







《十年一剑》
苍茫蜀山觅仙踪 挥剑难断未了情
千载之下同晓梦 死生不渝共鸳盟
永忆江湖初相逢 欲回人间共形影
海枯石烂心不弃 誓补情天鬼神惊
公司项目,已申请专利

生成模式作为深度学习技术的一大分支在图像领域有了较大发展,生成模式通过学习图像的数据统计分布特征,使用神经网络训练拟合这种统计分布特征,然后通过在得到的分布特征中随机采样,重构生成与原图同分布不同采样的新数据,即生成和原图“同类但不一样”的新图像。可以大量生成各种不同的新图像,扩充数据集。
基于生成对抗(GAN)的深度学习方法在生成模式中独树一帜,其独特的生成器和判别器对抗方式,极大提升了生成图像的质量。该方法包括一个用于生成图像的生成器模块和一个用于判别输入图像是真实图像还是由生成器生成的假图像的判别器模块,生成器尽可能生成以假乱真的图像试图骗过判别器,而判别器则尽可能地区分真假图像,两个模块在对抗中各自提升,最终达到纳什平衡,即判别器无法区别生成器生成的假图像和真实图像。但是生成对抗网络自身存在不可忽视的缺陷。
本专利为一种基于自对抗的深度学习生成模式,发明了一种新的自对抗模式,包括生成器G和反向器R。生成器G将从标准正态分布中随机采样的噪声数据Z使用基于反卷积和卷积操作的神经网络生成假图像G(Z),而反向器则使用生成器输出假图像G(Z)和真实图像X,使用基于卷积操作的神经网络编码成数据分布特征空间R(G(Z))和R(X)。两者进行互逆操作,生成器G将数据分布特征空间映射到图像,而反向器R将图像映射回数据分布特征空间,两个模块共享关键的卷积权重参数,即生成器G中的对应的反卷积权重参数和反向器R的卷积权重参数相同,两个模块各自从相对的角度同向逼近,相互对抗,由于共享关键权重参数,也可以和自身进行对抗,即自对抗生成模式。
一般生成模式都是单向映射模式,即从数据分布特征空间映射到图像,这种方式较难拟合出比较匹配的映射函数,训练时比较容易陷入局部最优值。本专利通过两个模块对抗训练进行双向映射,采用独创的自对抗方式共享权重参数,能更好的找到数据分布特征空间和图像之间的最优映射函数,即使某一模块陷入局部最优,另一个模块也可以通过权值共享使其跳出局部最优点。传统生成对抗网络的两个模块生成器G和判别器D是完全无关的神经网络,而本专利的生成器G和反向器R属于互逆模型,且共享卷积权重参数,能更好地进行互相对抗和互相监督。
本方案属于计算机视觉、图像生成领域,涉及一种基于多层卷积特征提取、注意力分配、反卷积图像重构的图像处理方法。包括采集训练图像,进行图像预处理;本发明设计了一种基于自对抗的神经网络模型称为SAN,包括一个生成器G和一个反向器R。生成器G用于通过在标准正态分布中随机采样Z,使用生成器得到期望的假图像;反向器R对真实图像X和由生成器G生成的假图像G(Z)进行反向映射成数据分布特征空间。
