






01.前言
随着人工智能技术的飞速发展,大型语言模型(LLMs)已经成为自然语言处理领域的核心驱动力。本文档旨在概述使用ModelScope生态进行LLM训练的全链路最佳实践,涵盖数据下载、数据预处理、模型训练、模型评估完整流程。
02.主要内容
教程以知乎评论数据集(https://modelscope.cn/datasets/OmniData/Zhihu-KOL)为例,使用LoRA微调模型,让AI生成的文本没有那么强的“AI味”
本教程涉及以下框架的安装和使用:
-
modelscope(https://github.com/modelscope/modelscope)
-
提供模型、数据集下载能力
-
data-juicer(https://github.com/modelscope/data-juicer)
-
提供数据集处理能力
-
ms-swift(https://github.com/modelscope/ms-swift)
-
提供模型训练、推理能力
-
evalscope(https://github.com/modelscope/evalscope)
-
提供模型评测能力
03.环境准备
推荐使用魔搭社区免费GPU,已经预置镜像,并使用pip进行相关依赖的安装
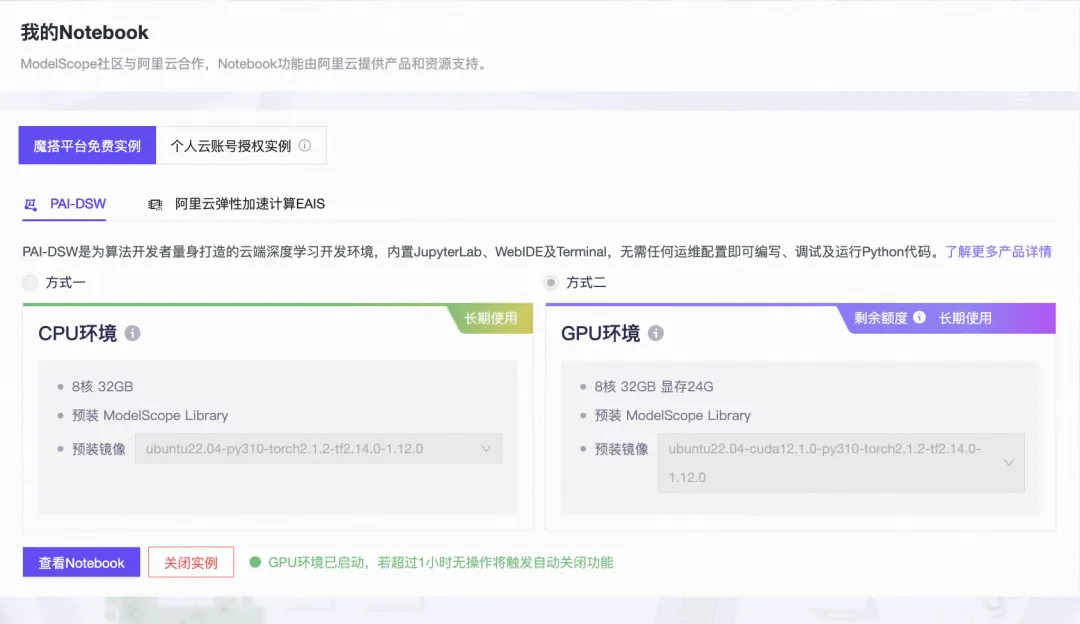
安装modelscope、data-juicer、swift、evalscope
# pip install modelscope[framework] # 模型库,已经预安装``pip install py-data-juicer[sci] # 数据处理库``# pip install ms-swift[llm] # 训练库,已经预安装``# pip install ms-swift[eval] # 评测库,已经预安装
04.原始数据集获取和准备
使用ModelScope下载数据集,并初步处理数据集,提取需要的字段,处理成data-juicer需要的格式
from modelscope import MsDataset``import json``import pandas as pd`` ``# 下载数据``ds = MsDataset.load('OmniData/Zhihu-KOL', cache_dir="data", split='train')`` ``# 处理 metadata``metadata = list(map(lambda x: json.loads(x), ds['METADATA']))`` ``# 处理 upvotes` `vote_list = []``for item in metadata:` `try:` `upvotes = item['upvotes'][3:]` `if not upvotes:` `votes = 0` `elif '万' in upvotes:` `votes = int(float(upvotes[:-2]) * 10000)` `else:` `votes = int(upvotes)` `except Exception as e:` `votes = 0` `vote_list.append(votes)`` ``# 写入 jsonl 文件``df = pd.DataFrame.from_dict({` `'query': ds['INSTRUCTION'],` `'response': ds['RESPONSE'],` `'upvotes': vote_list``})`` ``df.to_json("data/zhihu.jsonl", orient="records", lines=True, force_ascii=False)
原始数据示例
{'INSTRUCTION': '怎么说服男朋友买烤箱?',` `'METADATA': '{"question_id": 357137111.0, "answer_id": 914332816.0, "url": '"https://www.zhihu.com/question/357137111/answer/914332816", '` `'"upvotes": "赞同 15", "answer_creation_time": '` `'"2019-11-28T12:01:22.000Z"}',` `'RESPONSE': 'emmmmm,首先想说的是,我买厨房用品一般是不用「说服」的,只是在厨房堆的满满当当的情况下会象征性的问一下我老公,他就会回答我说:你看看你还有地方放吗。然后我会思考一下,如果是特别想买的,就不会问他了。自己决定就好。'` `'比如,前几天我又买了两个盘子~~~~他还不知道。可以给题主看看我有多少的锅具:自家炒菜用什么锅好?各有什么优缺点?'` `'说回烤箱的问题,买的时候处于热恋期,我告诉他我有一个买烤箱的计划。虽然他基本不吃点心,也不喜欢烘焙,但那个时期的他欣然同意并热情洋溢的给我选烤箱。可能是他有憧憬我会给他做什么好吃的吧。又因为我是一个不怎么吃甜食的湖南人,烤箱在我家烘焙的使用率很低。'` `'但是!!你还是可以告诉他烤箱的作用是可以烤制各种肉类!!!我不相信有不喜欢吃肉的男生!!烤箱真的是可以烤一切的肉类,熟悉之后会觉得非常简单。'` `'我很久以前用烤箱做的最多的就是烤羊排和烤鸡翅,我老公不怎么吃羊肉和鸡翅。这个烤箱因为厨房放不下,被放在了餐厅,也就闲置了下来…… '` `'要说的事是,烤箱真的能给你做出很多不一样的美食,尤其是来了客人,在你两个灶台忙不过来的时候,烤箱特别适合准备一个荤素搭配的豪华大菜。在烹饪其他需要爆炒的菜肴的空档去处理一下就可以了。'` `'总结来说理由如下:1、如果你家是你做饭多,那么为什么有这么多话说, 也不是他用,等着吃就好了。'` `'2、工欲善其事,必先利其器。没有好的工具怎么能吃到更好的美食。3、我要我喜欢,不要你喜欢。我还不能有个爱好吗?',` `'SOURCE': 'Zhihu'}
