






摘要
本文中,我们对从输入文本中创建知识图谱(KGC)的自动化方法感兴趣。大型语言模型(LLMs)的进展促使了一系列最近的研究将它们应用于KGC,例如,通过零/少次提示。尽管在小领域特定数据集上取得成功,但这些模型在扩展到许多现实世界应用中常见的文本上面临困难。一个主要问题是,在先前的方法中,KG模式必须包含在LLM提示中以生成有效的三元组;更大更复杂的模式很容易超过LLMs的上下文窗口长度。为了解决这个问题,我们提出了一个名为Extract-Define-Canonicalize(EDC)的三阶段框架:开放信息提取。跟着模式定义和事后规范化。EDC 是灵活的。
在这方面的优势在于它可以应用于有预定义目标模式的情况,也可以应用于没有预定义目标模式的情况;在后一种情况下,它会自动构建模式并应用自规范化。为了进一步提高性能,我们引入了一个经过训练的组件,用于检索与输入文本相关的模式元素;这以一种类似检索增强生成的方式提高了LLMs的提取性能。我们在三个知识图谱构建的基准数据上展示了,相比之前的工作,EDC能够在不进行任何参数调整的情况下提取出高质量的三元组,并且拥有显著更大的模式。
1 简介
知识图谱(KGs)(Ji 等,2021)是知识的结构化表示,通过图结构组织相互关联的信息,其中实体和关系被表示为节点和边。它们广泛用于各种下游任务,如决策(Guo 等,2021; Lan 等,2020)、问答(Huang 等,2019; Yasunaga 等,2021)和推荐(Guo 等,2020; Wang 等,2019)。然而,知识图构建(KGC)在本质上具有挑战性:该任务需要具备理解句法和语义的能力,以生成一致、简洁和有意义的知识图。因此,KGC 主要依赖于大量的人力劳动(Ye 等,2022)。
自2023年起,为了利用其卓越的自然语言理解能力,最近的尝试自动化KGC(Zhong等人,2023年;Ye等人,2022年)已经采用了大型语言模型(LLMs)。基于LLM的KGC方法采用了各种创新的基于提示的技术,例如多轮对话(Wei等人,2023年)和代码生成(Bi等人,2024年),以生成代表知识图的实体-关系三元组。然而,这些方法目前仅限于小型和特定领域的场景 - 为了确保生成的三元组的有效性,必须在提示中包含模式信息(例如,可能的实体和关系类型)。复杂的数据集(例如维基百科)通常需要超出上下文窗口长度或可能被LLMs忽略的大型模式(Wadhwa等人,2023年)。
在这项工作中,我们提出了提取-定义-将KGC规范化(EDC)作为KGC的结构化方法:关键思想是将KGC分解为三个主要阶段对应三个子任务(图1):
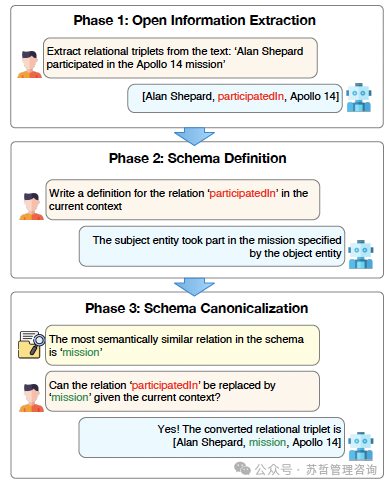
l开放信息抽取:提取一从输入文本中自由地列出实体-关系三元组。
l模式定义:生成一个定义-在提取阶段获得的三元组引导下,为模式的每个组件(如实体类型和关系类型)提供表示。
l架构规范化(Schema Canonicalization):使用用模式定义标准化三元组,使语义上等效的实体/关系类型具有相同的名词/关系短语。
EDC:提取-定义-规范化
阶段1:开放信息提取
每个阶段都利用了LLM的优势:图1:提取子任务的高层示意利用了最近的发现,LLM的Extract-Define-Canonicalize(EDC)对于知识图构建是有效的开放信息提取器(Li等,2023年;Han等,2023年)——它们可以提取语义正确且有意义的三元组。然而,结果三元组通常包含多余和模糊的信息,例如,多个语义等价关系短语,如“职业”、“工作”和“职业”(Kamp等,2023年;Putri等,2019年;Vashishth等,2018年)。
阶段2和阶段3(定义和规范化)标准化三元组,使它们对下游任务有用。我们设计了EDC是灵活的:它可以发现与可能很大的预定模式一致的三元组(目标对齐),也可以自动生成模式(自我规范化)。为了实现这一点,我们利用LLMs通过利用其解释生成能力来定义模式组件 - LLMs可以通过对人类专家可认同的解释来证实它们的提取(Li等人,2023)。这些定义用于找到最接近的实体/关联类型候选人(通过矢量相似度搜索),然后LLM可以引用这些候选人来规范化一个组件。在现有模式中不存在相应的对应对象的情况下,我们可以选择将其添加以丰富该模式。
为了进一步提高性能,上述三个步骤之后可以跟随一个额外的优化阶段:我们重复执行EDC,但在初始提取期间提供先前提取的三元组和模式的相关部分。我们提出了一个经过训练的模式检索器,检索与输入文本相关的模式组件(类似于检索增强生成(Lewis等,2020)),我们发现这可以改善生成的三元组。
实验结果表明,在目标对齐和自标准化设置下,与最先进的方法相比,EDC能够通过自动和手动评估提取质量更高的知识图。此外,使用Schema Retriever明显且持续地改善了EDC的性能。
总的来说,这篇论文做出了以下贡献:
-
EDC,一种灵活且高性能的基于LLM的知识图构建框架,能够提取具有大尺寸模式或无预定义模式的高质量知识图。
-
Schema Retriever,一个经过训练的模型,用于提取与输入文本有关的模式组件,类似于信息检索。
-
证据表明EDC和Schema的有效性。检索器。
2 背景
在本节中,我们提供有关知识图构建(KGC)、开放信息提取(OIE)和规范化的相关背景。