生成器G包括平面区域注意力模块(RPA);注意力机制模块(Attention);基于注意力的DropOut模块(ADO);PixelNorm;基于残差的反卷积操作。
反向器R包括平面区域注意力模块(RPA); 注意力机制模块(Attention);基于注意力的DropOut模块(ADO);PixelNorm;基于残差的卷积操作。
生成器G和反向器R对应的卷积核和反卷积核共享权重。
增加了L2正则化用于防止神经网络过拟合;增加了Resnet技术增加前后特征层的数据交互,最大限度保留浅层的特征,消除梯度消失现象;加入数据并行(DP)模式用于减少显存消耗和提升训练速度;
使用神经网络对训练数据集进行深度学习,将从标准正态分布里随机采样数据输入已完成训练的生成器G进行推理,生产能出新的图像。
本专利创造性地设计了一种自对抗生成模式,设计了一种共享关键卷积权重的互逆神经网络模型模块。
目录
1.基于自对抗的图像数据集生成模式
2. 训练图片获取及预处理
3.SAN神经网络模型设计
4.损失函数
5.SAN训练和生成过程
基于自对抗的图像数据集生成模式
本专利图像数据集生成方案分为真实图像训练集获取、自对抗神经网络模型设计编码、AI模型训练、AI模型测试部署五个步骤。
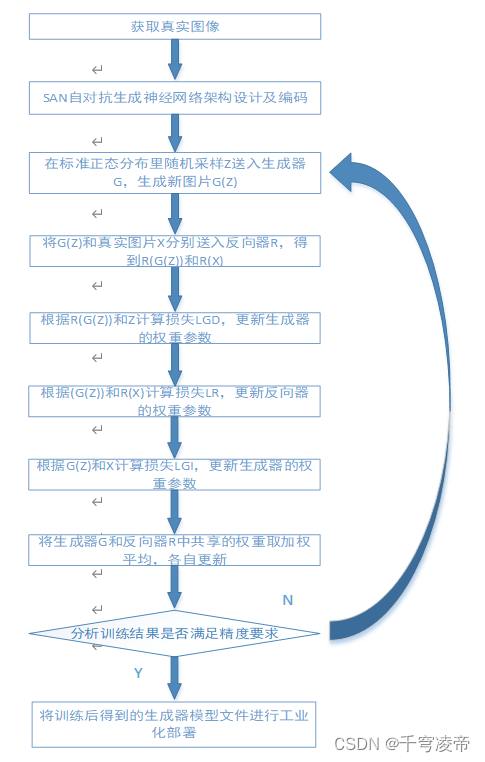
训练图片获取及预处理
本专利使用的是无监督的深度学习技术,AI模型处理的是图片数据,因此需要一些真实图片作为训练集,使用图像增强技术对训练数据集进行扩充。
SAN神经网络模型设计
本专利使用自对抗的神经网络进行图像数据集的生成,将从标准正态分布中随机采样数据Z输入生成器G,得到生成的假图片G(Z)。生成器网络基于平面区域注意力模块(RPA);基于3×3卷积的模块(Conv);基于注意力的DropOut模块(ADO);基于通道注意力模块(Attention);PixelNorm;反卷积模块(Conv_t);
本专利自主设计一套AI神经网络体系结构名为 SAN,如下图:
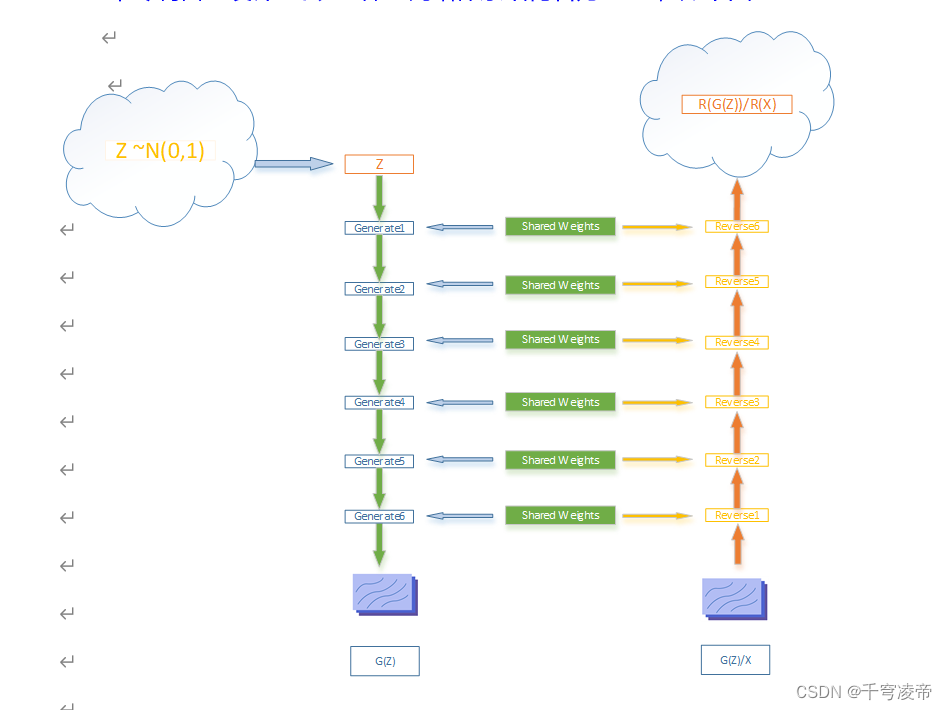
整个神经网络分为3个部分,一个生成器G,一个反向器R和共享卷积权重部分。在标准正态分布中随机采样数据Z送入生成器G,生成新的假图G(Z);将生成器生成的假图片G(Z)以及真实图片X分别送入反向器R,反向生成该图片的特征空间R(G(Z))和R(X),计算生成器损失值LG和反向器损失LR,分别更新生成器和反向器的权重值,然后将两者共享的权重值取加权平均作为两者新的共享权重值:
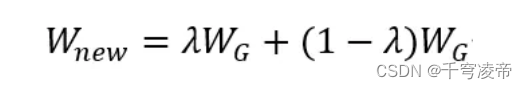
λ介于0-1之间;
