






背景
在 OpenAI 系列发布会的次日,OpenAI 公布了强化微调(Reinforcement Fine-Tuning)研究计划。强化微调是一种具有创新性的模型定制技术,开发者可以利用包含数十到数千个高质量任务的数据集,对模型进行针对性优化,从而让人工智能在特定领域的复杂任务中表现出更高的精准度。Sam Altman 称其为 2024 年最令人惊喜的发现之一,它使得在特定领域创建专家模型变得极为容易,且只需少量训练数据即可。

Reinforcement learning fine-tuning,也被称为 ReFT,它是将监督微调(SFT)与强化学习(RL)方法相结合的技术。该技术通过引入多条推理路径的学习,能够自动评估这些路径与正确答案的匹配程度,进而提升模型生成高质量解答的能力。值得一提的是,这一技术路线最早是由字节跳动提出的。以下是关于该技术的论文相关信息:
1. 论文名称:
REFT: Reasoning with REinforced Fine-Tuning
《REFT:通过强化微调进行推理》
2. 论文链接: https://arxiv.org/pdf/2401.08967
3. 论文作者所在机构:字节跳动
4.Github链接: https://github.com/lqtrung1998/mwp_ReFT
5. 一句话概括:论文提出了强化微调(ReFT)方法,通过监督微调预热和在线强化学习进一步优化模型,利用自动采样推理路径和自然奖励机制提升大语言模型在数学问题解决中的泛化能力,在多个数据集和模型上进行的实验验证了其性能超越监督微调且与推理时策略兼容。
接下来,本文将对该论文进行深入学习与解读。
一、论文挑战
论文面对的挑战主要包括以下两个方面:
1. 提升模型推理能力与泛化性
(1)现有使用 Chain-of-Thought (CoT) 注释进行监督微调(SFT)的方法,在训练数据中每个问题通常只有一个注释推理路径,这导致模型泛化能力不足。例如在数学问题解决中,模型仅从单一推理路径学习,难以应对多种可能情况,限制了其在不同问题场景中的应用。
(2)尽管部分研究尝试改进 CoT 提示设计和数据工程,但仍需更有效的方法来增强模型推理能力,使其能更好地处理复杂推理任务,尤其是在面对未见过的问题时能够准确推理并得出正确答案。
2. 强化学习应用中的问题
(1)训练效率: Reinforced Fine-Tuning (ReFT) 方法在优化过程中面临挑战。由于其优化的是不可微目标,需要探索生成空间以找到正确答案,这使得它比 SFT 需要更多的训练轮次才能收敛。若使用较大学习率,虽可能加快收敛,但会导致策略不稳定甚至崩溃;若增加批量大小,则会增加计算成本,这在实际应用中是需要权衡的问题。
(2)奖励操纵(Reward Hacking): 在基于多选择题的数学问题(如 MathQA MCQ)训练中,ReFT 的奖励函数仅依赖最终答案来确定奖励,当最终答案的可能空间有限(如 A、B、C、D 选项)时,模型可能被误导。例如,即使推理过程错误,但如果最终预测的选项与答案一致,模型仍会得到正向奖励,这严重干扰了模型训练,影响模型学习到正确的推理过程。
二、论文贡献点
论文的贡献点主要有以下三个方面:
1.提出新的微调方法: 引入了强化微调(ReFT)方法,通过强化学习解决数学问题。与传统监督微调相比,在相同数据集上训练时,ReFT 展现出更强的泛化能力,能够从多个推理路径中学习,从而提高模型在数学问题解决中的性能。