知识图谱构建。传统方法通常使用传统方法处理KGC。
“流水线”, 包括实体发现(Zukov-Gregoriˇ c等,2018年;Martinsˇ等,2019年)、实体类型(Choi等,2018年;Onoe&Durrett,2020年)和关系分类(Zeng等,2014年;2015年)。由于预训练生成式语言模型(如T5(Raffel等,2020年)和BERT(Lewis等,2019年))的进展,最近的作品将KGC作为一个序列到序列的问题,并通过微调这些中等大小的语言模型以端到端的方式生成关系三元组(Ye等,2022年)。大型语言模型(LLMs)的成功进一步推动了这一范式:当前方法直接促使LLMs以零/少量数据的方式生成三元组。例如,ChatIE(Wei等,2023年)通过将任务框架构建为一个多轮问答问题来提取三元组,而CodeKGC(Bi等,2024年)则将任务视为一个代码生成问题。如前所述,这些模型难以扩展到许多真实应用中普遍存在的一般文本,因为KG模式必须包含在LLM提示中。我们的EDC框架通过使用事后规范化(而无需对基础LLM进行微调)来避免这个问题。
开放信息抽取和规范化。标准(封闭)信息抽取需要输出的三元组遵循预定义的模式,例如需要从中提取的关系或实体类型列表。相比之下,开放信息抽取(OIE)没有这样的要求。OIE有悠久的历史,我们建议希望获取全面信息的读者参考优秀调查报告(刘等,2022年;周等,2022年;坎普等,2023年)。最近的研究发现,LLM在OIE任务上表现出色(李等,2023年)。然而,从OIE系统中提取的关系三元组没有规范化,例如,多个语义上等价的关系可以并存而不统一为规范形式,在诱发的开放知识图中会引起冗余和歧义。需要进行额外的规范化步骤,将三元组标准化,使得知识图对下游应用有用。
规范化方法因目标模式是否可用而异。 如果存在目标模式,则该任务有时被称为“对齐”(Putri等,2019)。例如,Putri等人(2019年)使用WordNet(Miller,1995年)作为附加信息,以获取OIE提取的关系短语的定义,并使用一种暹罗网络来比较OIE关系定义与目标模式中预定义关系。如果没有目标模式可用,最先进的方法通常基于聚类(Vashishth等,2018年;Dash等,2020年)。CESI(Vashishth等,2018)利用来自外部来源如PPDB(Ganitkevitch等,2013年)和WordNet的附加信息为OIE关系创建嵌入。然而,基于聚类的方法往往容易过于泛化(Kamp等,2023年;Putri等,2019年),例如,CESI可能将“是兄弟”,“是儿子”,“是主要反派”,和“是教授”的关系放入同一关系聚类中。
与现有的规范化方法相比,EDC更加通用;它可以在提供目标模式或不提供目标模式的情况下工作。EDC不使用像WordNet这样的静态外部来源,而是利用由LLMs生成的上下文和语义丰富的侧面信息。此外,通过允许LLMs验证是否可以执行转换(而不仅仅依靠嵌入相似度),EDC缓解了之前方法面临的过度泛化问题。
3 方法:KGC的EDC
本节概述了我们的主要贡献:一种以结构化方式利用LLMs构建知识图谱的方法。我们首先详细介绍了EDC框架,然后描述了细化(EDC+R)。给定输入文本,我们的目标是提取关系三元组,使其呈现规范形式,以确保生成的知识图谱中的歧义性和冗余性最小化。在存在预定义目标模式的情况下,所有生成的三元组应符合该模式。在没有预定义模式的情况下,系统应动态创建一个模式,并相对于该模式使三元组规范化。
3.1 EDC: 提取-定义-规范化
在高层次上,EDC将KGC分解为三个相互关联的子任务。为了明确我们的讨论,我们将使用一个具体的输入文本示例:“Alan Shepard于1923年11月18日出生,并于1959年被NASA选中。他是阿波罗14号飞船的机组成员”,并逐步介绍每个阶段。
阶段1:开放信息抽取: 我们首先利用大型语言模型(LLMs)进行开放式信息抽取。通过少样本提示,LLMs 从输入文本中识别并提取关系三元组([主体,关系,客体]),而不依赖于任何特定的模式。以我们上面的示例为例,提示为:
给定一段文本,从中提取关系三元组的形式为[主语,关系,宾语]。
以下是一些示例:
Example 1:The quick brown fox jumps over the lazy dog.
17068.8毫米长的ALCO RS-3型号拥有柴油电力传动系统。
三元组:[[‘ALCO RS-3’,‘powerType’,‘柴油电传动’],[‘ALCO RS-3’,‘length’,‘17068.8(毫米)’]] …
阿兰·谢泼德于1923年11月18日出生,并于1959年被NASA选中。他是阿波罗14号任务组的一员。
结果三元组(在这种情况下,[’Alan Shepard’, ‘出生于’, ‘1923年11月18日’],[’Alan Shepard’, ‘参与了’, ’阿波罗14号’])构成一个开放的知识图,将被传递到后续阶段。
阶段2:架构定义: 接下来,我们提示LLMs为由开放KG引发的模式的每个组件提供自然语言定义。
给定一段文本和从中提取出的关系三元组列表,为每个存在的关系写出定义。
Example 1:The quick brown fox jumps over the lazy dog.
