







目录
研究动机
现有的资源高效方法,如滑动窗口技术,虽然能够将高分辨率图像分割成较小的补丁并进行处理,但在处理跨越多个补丁的物体时,通常会降低识别精度。
提出了 HiRes-LLaVA,这是一种在不破坏原始上下文和空间几何形 状的情况下将高分辨率数据集成到 LVLM 中的有效方法。
主要贡献
-
EntityGrid-QA Benchmark
用于评估模型在处理切片方法导致的上下文碎片化方面的能力,包括识别、位置和计数任务
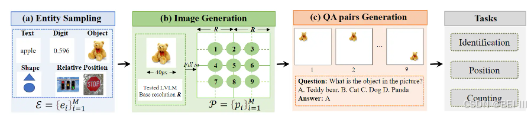
构建过程有三步:
a. 实体抽样: 从 预定义的实体集中选择一个或两个实体;
b. 图像生成: 将选定的实体放置在从空白图像 的九个预定义位置, 图像会被分成4块;
c. QA 对生成: 根据生成的图像、实体、类别和位置,我们可以自动生成问答对(QA)。QA包含三个不同的任务,即识别、定位和计数。
评估指标:

-
HiRes-LLaVA framework
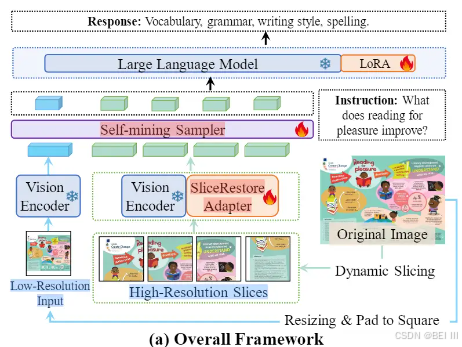
整体框架:
- 视觉编码器两个分支输入
- Low-Resolution Input:通过 CLIP-ViT 处理低分辨率图像以提取全局特征
- High-Resolution Slice用于高分辨率图像以捕获细粒度细节
-
SliceRestore Adapter
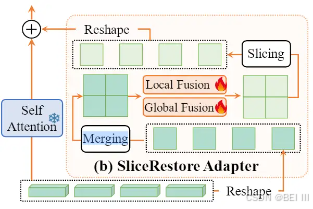
该组件通过捕获局部和全局信息将切片特征恢复为整个特征,然后将整个特征分割回切片
- SRA集成在CLIP-ViT的自注意力层

- SRA的三个步骤:
- Capturing:用两个Fusion模块来捕获局部和全局信息,局部用3*3内核的单层卷积,全局对特征downsample然后用自注意力再上采样回原来的大小。于是得到增强的特征
- Merging: Pi->Hi->F 意义是恢复原始输入特征
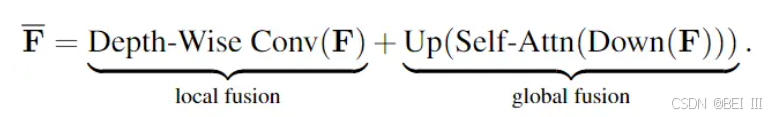
-
-
- Slicing:把增强特征
切回原始格式得到
- Slicing:把增强特征
-
-
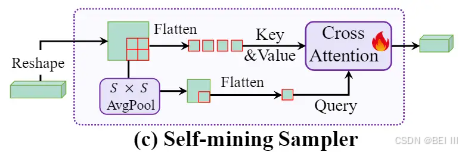
Self-Mining Sampler
动机:高分辨率图像需要处理更多的视觉标记,从而导致很大一部分计算负载。现有的解决方案, 有例如 Q-Former :
- Q-Former工作原理:Q-Former使用固定数量的查询(queries)通过交叉注意力机制来压缩和捕获视觉特征。
- 缺点:缺乏位置信息:由于使用的是固定查询,丢失了位置信息,这对于需要空间关系和精确位置的任务表现不佳。高训练开销:训练Q-Former需要更多的数据和更长的训练时间,这在数据稀缺的领域是一个挑战。
- 优点:能够在计算上较为经济地处理不同分辨率的图像,有效地捕获视觉信息。
-
为了解决Q-Former 缺点,文章提出Self-Mining Sampler:
工作原理:Self-Mining Sampler使用平均池化的切片(sliced patches)作为查询,而不是固定的可学习查询。
优点:保留原始上下文和位置信息:通过使用平均池化的切片作为查询。
与Q-former相比,训练开销低。
-
- 视觉特征的二维重塑:首先,将视觉编码器(如 CLIP-ViT)输出的视觉特征从一维形式(P ∈ R^L×D)重塑为二维形式(H × W × D),其中 L = H × W。这一步骤的目的是为了更好地保留图像的空间结构信息。
- 平均池化:接下来,使用大小为 S × S 的池化核对重塑后的视觉特征进行平均池化。这一步骤的目的是压缩视觉特征,减少计算量,同时保留重要的空间信息。
- 交叉注意力机制:最后,使用交叉注意力机制(Cross-Attn(P_c, P))来计算最终的压缩特征。通过这种方式,Self-Mining Sampler 能够在保留原始上下文和位置信息的同时,有效地压缩视觉特征。
-
动态高分辨率切片
- 动态切片高分辨率图像,而不预定义宽高比候选,支持各种分辨率图片的输入。
- 通过设置最大切片数M,允许图像根据基础分辨率自动选择最佳边界框,确保详细信息的保留而不过度增加模型的计算负担。
实验结果
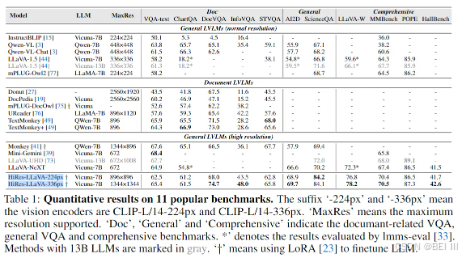
- on 11 popular benchmarks
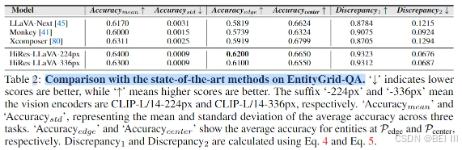
2. on EntityGrid-QA
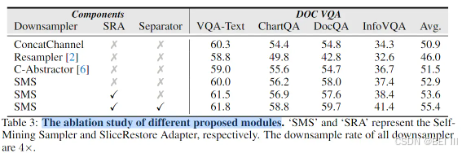
3. 消融实验


















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









