






1.HetGCoT-Rec: Heterogeneous Graph-Enhanced Chain-of-Thought LLM Reasoning for Journal Recommendation
Authors: Runsong Jia, Mengjia Wu, Ying Ding, Jie Lu, Yi Zhang Affiliations: University of Technology Sydney, University of Texas at Austin
https://arxiv.org/abs/2501.01203
论文摘要
Academic journal recommendation requires effectively combining structural understanding of scholarly networks with interpretable recommendations. While graph neural networks (GNNs) and large language models (LLMs) excel in their respective domains, current approaches often fail to achieve true integration at the reasoning level. We propose HetGCoT-Rec, a framework that deeply integrates heterogeneous graph transformer with LLMs through chain-of-thought reasoning. Our framework features two key technical innovations: (1) a structure-aware mechanism that transforms heterogeneous graph neural network learned subgraph information into natural language contexts, utilizing predefined metapaths to capture academic relationships, and (2) a multi-step reasoning strategy that systematically embeds graph-derived contexts into the LLM’s stage-wise reasoning process. Experiments on a dataset collected from OpenAlex demonstrate that our approach significantly outperforms baseline methods, achieving 96.48% Hit rate and 92.21% H@1 accuracy. Furthermore, we validate the framework’s adaptability across different LLM architectures, showing consistent improvements in both recommendation accuracy and explanation quality. Our work demonstrates an effective approach for combining graph-structured reasoning with language models for interpretable academic venue recommendations.
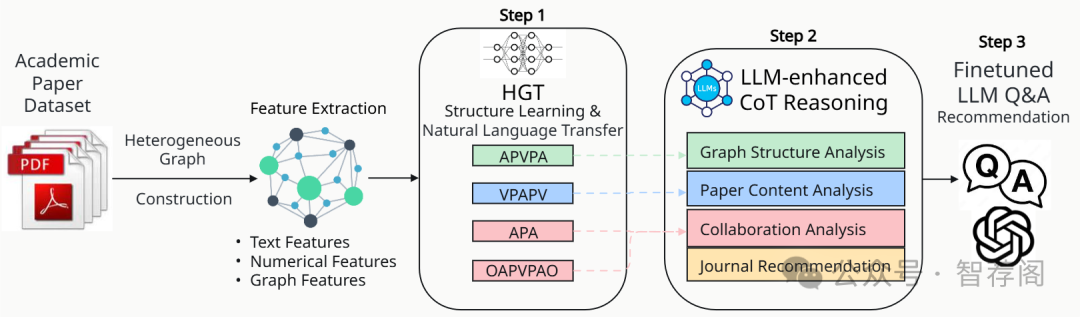
论文简评:这篇关于学术期刊推荐的文章是一个创新性的尝试,它利用了异构图增强的链式推理方法(HetGCoT-Rec)与大型语言模型(LLMs)来解决学术期刊推荐的问题。该框架通过提出结构感知机制和多步推理策略,将基于图的语义信息转换为自然语言,从而显著提高了推荐性能。此外,研究还展示了在OpenAlex数据集上的强大实证结果,并且提出了双通道和四步推理过程作为一种有组织的方法,用于整合图表来源和语义信息。整体而言,这篇文章展现了在学术期刊推荐领域的创新性和实用性。
2.Efficient and Responsible Adaptation of Large Language Models for Robust and Equitable Top-k Recommendations
Authors: Kirandeep Kaur, Manya Chadha, Vinayak Gupta, Chirag Shah Affiliations: University of Washington,
https://arxiv.org/abs/2501.04762
论文摘要
Conventional recommendation systems (RSs) are typically optimized to enhance performance metrics uniformly across all training samples, inadvertently overlooking the needs of diverse user populations. The performance disparity among various populations can harm the model’s robustness to sub-populations due to varying user properties. While large language models (LLMs) show promise in enhancing RS performance, their practical applicability is hindered by high costs, inference latency, and degraded performance on long user queries. To address these challenges, we propose a hybrid task allocation framework designed to promote social good by equitably serving all user groups. By adopting a two-phase approach, we promote a strategic assignment of tasks for efficient and responsible adaptation of LLMs. Our strategy works by first identifying the weak and inactive users that receive suboptimal ranking performance by RSs. Next, we use an in-context learning approach for such users, wherein each user interaction history is contextualized as a distinct ranking task. We evaluate our hybrid framework by incorporating eight different recommendation algorithms and three different LLMs—both open and close-sourced. Our results on three real-world datasets show a significant reduction in weak users and improved robustness to subpopulations without disproportionately escalating costs.
