






解决的问题:之前的网络针对的输入都是一个向量,现在是一串向量(比如句子、语音)
预处理:把文字表达成向量:用独热编码或者词向量
输出是什么:给每个向量打标(词性)/整个向量组打标(情感分析)/输出的类型数不定(比如写一段话概括一篇文章)
为什么不能用全连接层:句子的长度不定,如果要用则网络要按最长的句子大小来开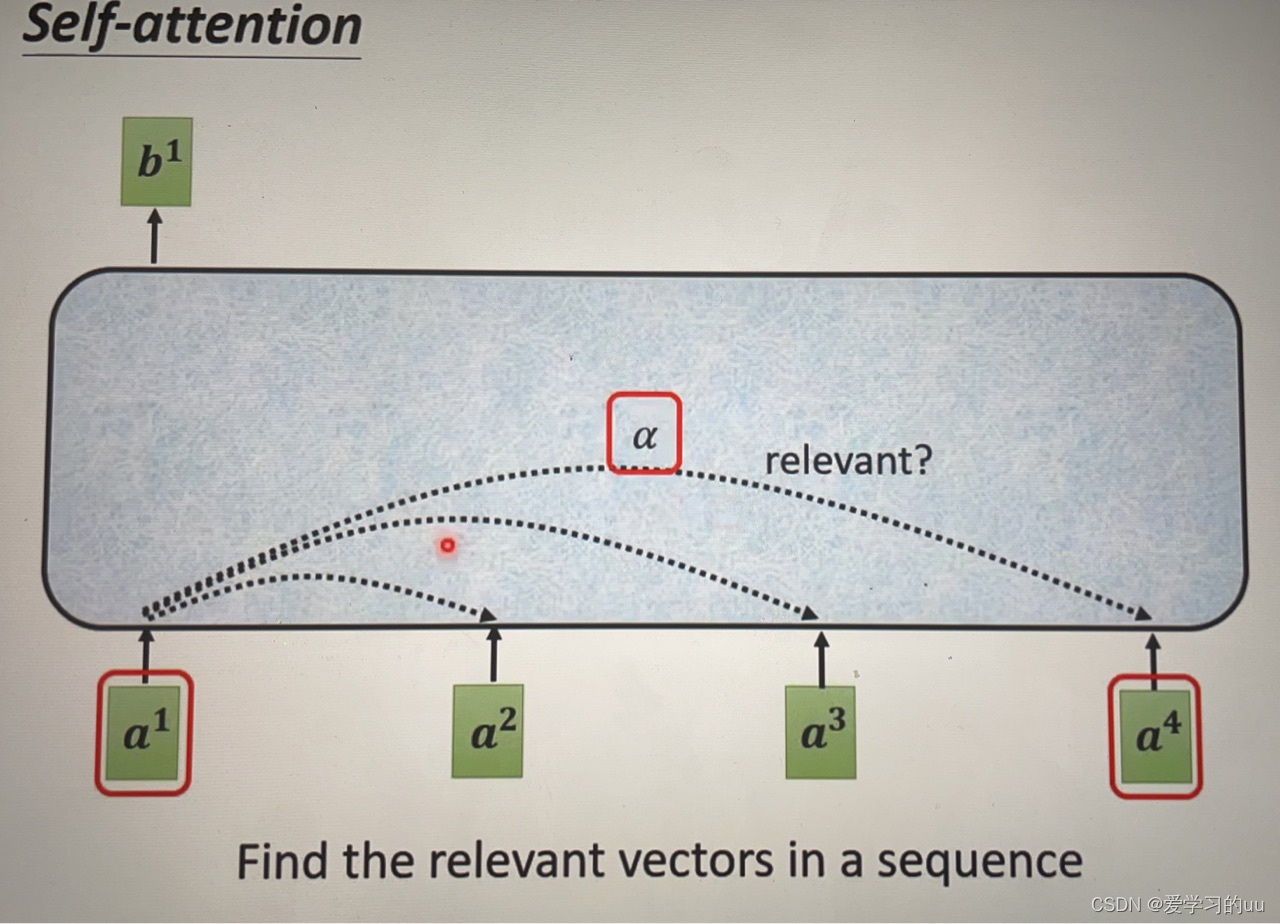
