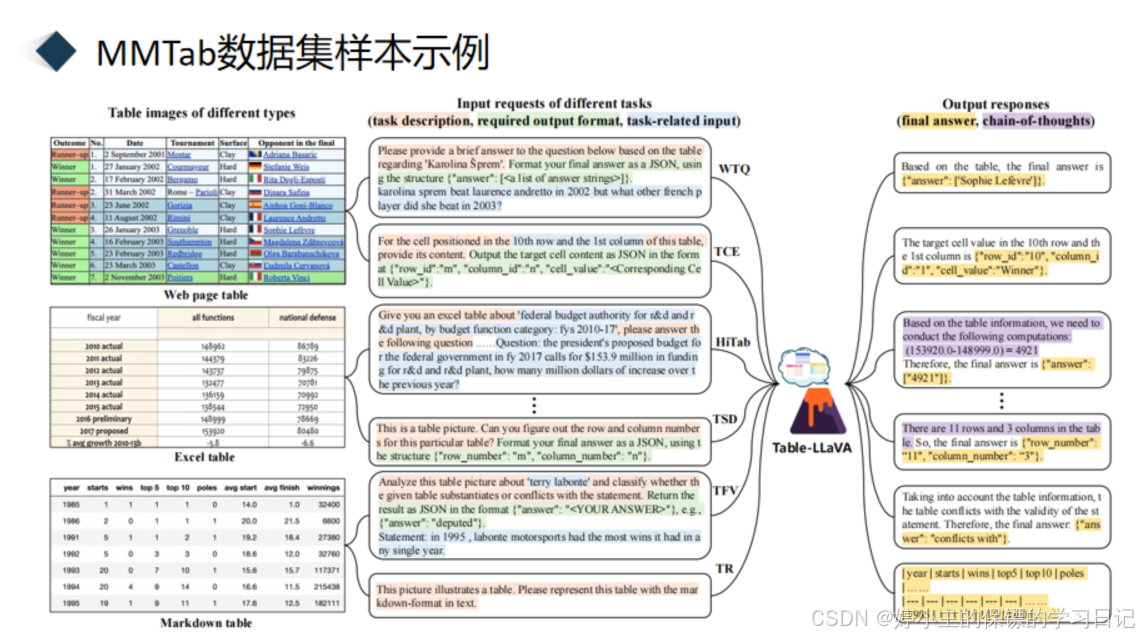
说了这么多,我们来看一个具体的样本示例,比如这里给了一个excel表,并且包含了任务描述说,这是一个表格图片,你能够计算这个表的行数和列数吗输出格式就是,形成一个JSON格式的最终答案,使用这个结构,行的数量为m,列的数量为n。然后思维链就是这是一个11行3列的表。最终答案为行的数量是11,列的数量为3.
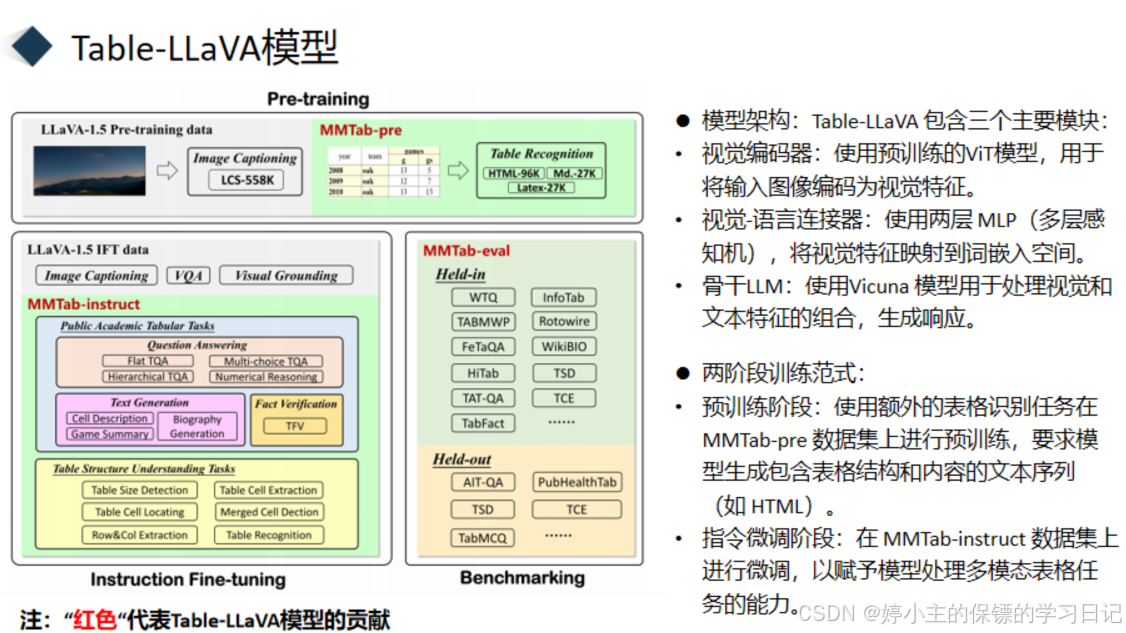
讲完了MMTab数据集的构建,我们再来讲一下这个作者提出的Table-LLaVA模型,模型架构包含三个模块,分别是视觉编码器,它是使用预训练的ViT模型,用于将输入图像编码为视觉特征。视觉-语言连接器,它是使用两层 MLP(多层感知机),将视觉特征映射到词嵌入空间。还有它的骨干LLM:使用Vicuna 模型用于处理视觉和文本特征的组合,生成响应。讲完了它的架构,我们来讲一下他的训练范式,首先是预训练阶段:使用额外的表格识别任务在 MMTab-pre 数据集上进行预训练,要求模型生成包含表格结构和内容的文本序列。然后是指令微调阶段,在 MMTab-instruct 数据集上进行微调,以赋予模型处理多模态表格任务的能力。