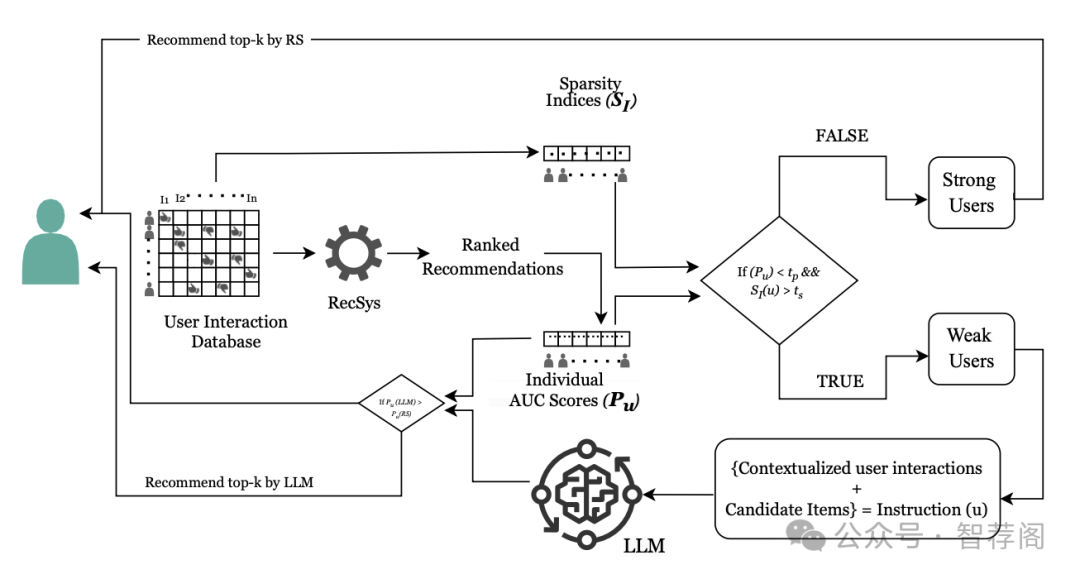
论文简评:该论文旨在探讨一种结合传统推荐系统与大型语言模型(LLM)的技术框架,以增强对弱用户稀疏交互历史的推荐质量。论文提出了一种两阶段策略,旨在识别弱用户,并利用LLMs强化其偏好语境,从而提高推荐系统的鲁棒性和公平性。
论文的关键点在于:
-
提出了一个解决推荐系统性能差异问题的方法,特别关注未受重视的弱用户群体。
-
将LLMs整合到推荐流程中是一种新颖且具有潜力的创新技术,有望显著提升推荐效果。
-
实验结果表明在处理用户稀疏性和公平性方面取得积极改进。
综上所述,这篇论文为深入探讨如何通过引入LLMs优化推荐系统提供了方法论基础,对于改善推荐系统的整体表现具有重要的理论价值和实践意义。
3.Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Authors: Weizhi Zhang, Yuanchen Bei, Liangwei Yang, Henry Peng Zou, Peilin Zhou, Aiwei Liu, Yinghui Li, Hao Chen, Jianling Wang, Yu Wang, Feiran Huang, Sheng Zhou, Jiajun Bu, Allen Lin, James Caverlee, Fakhri Karray, Irwin King, Philip S. Yu Affiliations: University of Illinois Chicago, Zhejiang University, HongKongUniversity of Science and Technology (Guangzhou), TsinghuaUniversity, TheHongKongPolytechnic University, Google Deepmind, Netflix
https://arxiv.org/abs/2501.01945
论文摘要
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both there search and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
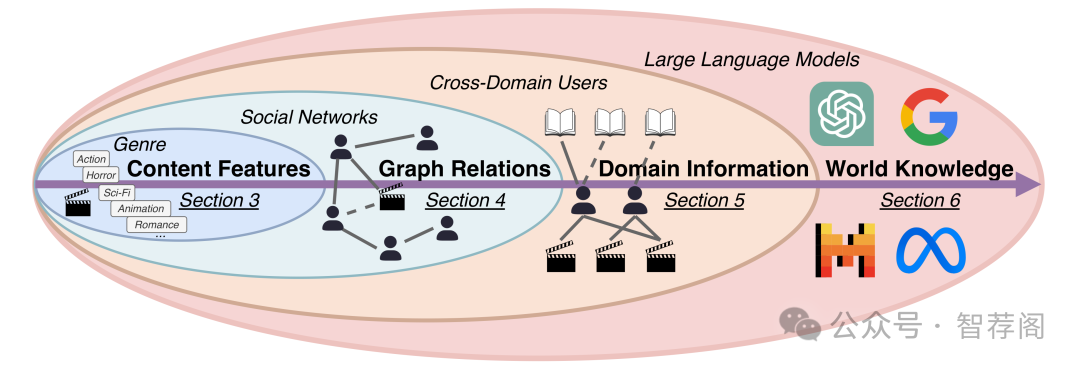
论文简评:在这篇论文中,作者对冷启动推荐系统进行了全面的综述,并着重于大型语言模型(LLMs)与现有方法的集成。该研究将现有方法分为四个知识领域:内容特征、图关系、域信息以及来自LLM的世界知识。通过这些分类,作者旨在强调冷启动推荐中的机会和挑战,并为未来的研究提供一条路径。
论文的关键在于其对冷启动问题的关注以及对解决方案的有效性评估。通过对现有方法的深入分析,作者揭示了如何利用LLMs提升冷启动推荐的效果。此外,这篇论文还提供对未来研究方向的一些建议,表明作者对冷启动推荐领域的持续关注和探索。
总体来说,这篇论文不仅提供了关于冷启动推荐系统的全面概述,而且还提出了一个有价值的框架来解决这一问题。它不仅展示当前技术的进步,而且也为未来的研究指明了方向。因此,这篇论文是值得阅读和学习的重要文献。
4.The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Authors: Huixue Zhou, Hengrui Gu, Xi Liu, Kaixiong Zhou, Mingfu Liang, Yongkang Xiao, Srinivas Govindan, Piyush Chawla, Jiyan Yang, Xiangfei Meng, Huayu Li, Buyun Zhang, Liang Luo, Wen-Yen Chen, Yiping Han, Bo Long, Rui Zhang, Tianlong Chen Affiliations: Meta Platforms, University of Minnesota, NCSU, UNC at Chapel Hill
https://arxiv.org/abs/2501.02173
论文摘要
The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
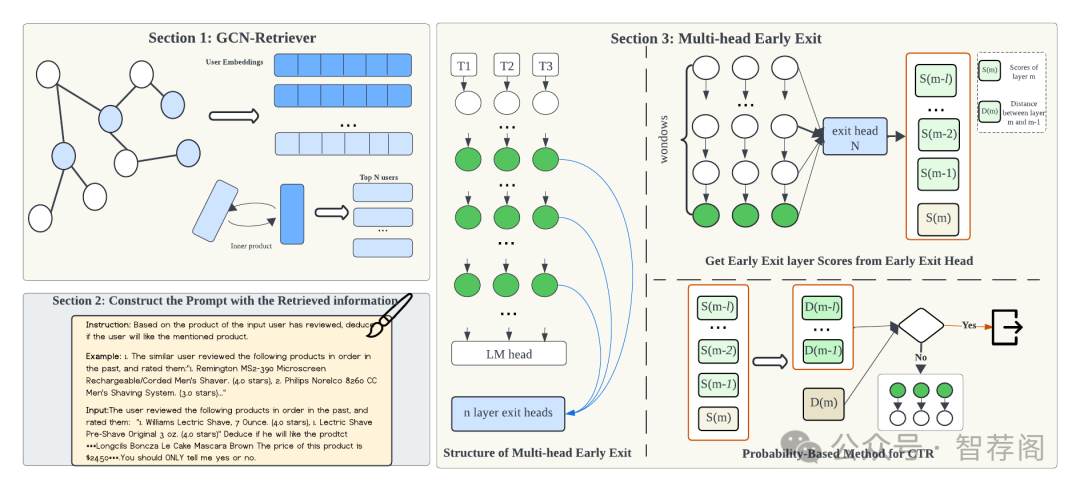
