






下面我们将以“IAEA2011 在维也纳总部举行的第五十五届常委会”为例,带大家具体演示如何通过“知识图谱+大模型”技术,将pdf版的会议记录进行知识的高效、精准地抽取。
1. 准备数据
如下链接可查看并下载原始会议记录:
https://www.iaea.org/sites/default/files/gc/gc55or-3_ch.pdf
为了将文本输入TopGraph知识构建系统中,需要先对PDF文件进行转换,得到文件中的正文文本。您可以考虑使用:
https://www.pdf2go.com/zh/pdf-to-text
等在线工具,或使用WPS、Adobe PDF等相关工具软件进行转换(请注意,这些工具可能需要上传您自己文件,存在一定数据泄露风险!),或手动将PDF文件中的相关文本拷贝出来,粘贴在纯文本文件(.txt)中。
或者 您可以通过这个链接将我们已经做好的txt文件下载下来:http://file.gstore.cn/f/6be487a5c3dd4793ba09/?dl=1
直接上传即可,效果如下图所示:

2. 创建项目
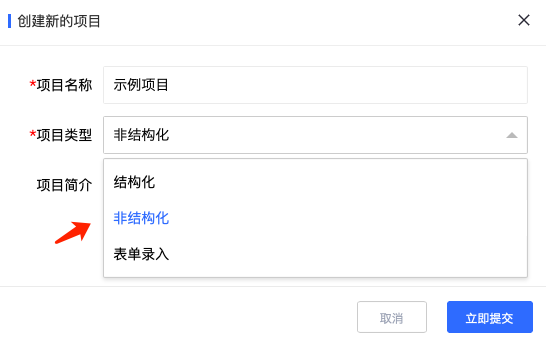
请根据产品使用手册申请账号,并根据手册内2.4.1.1 的内容新建项目一节,创建一个非结构化构建项目:关注【途普智能】公众号,发送【产品手册】即可获取下载地址
3. schema 设计
我们的业务目标是,从该次IAEA关于原子能利用、限制及环保为主题的会议中,通过各个国家做出的承诺来构建各地区实体的关系图谱,包括各个国家共同签订过什么相关条约、执行过什么行动,以及各个国家在该次会议上的代表人。为此,我们为本次抽取任务设计了如下的schema:
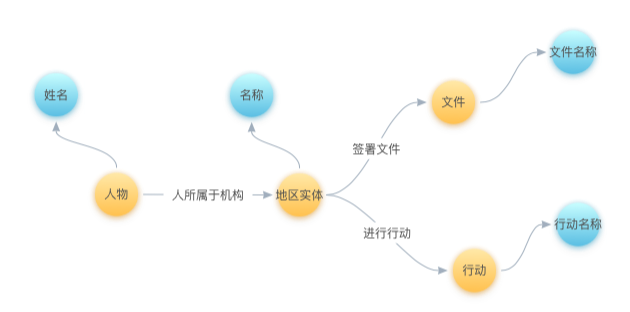
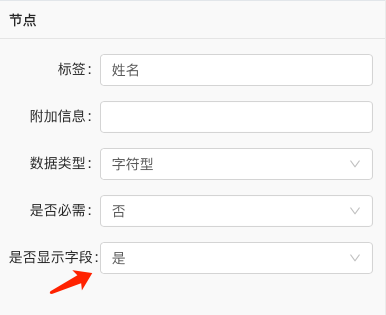
