







arXiv | https://arxiv.org/abs/2406.18394
GitHub | https://github.com/DulyHao/AlphaForge
摘要:
金融数据的复杂性,以其可变性和低信噪比为特征,需要优先考虑绩效和可解释性的先进量化投资方法。从早期的人工提取过渡到遗传规划,目前alpha因子挖掘领域最先进的方法是使用强化学习来挖掘一组具有固定权重的组合因子。然而,最终alpha因子的表现表现不一致,固定因子权重的不灵活性证明不足以适应金融市场的动态性。为了解决这个问题,本文提出了一个两阶段的公式化alpha生成框架AlphaForge,用于alpha因子挖掘和因子组合。该框架采用生成-预测神经网络来生成因子,利用深度学习固有的强大空间探索能力,同时保持多样性。框架内的组合模型结合了选择因子的时间表现,并动态调整分配给每个成分alpha因子的权重。在真实世界数据集上进行的实验表明,我们提出的模型在公式化alpha因子挖掘方面优于当前基准。此外,我们的模型在量化投资和真实投资领域内显示出显著的投资组合收益增强。
一、引言
1.1 研究动机
- 在投资实践中,投资经理经常将大量的alpha因子收集到因子库中,再通过组合模型组合形成交易的最终信号 Mega-Alpha,由于金融市场对可解释性的重视,组合因子的模型通常采用线性结构。
- 前沿的研究使用强化学习方法(Yu et al., 2023)将组合模型和挖掘过程集成到一个统一的框架中,同时进行因子挖掘和组合为 Mega-Alpha。但固定的因子和权重有时会使Mega-Alpha的某些部分无效,甚至逆转它们的效果,因此必须考虑每个Alpha因子的选股能力的周期性,以及随着时间推移可能出现的逆转。
1.2 主要贡献
为了解决alpha因子的利用率及其波动问题,我们提出了一个两阶段alpha因子挖掘和组合框架,由挖掘因子的生成-预测神经网络(generative-predictive neural network)和根据性能动态选择和组合因子的复合模型组成。
- 引入了生成-预测因子挖掘模型,该模型利用深度学习强大的空间探索能力,即使在目标函数稀疏且复杂的情况下也能有效地挖掘alpha因子。此外,因子挖掘过程中的目标函数是可变的。
- 提出了一个动态alpha因子组合模型来生成Mega-Alpha,允许动态考虑新市场数据的时变影响,生成实时动态权重。
- 进行了一套全面的实验来验证我们提出的方法的有效性,实验和实际投资证明,因子择时可以产生有利的结果。
二、公式化因子
公式化因子是一个函数,通过数学表达式(由运算符和操作数组成)将 n n n 只股票前 τ \tau τ 天的 m m m 个基本特征的原始特征矩阵 X t ∈ R n × m τ X_t\in \R^{n\times m\tau} Xt∈Rn×mτ 映射到因子值 v t = f ( X t ) ∈ R n v_t=f(X_t)\in \R^n vt=f(Xt)∈Rn,使用逆波兰表达式(RPN)来表示公式。
- 原始特征:开盘价、最高价、最低价、收盘价、成交量和VWAP
- 评价指标:IC、ICIR、Rank IC和Rank ICIR(Pearson相关系数的时间序列平均值)
三、模型方法
本文的因子挖掘框架由两个部分组成:
- 生成-预测结构的alpha因子挖掘网络,生成一批具有低相关性和高质量特征的alpha因子,形成因子动物园;
- 考虑因子的时间序列属性的因子时序模型,利用更新的历史数据在每个时间点重新评估因子动物园中每个因素的近期表现,形成适应市场变化的 Mega-Alpha。
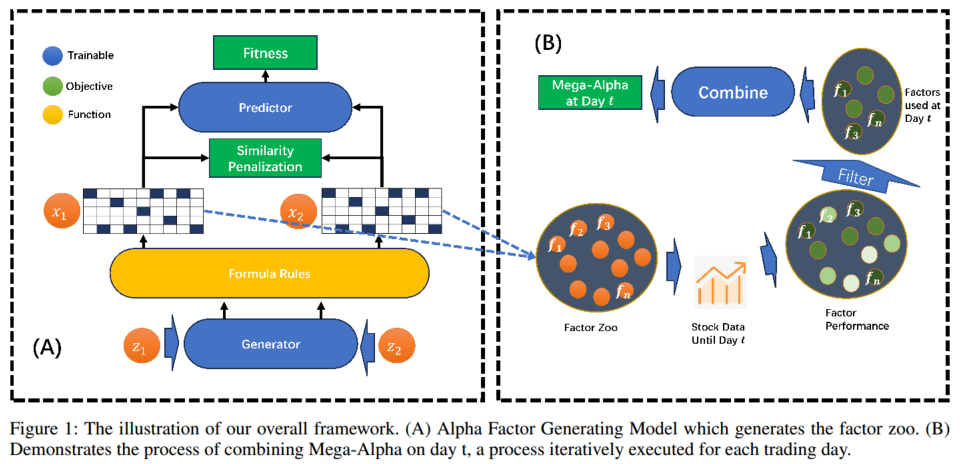
3.1 因子挖掘模型
基于生成-预测神经网络结构的因子挖掘模型包括生成器(Generator)和可微的预测器(Predictor)。预测器作为代理模型,学习并预测因子的适应度得分**(预测器可以提高因子挖掘的效率,不用每次使用fitness来判断因子好坏);生成器负责产生候选Alpha因子,以正态分布噪声输入并转化为独热矩阵输出,以最大化预测器的输出值来训练生成器,即使得生成的Alpha因子具有高适应度**。
- 适应度 fitness 使用IC和ICIR来过滤选股能力和稳定性,使用与库中现有因子的相关性避免选股能力重叠:
π ( x , Z , X , Y ) = { Abs ( I C ( f , X , Y ) ) , f is valid and ψ ( f , Z , X , Y ) < C O R R ′ 0 , e l s e \pi(x,Z,X,Y)= \begin{cases} \text{Abs}(IC(f,X,Y)) &, \text{f is valid and} \psi(f,Z,X,Y)\lt CORR' \\ 0 &, else \end{cases} π(x,Z,X,Y)={Abs(IC(f,X,Y))0,f is valid andψ(f,Z,X,Y)<CORR′,else
其中 f = parse ( x ) f = \text{parse}(x) f=parse(x) 表示从独热矩阵 x ∈ { 0 , 1 } D × S x\in\{0,1\}^{D\times S} x∈{0,1}D×S 解析出的公式, Z Z Z 表示现有因子集, ψ \psi ψ 计算 f f f 与 Z Z Z 中每个现有因子之间相关性的最大绝对值, C O R R ′ CORR' CORR′ 是手动设置的阈值。当 ∣ Z ∣ = 0 |Z|= 0 ∣Z∣=0时, π ( x , Z , X , Y ) \pi(x,Z,X,Y) π(x,Z,X,Y)返回因子IC的绝对值。
- 预测器网络 P ( x ) P(x) P(x) 在生成器网络 G ( x ) G(x) G(x) 训练之前,随机采样一组现有的因子样本库 R = { x 1 , … , x r } , R f i t n e s s = { f i t n e s s ( x 1 ) , … , f i t n e s s ( x r ) } R=\{x_1,…,x_r\},R_{fitness}=\{fitness(x_1),…,fitness(x_r)\} R={x1,…,xr},Rfitness={fitness(x1),…,fitness(xr)} 的训练数据进行独立训练,以确保其能够准确预测因子的适应度得分。预测器训练损失函数为:
L P = 1 n ∑ i = 1 n ( P ( x i ) − f i t n e s s ( x i ) ) 2 L_P=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(P(x_i)-fitness(x_i))^2} LP=n1i=1∑n(P(xi)−fitness(xi))2
- 生成器网络 G ( z ) G(z) G(z) 以生成能够最大化预测器输出的因子为目标开始训练。 G ( x ) G(x) G(x) 以 Q Q Q 维正态分布噪声 z ∈ R Q z\in R^Q z∈RQ 作为输入,输出一个 D × S D\times S D×S 的logit矩阵,并转化为独热矩阵 x = M ( G ( z ) ) ∈ { 0 , 1 } D × S x=M(G(z))\in \{0,1\}^{D\times S} x=M(G(z))∈{0,1}D×S,转化 M ( ) M() M() 涉及序列规则的掩码和使保持可微分性并允许梯度传播的 gumbel-softmax。为避免仅最大化预测器输出使得生成器过早收敛至局部最优解,通过对比两组 z 1 , z 2 z_1,z_2 z1,z2 采样产生的因子的相关性引入多样性损失。生成器训练损失函数为:
L G = L F i t n e s s + L D i v e r s i t y = − P ( x 1 ) + λ o n e h o t ∗ S i m i l a r i t y o n e h o t ( f ( z 1 ) , f ( z 2 ) ) + λ h i d d e n ∗ S i m i l a r i t y h i d d e n ( f ( z 1 ) , f ( z 2 ) ) \begin{split} L_G&=L_{Fitness}+L_{Diversity}\\ &=-P(x_1)+\lambda_{onehot}*Similarity_{onehot}(f(z_1),f(z_2))+\lambda_{hidden}*Similarity_{hidden}(f(z_1),f(z_2)) \end{split} LG=LFitness+LDiversity=−P(x1)+λonehot∗Similarityonehot(f(z1),f(z2))+λhidden∗Similarityhidden(f(z1),f(z2))