17068.8毫米长的ALCO RS-3型号拥有柴油电力传动系统。
三元组:[[‘ALCO RS-3’,‘动力类型’,‘柴油电传动’],[‘ALCO RS-3’,‘长度’,‘17068.8(毫米)’]] 定义:
powerType:主体实体使用对象实体指定的能源类型或能量源。
现在为从以下文本中提取的三元组中的每个关系编写一个定义:文本:艾伦·谢泼德(Alan Shepard)是一名美国人,在1923年11月18日出生于新罕布什尔州,于1959年被NASA选中,是阿波罗14号机组的成员,并在加利福尼亚州去世。
三元组:[[‘Alan Shepard’,‘出生于’,‘1923年11月18日’],[‘Alan Shepard’,‘参与了’,‘阿波罗14号’]]
这个示例提示导致了(bornOn:主体实体出生于对象实体指定的日期。)和(participatedIn:主体实体参与了对象实体指定的事件或任务。)的定义,然后将它们作为辅助信息传递到下一个阶段,用于规范化。
阶段3:模式规范化:第三阶段旨在将开放式知识图谱精炼为一个规范形式,消除冗余和歧义。我们首先通过使用句子转换器对每个模式组件的定义进行向量化来创建嵌入。然后,规范化将以两种方式之一进行,取决于目标模式的可用性:
目标对齐:在现有目标模式中,我们为每个元素识别目标模式中最相关的组件,考虑将它们用于规范化。为了防止过分概括的问题,LLMs评估每个潜在转换的可行性。如果一个转换被认为不合理,表明在目标模式中没有语义等价物,那么该组件及其相关三元组将被排除。
l自我规范化:在没有目标模式的情况下,目标是 consolida te 相似模式组件,将它们标准化为一个单一的表示以简化知识图谱。从一个空的规范模式开始,我们检查开放的知识图谱三元组,通过向量相似性和 LLM 验证搜索潜在的整合候选项。与目标对齐不同,被认为不可转换的组件被添加到规范模式中,从而扩展它。
使用我们的例子,提示如下:
给定一段文本,从中提取出一个关系三元组以及其中的关系定义,如果可能的话,在这个上下文中选择最合适的关系进行替换。
艾伦·谢泼德(Alan Shepard)于1923年11月18日出生,于1959年被NASA选拔。他是阿波罗14号(Apollo 14)组的成员。
三元组:[‘Alan Shepard’,‘参与’,‘阿波罗14’] 定义:“参与”:主体实体参加了由客体实体指定的事件或任务。选择:
l’mission’: 主体实体参与了由客体实体指定的事件或操作。
“季节”:主体实体参与了对象实体指定的季节。
l"联赛": 主体实体参与或竞争对象实体指定的联赛。
l’activeYearsStartYear’: 主体实体于对象实体指定的年份开始了他们的职业生涯。
l’foundingYear’:主体实体成立于对象实体指定的年份。
以上均不是。
请注意,上述选择是通过使用向量相似性搜索获得的。在LLM做出选择后,关系被转换为:[‘Alan Shepard’,‘出生日期’,‘1923年11月18日’],[‘Alan Shepard’,‘任务’,‘阿波罗14号’],这形成了我们的规范化知识图谱。
3.2EDC+R: 通过模式检索器迭代地优化EDC
提炼过程利用EDC生成的数据来提高提取的三元组的质量。受到检索增强生成和之前的工作Bi等人(2024年)的启发,我们为提取阶段构建了一个“提示”,包括两个主要元素:
候选实体:从前一次迭代中EDC提取的实体,以及使用LLM从文本中提取的实体;
候选关系:由EDC在上一个周期中提取的关系和通过训练好的模式检索器从预定义/规范化模式中检索到的关系。
将来自LLM和模式检索器的实体和关系的包含为LLM提供了更丰富的候选池,这解决了实体或关系缺失影响LLM效果的问题。通过将前期阶段提取的实体和关系与来自实体提取和模式检索的新发现合并,提示有助于通过从上一轮引导OIE。
为了将EDC扩展到大型模式,我们采用了经过训练的模式检索器,这使我们能够有效地搜索模式。模式检索器的工作方式类似于基于向量空间的信息检索方法 Ganguly 等 (2015); Lewis 等 (2020); 它将模式组件和输入文本投影到一个向量空间,使得余弦相似度捕捉到两者之间的相关性,即一个模式组件在输入文本中存在的可能性有多大。需要注意的是,在我们的设定中,相似度空间与标准句子嵌入模型中的余弦相似度不同,后者捕捉到语义等价关系。我们的模式检索器是对句子嵌入模型 E5-mistral-7b-instruct 的微调变种 (Wang 等, 2023)。我们遵循论文中详细介绍的原始训练方法,涉及利用文本及其相应定义的关系对。详情请参阅附录。对于给定的正面文本-关系对 (t+, r+),我们在 t+ 上应用一种指令模板以生成一个新的文本 tinst+:
tinst+ =指令: 检索给定文本中存在的关系 \n 查询: {t+}.
