







 本文探讨了如何在自动驾驶中通过深度卷积神经网络(DCNN)实现传感器融合,以提高感知准确性。作者提出了特征差异度量和融合过滤器,用于解决不同模态特征图的不匹配问题。融合过滤器是一个1*1卷积模块,用于学习不同图像数据间的非线性关系,实现特征图的融合。此外,通过深层共享技术和Auxiliary Weight Network,能够在减少计算开销的同时提高准确性。实验证明,这种方法在KITTI数据集上表现优秀,特别是在城市道路场景下。
本文探讨了如何在自动驾驶中通过深度卷积神经网络(DCNN)实现传感器融合,以提高感知准确性。作者提出了特征差异度量和融合过滤器,用于解决不同模态特征图的不匹配问题。融合过滤器是一个1*1卷积模块,用于学习不同图像数据间的非线性关系,实现特征图的融合。此外,通过深层共享技术和Auxiliary Weight Network,能够在减少计算开销的同时提高准确性。实验证明,这种方法在KITTI数据集上表现优秀,特别是在城市道路场景下。

论文标题:Enabling Efficient Deep Convolutional Neural Network-based Sensor Fusion for Autonomous Driving
论文链接:https://arxiv.org/abs/2202.11231
论文代码:
发表时间:2022年2月
本文基于数据融合架构 RoadSeg 的基础上进行改进,增加一个融合过滤器,本质上是一个1*1的卷积模块,旨在寻找两种不同图像数据的非线性关系,转换成同一种数据图像,进行融合,实现语义互补。