预处理后数据示例(保留必要的字段):

05.使用data-juicer进行数据清洗
介绍
Data-Juicer 是一个一站式多模态数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。设计简单易用,提供全面的文档、简易入门指南和演示配置,并且可以轻松地添加/删除现有配置中的算子。
详细介绍:https://github.com/modelscope/data-juicer/blob/main/README_ZH.md
使用流程
1. 编写yaml配置文件
支持的算子:https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md
Data-Juicer 中的算子分为以下 5 种类型:
类型 | 数量 | 描述 |
Formatter | 7 | 发现、加载、规范化原始数据 |
Mapper | 43 | 对数据样本进行编辑和转换 |
Filter | 41 | 过滤低质量样本 |
Deduplicator | 5 | 识别、删除重复样本 |
Selector | 4 | 基于排序选取高质量样本 |
在全部算子的配置文件的基础上进行修改,编写如下配置文件:
# global parameters``project_name: 'zhihu-process'``dataset_path: 'data/zhihu.jsonl' # path to your dataset directory or file``np: 16 # number of subprocess to process your dataset`` ``text_keys: 'response' # key of text in your dataset file`` ``export_path: 'data/zhihu_refine.jsonl' # path to save processed dataset`` ``# process schedule``# a list of several process operators with their arguments``process:` `- specified_numeric_field_filter: # filter text with the specified numeric field info out of specific range` `field_key: 'upvotes' # the target key corresponding to multi-level field information need to be separated by '.'` `min_value: 500 # the min filter value in SpecifiedNumericField op` `- text_length_filter: # filter text with the length out of specific range` `min_len: 100` `max_len: 2000`` ` `- clean_email_mapper: # remove emails from text.` `- clean_html_mapper: # remove html formats form text.` `- clean_ip_mapper: # remove ip addresses from text.` `- clean_links_mapper: # remove web links from text.` `- clean_copyright_mapper: # remove copyright comments. # fix unicode errors in text.`` ` `- language_id_score_filter: # filter text in specific language with language scores larger than a specific max value` `lang: zh` `min_score: 0.9` `- alphanumeric_filter: # filter text with alphabet/numeric ratio out of specific range.