然后,我们通过使用InfoNCE损失来微调嵌入模型,以区分给定文本相关的正确关系和其他不相关关系。
回到我们的例子,通过模式检索器的细化,向前面的集合添加了以下关系:[‘阿兰·谢泼德’,‘NASA选择’,‘阿波罗14号’]。关系’NASA选择’相当模糊,但在目标模式中指定了。
4 实验
在这一部分,我们描述了设计用于评估EDC和EDC+R性能的实验。简而言之,我们的结果表明,EDC在目标对齐和自我规范化设置中明显优于最先进的方法。进一步的改进提高了EDC的性能。EDC的源代码和复制我们的实验的方法可在https://github.com/clear-nus/edc找到,附录中包含完整的表格。
4.1 实验设置
数据集。 我们使用三个KGC数据集对EDC进行评估:
lWebNLG(Ferreira等,2020年):我们使用WebNLG+2020(v3.0)语义解析任务的测试集。它包含1165对文本和三元组。从这些参考三元组中得出的模式涵盖了159种唯一的关系类型。
lREBEL(Cabot & Navigli,2021):REBEL的原始测试分区包括105,516个条目。为了管理成本,我们选择了1000个文本三元组对的随机样本。这个子集引发了一个包含200种不同关系类型的模式。
l来自Wiki-NRE(Distiawan et al., 2019):从Wiki-NRE的测试集(29,619个条目)中,我们随机抽取了1000个文本三元组对,得到一个包含45种唯一关系类型的模式。
这些数据集被选择,而不是选择类似于ADE(Gurulingappa等,2012年)(1种关系类型),SciERC(Luan等,2018年)(7种关系类型)和CoNLL04(Roth&Yih,2004年)(4种关系类型)等备选方案,用于评估先前基于LLM方法(Bi等,2024年;Wadhwa等,2023年)用于以往基于LLM方法的研究,因为它们拥有更丰富的关系类型。这种多样性更好地模拟了现实世界的复杂性。在我们的实验中,我们专注于提取关系作为所有数据集中唯一可用的模式组件。关系作为知识图谱的基础元素,优先于其他组件如实体或事件类型。然而,请注意,EDC可以轻松扩展到其他模式组件。
EDC模型。 EDC 包含多个由LLMs提供动力的模块。由于OIE模块是确定在KG中捕获的语义内容的关键上游模块,因此我们测试了不同大小的不同LLMs,包括GPT-4 (Achiam等,2023年)、GPT3.5-turbo (Brown等,2020年) 和Mistral-7b (Jiang等,2023年)。 Mistral-7b 私有化部署在本地工作站上,而GPT模型则通过OpenAI API访问。对于需要提示的框架的其余组件,我们使用了GPT-3.5-turbo。在规范化阶段,E5-Mistral-7b 模型被用于向量相似性搜索,不进行修改。
4.1.1 评估标准和基线
我们根据目标对我们的方法进行了不同的评估:在目标对齐(提供架构)和自我规范化(无架构)下。对于上述数据集,基于LLM的KGC方法(ChatIE和CodeKGC)由于架构大小而无法使用。
目标对齐。我们将EDC和EDC+R与每个数据集的专门训练模型进行比较:
lREGEN(Dognin等人,2021)是WebNLG的SOTA模型。它是一种生成式序列到序列模型,利用预训练的T5(Raffel等人,2020)和强化学习(RL)进行双向文本到图形和图形到文本生成。
lGenIE(Josifoski等,2022年),一个生成式序列到序列模型,利用预训练的BART(Lewis等,2019年)和双层约束生成策略来约束输出三元组与预定义模式一致。GenIE是REBEL和Wiki-NRE的最先进模型。
根据之前的工作(Dognin等,2021年;Melnyk等,2022年),我们使用WEBNLG评估脚本(Ferreira等,2020年),该脚本以基于标记的方式计算输出三元组与真实情况的精确度、召回率和F1分数。基于命名实体评估的指标被用来以三种不同方式测量精确度、召回率和F1分数。
lExact: 要求候选三元组与参考三元组完全匹配,无视类型(主语、关系、客体)。
l允许候选三元组与参考三元组之间至少部分匹配,忽略类型。
lStrict: 要求候选项和参考三元组之间完全匹配,包括元素类型。
自我规范化。 为了评估自我规范化性能,将其与以下内容进行比较:
l基准开放知识图谱,这是OIE(Open Information Extraction)的初始开放知识图谱输出。
信息抽取(Information Extraction)阶段。 这可作为一个参考点,来说明规范化过程中精度和模式简洁性的改善。
lCESI(Vashishth等,2018年)被认为是知识图谱规范化中一种领先的基于聚类的方法。通过将CESI应用于开放的知识图谱,我们旨在对比其与EDC规范化的性能。
鉴于规范化的三元组可能使用与参考三元组不同措辞的关系,基于标记的评估方法不适用。因此,我们转向手动评估,并着重于三个关键方面:
l精度: 与OIE三元组相比,规范化的三元组在文本方面仍然正确且有意义。
l简洁度:模式的简洁度由关系类型的数量来衡量。
l冗余性:我们使用一个冗余性得分——每个规范化关系及其最近对应关系之间的平均余弦相似度——其中得分较低表示模式的关系在语义上是不同的。
4.2 结果与分析
以下,我们重点传达我们的主要发现和结果。有关完整的结果和表格,请参阅附录。
4.2.1 目标对齐
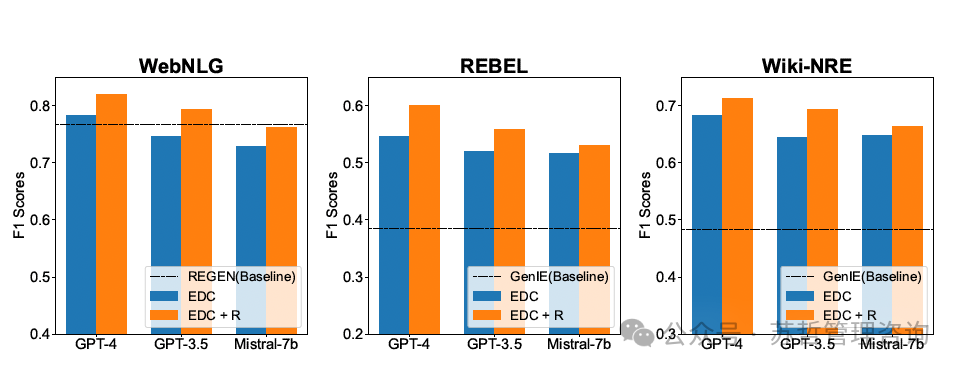