Algorithm 1:
- 初始化一个空的因子库;
- 随机采样现有因子,训练预测器P;
- 生成器重复进行以下过程,直到因子库达到预设的大小:
- 随机生成因子,并以最大化预测器输出和多样性为目标训练生成器;
- 评估新因子,合格的因子被加入到因子库中。

3.2 因子组合模型
动态权重因子组合模型采用线性模型进行因子组合,以保持模型的可解释性。在每个时间点 t t t,使用最新的前 n n n 天的数据对因子动物园中的因子根据最新的评价指标(IC、ICIR)进行重新排名和选择,选择前 N N N 个因子,拟合最佳线性模型来得到适应市场变化的 Mega-Alpha。

四、实验结果
数据:
- 中国A股的CSI300和CSI500成份股
- 2018-2022年滚动训练(7年训练,1年验证,1年测试)
- 目标设置为 ( Ref ( vwap , − 21 ) / Ref ( vwap , − 1 ) − 1 ) (\text{Ref}(\text{vwap},−21)/\text{Ref}(\text{vwap},−1)−1) (Ref(vwap,−21)/Ref(vwap,−1)−1)
基线方法:
- 遗传规划(GP)方法、深度符号优化 DSO 方法(Landajuela et al., 2022)、强化学习(RL)方法(Yu et al., 2023)
- XGBoost、LightGBM、MLP
- 为了避免随机种子的影响,每个模型重复运行5次
4.1 主要结果
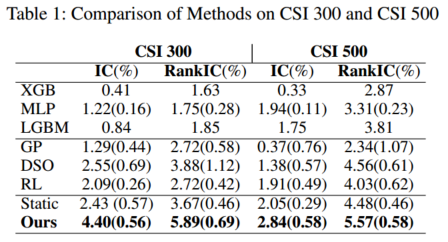
4.2 复合模型因子池大小影响
复合模型因子池大小:[1,10,20,50,100]
当复合模型因子池大小设置为10时,性能最高。我们将这一现象归因于组合模型中因素的动态选择:并非所有因素都始终有效,在任何给定时间大约有10个因素捕捉到最相关的价格信息。因此,进一步增加因子库的大小可能会导致 Mega-Alpha的收益递减。
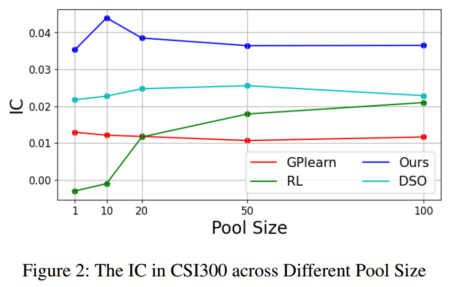
4.3 消融实验
Static:使用本文的因子挖掘模型来生成alpha,并使用与 RL 相同的方法组合Mega-Alpha
Dynamic(ours):本文所有模型
4.4 案例研究
因子动物园因子池大小100,复合模型因子池大小10,两个不同交易日 Mega-Alpha 因子的组成和相应的权重
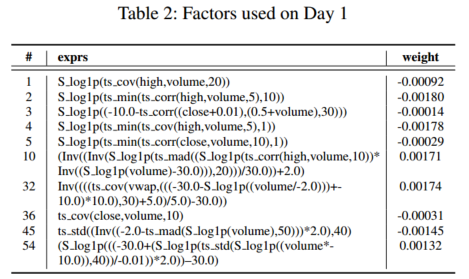
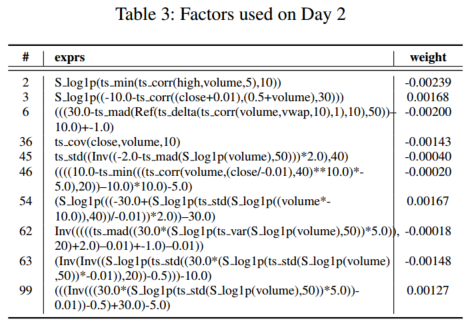
4.5 因子的可解释性
S_log1p(ts_cov(high,volume,20)) \text{S\_log1p(ts\_cov(high,volume,20))} S_log1p(ts_cov(high,volume,20)):过去20天内最高价与成交量的走势是否一致。这个因子的负权重反映了一种潜在的投资逻辑:当价格在上涨但没有引起多少关注时,可能值得考虑买入。当价格下跌,人群恐慌性抛售时,这可能是买入的机会。
4.6 模拟交易和真实投资
CSI300成份股,每日等权持有 Mega-Alpha 得分最高的前 50 只股票。此外,为了避免过高的交易成本,每天最多只能更换5只股票。
超额收益21.68%
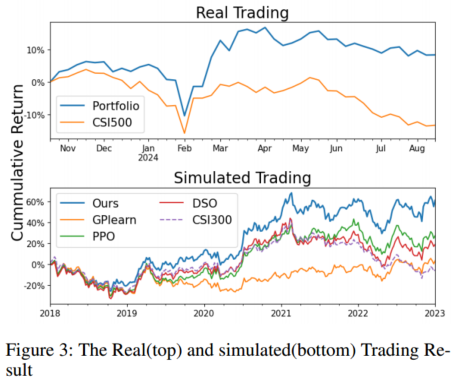
模拟交易和真实投资
CSI300成份股,每日等权持有 Mega-Alpha 得分最高的前 50 只股票。此外,为了避免过高的交易成本,每天最多只能更换5只股票。
超额收益21.68%
[外链图片转存中…(img-4hfIRVxu-1739196007255)]

















 3060
3060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