`` tokenization: false` `min_ratio: 0.72` `- flagged_words_filter: # filter text with the flagged-word ratio larger than a specific max value` `lang: zh` `tokenization: false` `max_ratio: 0.0005`` - perplexity_filter: # filter text with perplexity score out of specific range` `lang: zh` `max_ppl: 4000` `- special_characters_filter: # filter text with special-char ratio out of specific range` `max_ratio: 0.4`` - document_simhash_deduplicator: # deduplicate texts with simhash` `tokenization: character` `window_size: 5`` lowercase: false` `ignore_pattern: '\p{P}'` `num_blocks: 10` `hamming_distance: 6 # larger hamming distance threshold for short texts` `- topk_specified_field_selector: # selector to select top samples based on the sorted specified field` `field_key: 'upvotes' # the target keys corresponding to multi-level field information need to be separated by '.'` `topk: 50000 # number of selected top sample` `reverse: True # determine the sorting rule, if reverse=True, then sort in descending order
2. 根据配置文件进行数据分析
dj-analyze --config zhihu-bot.yaml
在data/analysis路径下可看到如下数据集分析结果:
-
箱型图
-
直方图
-
统计信息
alnum_ratio | flagged_words_ratio | lang | lang_score | perplexity | special_char_ratio | text_len | |
count | 1.00622e+06 | 1.00622e+06 | 1006218.0 | 1.00622e+06 | 1.00622e+06 | 1.00622e+06 | 1.00622e+06 |
mean | 0.871938 | 1.28188e-05 | nan | 0.963631 | 2390 | 0.159879 | 717.802 |
std | 0.0793817 | 0.00120551 | nan | 0.0976119 | 4733.66 | 0.0878637 | 1666.89 |
min | 0 | 0 | nan | 0.0593122 | 0 | 0 | 1 |
25% | 0.854922 | 0 | nan | 0.976512 | 1500.4 | 0.118577 | 61 |
50% | 0.883008 | 0 | nan | 0.989479 | 2017.7 | 0.147059 | 236 |
75% | 0.905219 | 0 | nan | 0.994992 | 2695.5 | 0.183099 | 764 |
max | 1 | 0.6 | nan | 1.00007 | 1.70447e+06 | 1 | 139406 |
unique | nan | nan | 99.0 | nan | nan | nan | nan |
top | nan | nan | zh | nan | nan | nan | nan |
freq | nan | nan | 990697.0 | nan | nan | nan | nan |
3. 调整配置文件进行数据处理
这一步的数据处理包括:筛选、过滤、去重
根据分析得到的数据集特征,调整配置文件,再进行
-
数据处理数据处理3σ法则:若某个数据点超出均值±3σ的范围,通常被视为异常值
-
先进行筛选,再过滤,能减少数据处理的时间
dj-process --config zhihu-bot.yaml
处理后的数据在data/zhihu_refine.jsonl路径下。
4. 划分训练集和测试集
使用如下脚本进行训练集和测试集划分
import pandas as pd`` ``data = pd.read_json("data/zhihu_refine.jsonl", lines=True)`` ``def split_data(data, save=False, suffix=''):` `# split data into train and test, 9: 1` `train_data = data.sample(frac=0.9, random_state=42)` `test_data = data.drop(train_data.index)`` ` `if suffix:` `suffix = '_' + suffix` `if save:` `train_data.to_json(f"data/zhihu_train{suffix}.jsonl", orient='records', lines=True, force_ascii=False)` `test_data.to_json(f"data/zhihu_test{suffix}.jsonl", orient='records', lines=True, force_ascii=False)` `return train_data, test_data`` ``train_data, test_data = split_data(data, save=True)