图2中的条形图总结了EDC和EDC+R在所有三个数据集上针对OIE使用不同LLMs获得的部分F1分数,与各自的基线进行比较。EDC展示了优于或与最先进技术同等的性能。
图2: 在目标对齐设置下,EDC和EDC+R在WebNLG、REBEL和Wiki-NRE数据集上的性能与各自基线(使用“部分”标准的F1分数)相比。我们发现,EDC+R只进行了1次改进迭代,之后改进效果显著降低。
在所有评估数据集中,GPT-4表现最佳,Mistral-7b和GPT-3.5-turbo的结果相当。我们的方法与基线方法之间的差距在REBEL和Wiki-NRE数据集上更为显著;主要原因是GenIE的受限生成方式不足以提取包含文字量的三元组,比如数字和日期。
EDC+R不断并显著提升性能。在后续的优化过程中,GPT-3.5-turbo和Mistral-7b之间的性能差异较大,这表明Mistral-7b无法充分利用提供的提示。然而,使用提示进行单次优化迭代可以提高所有测试的LLMs的性能。
根据分数显示,相比于REBEL和Wiki-NRE,EDC在WebNLG上的表现明显更好。然而,我们注意到尽管在后两个数据集上生成了有效的三元组,EDC仍然受到了惩罚。其中一个原因是这些数据集中的参考三元组是非穷尽的。例如,在REBEL数据集中给定的文本。
"Romany Love is a 1931 British musical film directed by Fred Paul and starring Esmond Knight,
弗罗伦斯·麦克休(Florence McHugh)和罗伊·特拉弗斯(Roy Travers)所提取的EDC数据:[‘罗曼尼之爱’,‘演员’,‘埃斯蒙德·奈特(Esmond Knight)’],[‘罗曼尼之爱’,‘演员’,‘弗罗伦斯·麦克休’],[‘罗曼尼之爱’,‘演员’,‘罗伊·特拉弗斯’],这些都在语义上是正确的,但只有第一个三元组在参考集中存在。数据集还包含基于文本之外的信息的参考三元组,例如,“丹尼尔是一名埃塞俄比亚足球运动员,目前效力于哈瓦萨城足球俱乐部(Hawassa City S.C.)”,对应的参考三元组为[‘哈瓦萨城足球俱乐部’,‘国家’,‘埃塞俄比亚’]。
这些问题可以归因于创建这些数据集所采用的不同方法论。对于WebNLG,注释者被要求仅根据三元组来撰写文本。因此,文本与三元组有直接对应关系,而文本通常不包含除三元组所反映的信息以外的其他内容。相比之下,REBEL和Wiki-NRE是通过远程监督(Smirnova & Cudre-Mauroux, 2018)将文本与三元组对齐而创建的。这种方法可能导致提取不太直接的三元组和不完整的参考集,从而可能会对EDC等能够产生正确但不在数据集中的三元组的方法进行悲观评估(Han等,2023; Wadhwa等,2023)。平均而言,相对于WebNLG,EDC每句话提取出的三元组数量在REBEL和Wiki-NRE中多出1个,而在WebNLG中,EDC提取的三元组数量与参考集相似。
模式检索器的消融研究。 为了评估在精炼过程中模式检索器提供的关系对结果的影响,我们使用GPT-3.5-turbo进行了一项消融研究,通过从提示中移除通过模式检索器检索的关系。表1中的结果显示,消融模式检索器会导致性能明显下降。
定性地,我们发现模式检索器有助于找到与Table 1中的基准实验结果相关的关系:模式检索器,用于开放信息抽取的LLM是GPT-3.5-turbo。S.R.代表模式检索器。

表2:在自我规范化设置中EDC的性能(人工评估的准确率和模式指标)。每个数据集和指标的最佳结果都以粗体显示。Prec.代表准确率,No. Rel.代表关系数量,Red.代表冗余分数。

在OIE阶段对LLMs来说是具有挑战性的。例如,考虑到文本
‘第戎勃艮第大学有16,800名本科生’,在OIE过程中LLMs提取了[’第戎勃艮第大学’, ’位置’, ’第戎’]。虽然在语义上是正确的,但这种关系忽略了目标模式中更加具体的关系,即用于表示大学位置的‘校园’。模式检索器成功地识别了这种更精细的关系,使LLMs能够调整他们的提取为[’第戎勃艮第大学’, ’校园’, ’第戎’]。这个实验凸显了模式检索器在促进精确提取和与上下文相关的关系方面的价值。
4.2.2 自我规范化
在这里,我们重点评估EDC的自规范化性能(利用GPT-3.5turbo进行OIE)。在自规范化设置中,我们省略了细化过程,因为已经在上文中进行了研究,并且在后续迭代中,自构建的规范化模式成为目标模式。根据之前的工作(Wadhwa等,2023年;Kolluru等,2020年),我们进行了针对知识图的有针对性的人工评估。这项评估包括两位独立的注释者在没有关于系统细节的先验知识的情况下评估从给定文本中抽取的三元组的合理性。我们观察到高达0.94的注释者间一致性得分。
评估结果和模式度量指标总结在表2中。这些发现表明,虽然由OIE阶段生成的开放知识图包含语义上有效的三元组,但在所得模式中存在相当大程度的冗余。EDC准确地将开放知识图规范化,产生的模式比CESI更简洁、更少冗余。与之前的工作一致,我们观察到CESI不当地将各种关系聚类为一个“死亡日期”的类别,避免了CESI过度泛化的倾向。
5 结论
在这项工作中,我们提出了EDC,这是一个基于LLM的三阶段框架,通过开放信息提取和事后规范化来解决KGC的问题。实验证明,当存在目标模式时,EDC和EDC+R能够比专门训练的模型提取更好的知识图,而当没有提供模式时,它们可以动态创建模式。EDC的可扩展性和多功能性为应用程序开辟了许多机会:它使我们能够使用大型模式(如Wikidata)从一般文本中自动提取高质量的知识图,并甚至可以使用新发现的关系来丰富这些模式。未来的工作也可以改进EDC的组件以进一步提升性能,例如,模式检索器可以在更多种类和高质量的数据上进行训练。