原理:如图所示,b1由a1-a4中与a1相关的向量共同产生,如何求出相关系数a呢:
把a1和a2分别乘矩阵Wq和Wk,得q和k,然后计算点乘
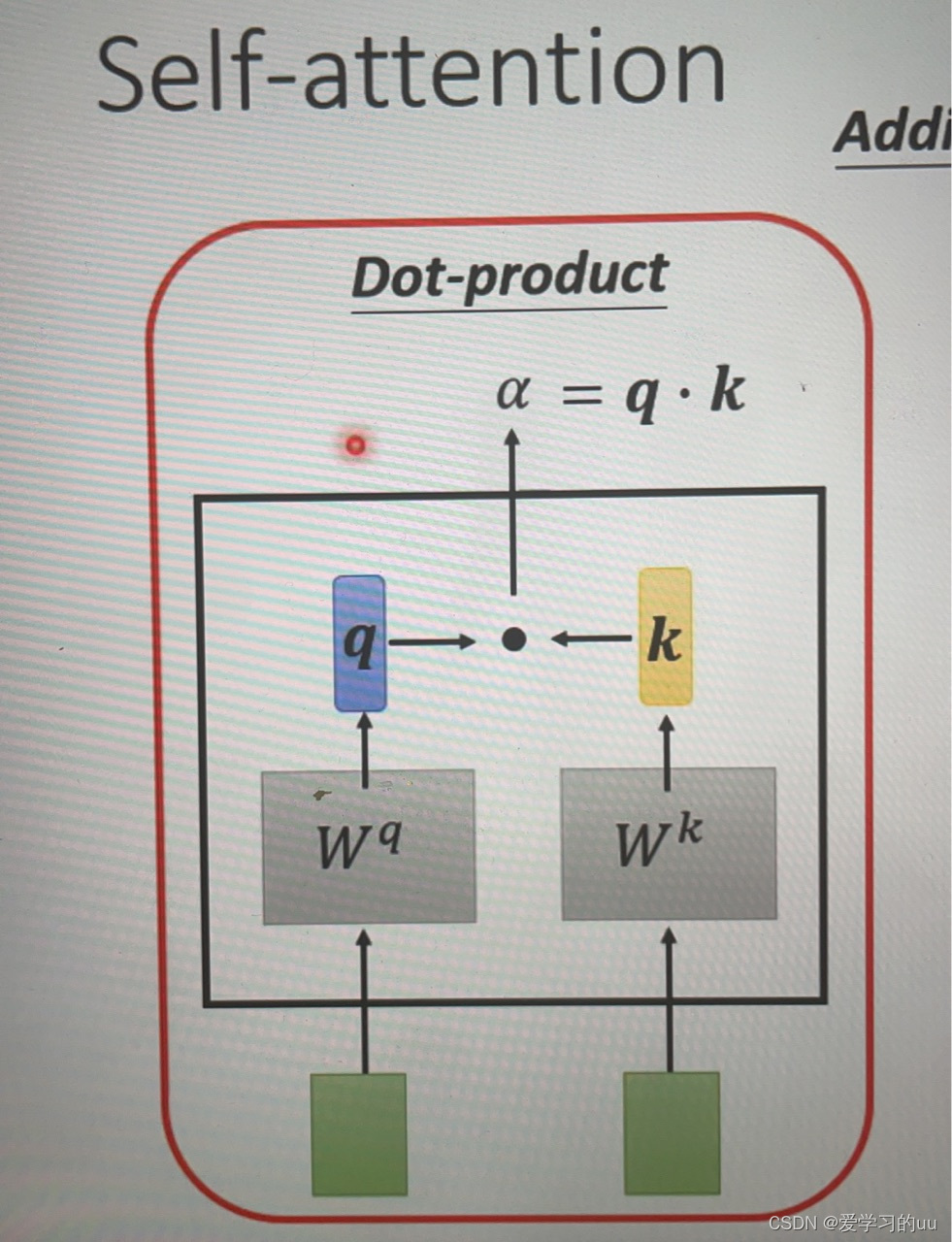
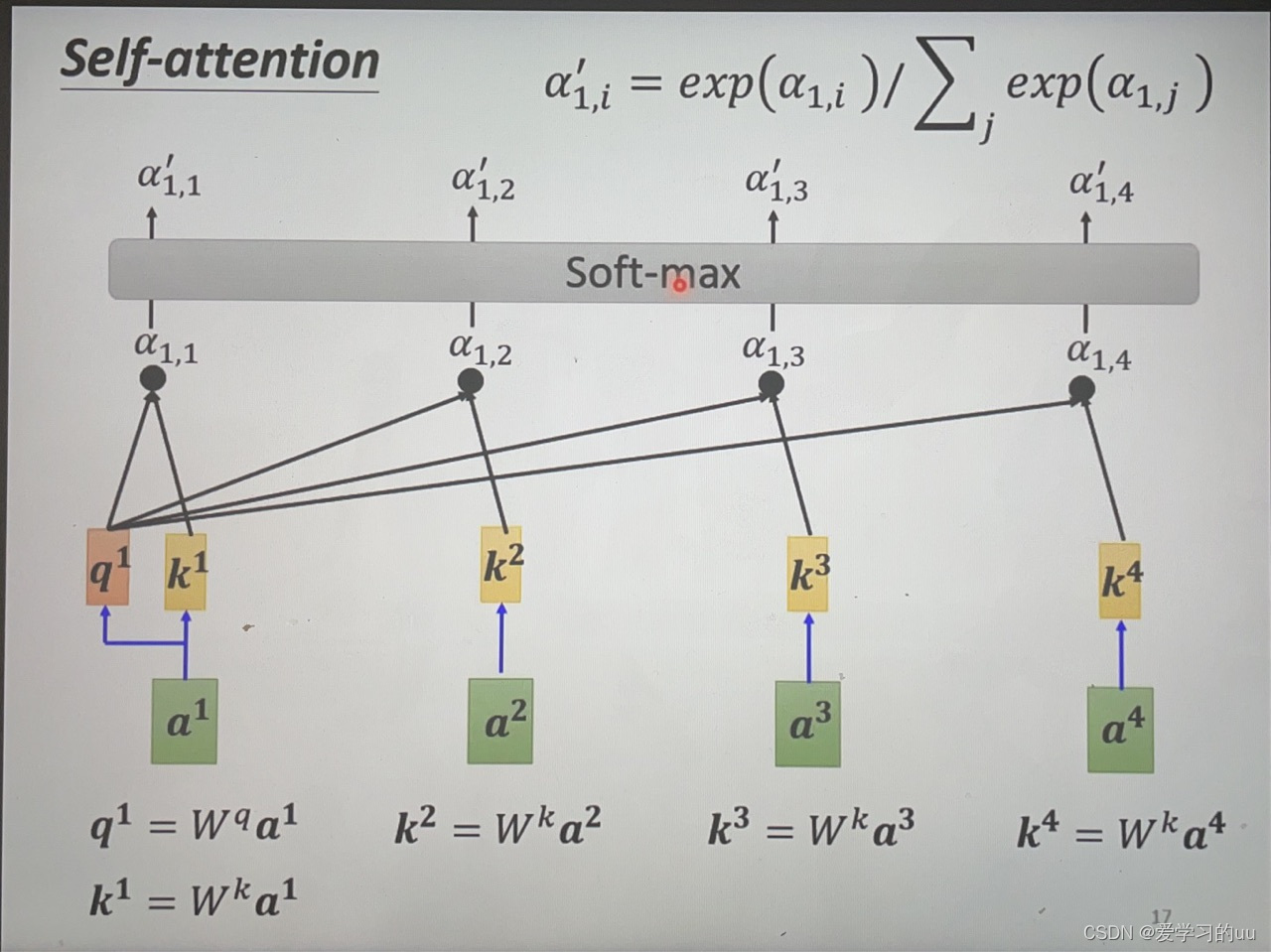
根据这个原理,按图中箭头操作得四个相关性向量,再经过softmax层得输出