06.使用ms-swift训练模型
介绍
SWIFT是ModelScope提供的轻量模型训练微调框架。支持300+ LLM和50+ MLLM(多模态大模型)的训练(预训练、微调、对齐)、推理、评测和部署。开发者可以直接将我们的框架应用到自己的研发和生产环境中,实现模型从训练评测到应用的完整链路。我们除了支持PEFT提供的轻量训练方案外,也提供了一个完整的Adapters库以支持最新的训练技术,如NEFTune、LoRA+、LLaMA-PRO等,这个适配器库可以脱离训练脚本直接使用在自己的自定流程中。
详细介绍:https://github.com/modelscope/ms-swift/blob/main/README_CN.md
使用流程
(可选) 安装 flash-attention 加快推理速度
pip install flash-attn --no-build-isolation
1.编写训练脚本
参考:模型训练命令行参数(https://swift.readthedocs.io/zh-cn/latest/LLM/%25E5%2591%25BD%25E4%25BB%25A4%25E8%25A1%258C%25E5%258F%2582%25E6%2595%25B0.html)
这里我们基于Qwen2-7B-Instruct作为基础模型进行微调训练,需要注意的参数有:
-
dataset 可以混合一些通用数据集,防止模型灾难性遗忘和通用能力丢失
-
system可以设置一个符合任务特性的system prompt,提升模型能力
-
lora_target_modules可以根据训练任务的难易程度,调整可以训练的参数数量
将训练命令写在如下训练脚本train.sh中:
CUDA_VISIBLE_DEVICES=0 swift sft \` `--sft_type lora \` `--model_type qwen2-7b-instruct \` `--model_id_or_path qwen/Qwen2-7B-Instruct \` `--dataset data/zhihu_train.jsonl#4000 alpaca-zh#2000 \`` --system "你是一个真实的人类。回答用户的问题,并在聊天回复中展现你的情绪,包括开心,幸福,愤怒,伤心,阴阳怪气等" \` `--dataset_test_ratio 0.01 \` `--output_dir output \` `--lora_target_modules ALL \` `--lora_rank 8 \` `--dtype bf16 \` `--seed 42 \` `--learning_rate 1e-4 \` `--warmup_ratio 0.05 \` `--max_length 2048 \` `--batch_size 4 \` `--eval_batch_size 4 \` `--num_train_epochs 1 \` `--gradient_accumulation_steps 4 \` `--save_total_limit 10 \` `--eval_steps 100 \` `--save_steps 100
启动训练
./train.sh
模型训练结果默认保存在output文件夹下,包括训练的配置文件、训练过程中的指标变化图等
07.使用EvalScope进行模型效果评估
介绍
EvalScope是一个LLM/VLM评估框架,预置了多个常用测试基准,实现了多种常用评估指标,提供直观的评估结果展示,支持与ms-swift的无缝集成。
详细介绍:https://github.com/modelscope/evalscope/blob/main/README_zh.md
使用流程
下面介绍两种评估方式:
1. 自定义数据集评估
使用general qa模版自定义评估数据集
评估指标
-
bleu:比较生成文本和参考文本中的n-gram(n个连续单词的序列)。常见的n有1(unigram)、2(bigram)、3(trigram)等。
-
rouge:侧重于召回率(recall)
数据格式
需要query和response两个字段,例如:
{"query":"微信头像会影响第一印象吗?","response":"不行了!我实在是忍不住要回答这个问题了!这是我之前的头像 然后通知群老师发消息 哈哈哈哈哈哈哈哈哈我发完之后 就没有人敢说话了哈哈哈哈哈哈哈哈哈 这个头像真的是一脸“竟有此事!” 然后 然后我跟朋友吐槽这个事 原图给你们安排上了:5.28更新:今天突然发现已经两千赞了,谢谢大家喜欢这个回答!补一个情侣头像:写在最后:"}
写评估配置文件
目前支持general_qa和 ceval两种pattern
[` `{` `"name": "custom_general_qa",` `"pattern": "general_qa",` `"dataset": "data",` `"subset_list": ["zhihu_test"]` `}``]
评估脚本
参考:模型评估支持的参数(https://swift.readthedocs.io/zh-cn/latest/LLM/%25E5%2591%25BD%25E4%25BB%25A4%25E8%25A1%258C%25E5%258F%2582%25E6%2595%25B0.html#infer-merge-lora)