论文简评:这篇论文提出了一个优化框架,用以平衡基于大型语言模型(LLMs)的推荐系统的计算效率与预测准确性。该框架通过集成检索增强生成(RAG)与多头早期退出架构,旨在提供一种有效的解决方案。论文首先介绍了基于图卷积神经网络(GCN)的检索机制,以减少数据检索时间并保持模型性能的高效性。此外,还提出了一种动态终止模型推理的策略。实验结果表明,在CTR预测任务中,使用该方法可以显著降低计算时间,同时保持或提高预测准确性。因此,这篇论文为商业系统提供了有效的实时应用解决方案。
5.Knowledge Graph Retrieval-Augmented Generation for LLM-based Recommendation
Authors: Shijie Wang, Wenqi Fan, Yue Feng, Xinyu Ma, Shuaiqiang Wang, Dawei Yin Affiliations: The Hong Kong Polytechnic University, University of Birmingham, Baidu Inc
https://arxiv.org/abs/2501.02226
论文摘要
Recommender systems have become increasingly vital in our daily lives, helping to alleviate the problem of information overload across various user-oriented online services. The emergence of Large Language Models (LLMs) has yielded remarkable achievements, demonstrating their potential for the development of next-generation recommender systems. Despite these advancements, LLM-based recommender systems face inherent limitations stemming from their LLM backbones, particularly issues of hallucinations and the lack of up-to-date and domain-specific knowledge. Recently, Retrieval-Augmented Generation (RAG) has garnered significant attention for addressing these limitations by leveraging external knowledge sources to enhance the understanding and generation of LLMs. However, vanilla RAG methods often introduce noise and neglect structural relationships in knowledge, limiting their effectiveness in LLM-based recommendations. To address these limitations, we propose to retrieve high-quality and up-to-date structured information from the knowledge graph (KG) to augment recommendations. Specifically, our approach develops a retrieval-augmented framework, termed K-RagRec, that facilitates the recommendation generation process by incorporating structured information from the external KG. Extensive experiments have been conducted to demonstrate the effectiveness of our proposed method.