Abstract
自动驾驶需要准确的感知和安全的决策。为了实现这一目标,自动驾驶汽车现在配备了多个传感器(例如摄像头、激光雷达等),使它们能够通过融合来自不同传感模式的数据来利用互补的环境背景。 随着深度卷积神经网络(DCNN)的成功,DCNN之间的融合已被证明是一种有前途的策略,可以实现令人满意的感知精度。然而,现有的主流DCNN融合方案通过直接将在各个阶段从不同模态提取的特征图逐个元素地添加到一起来进行融合,没有考虑被融合的特征是否匹配。因此,我们首先提出了一个特征差异度量来定量测量被融合的特征图之间的特征差异程度。然后,我们提出融合过滤器作为一种特征匹配技术来解决特征不匹配问题。我们还提出了一种深层共享技术,该技术可以以更少的计算开销实现更高的准确性。再加上特征差异作为额外损失的帮助,我们提出的技术使DCNN能够从不同的模态中学习具有相似特征和互补视觉上下文的相应特征图,以实现更好的准确性。实验结果表明,我们提出的融合技术可以在 KITTI 数据集上以更少的计算资源需求实现更好的精度。
Personal Understanding
在自动驾驶领域,自动驾驶汽车的安全性取决于传感器感知结果的准确性。
因此提出从不同模态中,例如相机和激光雷达,采集的不同信息进行融合,从而实现信息互补,提供更好、更强大的感知性能。
本文使用两种不同模态分别为:RGB图像和深度图像(从激光雷达(LiDAR)采集的3D点云进行预处理),如图(a),(b)。
