







最强的开源大语言模型 Llama3 已经发布一段时间了,一些盆友资源有限,私信询问是否可以使用 4GB 的 VRAM 在本地运行 Llama3 70B。
与 GPT-4 相比,Llama3 的性能如何?Llama3 使用了哪些关键的前沿技术使其变得如此强大?Llama3 的突破是否意味着开源模型已经正式开始超越闭源模型?
本文给一个解决方案:在仅有 4GB 显存的单个 GPU 上运行 Llama3 70B,并解释相关问题,喜欢本文记得收藏、点赞、关注,欢迎与我进行技术交流。
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流+CSDN
方案
Llama3 的模型架构没有改变,因此 AirLLM 自然已经支持完美运行 Llama3 70B!它甚至可以在 MacBook 上运行。
首先,安装 AirLLM:
pip install airllm
然后,你只需要几行代码:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("v2ray/Llama-3-70B")
input_text = [
'What is the capital of United States?'
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True
)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)
Llama3 与 GPT-4 的比较
根据官方评估数据和最新的 lmsys 排行榜,Llama3 70B 非常接近 GPT-4 和 Claude3 Opus。
官方评估结果:
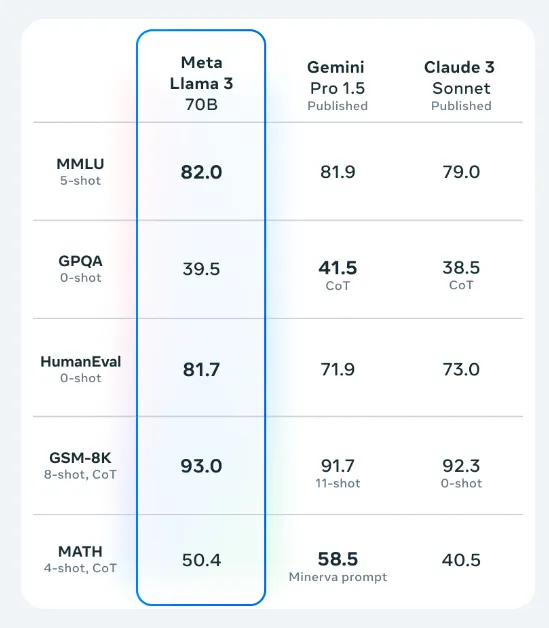
lmsys排行榜结果:
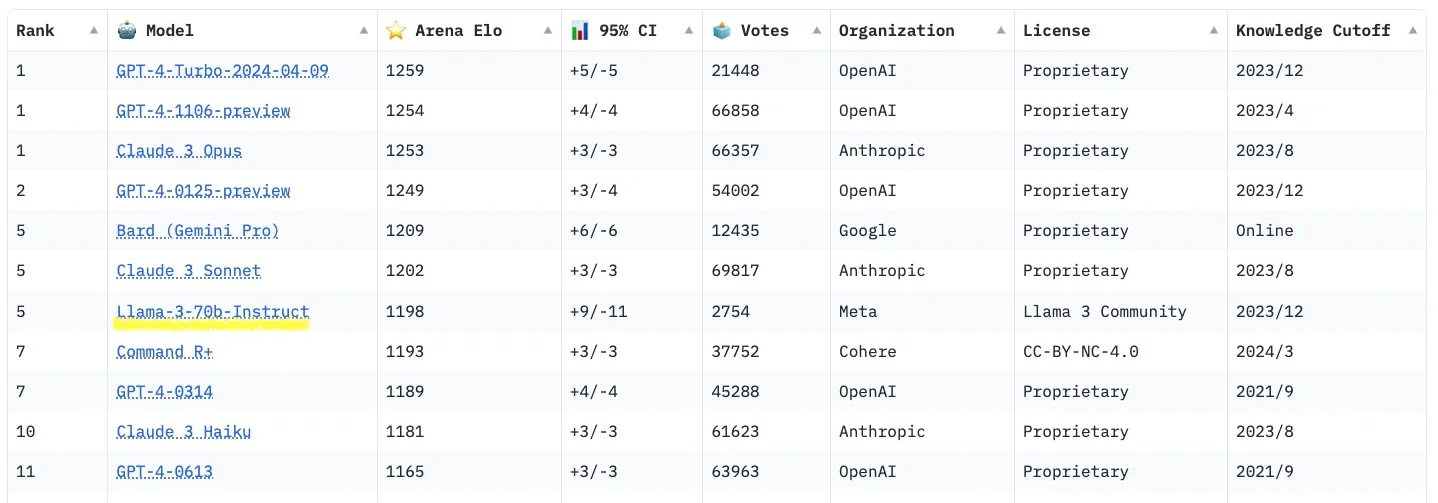
当然,将相似规模的400B模型与GPT-4和Claude3 Opus进行比较会更合理:
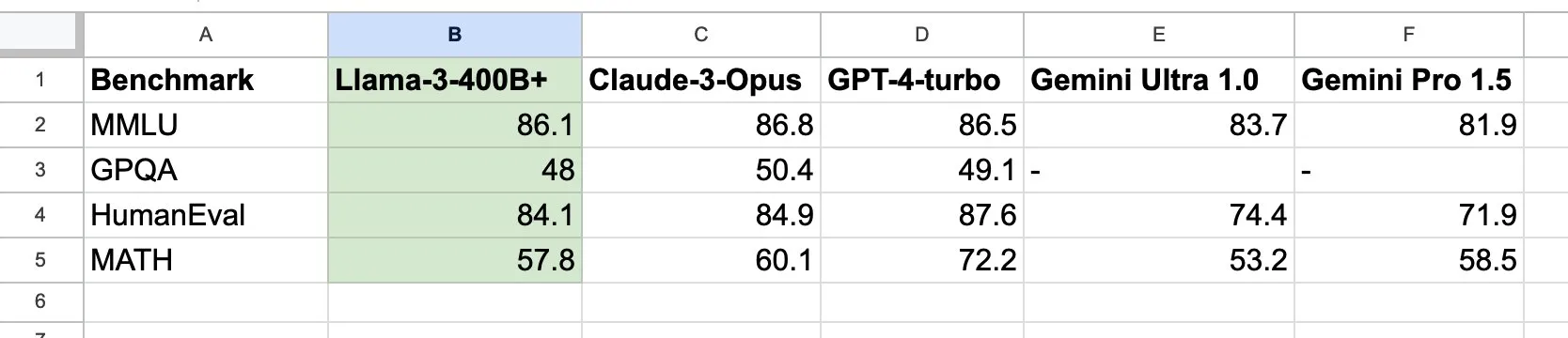