设计schema的方式请参见产品手册2.4.2 Schema设计章节。在上面的schema中,人物、地区实体、文件、行动为实体节点,并存在如图所示的关系。姓名、名称、文件名称、行动名称则为上述实体对应的唯一属性,我们从文本中抽取出的字面值将作为这些属性的属性值,并会代表对应属性的唯一标识符。因此,请在schema设计的节点面板中,将这些属性选择为“选择字段”,如下图所示:
完成本项目的schema设计后,请点击“保存”按钮保存您的本体设计。
4. 上传数据集
将您在前面步骤准备好的数据集上传至非结构化项目中。
请从左侧菜单 > 知识图谱设计 > 项目管理进入项目管理,在右侧的项目列表中找到您刚才创建的项目,点击“构建”按钮进入非结构化项目构建面板:
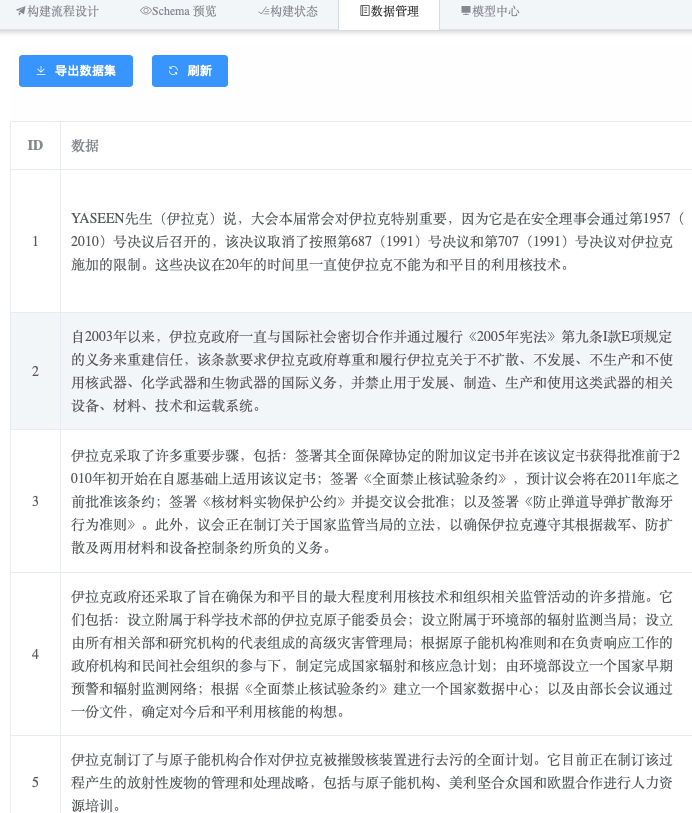
在构建面板中,找到“数据管理”选项卡,进入后点击“上传数据集”按钮上传您的数据:

如数据正常上传,您将在该选项卡中看到您的数据集:
5. 非结构化信息抽取管线设计思路及构建
关于构建管线的设计、实现和具体操作请参考产品手册2.4.4.2.3 构建流程一节中的描述说明。本节将面向本示例项目的需求进行实战描述。
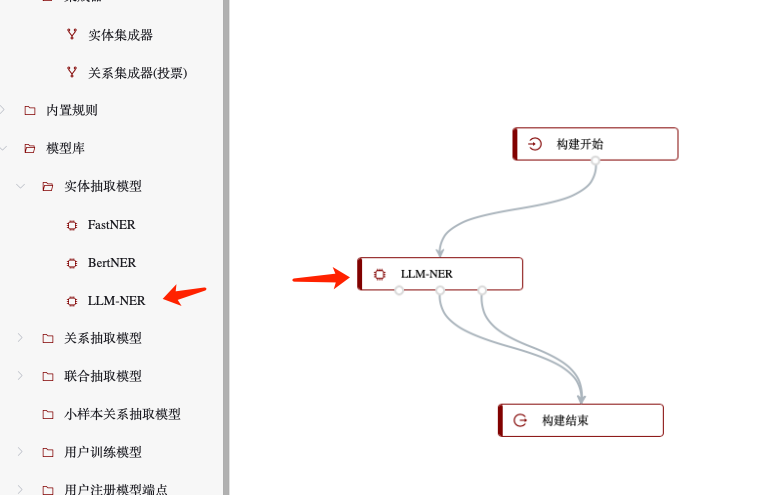
为了达成我们预设的业务目标,考虑需要做如下几件事:抽取会议记录中的人物、地区实体(包括国家、大洲、政治实体等)、文件、行动,并发掘上述实体之间存在的关系。为此,我们需要构建一个能做到这些功能且效果良好的pipeline(管线)。首先需要抽取实体,我们选择最基础且匹配需求的人名、地名开始,从左侧工具栏中将“LLM-NER”节点拖拽到画布中,与“构建开始”、“构建结束”节点相连,如图所示:
LLM-NER是一个基于大规模语言模型的实体抽取模型,可以较为准确的识别人名、地名、机构名。菜单 > 运行 > 测试中执行样例测试,任意输入我们数据集中的一段话,可以看到如下结果:
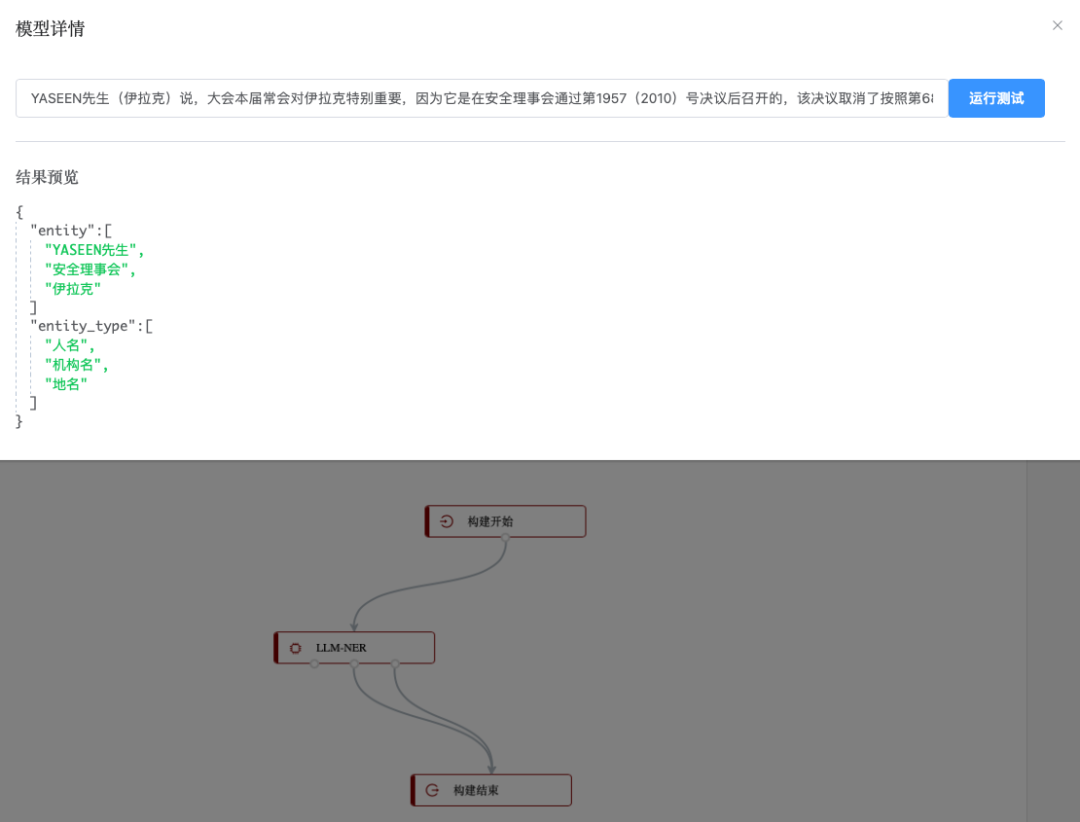
可以看到能顺利抽取出相关的实体。根据需求,人名和地名在我们的schema中分别叫做人物和地区实体,因此进行实体类型映射,将抽取出的实体的类型进行编辑,如下图所示(具体操作可参见2.4.4.2.3.3 实体类型映射):
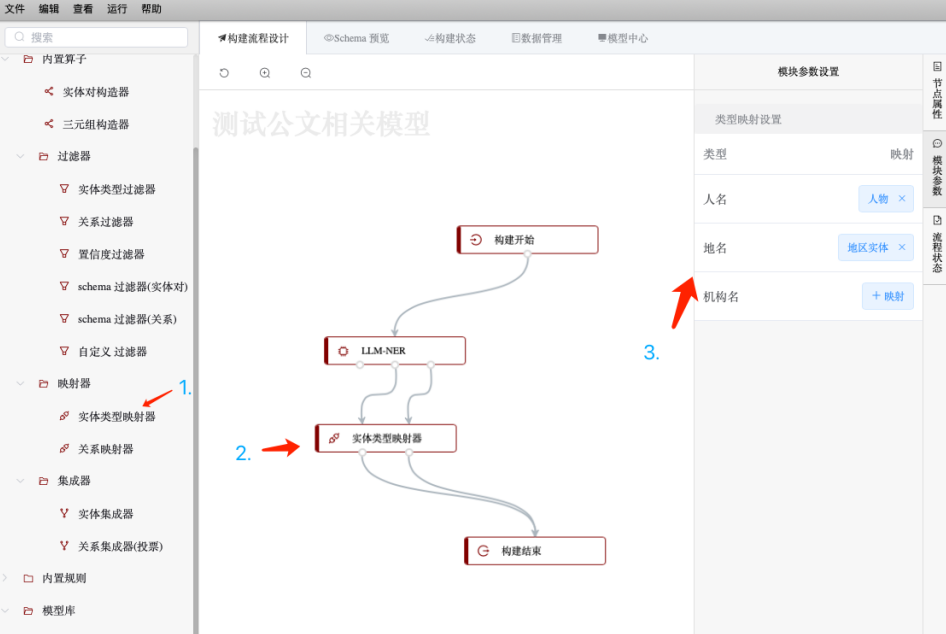
接下来,可以将抽取出的实体构造成实体对(因为关系必然是发生在两个实体间的),可以在实体类型映射器节点的后面加上实体对构造器,即下图步骤1;而构造的实体对是笛卡尔积一一匹配的,有许多实体类型构成的pair并非我们需要考虑的关系,比如在我们的schema中,只有“人物-地区实体”的关系,“人物-人物”、“人物-机构”等实体对并不会存在关系,因此需要事先筛去,以减少后续关系推理时的复杂度,提高整体构建速度,我们在实体对构造器后连接上“schema过滤器(实体对)”,如下图步骤2所示,从而得到符合schema的实体对列表;接着就可以在schema过滤器(实体对)后面连接上关系抽取模型,在本项目中我们选择“LLM-RE”模型,如下图步骤3所示:
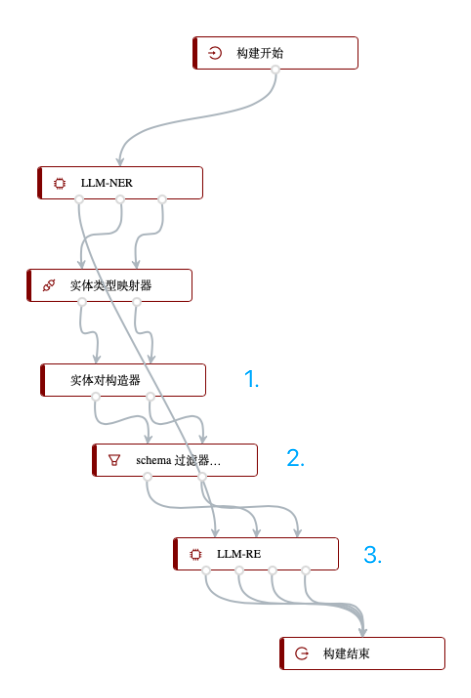
上述构建管线的输出结果如下图所示:

可见,我们的抽取管线顺利地将人物“YASEEN先生”和与他相关的关系给抽取了出来。然而,这只完成了我们业务需求中的一部分,而关于文件、行动相关的实体和关系没有实现,并且在内置的模型库中也没有能实现相关功能的组件,为此我们需要通过标注数据、训练模型来实现完整的业务需求。
6. 数据标注及自定义模型构建
为了标注数据,我们进入标注系统创建一个新的标注任务,从左侧菜单依次操作:非结构化管理 > 标注标签 > 选择项目 > 新增标签。
点击“新增标签”按钮,根据刚才设计的schema新增一系列标签,如下图所示:
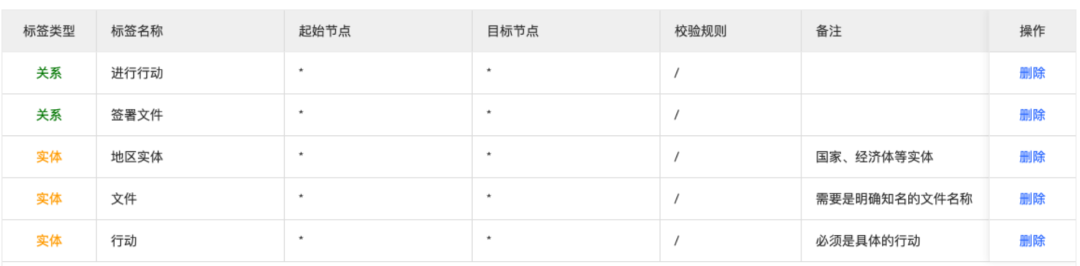
即,在稍后的标注中,我们会标注“文件”、“行动”、“地区实体”实体,并标注它们之间的“进行行动”、“签署文件”的关系。完成标签创建之后,点击左侧菜单:非结构化管理 > 文本标注 > 新增文本。
在这个页面中需要添加需要进行标注的文本。我们可以从本示例项目的数据集中任意选择3条数据,通过“新增文本”按钮将文本加入到待标注列表中,如下图所示:
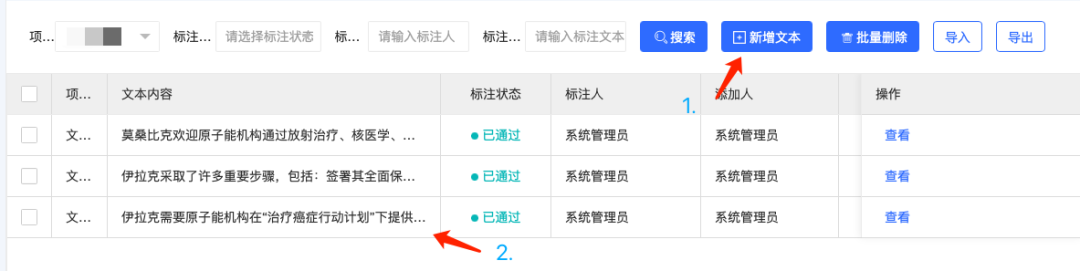
请注意,标注数据的选择需要与您的标注意图相匹配,例如在本示例项目中,我们想标注包含“地区实体”、“文件”、“签署文件”等相关内容的文本,那么添加进项目的文本也应当尽可能包含上述的信息。由于我们打算在gBuilder非结构化构建中选用LLM-NER和LLM-RE两种大模型进行小样本训练,因此我们只选择了上图所示的3条数据。在实际业务中,可以选择标注更多的数据提升模型效果(一般来说,训练数据需要保证多样化,且可以将模型拿不准主意或者容易混淆的数据放入您的训练集中)。
添加完数据之后,遍可以在标注页面的操作列中点击“标注”按钮,开始标注:

在弹出的标注页中,用户可以通过拖动鼠标的方式选中实体,并标注实体类型,然后在实体上的锚点上拖动鼠标,将一个实体和另一个实体连接起来,从而标注它们之间的关系,标注完成后应大致如下图所示:

数据标注的质量和您得到的自定义模型的效果息息相关。
然后可以在 非结构化管理 > 文本标注 中,选择刚才标注好的项目,点击 导出 > 导出训练样本,得到需要用于模型训练的训练集:
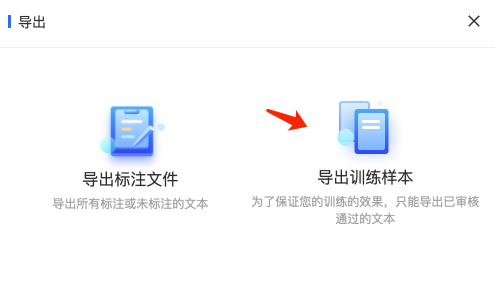
得到的数据大致如下图所示:

有了标注好的数据后,便可以训练与我们业务对齐的信息抽取模型了。回到gBuilder非结构化构建模块,在非结构化构建面板的上侧找到“模型中心”选项卡,如下图所示:
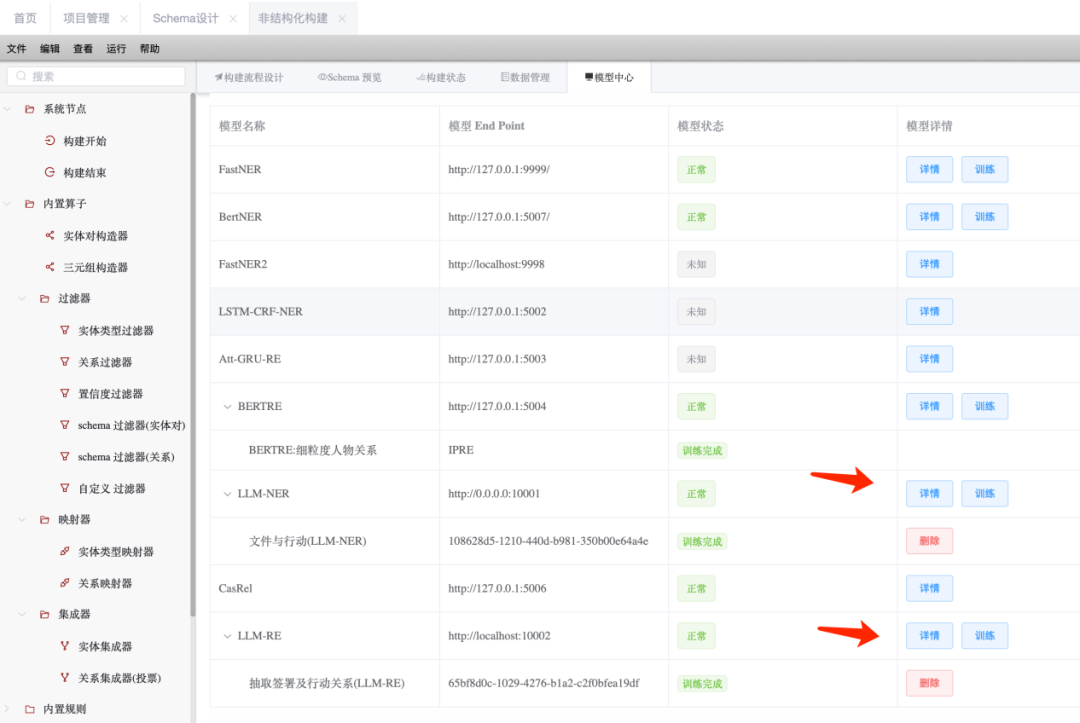
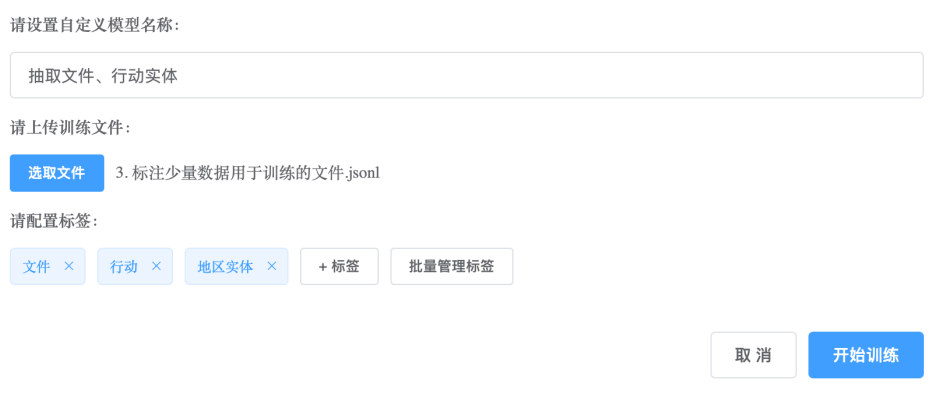
并点击LLM-NER左侧的“训练”按钮,在弹出的训练对话框中,设定好自定义模型的名称、上传前面得到的训练文件,并填入需要抽取的实体类型“文件”、“行动”、“地区实体”,点击训练,数秒过后即可得到训练好的模型:
同理,经过同样的操作,可以通过用标注好的数据训练LLM-RE模型,得到用于抽取“签署文件”、“进行行动”关系的自定义关系抽取模型:
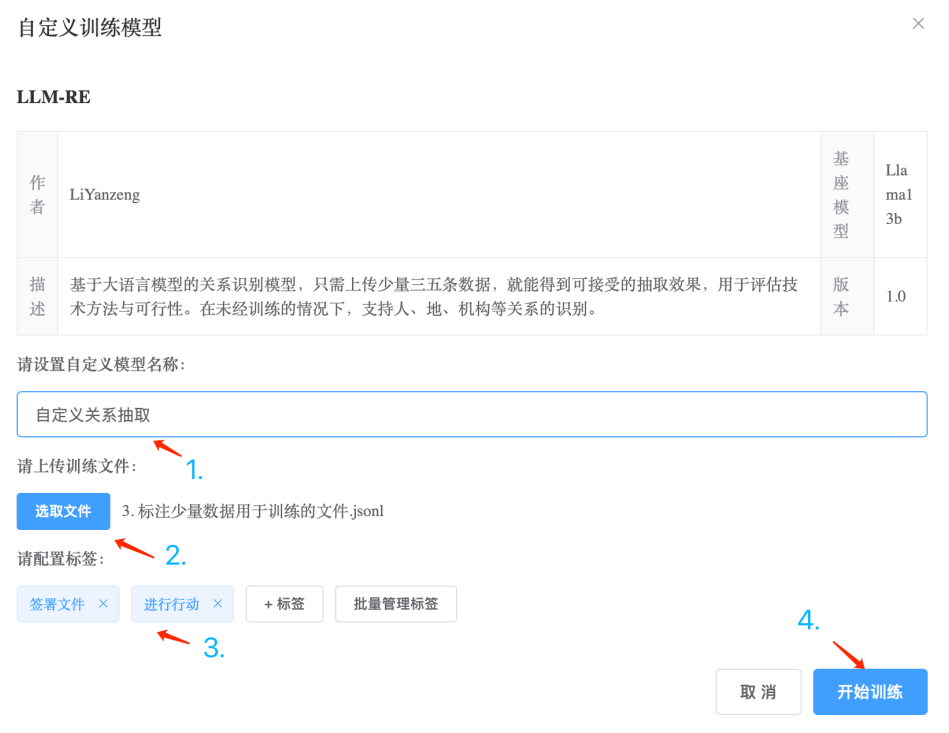
在获得与业务需求匹配的模型之后,便可以继续设计本项目的信息抽取工作流,回到构建流程设计面板中,从左侧工具箱的“用户训练模型”从,将刚才构建的两个自定义模型拖拽到画布中(如下图步骤1、步骤5)。
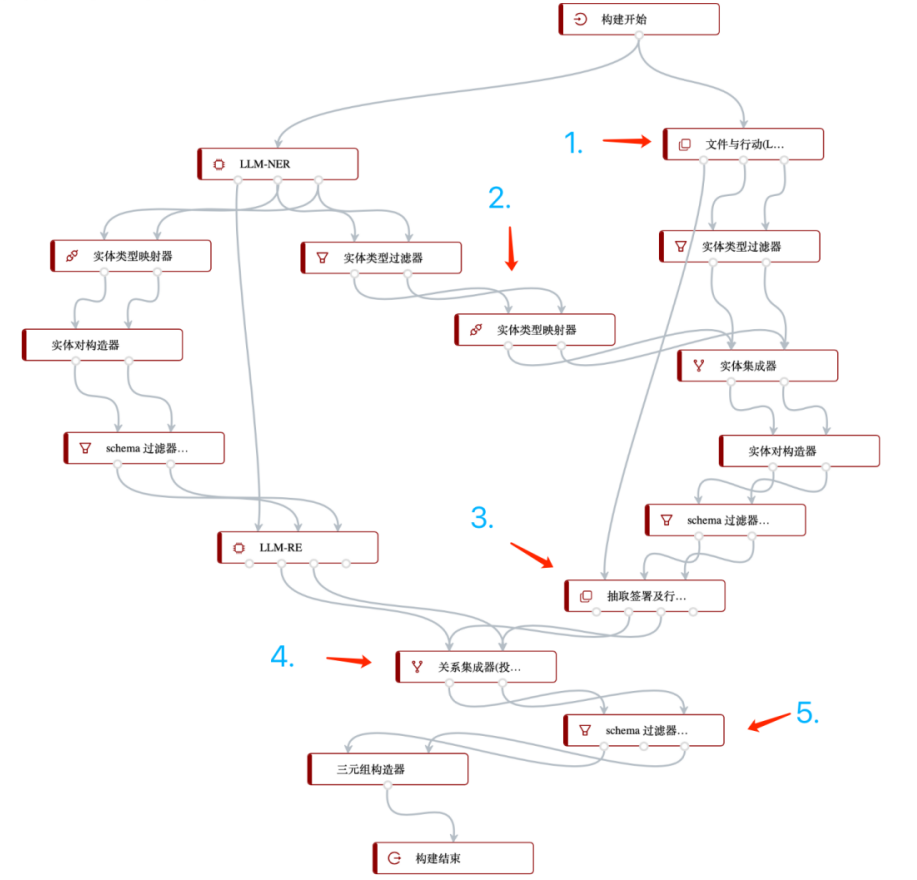
由于构建的自定义模型抽取地区实体的效果不如内置的LLM-NER模型效果好,因此在构建工作流中,我们将使用来自LLM-NER所产生的“地区实体”类型的实体,为此,需要从左边“LLM-NER”拖出一个数据管道,连上一个“实体类型过滤器”,并设置只保留“地名”属性,如下图所示:
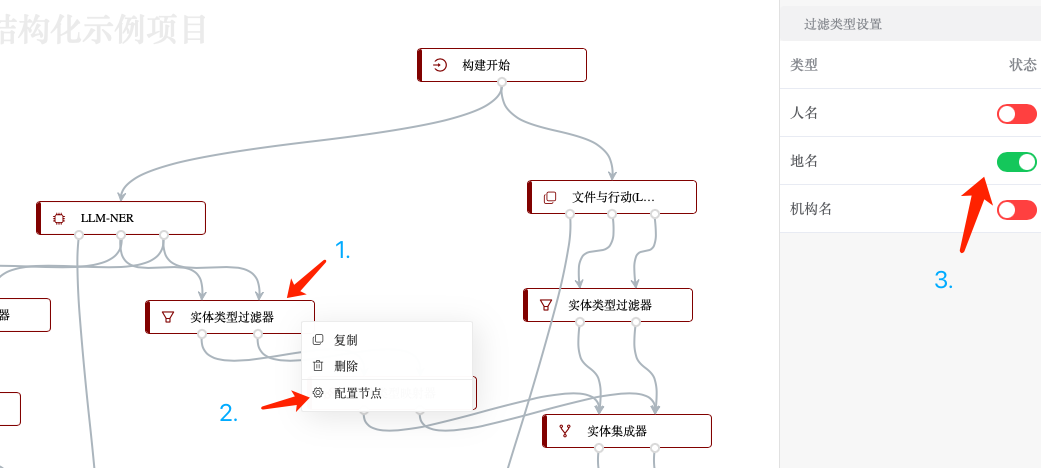
并通过一个“实体类型映射器”将“地名”这一实体类型映射成“地区实体”:
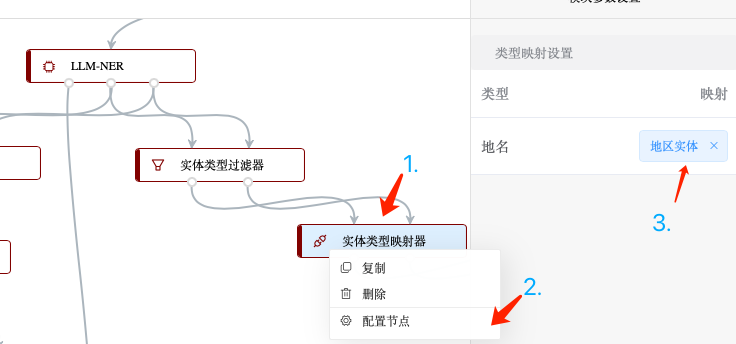
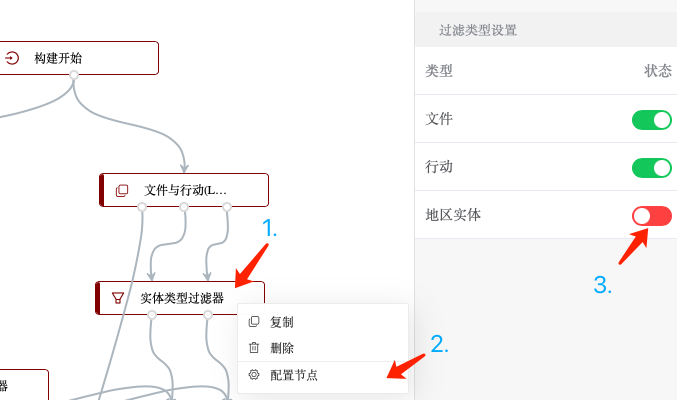
而自定义的实体抽取模型则只需要保留抽取出来的“文件”、“行动”实体,同样通过一个“实体类型过滤器”来实现:
并通过“实体集成器”节点,将两个模型产生的不同类型的实体融合在一起:
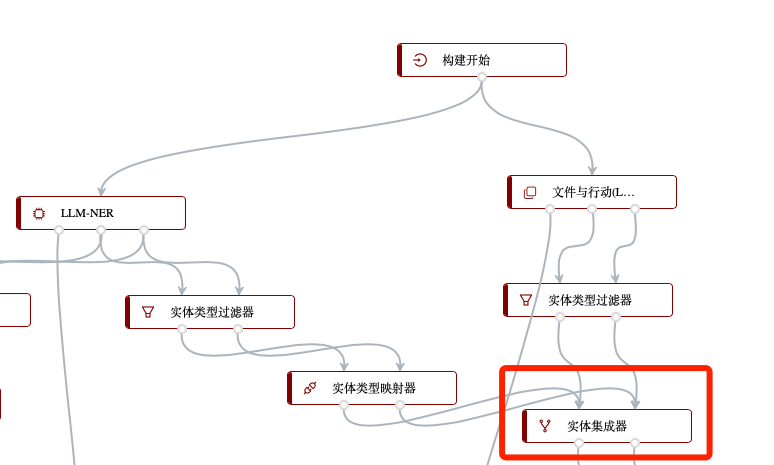
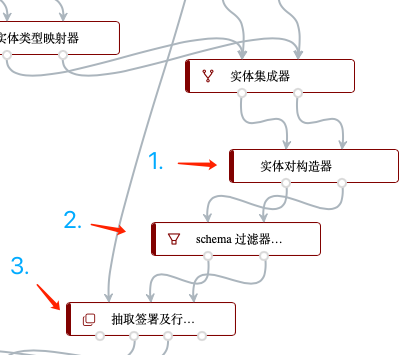
接下来,便可以重复3.1.1.5中的步骤,为上述步骤得到的“地区实体”、“文件”、“行动”实体构建并过滤实体对,从而输入刚才训练得到的“签署文件”、“进行行动”关系识别模型:
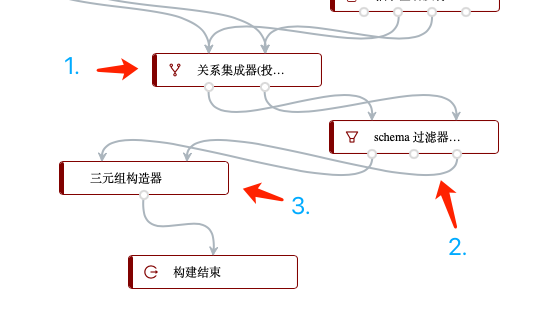
最后,将这一个包含与文件、行动相关的数据旁路,通过“关系集成器”进行合并(下图步骤1),经过schema关系过滤器过滤掉不需要的关系种类后(下图步骤2),使用三元组构造器将头尾实体以及它们之间的关系进行整合,从而得到最终所需要的图谱:
完成整个抽取流程设计后,通过运行 > 运行测试,输入一条示例数据查看构建情况,可以得到类似下图的结果:
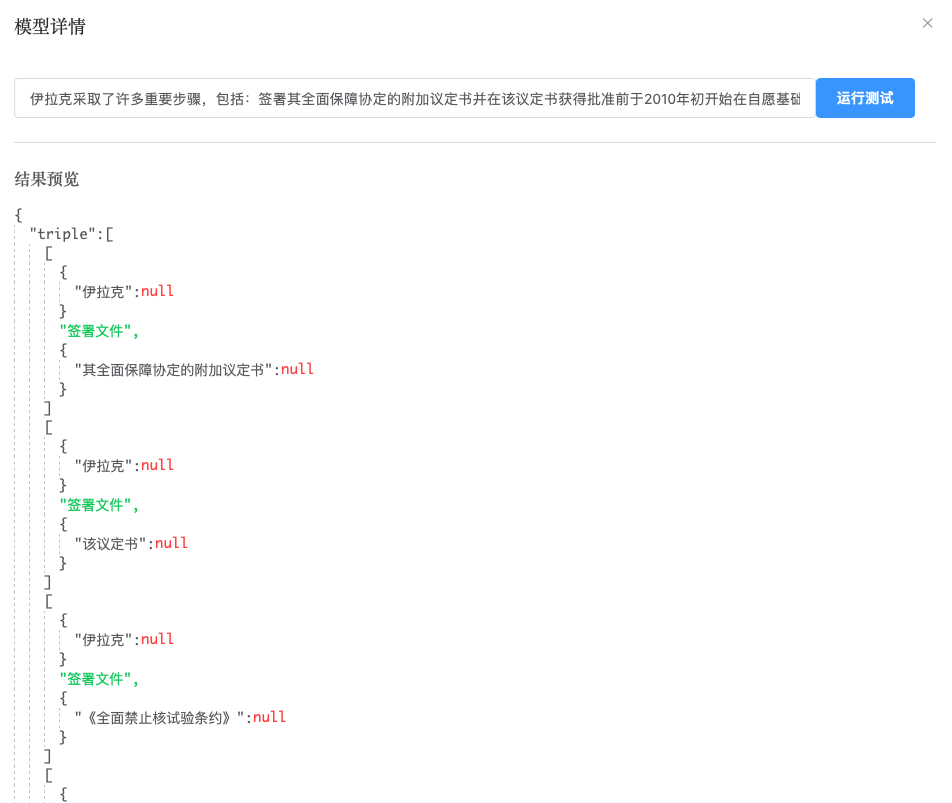
说明设计的抽取流程已经可以正常运作了。
请注意,用户可以随时根据需求,将“构建结束”节点与前面任一节点相连,则该节点将作为构建结束的出口,可以通过这种方式反复调试并查看在特定步骤时的构建情况。
请注意,如果自定义抽取模型效果不佳,您可以将抽取错误的数据,作为标注数据重新执行前面数据标注到训练模型的步骤,通过这种方式迭代数次,一般都能得到效果较好的自定义模型。该种调试模型一般称为“主动学习”或“人在回路学习”(Human-in-AI-loop),可以通过发现困难样本、标注困难样本,快速提高模型的能力。
7. 构建图谱并导出NT文件
请参考本手册2.4.4.2.3.10 开始构建、2.4.4.2.4 构建状态、2.4.4.3 下载 nt 文件章节操作,将前面设计好的构建工作流在全量数据集上运行,从而得到该数据集中符合schema设计的图谱数据。
完成构建后,应当能在“构建状态”选项卡中看到全部构建步骤都变为绿色:
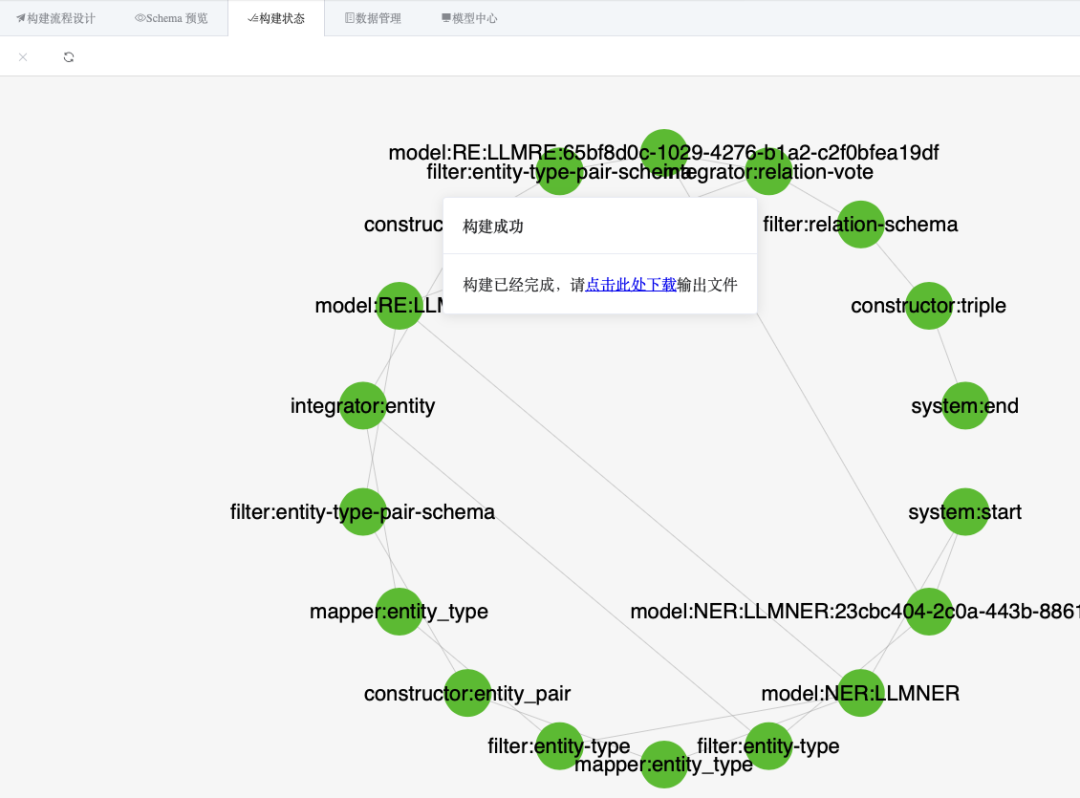
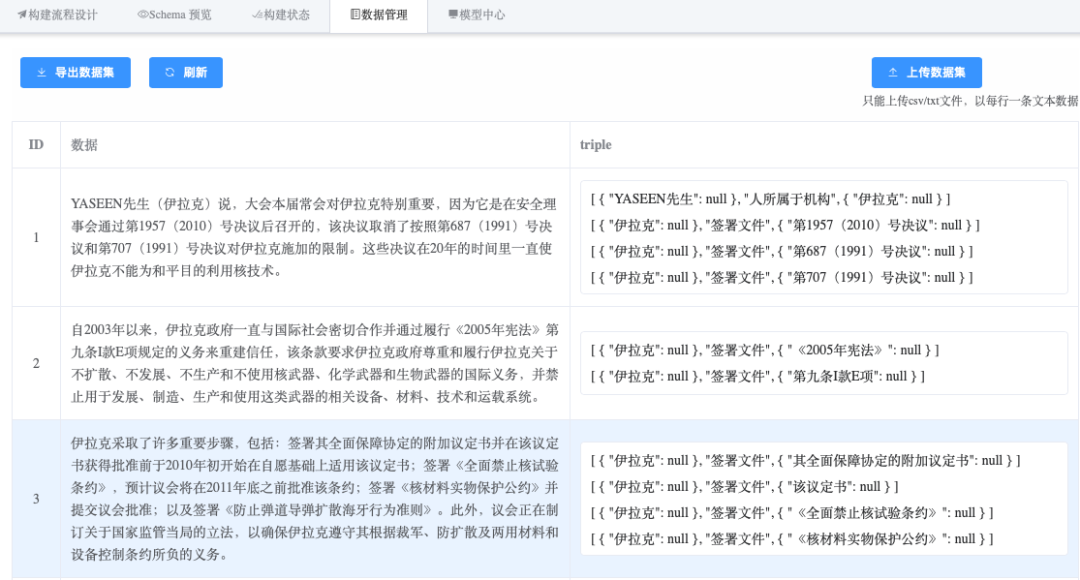
“数据管理”选项卡中出现triple列:
此时,可以点击菜单中的运行 > 生成.nt文件,在gBuilder左侧菜单的知识抽取 > NT生成日志中,可以找到刚才构建得到的数据,点击“下载”将相关数据导出,如下图所示:

8. 使用gCloud或Workbench对图谱进行可视化
gCloud(http://cloud.gstore.cn)提供了在线的RDF数据库云服务及可视化分析组件,Workbench提供了针对本地gStore服务的可视化分析组件,用户可以根据具体需要进行选择。下面以gCloud为例说明如何对上述会议记录抽取得到的图谱进行简单可视化及分析。
进入gCloud控制面板,通过左侧菜单选择 会员专区 > 数据库管理,确认数据库实例处于运行状态(如果提示数据库没有运行,请点击右上角的“启动实例”按钮)。点击“新建”按钮,创建一个新的数据库:
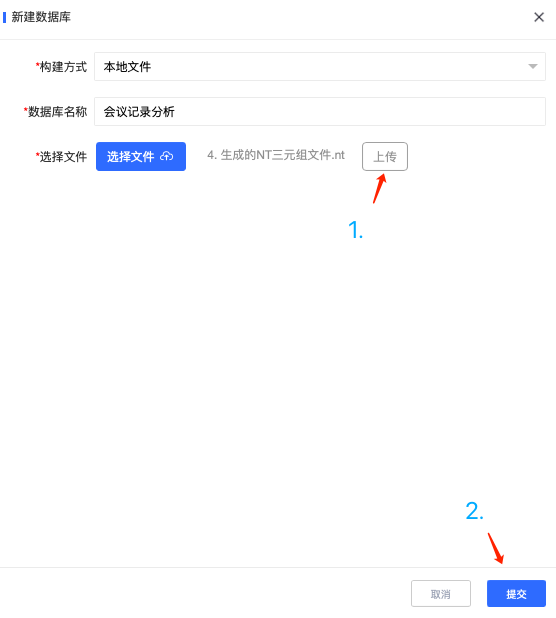
将刚才得到的.nt文件,上传至gCloud平台。在创建出来的新数据库上,点击“查询”按钮,进入查询面板,输入查询SPARQL:
SELECT *
WHERE {
?s ?p ?o .
}
LIMIT 500
并点击“查询”:
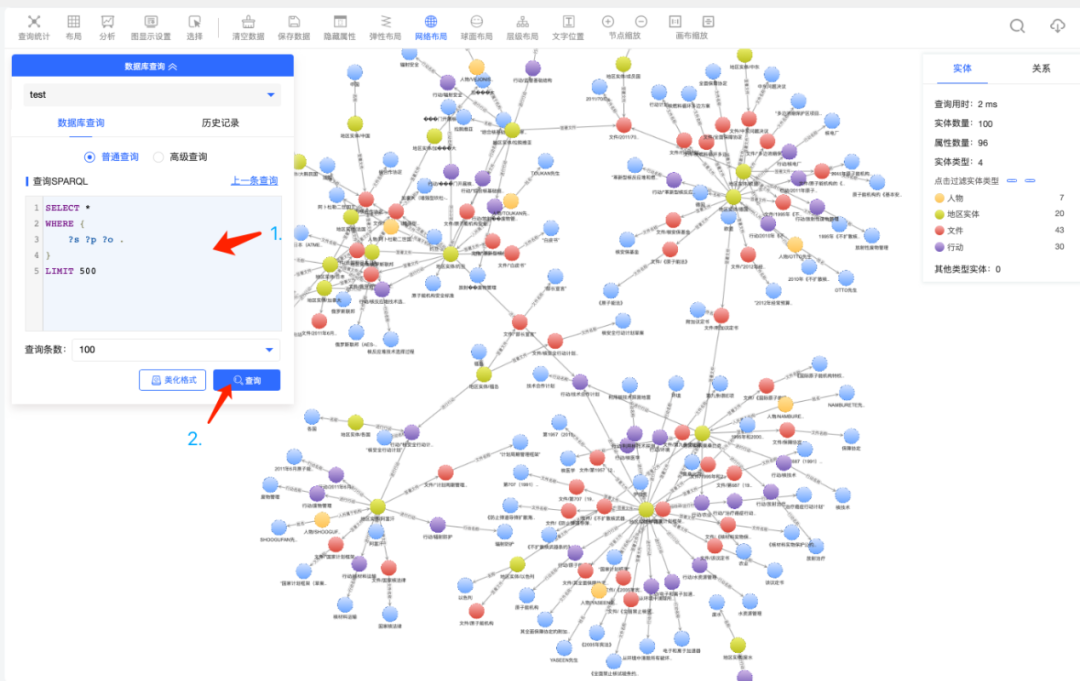
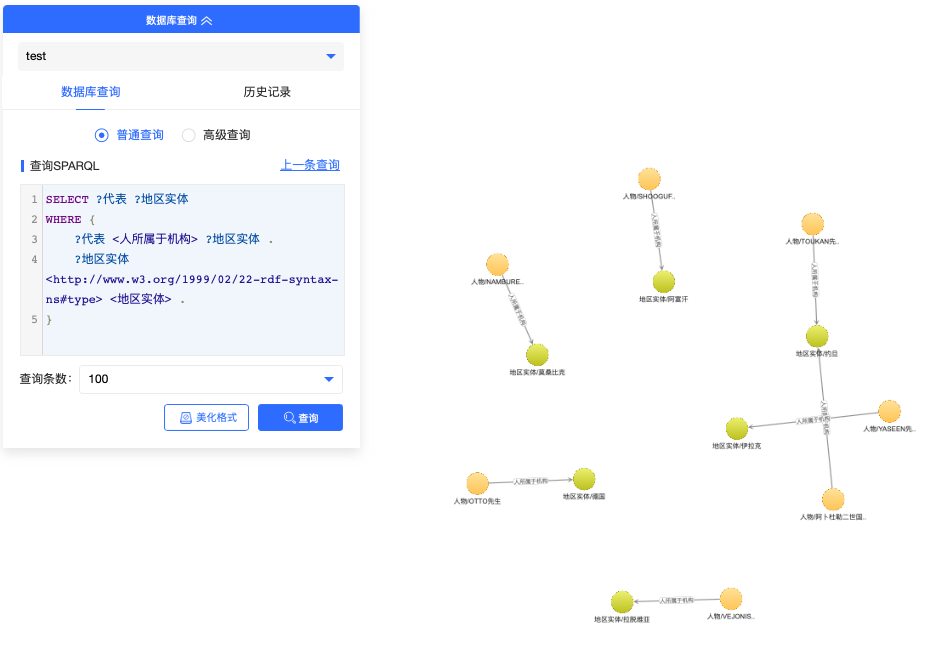
即可将刚才构建出图谱的全貌进行可视化预览。您可以在画布中左键或右键点击各个节点与之交互,也可以使用各种各样的查询对这个图谱数据进行进一步发掘。例如,可以使用如下查询:
SELECT ?代表 ?地区实体
WHERE {
?代表 <人所属于机构> ?地区实体 .