参考文献
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat等人。GPT-4技术报告。arXiv预印本 arXiv:2303.08774,2023。
Oshin Agarwal, Heming Ge, Siamak Shakeri, and Rami Al-Rfou.基于知识图谱的合成语料库生成用于增强知识的语言模型预训练。arXiv
预印本arXiv:2010.12688,2020.
Zhen Bi, Jing Chen, Yinuo Jiang, Feiyu Xiong, Wei Guo, Huajun Chen, and Ningyu Zhang. Codekgc: Code language model for generative knowledge graph construction. ACM Transactions on Asian and Low-Resource Language Information Processing, 23(3):1–16, 2024.Codekgc:用于生成知识图谱构建的代码语言模型。《ACM Transactions on Asian and Low-Resource Language Information Processing》,23(3):1-16,2024年。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell等人。语言模型是少样本学习者。神经信息处理进展。系统,33:1877–1901,2020.
Pere-Llu´ıs Huguet Cabot 和 Roberto Navigli。Rebel:端到端语言生成的关系抽取。在计算语言学协会发现:EMNLP。2021年,第2370-2381页,2021年。
Eunsol Choi, Omer Levy, Yejin Choi, and Luke Zettlemoyer.超细粒度实体类型标注. arXiv 预印本 arXiv:1807.04905,2018.
Sarthak Dash, Gaetano Rossiello, Nandana Mihindukulasooriya, Sugato Bagchi, and Alfio Gliozzo.开放知识图谱规范化使用变分自动编码器。arXivpreprint arXiv:2012.04780, 2020.
Bayu Distiawan, Gerhard Weikum, Jianzhong Qi和Rui Zhang。神经关系抽取用于知识库补充。在计算语言学协会第57届年会论文集中,第229-240页,2019年。
Pierre L Dognin, Inkit Padhi, Igor Melnyk,和 Payel Das. Regen: Reinforcement learning for text and knowledge base generation using pretrained language models. arXiv 预印本 arXiv:2108.12472,2021年。
Thiago Castro Ferreira, Claire Gardent, Nikolai Ilinykh, Chris Van Der Lee, Simon Mille, Diego Moussallem和Anastasia Shimorina。2020年双语、双向WebNLG+共享任务概述和评估结果(webnlg+ 2020)。在第3届国际语言生成从语义Web(WebNLG+)研讨会论文集中, 2020。
Debasis Ganguly, Dwaipayan Roy, Mandar Mitra,和 Gareth JF Jones. 基于词嵌入的通用语言模型用于信息检索。 在第38届国际ACM SIGIR会议上的研究和信息检索发展中的论文集中,第795–798页,2015年。
Juri Ganitkevitch, Benjamin Van Durme和Chris Callison-Burch。Ppdb:释义数据库。在2013年北美计算语言协会会议论文集:人类语言技术上,第758-764页,2013年。
基于知识图谱的自动加工工艺决策系统。集成制造,34(12):1348-1369,2021。
清宇 郭,富振 庄,川 秦,恒舒 朱,兴 谢,慧 雄,庆 贺。知识图谱推荐系统综述。IEEE交易。
知识与数据工程, 34(8):3549–3568, 2020.
Harsha Gurulingappa,Abdul Mateen Rajput,Angus Roberts,Juliane Fluck,Martin Hofmann-Apitius和Luca Toldo。开发一个基准语料库,以支持从医疗病例报告中自动提取与药物相关的不良反应。Journal of
生物医学信息学,45(5):885-892,2012.
Ridong Han, Tao Peng, Chaohao Yang, Benyou Wang, Lu Liu, and Xiang Wan. Is information extraction solved by chatgpt? an analysis of performance, evaluation criteria, robustness and errors. arXiv preprint arXiv:2305.14450, 2023.