Llama3 400B已经非常接近GPT-4和Claude3的最强版本,而且它还在持续训练中。
Llama3的核心改进是什么?
Llama3 的架构没有变化;在训练方法上有一些技术改进,比如基于DPO(离散策略优化)的模型对齐训练。
DPO 基本上已经成为所有排行榜上顶级大模型的标准训练方法——它确实有效!
当然,Llama3 的主要秘密武器在于其训练数据的数量和质量的巨大提升。从 Llama2 的2万亿增加到15万亿!人工智能的核心就是数据!
数据的改进不仅在于数量,还有质量。Meta进行了大量的数据质量过滤、去重等工作,其中很多都是基于使用像Llama2这样的模型来过滤和选择数据。
训练AI模型的核心是数据。要训练一个好的AI模型,不在于拥有很多花哨的训练技术,而在于扎实细致地做好基础工作。特别是那些不太引人注目、繁琐枯燥的数据质量工作——这实际上至关重要。
我一直对 Meta AI 的能力评价很高。从早期使用 Transformer 进行判别性AI开始,Meta AI 以其扎实的数据处理基础著称,推出了许多长期占据SOTA榜首的经典模型,如Roberta和Roberta XLM。
Llama3 的成功是否预示着开源模型的崛起?
开源与闭源之间的斗争可能远未结束,还有很多戏剧性事件即将上演。
无论是开源还是闭源,训练大模型已经变成了一场烧钱的游戏。15万亿的数据和4000亿的模型不是小玩家能够负担得起的。我认为在接下来的六个月内,许多致力于大模型的小公司将会消失。
在烧钱的竞争中,真正比拼的是长期的投资回报能力和效率。事实上,直到今天,真正实现盈利的AI大语言模型应用仍然很少。很难说谁能够持续投资,以及以何种方式实现盈利。
参考链接
- https://ai.gopubby.com/run-the-strongest-open-source-llm-model-llama3-70b-with-just-a-single-4gb-gpu-7e0ea2ad8ba2
- https://github.com/lyogavin/Anima/tree/main/air_llm
















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