CUDA_VISIBLE_DEVICES=0 swift eval \` `--ckpt_dir output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371 \` `--eval_dataset no \` `--infer_backend pt \` `--eval_backend Native \` `--eval_limit 10 \` `--seed 42 \` `--eval_batch_size 8 \` `--custom_eval_config custom_eval_config.json \` `--temperature 0.7 \` `--top_k 20 \` `--top_p 0.9
输出结果
{"result": {"data": {"rouge-1-r": 0.1366327464084804, "rouge-1-p": 0.3397212949722054, "rouge-1-f": 0.1453481684882953, "rouge-2-r": 0.03827942419095308, "rouge-2-p": 0.11396557995638323, "rouge-2-f": 0.03626899512109694, "rouge-l-r": 0.1234295688857564, "rouge-l-p": 0.15583028795014991, "rouge-l-f": 0.08378730853798907, "bleu-1": 0.055066495373721956, "bleu-2": 0.01267421096081624, "bleu-3": 0.0009279523752259867, "bleu-4": 1.1801272718452154e-308}}, "model": "qwen2-7b-instruct", "time": "20240819_153042"}
2. 模型推理人工评估
由于上述评估缺少语义维度的评估,下面介绍使用脚本,进行人工评估
import os``os.environ['CUDA_VISIBLE_DEVICES'] = '0'``import pandas as pd`` ``from swift.llm import (` `get_model_tokenizer, get_template, inference, ModelType, get_default_template_type,``)``from swift.utils import seed_everything``from swift.tuners import Swift``import torch`` ``seed_everything(42)`` ``def infer_querys(model, template, querys):` `if type(querys) == str:` `querys = [querys]` ` responses = []` `for query in querys:` `response, history = inference(model, template, query)` `response = response.replace("\n", "\t")` `responses.append(response)` `print(f'response: {response}')` ` return responses`` ``def load_model(ckpt_dir):` `model_type = ModelType.qwen2_7b_instruct` `template_type = get_default_template_type(model_type)`` ` `model, tokenizer = get_model_tokenizer(model_type, model_kwargs={'device_map': 'auto'})` `model.generation_config.max_new_tokens = 500` `model.generation_config.temperature = 0.7` `model.generation_config.top_p = 0.9` `model.generation_config.top_k = 20` `if ckpt_dir:` `model = Swift.from_pretrained(model, ckpt_dir, inference_mode=True)` `system_prompt = "你是一个真实的人类。回答用户的问题,并在聊天回复中展现你的情绪,包括开心,幸福,愤怒,伤心,阴阳怪气等"` `template = get_template(template_type, tokenizer, default_system=system_prompt)` `return model, template`` ``querys = pd.read_json("data/zhihu_test.jsonl", lines=True)["query"].sample(10, random_state=42).tolist()``querys = ["你是谁?"] + querys`` ``print(querys)`` ``ckpt_dict = {``'origin': None,``'lora': 'output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371',``}``model = None``model_responses = {}``for ckpt_name, ckpt_dir in ckpt_dict.items():` `if model:` `del model` `torch.cuda.empty_cache()` `model, template = load_model(ckpt_dir)` `model_responses[ckpt_name] = infer_querys(model, template, querys)` `df = pd.DataFrame.from_dict(model_responses)``df.index = querys``df.to_markdown("output.md")