Xiao Huang, Jingyuan Zhang, Dingcheng Li, and Ping Li.知识图谱嵌入式问答系统. 在第十二届ACM国际网络搜索和数据挖掘会议论文集中,第105-113页,2019年。
Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and S Yu Philip. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE transactions on
神经网络与学习系统,33(2):494–514,2021。
阿尔伯特·蒋,亚历山大·萨布拉约尔,亚瑟·曼施,克里斯·班福德,迪文德拉·辛格·查普洛特,迭戈·德拉斯卡斯,弗洛里安·布雷杉,吉安娜·伦吉尔,吉约姆·朗普尔,吕西尔·索尼尔等。 弥斯特拉尔7b。arXiv预印本arXiv:2310.06825,2023.
Martin Josifoski, Nicola De Cao, Maxime Peyrard, Fabio Petroni和Robert West。GenIE: 生成信息提取。在2022年北美计算语言学协会年会论文集中:人类语言技术,第4626-4643页,美国西雅图,2022年7月。计算语言学协会。doi: 10.18653/v1/2022.naacl-main.342。URL https://aclanthology.org/2022.naacl-main.342.
Serafina Kamp, Morteza Fayazi, Zineb Benameur-El, Shuyan Yu, and Ronald Dreslinski. Open information extraction: A review of baseline techniques, approaches, and applications. arXiv preprint arXiv:2310.11644, 2023.
Keshav Kolluru, Vaibhav Adlakha, Samarth Aggarwal, Soumen Chakrabarti等人。Openie6:用于开放信息抽取的迭代网格标记和协调分析。arXiv预印本arXiv:2010.03147,2020年。
Luong Thi Hong Lan, Tran Manh Tuan, Tran Thi Ngan, Nguyen Long Giang, Vo Truong Nhu Ngoc, Pham Van Hai等。一种带有模糊知识图和扩展的新复合模糊推理系统在决策制定中的应用。Ieee Access,8:164899–164921,2020.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov和Luke Zettlemoyer。Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv预印本arXiv:1910.13461,2019。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin.Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel,等。检索增强生成,用于知识密集型自然语言处理任务。神经网络进展。信息处理系统,33:9459-9474,2020。
玻璃博,方戈翔,杨洋,王权森,叶伟,赵文和张世坤。评估ChatGPT的信息提取能力:性能、可解释性、校准性和忠实度的评估。arXiv预印本arXiv:2304.11633,2023年。
Pai Liu, Wenyang Gao, Wenjie Dong, Songfang Huang, and Yue Zhang.从2007年到2022年的开放信息提取研究综述. arXiv预印本arXiv:2208.08690, 2022.
Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi.多任务识别实体、关系和共指以构建科学知识图。arXiv预印本arXiv:1808.09602,2018。
Pedro Henrique Martins, Zita Marinho和 Andre FT Martins. 联合学习命名实体识别和实体链接. arXiv预印本 arXiv:1907.08243, 2019.
Igor Melnyk, Pierre Dognin和Payel Das. 知识图生成自文本. arXiv
预印本arXiv:2211.10511,2022。
乔治·A·米勒。WordNet:一个英语词汇数据库。ACM通信,38(11):39–41, 1995.
Yasumasa Onoe和Greg Durrett。细粒度实体类型的领域无关实体链接。在人工智能AAAI会议论文集的《AAAI会议论文集》中,卷34,页码 8576-8583,2020年。
Rifki Afina Putri、Giwon Hong和Sung-Hyon Myaeng。使用基于词嵌入的标准网络对开放IE关系和KB关系进行对齐。在第13届国际计算语义会议——长论文集中,第142-153页,2019年。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu.探索具有统一文本生成模型的迁移学习极限。 机器学习研究杂志, 21(140):1–67, 2020.
Dan Roth和Wen-tau Yih。一个线性编程形式在自然语言任务中的全局推理。在第八届计算自然语言学习会议(CoNLL-2004)在HLT-NAACL 2004上,第1-8页,2004年。
Alisa Smirnova和Philippe Cudre-Mauroux。使用遥监进行关系抽取:一项调查。ACM Computing Surveys(CSUR),51(5):1-35,2018。
Shikhar Vashishth, Prince Jain, and Partha Talukdar. Cesi:使用嵌入和侧面信息对开放知识库进行规范化。在2018年世界范围内的会议论文集中。
Web Conference, pp. 1317–1327, 2018.网络会议,页码1317-1327,2018年。
Denny Vrandeciˇ c和 Markus Kr´ otzsch. Wikidata:一个免费的协作知识库。ACM通讯,57(10):78–85,2014。
Somin Wadhwa, Silvio Amir,和 Byron C Wallace. 在大型语言模型时代重新思考关系抽取。在会议论文集中。计算语言学协会会议。第2023卷,第15566页。NIH Public Access,2023。
王宏伟,赵淼,谢星,李文杰和郭敏毅。知识图谱卷积网络用于推荐系统。在万维网会议中。pp. 3307–3313, 2019.–> pp. 3307–3313, 2019.
王亮,杨楠,黄晓龙,杨琳俊,Rangan Majumder和魏富如。利用大语言模型改进文本嵌入。arXiv预印本arXiv:2401.00368。
向伟,熹宇崔,宁诚,晓彬王,鑫张,神煌,鹏军零样本信息抽取通过与ChatGPT对话进行。arXiv预印本arXiv:2302.10205,2023年。
Qagnn:语言模型和知识图谱的推理问答。arXiv预印本arXiv:2104.06378,2021.