2.广泛实验验证有效性: 使用 CodeLLAMA 和 Galactica 两个基础模型,在 GSM8K、MathQA 和 SVAMP 三个标准数据集上进行了大量实验,涵盖自然语言和程序基 CoTs。实验结果表明,ReFT 在性能和泛化能力上显著优于监督微调(SFT),证明了 ReFT 方法的有效性和实用性。
3.展示与其他技术的兼容性: 证明了 ReFT 训练的模型与多数投票和奖励模型重新排名等推理时策略兼容,进一步提升了模型性能。例如,在 GSM8K 数据集上,通过多数投票和奖励模型重新排名,ReFT 的性能得到了进一步提高,且在与现有开源模型比较中,ReFT 在不依赖额外数据和蒸馏的情况下,表现出更优的性能。
三、强化微调
强化微调(ReFT,Reinforced Fine-Tuning)过程包括两个阶段:预热阶段(Warm-up)和强化学习(reinforcement learning)阶段。

Warm-up
在这个阶段,策略会在由 “(question, CoT)” 元组(x,e)组成的数据集中进行几个轮次的微调。这使模型具备基本的问题解决能力,从而生成合适的回答。
形式上,思维链的生成过程可以分解为一系列下一个词元预测动作。最后一个动作词元表示生成过程结束。
思维链e可写为:
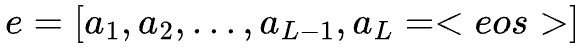
其中,L为最大长度。在时间步t,动作at从策略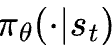 中采样,其中at可以是词汇表中的任何词元,状态st由问题中的所有词元和到目前为止生成的所有词元组成。
中采样,其中at可以是词汇表中的任何词元,状态st由问题中的所有词元和到目前为止生成的所有词元组成。
每次动作后,产生的状态s_t+1是当前状态st和动作at的连接:
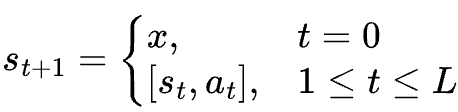
当产生的动作是词元时,产生的状态s_L+1是终止状态,生成过程结束。根据此符号表示,一个样本的损失函数可以写为:
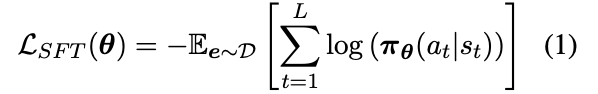
Reinforcement Learning
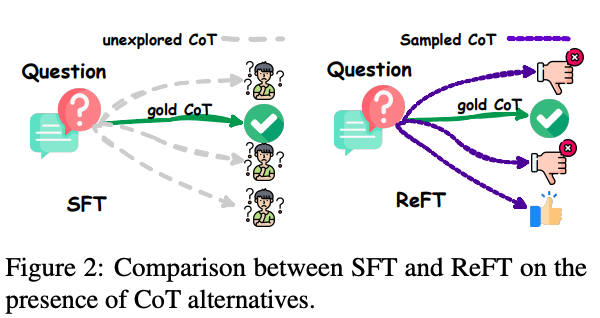
在这个阶段,策略通过使用由(question, answer)元组 (x, y)组成的数据集进行在线自学习来提高其性能。
具体来说,策略模型通过反复采样响应(图 2)、评估响应答案的正确性,并以在线方式更新其参数(算法 1 中的第 7 - 14 行)来进行学习。
论文采用带有裁剪目标算法的近端策略优化(PPO)进行训练。遵循 Ziegler 等人(Fine-tuning language models from human preferences. )的方法,价值模型是通过在策略模型(即热身阶段后的模型)的最后隐藏状态上附加一个线性价值头来构建的。对于导致非终止状态的所有动作,给予 0 奖励。在终止状态下,使用一个奖励函数,该函数直接比较从状态的思维链中提取的答案与真实答案。在这里,如果答案被认为是正确的,奖励函数返回 1,否则返回 0。在所有答案都是数值的数据集上,当答案可以被提取且为数值类型时,可以应用 0.1 的部分奖励。
对于,写为