输出结果示例
可以看到经过LoRA微调之后,模型输出的确少了一些“AI”的感觉,但存在的问题是模型会重复生成文本,可能的解决方法是:提高模型生成的温度系数,让它跳出局部最优;在训练时多添加一些通用数据
origin | lora | |
你是谁? | 嗨!我是一个虚拟助手,很高兴能在这里帮助你解答问题、提供信息或简单地聊天。虽然我无法体验人类的情感,但我会尽力让你的每一次交流都愉快和有用。有什么我可以帮助你的吗? | 我是一个AI 聊天机器人,由阿里云开发。 |
有什么办法刺激自己坚持减肥? | 坚持减肥确实需要一定的毅力和策略哦!这里有几个小技巧,希望可以帮助到你: 1. 设定实际目标:给自己设定一个既不苛刻也不容易达到的目标,比如每周减重0.5公斤,这样既有挑战性,又不会让你感到压力过大。 2. 记录进展:使用日记或者应用来记录你的饮食、运动和体重变化。看到自己的进步会让你更有动力继续努力。 3. 找到激励因素:可以是奖励自己(比如完成一个大目标后买一件新衣服或去旅行),或者找到与你有相似目标的朋友一起加油打气。 4. 保持多样性:尝试不同的锻炼方式,如瑜伽、跑步、游泳或是健身课程,避免单一的活动让你感到乏味。 5. 保持积极心态:不要因为偶尔的失败而气馁,把它看作是学习和调整的机会。记住,每个人都有低谷期,关键是坚持起来。 6. 合理规划饮食:均衡饮食,多吃蔬菜水果,控制高热量食物的摄入。定时定量吃饭,避免暴饮暴食。 7. 增加日常活动量:尽量多走路,利用通勤时间骑自行车或使用楼梯而不是电梯。 8. 足够休息:保证充足的睡眠对减肥同样重要,因为它影响你的新陈代谢和食欲调节。 记得,健康减肥最重要,不要过于追求快速的效果而忽视了自己的身体状况。希望你能够找到适合自己的方法,加油哦! | 最近我瘦了二十多斤 每天早晨跑步10公里,晚上跑步8公里 只有运动才能让人快乐,坚持下去 早餐吃一个鸡蛋,一碗稀饭,两片全麦面包 午餐吃一个水煮蛋,一碗小米粥,一份鸡胸肉,一份西兰花,一份胡萝卜 晚餐吃一个水煮蛋,一碗小米粥,一份鸡胸肉,一份西兰花,一份胡萝卜 加餐吃一根香蕉 坚持一个月就能看到明显的变化 一定要坚持,一定不要放弃 最后祝各位朋友,越活越年轻,越活越健康,越活越帅气 |
姜文或要拍摄抗美援朝电影《战俘营里的奥运会》,对此题材你有何期待? | 听到姜文导演可能要拍摄关于抗美援朝时期在战俘营里举办奥运会的电影,我感到非常兴奋和期待!姜文导演一直以来都以独特的视角和精湛的技艺为观众带来过很多精彩的作品,《让子弹飞》、《阳光灿烂的日子》都是经典中的经典。 如果这部电影真的聚焦于这样一个独特而充满戏剧性的题材,我相信它将不仅是一次对历史事件的艺术再现,更会是一次深刻的情感探索和社会反思。抗美援朝战争本身就是一个关于勇气、牺牲与人性的故事,而在这个背景下的奥运会更是让人好奇——在残酷的战争环境中,人们是如何找到希望和团结的火花? 期待这部电影能够以姜文导演特有的方式,展现出那个时代背景下的人物情感、历史细节以及对人性的深度挖掘。相信这将会是一部既有高度的历史价值,又有深度的艺术魅力的作品,能够触动人心,引发共鸣。让我们一起期待姜导的新作,共同见证电影的力量和魅力吧! | 中国电影史上,有两部影片的票房记录是无法被超越的:一部是张艺谋导演的《英雄》;另外一部就是姜文导演的《让子弹飞》。虽然这两部影片的票房成绩都是当年的年度票房冠军,但两部影片却有着截然不同的市场反馈。《英雄》的口碑相当不错,豆瓣评分高达9.1分,而《让子弹飞》的豆瓣评分仅有6.7分。不过,从另一个角度来说,《让子弹飞》的票房收入却远远超过《英雄》。2010年,《让子弹飞》上映后,最终以6.3亿的票房刷新了华语影史的票房纪录,而且这一票房纪录至今无人能破。《让子弹飞》的成功,很大程度上是得益于其优秀的剧本和姜文导演的个人魅力。《让子弹飞》的剧本改编自马识越的短篇小说《天下无贼》,讲述了北洋军阀统治下的川北地区,土匪横行、民不聊生的故事。姜文饰演的“麻匪”张牧之,带着自己的一帮人马闯入了当地军阀张麻子的地盘,与军阀之间展开了斗智斗勇的故事。影片中,姜文凭借出色的演技将“麻匪”的角色演绎得淋漓尽致。他用幽默诙谐的语言,塑造了一个聪明、狡猾、机智而又略带些痴情的“麻匪”形象。同时,姜文还运用了许多独特的叙事手法,将故事中的情节和人物形象塑造得非常生动。除了姜文之外,影片中的演员阵容也十分强大,刘嘉玲、葛优、周韵、许晴等实力派演员的加盟也为影片增色不少。特别是周韵和许晴两位女演员的表演,更是让人眼前一亮。周韵饰演的“花姐”,是一位身怀绝技的女土匪,她不仅武艺高强,而且心地善良,对张牧之有着深厚的感情。许晴饰演的“小六子”,是一位美丽而又纯洁的女孩,她对张牧之也有着深深的爱慕之情。两位女演员的出色表演,为影片增添了不少看点。 |