生成器G如图左半部分所示,包括标准正态分布数据空间、6个生成模块Generator。反向器R如图右半部分所示,包括6个反向模块Reverse和生成特征空间。各层Generator模块和Reverse模块共享关键卷积权重值。
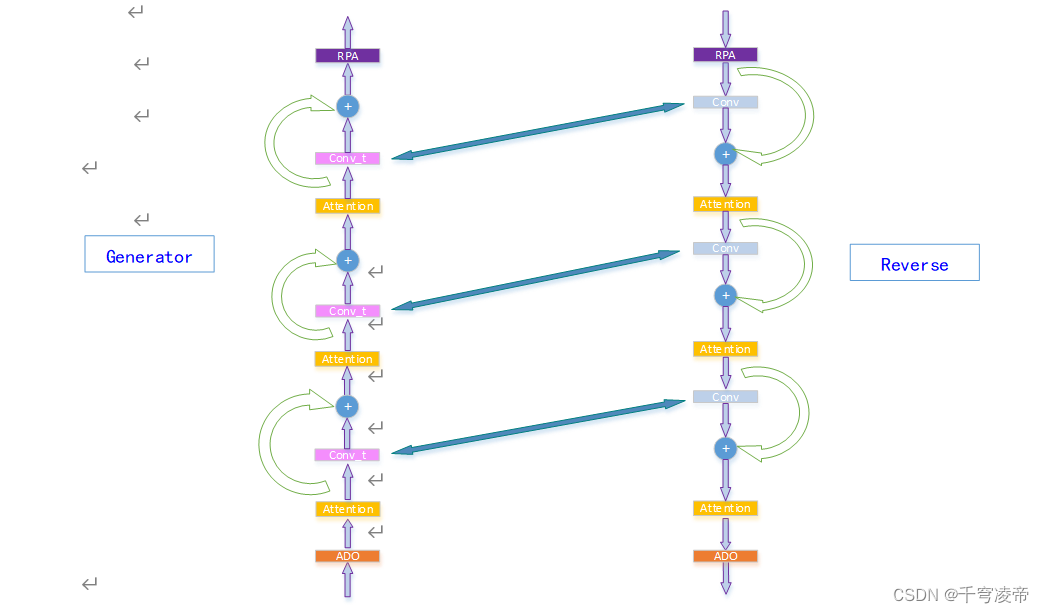
Generator
Generator如图左半部分所示,输入特征依次经过一个ADO、3个Attention/Conv_t块和一个RPA。每个Attention/Conv_t块有一个Split/Add操作作为Resnet结构,每个Conv_t包括反卷积操作、PixelNorm标准化和LeakyReLU激活函数。
Reverse
Reverse如图右半部分所示,和Generator进行反向操作,输入特征依次经过一个RPA、3个Attention/Conv块和一个ADO。每个Attention/Conv块有一个Split/Add操作作为Resnet结构,每个Conv包括反卷积操作、PixelNorm标准化和LeakyReLU激活函数。
共享卷积权重
如图中间双向箭头连接的Generator反卷积核和Reverse卷积核,对应的一组卷积核和反卷积核共享同一份卷积权重值。
RPA
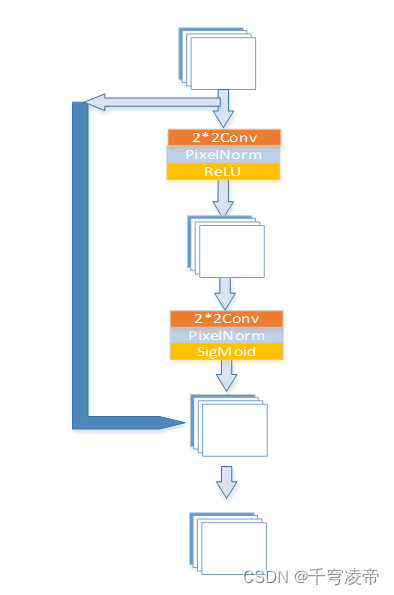
RPA作为第一重注意力机制,给输入特征的每块区域像素分配一个权重,使得神经网络对于图像特征明显的区域更加关注。输入特征(B,C,H,W)先经过一个Conv-PixelNorm-LReLU进行通道压缩为(B,C*r,H/2,W/2),r<1;再经过一个Conv-PixelNorm还原成(B,C,H/4,W/4),通过SigMoid函数生成每个像素值的权重,最后使用双线性插值还原成(B,C,H,W),和原输入特征一对一相乘相乘。

ADO
基于注意力的Dropout方法,不同于一般Dropout使用的随机方式,利用注意力保留更重要的特征信息,使得神经网络的性能和泛化性更好。
对输入特征经过两个像素归一化+卷积+LeakyReLU/SigMiod,生成和原特征形同尺寸的注意力矩阵,根据注意力矩阵的值,将注意力小于阈值的原特征矩阵对应位置神经元置零。
损失函数
本专利生成器输出图像,反向器输出数据分布,因此使用Wasserstein distance+梯度惩罚计算数据分布损失,使用均方误差计算图像像素损失。
Wasserstein距离度量两个概率分布之间的距离,定义如下:
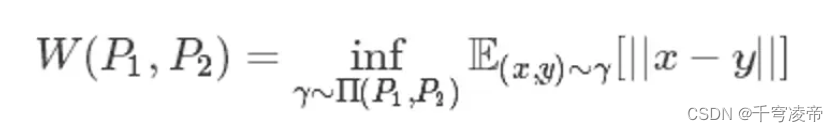