叶洪斌,张宁宇,陈晖和陈华军。生成式知识图谱构建:一项综述。arXiv预印本arXiv:2210.12714,2022年。
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou和Jun Zhao。通过卷积深度神经网络进行关系分类。在COLING 2014年会议论文集中,第25届国际计算语言学会议技术论文,第2335-2344页,2014年。
Daojian Zeng, Kang Liu, Yubo Chen,和 Jun Zhao. 使用分段卷积神经网络进行关系抽取的远程监督。在2015年经验方法在自然语言处理会议论文集上,第1753-1762页,2015年。
Lingfeng Zhong, Jia Wu, Qian Li, Hao Peng, and Xindong Wu. A comprehensive survey on automatic knowledge graph construction. ACM Computing Surveys, 56(4):1–62, 2023.钟凌峰,吴佳,李倩,彭浩,吴新东。关于自动知识图谱构建的综合调查。ACM计算调查,56(4):1-62,2023。
周少文,余博文,孙爱新,龙成,李景阳,于海洋,孙健和
李勇斌。神经开放信息抽取综述:当前状况与未来方向。arXiv预印本arXiv:2205.11725,2022。
Andrej Zukov-Gregoriˇ c, Yoram Bachrach和Sam Coope。以平行循环神经网络进行命名实体识别。在第56届计算语言学协会年会论文集(第2卷:短文)中,第69-74页,2018年。
A Schema检索器训练
遵循原始论文中详细介绍的原始训练方法,该方法涉及利用文本及其对应定义的关系对。对于给定的正文关系对(t+, r+), 我们在t+上应用指令模板生成新文本tinst+ : tinst+ = 指导:检索给定文本中存在的关系 \n 查询:{t+}。
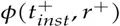
然后我们通过使用InfoNCE损失来微调嵌入模型,以区分给定文本所关联的正确关系和其他不相关关系。
min L = − log ϕ(tinst+ , r+)+∑ni∈Nϕ(tinst+ , ni)
在这里,N表示负样本集合,ϕ代表余弦相似度函数。请参阅附录获取额外的训练细节。
用于训练,我们使用了TEKGEN数据集(Agarwal等,2020年)合成了一组文本关系对,这是一个大规模的文本三元组数据集,通过将Wikidata三元组与维基百科文本进行对齐而创建。训练数据集包括37,500对,正负样本均匀分布。对微调后的模式检索器的性能在WebNLG、REBEL和Wiki-NRE数据集的测试拆分上进行了评估。在这些数据集上的召回率@10分别为0.823、0.663和0.818,表明模式检索器在不同知识图上下文中的有效性。
B目标对齐的详细结果
B.1 完整结果
表3:在WebNLG数据集上,EDC和EDC+R的完整结果与基线对比。
REGEN(精确率、召回率、F1值,使用“部分匹配”、“严格匹配”和“完全匹配”标准)。EDC+R仅执行1次迭代的改进。最佳结果已加粗显示。
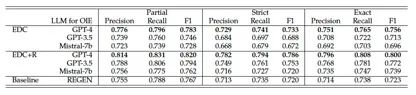
表4:在REBEL数据集上,对比基线REGEN的EDC和EDC+R的完整结果(精确率、召回率、以‘部分’、‘严格’和‘完全’标准的F1值)。EDC+R只进行1次迭代的优化。最佳结果以粗体显示。
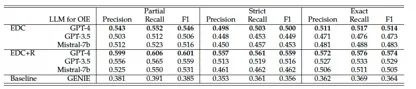
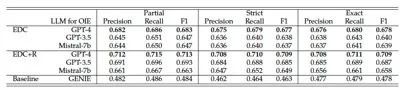
EDC和EDC+R在WebNLG、REBEL和Wiki-NRE上的完整结果分别总结在表3、表4和表5中。在所有度量标准(精确率、召回率和F1值)的所有标准(部分、严格和完全匹配)方面,EDC的表现要优于或与最先进的基线模型相媲美,而EDC+R能够在各个方面持续改进。这些结果更全面地展示了EDC和EDC+R的性能。
表5:Wiki-NRE数据集上EDC和EDC+R的完整结果与基线对比。
REGEN (使用“部分”、“严格”和“精确”标准的精度、召回率和F1值)。EDC+R只进行1次迭代的精化。最佳结果用粗体标出。
B.2 更多细化迭代的影响
表6:进一步迭代细化的结果,用于OIE的LLM是GPT-3.5-turbo。EDC+2xR是具有2次细化迭代的EDC。

表6显示了在所有数据集上使用EDC进行额外迭代细化的结果。虽然进一步的细化稳定地改善了结果,但我们观察到收益递减,因此在主要结果中仅报告了一次迭代。
B.3关于KGC数据集注释的讨论
表7:所有三个数据集中每个句子提取的三元组平均数。WebNLG的基线模型是REGEN,而Rebel和Wiki-NRE的基线模型是GENIE。括号中的数字是与参考注释的差异。
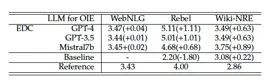
根据4.2节的陈述,我们观察到在Rebel和WikiNRE数据集上,EDC受到评分器的惩罚,这是由于注释不完整。这与(Wadhwa等,2023年;Han等,2023年)的先前研究结果呼应,即LLMs通常可以提取出注释中缺失的正确结果,这导致评估过于悲观。正如表7所示,与参考注释和基准GenIE相比,EDC往往提取出更多三元组。此外,正如表2中的手动评估所显示的,这些三元组中许多确实与输入文本相关,并且是正确的。尽管EDC的自动评估结果过于悲观,但仍然大幅超过基线,考虑到提取的三元组数量的差异,实际性能可能会更高。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