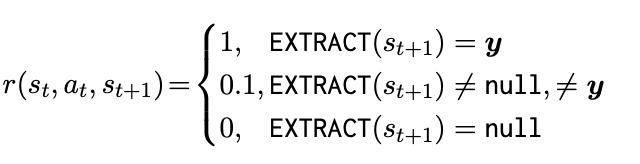
这样的部分奖励有助于减少从稀疏奖励中学习的影响。此外,论文的总奖励是奖励函数得分与学习到的强化学习策略和初始策略之间的KL散度乘以系数因子的总和。
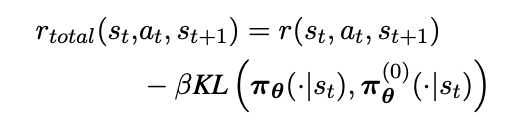
广义优势估计用于优势计算:
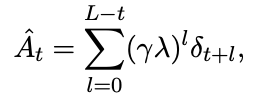
其中,时间差分(TD)定义为:
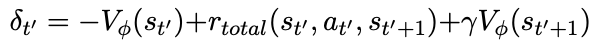
其中终端状态值Vϕ(sL+1) := 0, λ ∈(0, 1]是奖励的折扣因子,γ ∈[0, 1]是时间差分的折扣因子。对于回报的估计,利用λ回报Rˆt,它可以表示为广义优势估计值和价值估计值的总和:
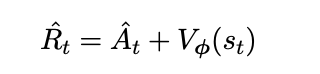
最后,策略和价值目标可以用下面两个方程来表示:
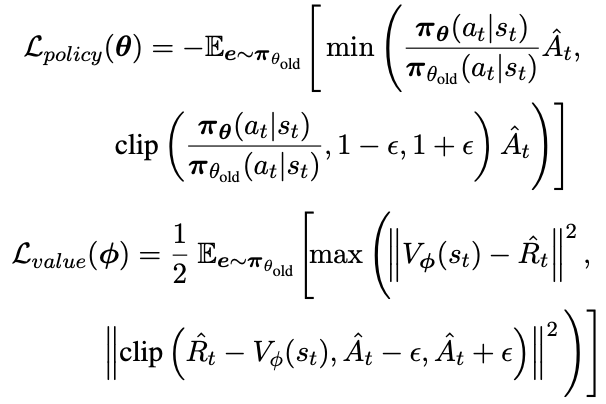
其中,πθold , Vϕold用于采样思维链并计算Aˆt, Rˆt。统一的损失函数是上述目标的加权和。
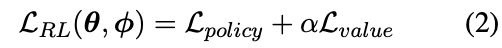
其中α是价值目标的系数。
四、实验与结论
实验设置
(1)数据集: 在 GSM8K、SVAMP 和 MathQA 三个数学问题数据集上进行实验,其中 MathQA 包含多选和数值两种格式,对各数据集进行了训练集和测试集的划分,并统计了数据量。
(2)基线模型: 将 ReFT 与 SFT 和自训练基线方法进行比较,包括离线自训练(Offline Self-Training)和在线自训练(Online Self-Training)。
(3)实验模型: 采用 Galactica - 6.7B 和 CodeLLAMA - 7B 两个基础模型进行实验。
(4)超参数设置: 在训练过程中使用 DeepSpeed 和 HuggingFace Accelerate,详细说明了 ReFT、SFT 基线、离线自训练基线和在线自训练基线在不同数据集上的训练轮数、优化器、学习率、批量大小等超参数设置。同时介绍了奖励模型重排序的训练参数设置以及评估指标(报告所有数据集上 N-CoT 和 P-CoT 的准确率,多数投票和重排序时采样 100 个 CoT 进行评估)。
实验结果
(1)ReFT 性能优于 SFT: 在除 MathQA MCQ N-CoT 外的实验中,ReFT 相比 SFT 有显著性能提升,如在 GSM8K N-CoT 和 P-CoT 上,CodeLLAMA 模型使用 ReFT 分别有近 10 点和 12 点的提升,平均在各数据集上 N-CoT 和 P-CoT 分别提升 6.7 点和 7.4 点。离线自训练虽能提升性能但远不及 ReFT,表明 ReFT 中的 “探索” 对性能提升很重要,在线自训练虽有改进但仍远落后于 ReFT,说明错误实例对引导模型探索也很关键,同时表明 ReFT 的策略采样和强化学习方法优于标准数据增强方法。
(2)发现 MathQA 中的奖励黑客问题: 在 MathQA MCQ 数据集上,ReFT 受奖励黑客问题影响,因模型在多选中会根据选项预测最终答案,即使中间推理错误,若最终答案与选项匹配仍会得到正奖励,误导模型训练。实验表明在 MathQA numeric 版本(无选项,直接预测数值答案)上,ReFT 性能优于基线模型,凸显了多选中奖励黑客问题的负面影响,也指出控制奖励黑客问题是未来工作的重要方向。