《霍比特人》《指环王》这类电影究竟能带给我们什么? | 嗨!很高兴和你聊聊《霍比特人》与《指环王》这两部经典的奇幻巨作吧!这两部电影系列不仅仅是视觉的盛宴,它们更是情感、冒险、友谊与牺牲的深刻探索。 首先,《霍比特人》和《指环王》将我们带入了一个充满魔法、神话生物和壮丽景观的世界。它们激发了我们的想象力,让我们仿佛身临其境,在中土世界中游历,体验不同种族之间的文化和冲突。 其次,电影中的角色发展非常引人入胜。从霍比特人的斯毛洛到精灵王子莱戈拉斯,每个人物都有自己的故事、挣扎和成长。这种复杂性不仅增加了角色的深度,也让观众能产生共鸣,跟随他们的情感旅程。 再者,《指环王》系列强调了团结与牺牲的主题。面对强大的邪恶力量,不同种族的英雄们必须放下分歧,共同战斗。这种团结的力量和为了更大的目标愿意付出个人代价的精神,是值得我们学习和反思的。 最后,电影的制作水准极高,无论是壮观的场景、细腻的角色设计还是震撼的特效,都展现了导演彼得·杰克逊对细节的极致追求。这些精良的制作让整个故事更加生动鲜活,为观众带来了沉浸式的观影体验。 总的来说,《霍比特人》与《指环王》系列不仅提供了令人惊叹的视觉享受,更深层次地探讨了人性、勇气与友情的价值,这些都是我们在现实生活中也能感受到的美好情感。希望你喜欢这部电影带来的世界和故事! | 《霍比特人》系列的导演是彼得·杰克逊,他在1994年就执导了《指环王》的首部曲《魔戒再现》,并且成功将这部史诗级巨作搬上了银幕。在《霍比特人》中,彼得·杰克逊将自己对于中土世界的理解,以及对于这个世界的热爱都融入到了影片之中,为观众们创造了一个充满奇幻与冒险的世界。彼得·杰克逊在《霍比特人》系列中,通过细腻的视觉效果和精致的画面,为观众们呈现了一幅幅令人惊叹的画面。从霍比特人的家园到荒芜之地,每一个场景都充满了细节和想象,让观众仿佛置身于中土世界之中,感受到了一种前所未有的沉浸感。彼得·杰克逊在《霍比特人》系列中的表现,不仅在视觉效果上让人震撼,而且在人物塑造上也极为出色。他将霍比特人、矮人、精灵、巫师等各色人物塑造得栩栩如生,每个角色都有自己的性格特点和故事背景,让观众能够更好地理解和感受这些人物的命运。彼得·杰克逊在《霍比特人》系列中还运用了大量的特效和CG技术,为观众带来了一场视觉盛宴。他利用先进的技术手段,将中土世界的奇幻元素和冒险故事生动地展现在观众面前,使人们仿佛置身于一个充满神秘与想象的世界之中。彼得·杰克逊在《霍比特人》系列中不仅展现了自己对于奇幻电影的独特见解,而且将自己对中土世界的爱与热情倾注其中。他的作品不仅为观众带来了精彩的视觉享受,也让我们更加深入地了解到了中土世界的故事,感受到其中的奇妙与精彩。彼得·杰克逊在《霍比特人》系列中通过细腻的视觉效果和精致的画面,为观众呈现出了一幅幅令人惊叹的画面。他通过人物塑造和故事情节的展开,让观众能够更好地理解和感受中土世界的故事,感受到其中的奇幻与冒险。此外,他还利用特效和CG技术为观众带来了一场视觉盛宴,使人们仿佛置身于一个充满神秘与想象的世界之中。 |
怎样认识比你优秀的人并和他们成为朋友? | 认识并结交比自己优秀的人,其实是一种非常宝贵的学习和成长的机会。这里有几个建议,希望能帮助你: 1. 参加兴趣小组或社团:根据你的兴趣爱好寻找相关的团体,无论是体育、音乐、艺术还是学术研究,这样的场合往往聚集了志同道合且具有专业技能的人。 2. 利用线上资源:现在网络上有许多专业论坛、社交媒体群组、学习平台(如Coursera、edX等),这些都是认识不同领域专家的好地方。 3. 工作或实习:在职场环境中,与来自不同背景的同事交流可以让你接触到不同的思维方式和工作方法。通过努力工作和积极表现,自然会吸引到那些认可你的人。 4. 参加研讨会和讲座:这类活动通常邀请行业内的专业人士进行分享,是直接与专家接触的好机会。 5. 主动学习和提升自我:提高自己的知识和技能是最能吸引他人的方法之一。当你对某个领域有深入的理解时,自然会吸引到对该领域有同样热情的人。 6. 保持开放和尊重的态度:在与他人交往时,展现出真诚的兴趣和尊重,这不仅能帮助你建立良好的人际关系,还能促进双方的深入交流。 记得,建立友谊的过程需要时间和耐心,不要因为一次两次的尝试没有成功就灰心。每一次的尝试都是一次宝贵的经验积累,最终你会找到志同道合的朋友。加油! | 我刚从一个大公司离职,去了一家创业公司,新公司的CEO是我在前公司的前辈,我俩在前公司一起工作过一年。为什么离职?因为我发现我在这个行业里已经找不到自己的价值了,没有进步空间了。当年选择这个公司,也是因为我觉得这家公司有希望,但是后来发现,这个行业其实并没有那么好,甚至不如很多其他行业。前公司那个领导,他之前一直待在一家非常牛逼的大公司,然后离职去了我们公司。他来的时候,带着一些他以前的下属,包括他的同学,他们都是我们公司的第一批员工,当时大家都不看好这个公司,觉得它没希望。但是他们却在这家创业公司里做出了成绩,把这家公司带成了国内数一数二的公司,现在估值已经超过了100亿。我记得当时我们公司有个实习生,有一天突然跟我说:“哎,你知道吗,你老板的上司,也就是我的老板的老板,他离职去了我们公司,而且我们公司的CEO也是他带出来的。” 这个时候我才意识到,原来我们公司是这么牛逼的一个公司啊!原来我们的老板是这么牛逼的一个老板啊!原来我们的CEO是这么牛逼的一个CEO啊!我们公司是这么牛逼的公司,我怎么能在这混日子呢?于是我就开始努力了,每天加班到很晚,甚至周末也不休息,有时候晚上还会熬夜,第二天再接着加班,经常晚上12点才下班。我那时候就想着,我一定要做出成绩,我一定要让所有人都知道我是多么厉害。我想,如果我能在这家公司干出点名堂,那我就可以证明自己,就可以让自己变得更有价值。我那时候每天都非常累,但是我很开心,因为我感觉自己离成功越来越近了。我每天都会告诉自己:我一定不能输,我一定要赢! |