∏(P1,P2)是 P1和P2分布组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布 ,可以从中采样(x,y)∼ 得到一个样本x和y,并计算出这对样本的距离||x−y||,所以可以计算该联合分布 下,样本对距离的期望值E(x,y)∼ [||x−y||]。 在所有可能的联合分布中能够对这个期望值取到的下界就是Wasserstein距离。直观上可以把E(x,y)∼ [||x−y||]理解为在 这个路径规划下把土堆 挪到土堆 所需要的消耗。而Wasserstein距离就是在最优路径规划下的最小消耗。所以Wesserstein距离又叫Earth-Mover距离。Wessertein距离相比KL散度和JS散度的优势在于:即使两个分布的支撑集没有重叠或者重叠非常少,仍然能反映两个分布的远近。而JS散度在此情况下是常量,KL散度可能无意义。
均方误差(MSE)是最常用的回归损失函数。MSE是目标变量与预测值之间距离平方之和,本专利使用经过反向器恢复后的特征张量和采样得到的Z对应元素进行MSE,得到误差值,再进行反向梯度计算,更新神经网络的权重值。
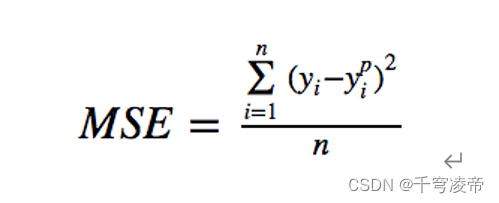
本专利SAN神经网络包括一个生成器和一个反向器,对应4个损失:
1. 生成器的输出图片在反向器上的输出特征R(G(Z))和采样数据的损失LGD=WD(R(G(Z)),Z);
2. 生成器的输出图片和反向器的真实输入图片X的损失LGI=MSE(G(Z),X);
3. 生成器的输出图片在反向器上的输出特征R(G(Z))和采样数据的损失LRZ=WD(R(G(Z)),Z);
4. 真实图片X在反向器上的输出特征R(X)和采样数据的损失LRX=WD(R(X),Z);
生成器的损失为LGD+ LGI;
反向器的损失为LRZ+LRX;
LRZ和LGD是一样的;
本专利使用L2正则化技术用于减小神经网络过拟合效应,使用LeakyReLU激活函数和kaiming权重初始化方法。
SAN训练和生成过程
整个神经网络训练分为正向推理和反向传播:
1.正向推理:随机采样数据Z,生成器G产生假图像G(Z);将G(Z)以及真实图像X分别输入反向器R,得到R(G(Z))和R(X);
2.计算得到损失函数LGI、LGD、LRZ和LRX;
3.反向传播:优化器算法,将损失值反向传播到神经网络的各个阈值参数上,使用LGI、LGD更新生成器权重值,使用LRZ和LRX更新反向器权重值;
4.共享关键卷积权重,将Generator和Reverse里各个对应的卷积和反卷积的权重值取加权平均作为新的权重值;
5.反复进行1-4,不停更新神经网络阈值参数,使得正向推理得到的生成器和判别器的损失值达到要求,停止训练;
训练完成后,生成时只使用生成器G从正态分布中随机采样的数据,自动生成新图像。
















 5069
5069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