三、实验结果
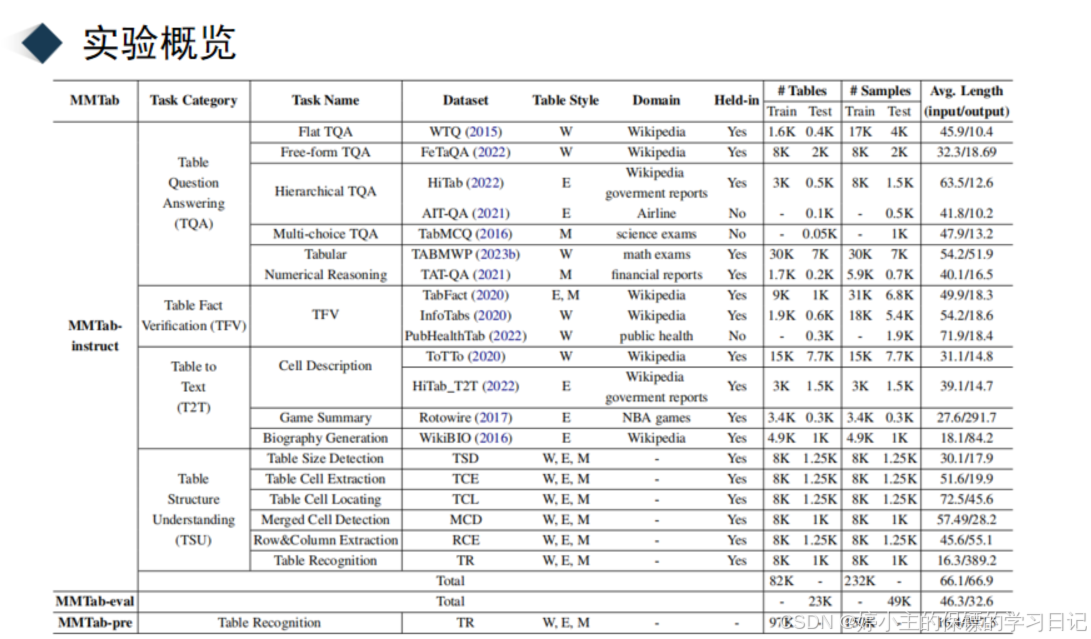
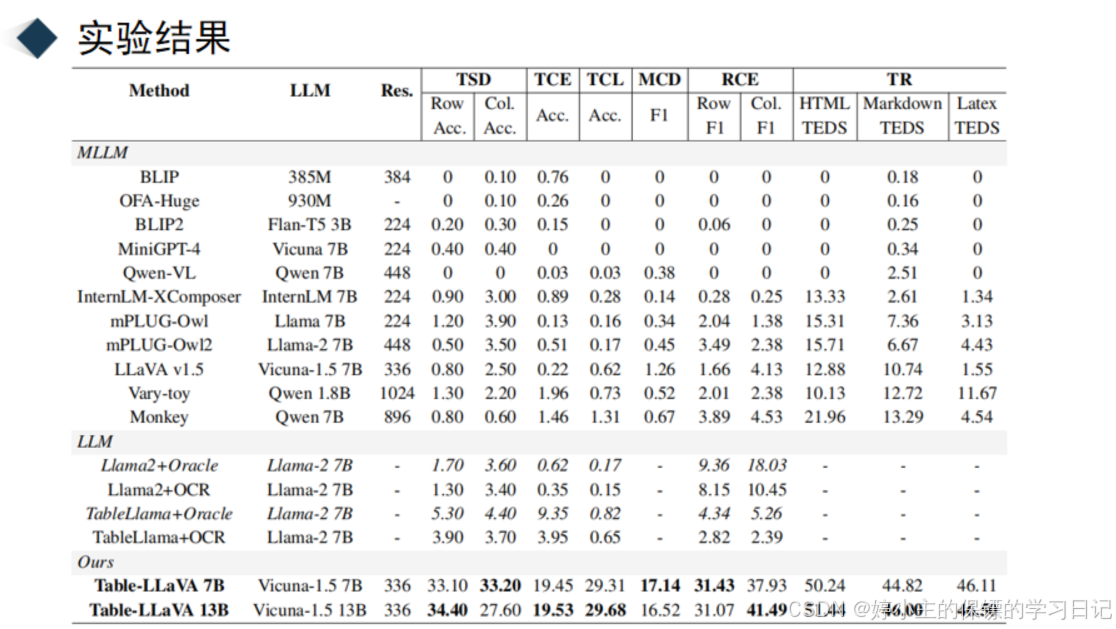
然后再来看看他的实验概览,作者主要就是这个表格上的实验,包括像表格问答、事实验证和表格转文本生成等等的十几个任务。然后我们来看看他的实验结果,这是在 11 个学术任务上的表现,可以发现他的性能在大部分任务上都比现有的一些多模态大模型和大模型要好。这是在6 个表格结构理解任务上的实验结果,发现他的性能全部优于其他的大模型。

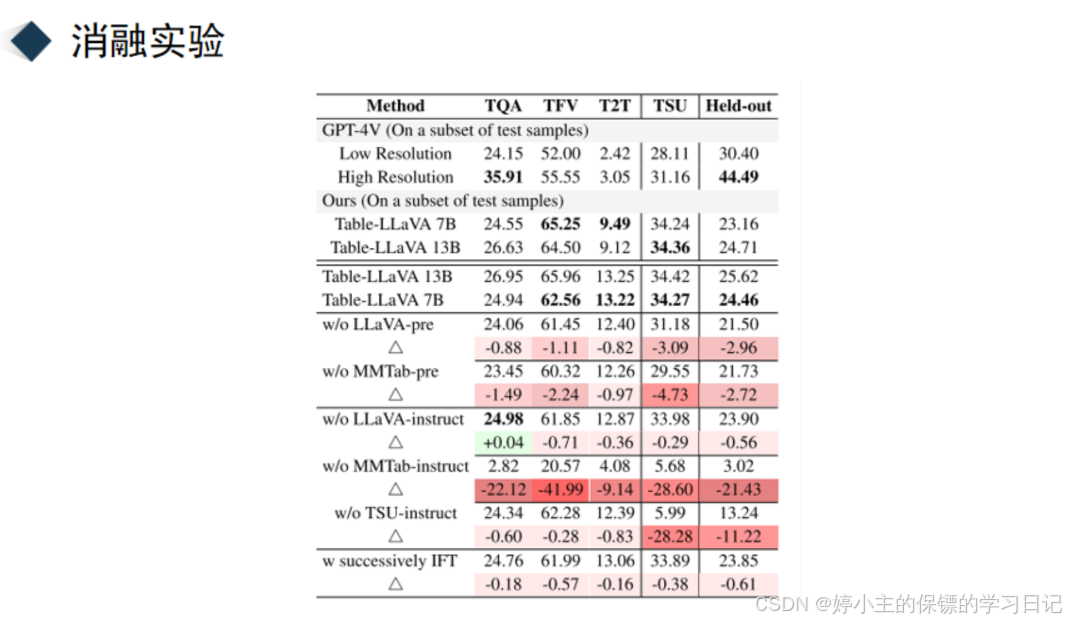
作者还进行了消融实验,这里去掉了mmtab预训练,模型效果都下降了好几个点。还去掉了mmtab的微调,可以看到模型效果下降剧烈。可以说明,模型进行的预训练和微调对于表格理解都起到了促进的作用。
研究者还比较了Table-LLaVA在非表格任务上的表现。结果显示,MMTab数据的加入非但没有削弱模型在非表格任务上的性能,反而起到了促进作用。这表明表格理解能力已经成为多模态大模型的一项基础性、不可或缺的能力。
四、总结和讨论
最后来讲讲他的研究总结,
他的优点是,首次系统地探索了多模态表格理解问题,并构建并发布了一个大规模数据集MMTab,涵盖了多种表格和任务,还开发了Table-LLaVA模型,显著优于多个强MLLM基线。
但是他也存在明显的缺点,就是数据集主要集中在英文表格场景,未考虑多表格场景和更广泛的语言覆盖。而且数据集中的表格图像是自动生成的高质量图像,但现实世界中的表格图像可能质量较低。还有输入图像分辨率相对较低,可能限制了模型性能的上限。

最后,谈一谈有可能的改进,就是现实场景的表格图像可能是低质量的,比如图片模糊、手写表格、表格污损。为了进一步弥合学术研究与真实的应用场景之间的差距,未来可以从野外收集更多的表格图像,并构建相应的指令跟踪数据,以构建更加强大的Table-LLaVA。
Table-LLaVA 模型的分辨率相对较低(336*336),模型性能上限可能会受到限制。未来使用 MMTab数据集搭配 LLaVA-Next、Monkey 等高分辨率MLLM 的效果值得探索。

以上就是一篇论文要如何进行汇报,以及展示出PPT以及具体的讲稿,希望对大家有所帮助。


















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