(3)多数投票和重排序对 ReFT 的提升: 进行多数投票和奖励模型重排序实验,结果表明 ReFT 在这些技术下性能提升显著,如 ReFT + 投票平均比 SFT + 投票高出 8.6 点,ReFT 重排序比 SFT 重排序高出 3 点以上,且在 GSM8K 上,ReFT 通过奖励模型重排序达到最佳性能,其最佳 P-CoT 变体准确率达到 81.2%,超过 GPT - 3.5 - turbo,且使用的是 7B 模型,而其他开源方法多使用额外数据和蒸馏技术。
(4)小模型实验: 使用 Galactica - 125M、Codeparrot - small 和 Codegen - 350M 小模型在 P-CoT 数据上进行实验,ReFT 仍优于 SFT,展示了 ReFT 在探索合理程序方面的稳健性。
(5)消融实验: 以 CodeLLAMA 在 GSM8K P-CoT 上进行消融实验,结果显示无部分奖励时 ReFT 准确率下降但仍优于 SFT,说明部分奖励有助于减少训练中稀疏奖励的影响;KL 系数设为 0 时策略分布崩溃,表明对策略探索空间施加约束很关键;使用单独值模型虽能使策略在早期 RL 训练中更快收敛,但最终性能与共享值模型相当,且计算和内存成本翻倍。
模型分析
(1)泛化能力: 通过展示 ReFT 在 GSM8K P-CoT 上训练时的平均奖励、评估准确率和 KL 散度,发现 SFT 在约 40 轮时收敛并过拟合,而 ReFT 在 40 轮时平均奖励较高且准确率仍在提升,KL 散度先大后稳定在合理范围,表明 ReFT 策略在合理程序空间内探索,强化学习机制提升了其泛化能力。
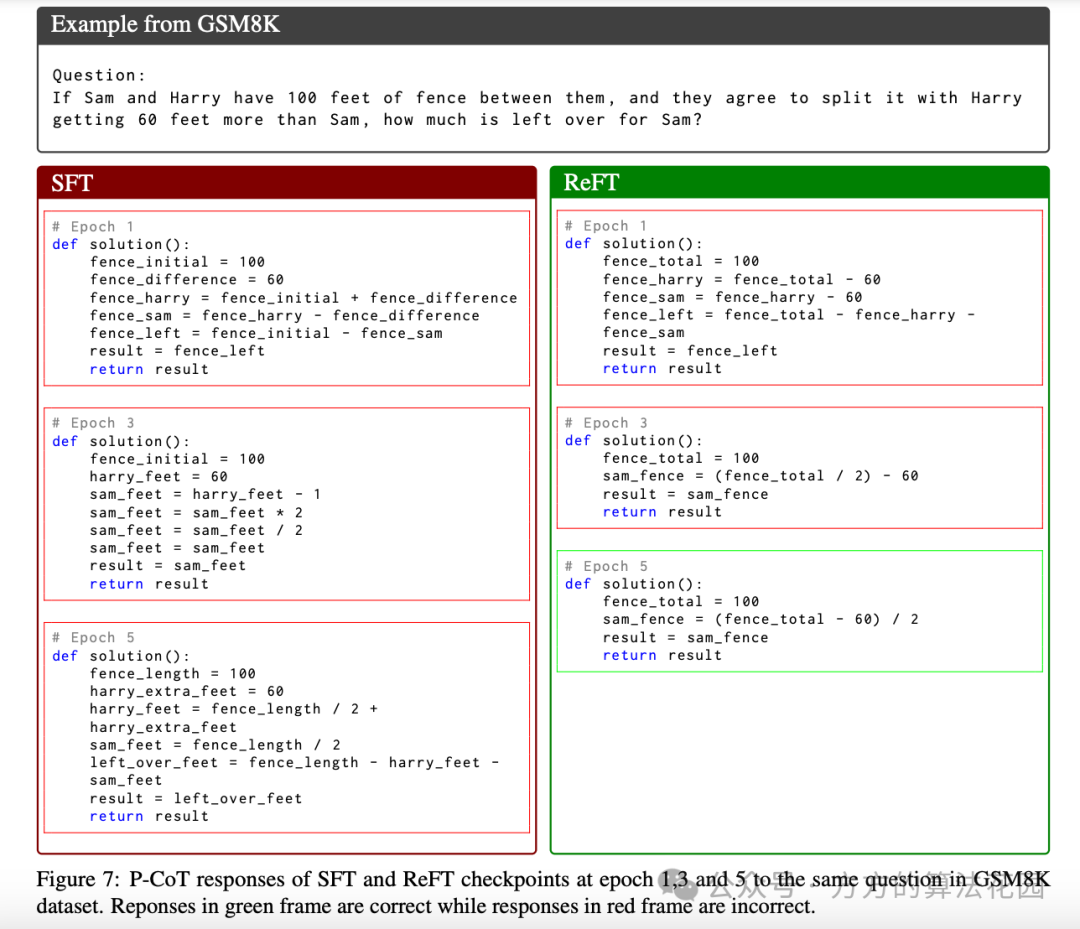
(2)定性评估: 进行人工评估,根据逻辑、命名和紧凑性三个标准对 SFT 模型、热身检查点模型和 ReFT 模型在 GSM8K 测试集上的输出进行评分,结果显示 ReFT 整体得分略高于 SFT 且优于热身变体,表明 ReFT 在生成准确和语义连贯的推理路径方面更具稳健性。
(3)ReFT 与 SFT 的关系: 通过使用不同数量的 SFT 热身步骤进行 ReFT 训练,发现训练初期 ReFT 性能下降,约 8 轮后开始提升,30 轮后 SFT 收敛时 ReFT 仍在改进且所有 ReFT 变体显著优于 SFT,不同变体间无明显优势。
五、展望与局限
1. 未来展望
- 尝试利用离线强化学习技术,开发无热身方法以提高训练效率和性能,缩小与重排序方法的差距。
- 探索在强化学习训练中实现基于过程的奖励,以应对奖励黑客问题,提升模型性能。
- 将 ReFT 应用于更广泛的可通过 CoT 形式化推理的任务。
2. 研究局限
- 训练效率:ReFT 需要更多轮数达到收敛,因优化不可微目标需探索生成空间,增加学习率虽可加速收敛但会导致策略不稳定或崩溃,增加批量大小虽可行但计算成本高。
- 奖励黑客问题:当前奖励函数仅基于最终答案确定奖励,在如 MathQA MCQ N-CoT 数据集上,最终答案空间有限时策略易受操纵,需采用更详细或基于过程的奖励函数考虑更多因素来缓解此问题。
六、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