图(c)为分割结果,绿色代表可驾驶道路

由于不同模态的数据,通过预处理,得到的图像是有差异的,因此首先要寻找差异在哪里,并且进行校准。
作者提出两处创新:
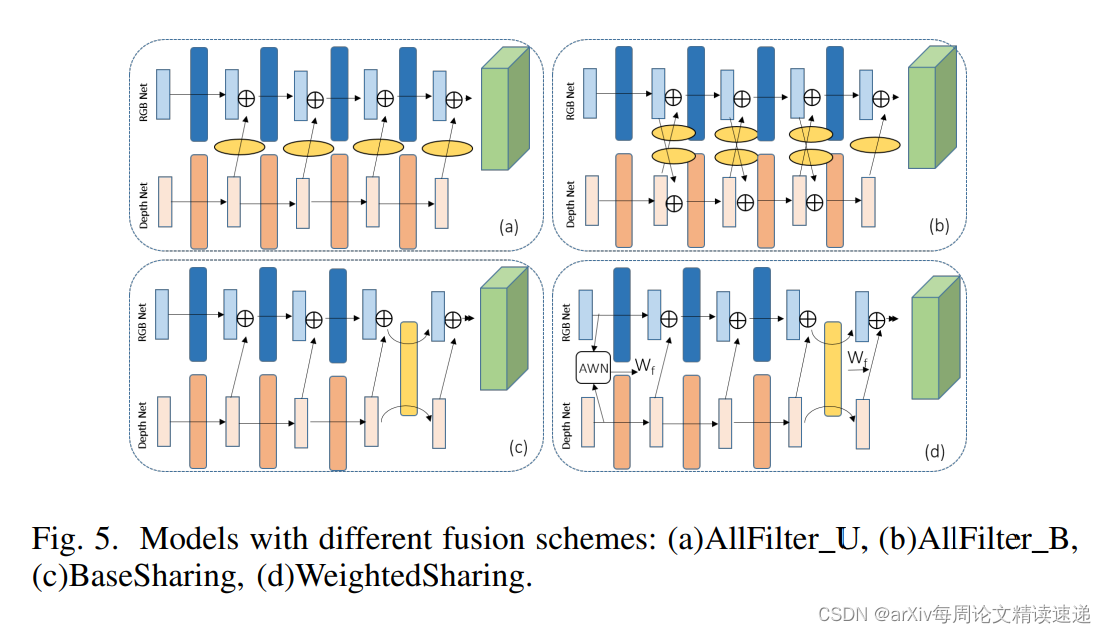
1、Fusion-filter(融合过滤器),它学习要融合的特征图之间的特征匹配关系,以保证特征匹配
2、深层特征差异不明显,将 Fusion-filter 参数共享
Method
1、首先对于两种传感器采集的数据RGB和Depth进行预处理,
预处理使用方法是RoadSeg架构,就是简单的卷积、正则化、残差,架构如图:
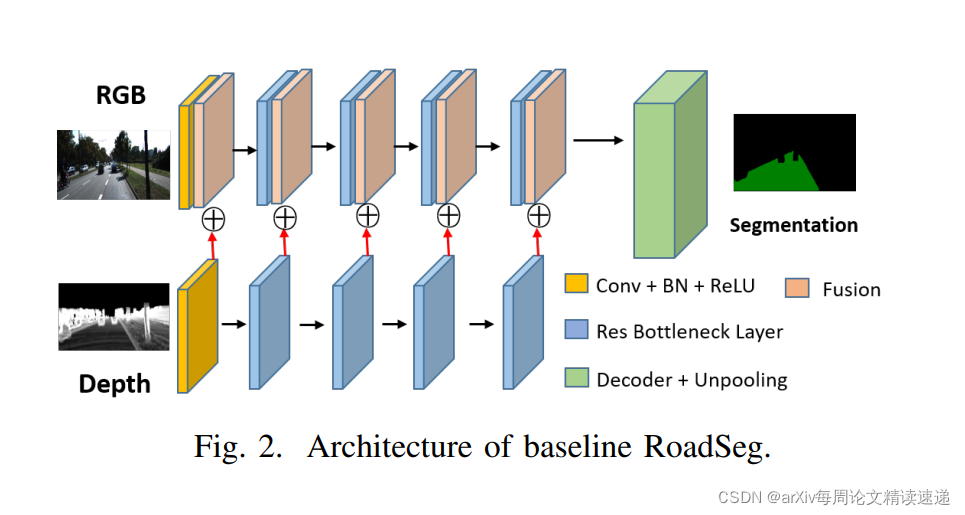
这里提及一下RoadSeg架构 Fusion 使用的就是加法规则,
2、处理后的数据,只将Depth的特征进入Fusion-filter,输出后的特征与 RGB 的特征按元素进行相加操作,如图:
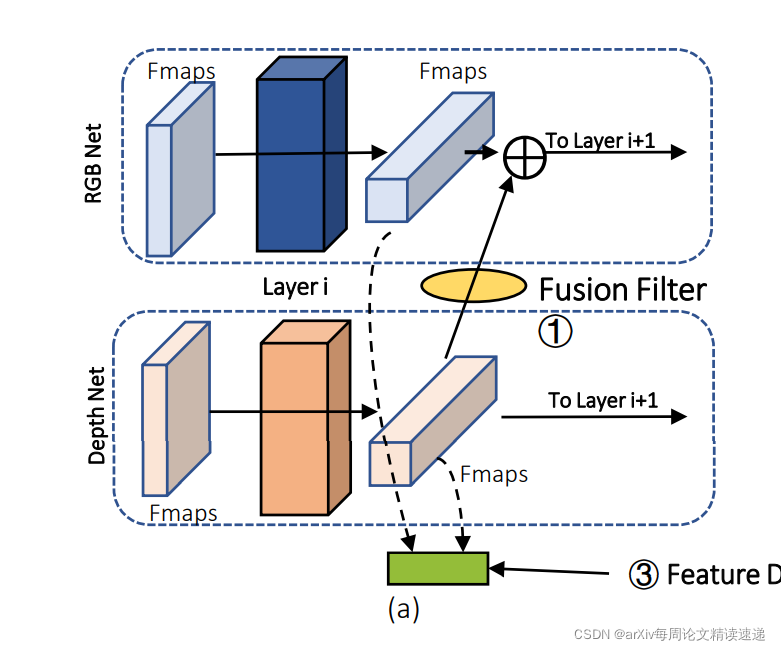
这里要重点讲一下Fusion-filter内部构造,其中就是卷积操作,作用在于寻找两种模态之间的关系,
原文如下:

Fusion-filter 旨在 Depth 的 Fmaps 通过与 Fusion-filter进行卷积来重建 Depth 新特征图,它能够从训练数据中学习从 Depth 到 RGB 特征图的匹配关系。本质就是非线性变换。
Fusion-filter的内核大小为 1x1,因为它仅旨在重组这两组特征图之间的映射关系。