?地区实体 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <地区实体> .
}
查询出各个地区实体/国家在该次会议上的代表人或发言人,如下图所示:
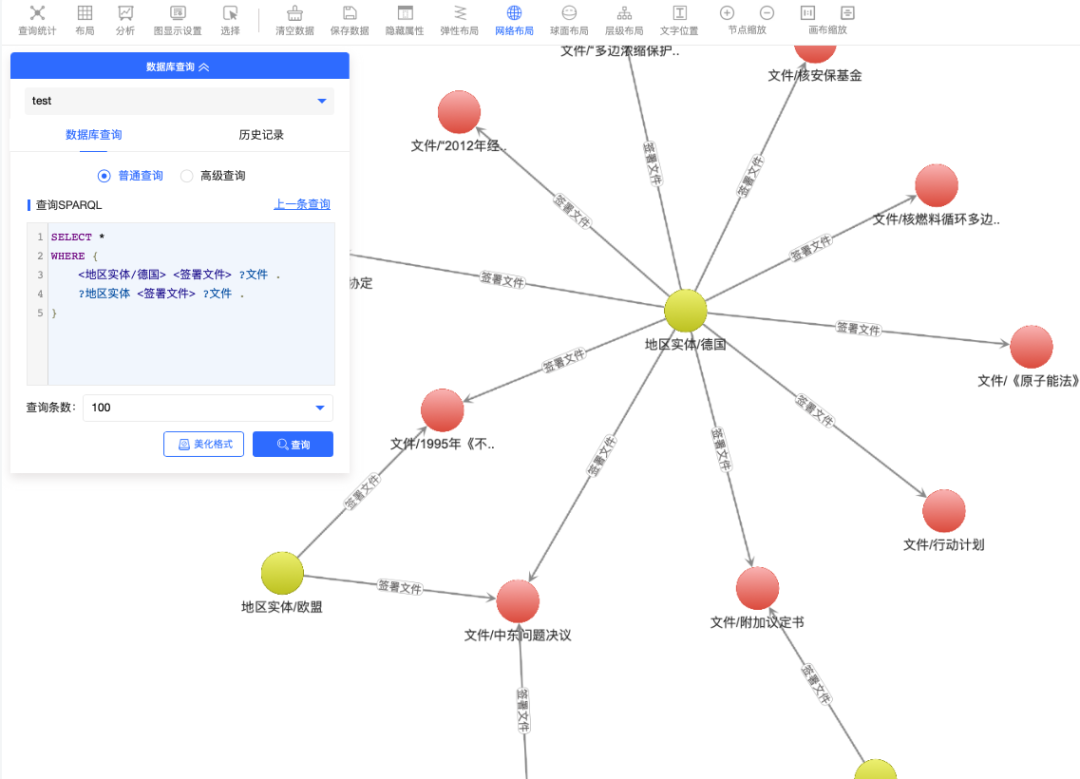
或可以使用下列查询:
SELECT *
WHERE {
<地区实体/德国> <签署文件> ?文件 .
?地区实体 <签署文件> ?文件 .
}
对与德国签署过相同文件的国家进行关联分析,如下图所示:
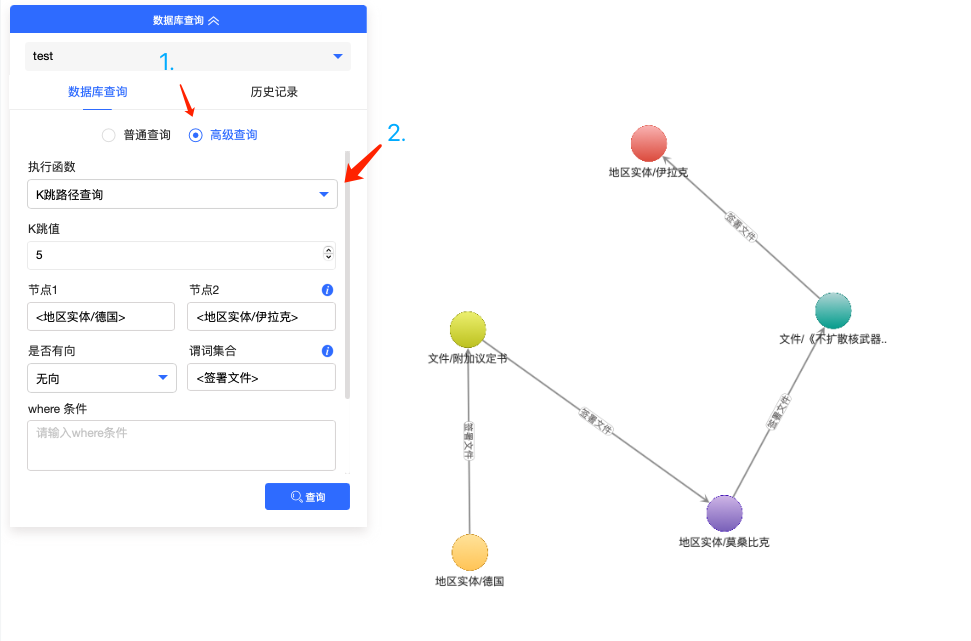
也可以使用“高级查询”功能,探索在该次会议中“德国”与“伊拉克”通过共同签署或间接签署文件所产生的K跳关系,如下图所示:
通过上述演示案例,我们展示了“Topgraph+大模型”在非结构化数据抽取方面的强大能力。展望未来,我们将不断推进“Topgraph+大模型”技术的创新与完善,开发更多高级功能,以适应企业客户多变的业务需求,将知识的力量转化为推动企业发展的强大动力。目前这项技术,已经成功应用于金融、政务、教育、医疗、工业等行业。
更多关于针对图谱分析、探索的用法,以及SPARQL查询语言的介绍,请参考官方文档 https://www.gstore.cn/pcsite/index.html#/documentation 。
产品免费试用
关于途普智能
途普智能科技(北京)有限公司是一家专注于图数据库系统研发、知识图谱应用的高科技创新企业,由北京大学科技成果转化所创立。公司致力于打造国产图数据库的“中国芯”,提供从知识构建、管理到服务系统为一体的TopGraph企业知识中台产品和行业解决方案,目前已部署于工业质量管控、金融风险分析、政务大数据、智能问答机器人、电信欺诈检测等多个场景,并在金融、政务、工业、教育、医疗等行业广泛应用。


















 3669
3669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