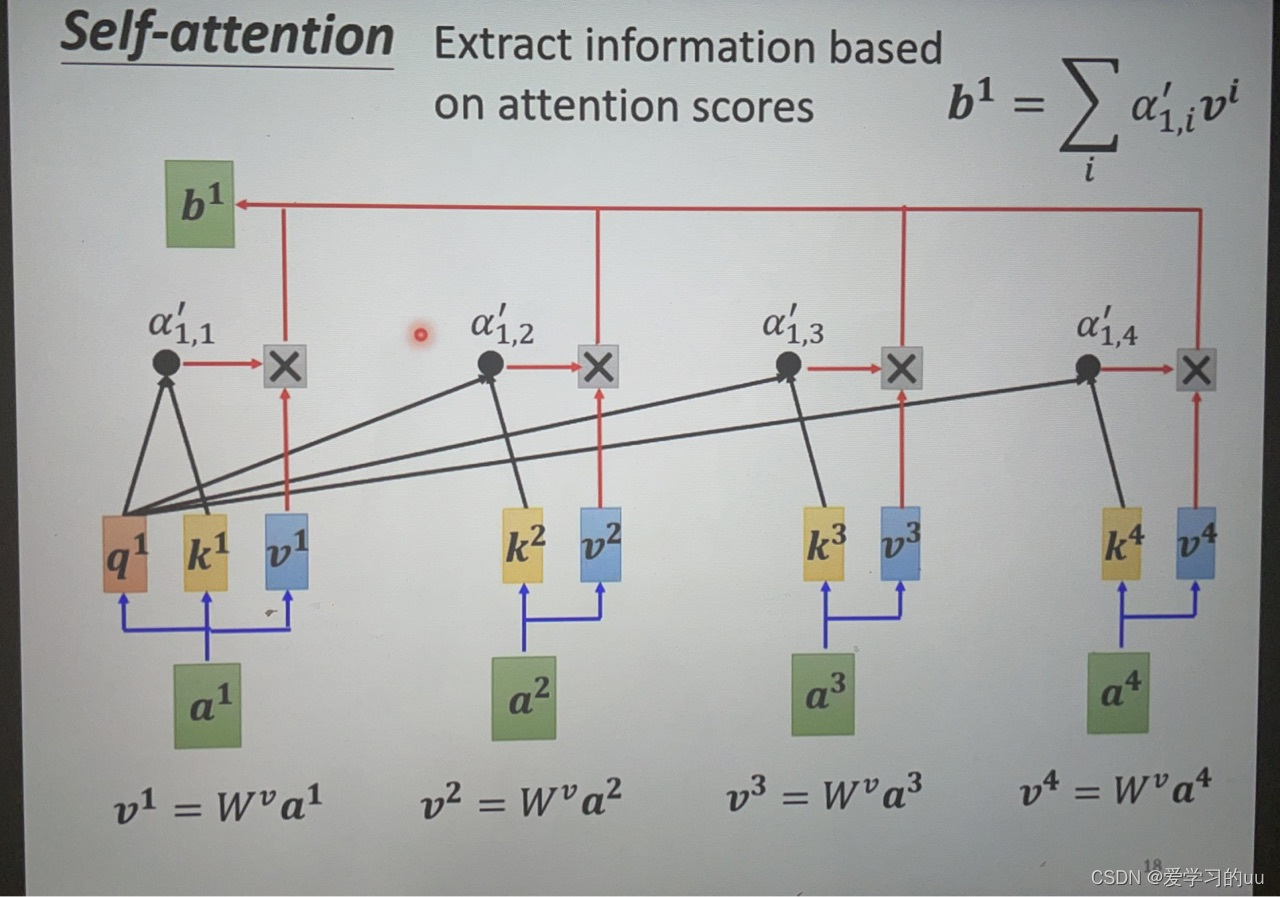
接下来根据相关性抽取重要资讯:再对每个向量分别求v1-vn,对应相乘累加得bi,哪个的相关性分数大,就将决定bi
多头注意力机制:如果需要考虑多种相关性,则可讲每个q分别去乘多个矩阵得到qi,1...qi,n再去分别算
改进:有些问题中位置信息也重要,则把ai+位置向量ei后再计算
原理讲到这儿,下面和CNN做个对比:CNN其实是一个简化版的自注意力机制,它只考虑一个范围内的格子
应用:可以把自注意力机制用在图上面,此时只要计算有连接的两点间的相关性(即为GNN)














 2856
2856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