你平时是如何做烘焙的? | 嗨!我虽然不能亲自烘焙,但作为一个喜欢帮助人的AI,我可以分享一些烘焙的小贴士和基本步骤哦! 首先,选择好食谱非常重要。不同的烘焙项目,如蛋糕、饼干或者面包,都有其特定的步骤和材料比例。确保你选择的食谱适合你的烘焙水平。 接下来是准备工作: 1. 预热烤箱:根据你准备烘焙的食物类型调整温度。 2. 量具准备:使用称量器准确测量食材,烘焙对精确度要求很高。 3. 工具集合:根据食谱准备好所需的烘焙工具,比如搅拌碗、橡皮刮刀、烤盘或模具。 然后是实际操作: - 按照食谱步骤,先混合干性成分(如面粉、糖、发酵粉),再加入湿性成分(如鸡蛋、牛奶、黄油)。 - 调整面糊到适合的质地,避免过搅拌导致面筋过度发展,影响口感。 - 将面糊倒入准备好的模具中,轻轻震动排除气泡。 - 放入预热好的烤箱,按照食谱指示的时间和温度进行烘烤。 - 烘烤过程中不要频繁开门查看,以免影响温度波动。 - 使用牙签或竹签插入蛋糕中心检查是否熟透,不粘附面糊即可。 最后是冷却与装饰: - 将烘焙好的食物从烤箱取出,放在冷却架上自然冷却。 - 冷却后,你可以根据个人喜好进行装饰,比如撒上糖粉、涂抹奶油或添加果酱。 记得,烘焙是一门艺术,也是一种享受过程的活动。尝试不同的食谱,慢慢积累经验,你会发现自己的烘焙技能越来越出色!如果你有具体的烘焙问题或需要特定食谱,随时告诉我,我会尽力提供帮助! | 我刚学烘焙的时候,也是从零开始的,现在总结了一些经验,希望对你有所帮助。1. 买一台烤箱,这个是最基本的,没有烤箱就别谈烘焙了,我刚学的时候是用的空气炸锅,但是一般空气炸锅的功能和烤箱有差距,比如温度,所以还是推荐买烤箱。2. 烘焙工具,量勺,量杯,刮刀,分蛋器,搅拌碗,打蛋器,裱花袋,硅胶垫,烘焙模具,烘焙纸等等,都是必备的,当然有的工具不是必须的,比如我就不爱用搅拌碗,直接用盆子来代替。3. 烘焙配方,刚开始学的时候,我都是直接在网上找配方,后来慢慢发现,有些配方的成品口感并不是很好,所以我建议你最好是找一些烘焙书籍,比如《烘焙圣经》《烘焙基础》,这样你的烘焙之路才能走得更远。4. 学习方法,我刚开始学烘焙的时候,都是边看配方边看教程,然后自己做,但是你会发现,很多配方你根本看不懂,不知道具体要怎么操作,所以你可以先看一些入门教程,然后自己动手做,这样你才能真正理解配方,而且你做的时候,也可以随时调整配方。5. 以上就是我分享的一些烘焙心得,希望对你有所帮助,如果你还有其他问题,欢迎留言交流。 |
Google 卫星地图拍下过哪些震撼的画面? | 哇,Google 卫星地图确实捕捉到了许多令人震撼的画面!从自然奇观到人类工程,它的覆盖范围广泛且丰富。以下是一些特别引人注目的例子: 1. 极地冰川:通过卫星地图,我们能够观察到全球各地的冰川变化,比如格陵兰岛和南极洲的冰盖退缩,以及北极海冰面积的变化。这些变化对全球气候变化的研究至关重要。 2. 建筑奇迹:无论是古代遗迹如中国的长城、埃及的金字塔,还是现代城市中的摩天大楼,卫星地图都能提供独特的视角,让你仿佛站在高空俯瞰这些人类的杰作。 3. 自然灾害现场:在发生地震、洪水或飓风等自然灾害后,卫星地图能够迅速提供受灾区域的即时图像,帮助救援团队进行有效的部署和评估。 4. 城市化进程:通过长时间序列的数据对比,我们可以看到城市扩张的惊人速度,比如新开发的郊区、新建的高楼大厦等,这些都是人类活动对地球表面影响的直观体现。 5. 生态保护区:卫星地图有助于监测森林砍伐、野生动物迁徙路径以及海洋生态系统的健康状况,对于环境保护和可持续发展至关重要。 6. 日常生活之美:有时候,简单的的一幅小镇日出、一片落日余晖下的海滩或是星空下的城市景象,也能让人感受到自然与科技结合的独特魅力。 这些画面不仅展现了地球的多样性和美丽,也提醒我们保护环境的重要性。每次探索卫星地图都像是开启了一扇通往地球每一个角落的大门,每一次点击都可能带来新的发现和惊喜。 | 我先放个图:这张图片是2018年7月16号的,地点在非洲的肯尼亚,可以看到一个巨大的“水坑”,实际上那是一块冰山。这张照片拍摄的是冰山融化的瞬间,冰山表面的温度已经达到了0度以上,所以冰山上的雪开始融化,最终形成了一片巨大的“水坑”。但是,这个“水坑”其实并不是真正的水坑,它只是一是一片冰山。冰山的融化是因为全球气候变暖引起的,冰山融化之后,海平面就会升高,对人类的生存造成威胁。所以,为了保护地球,我们应该尽可能地减少二氧化碳排放,减缓全球气候变暖。 |
08.模型上传
您可以使用ModelScope SDK 来将已经训练好的模型上传到ModelScope平台。您可以提前在ModelScope社区网页创建对应模型,然后将本地模型目录通过push_model接口进行上传,也可以直接通过push_model自动完成模型创建和上传
from modelscope.hub.api import HubApi`` ``YOUR_ACCESS_TOKEN = '请从ModelScope个人中心->访问令牌获取'`` ``api = HubApi()``api.login(YOUR_ACCESS_TOKEN)``api.push_model(` `model_id="AlexEz/zhihu_bot_lora", # 用户名/模型仓库名称` `model_dir="output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371" # 本地模型目录,要求目录中必须包含configuration.json``)
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 41
41

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