到此文章重点部分已经结束,下面文章作者进行优化改进
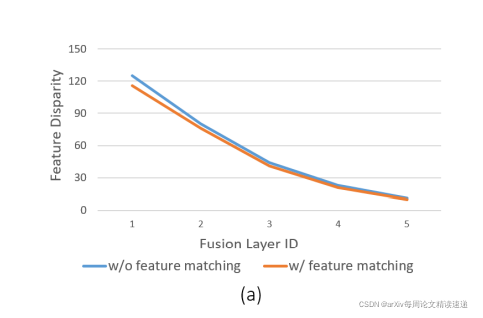
经过实验,发现层数加深,差异越小,因此提出,在深层中使用参数共享的方法,减少运算
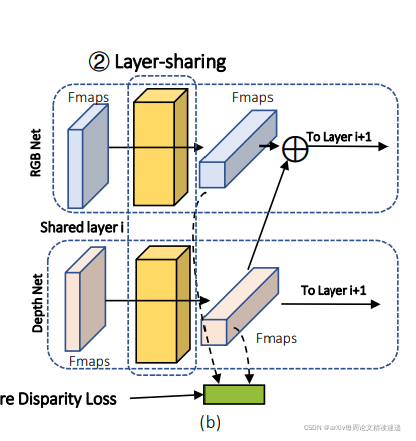
中间黄色矩形框内的参数共享,对应深层中的 Fusion-filter,
并且考虑到,这两个特征去是基于两个不同的传感器的感知模式进行的提取,
所以在分层共享后的结果特征图上应用Auxiliary Weight Network(AWN)本质就是全连接层,寻找非线性关系。将两种模态的特征,转换成一种特征,最后输出特征向量Wf
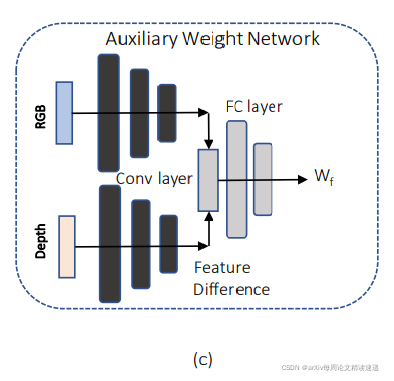
到此,作者构建四种使用 Fusion-filter 架构,如图:
实验结果如下:
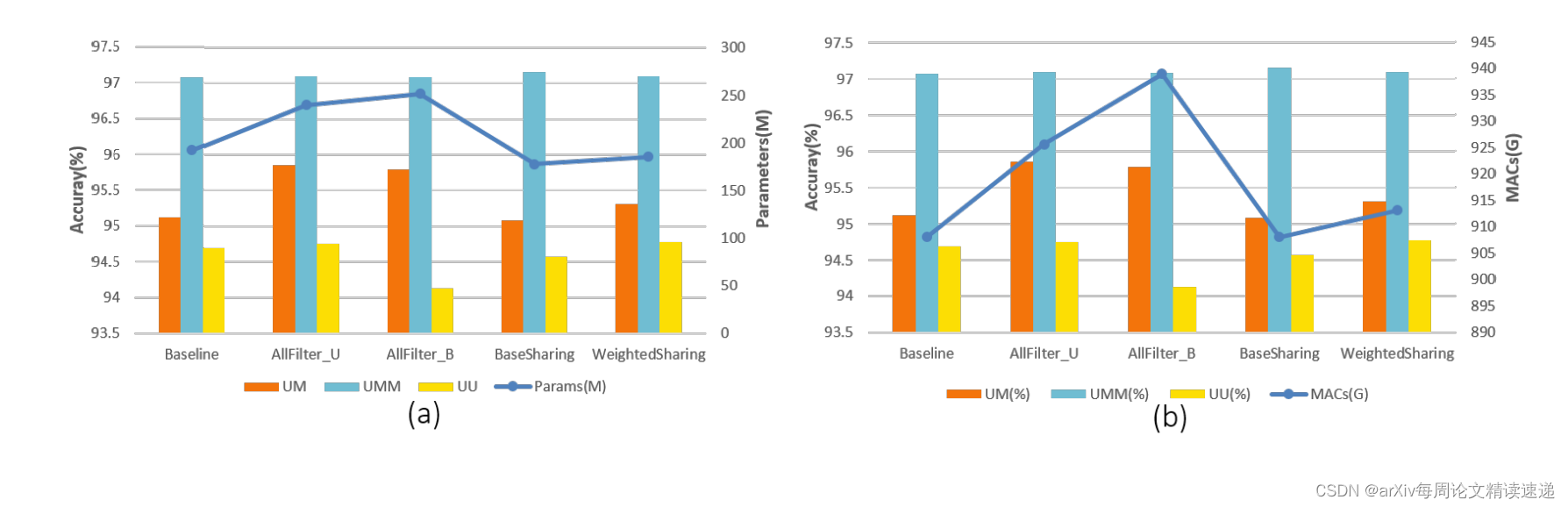
城市标记道路 (UM)、城市多标记车道 (UMM) 和 城市无标记道路(UU)
观察看实验结果,四种架构各有优势,但本文对标的架构 RoadSeg 是2020年的作品,并非目前效果最优的架构。Fusion-filter 是否能冲击最优目前未知,
本实验仅使用了一块NVIDIA’s Quadro RTX 8000 GPU 完成实验。


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