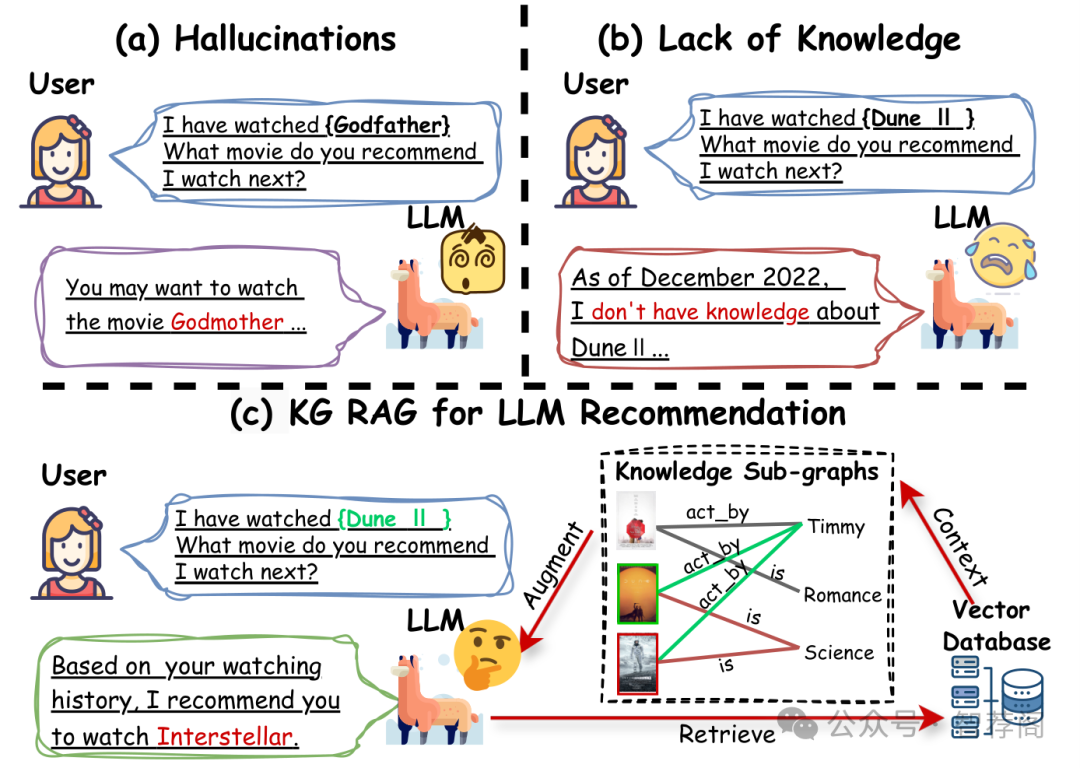
论文简评:这篇论文深入探讨了如何通过引入知识图谱(Knowledge Graphs,KG)增强基于大型语言模型(LLMs)的推荐系统。作者提出的框架K-RagRec不仅解决了虚假信息生成和知识过时等问题,而且通过整合来自知识图谱的知识显著提高了推荐系统的性能。论文的主要优点在于其创新性,特别是在解决LLMs领域中常见问题的有效方法。此外,实验结果表明,该方法能够有效改善推荐性能,尤其是在处理复杂、多变的数据集时,显示出较高的准确性和效率。总之,这篇论文为研究者提供了宝贵的经验和启示,值得进一步的研究与发展。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









