






IC验证工程师学习笔记搬运Day3——SystemVerilog!
System Verilog学习笔记
前言
首先,Verilog是进行数字设计的主要语言,专注于硬件行为描述,而SystemVerilog,简称SV,是在Verilog的基础上扩展而来的,属于更高级的编程语言,引入了C++、Java、Python等高级语言也有的类的概念,更抽象,还有其他扩展功能,可以实现数字设计的扩展,功能更强大,也是验证的主流语言,UVM方法学正是基于SV语言开发的。
一、SV语言基础
1.数据类型
| 数据类型 | 未初始化值 |
|---|---|
| 4值逻辑 | 0,1,x,z四态,未初始化的变量是x,线网类型是z |
| 2值逻辑 | 0,1两态,未初始化的变量是0 |
四值逻辑:reg、wire、logic、integer
二值逻辑:bit、int、byte、shortint、longint
SV中的数据类型中:bit,reg,logic的位宽是可以定义和改变的,并且默认为unsigned。
注意:在项目中遇到过一种输入输出inout数据,这种一般在接口中定义为wire类型,不可以定义为logic类型
1.数组
①定宽数组
定宽数组顾名思义就是给定可以容纳的元素,在SV中,尤其需要区分packed和unpacked,也就是合并和非合并数组。
-
合并数组:相当于只有一个元素的数组,例如bit[3:0][7:0] Bytes.

-
非合并数组:一般不需要把数据当成一个整体看,一般有m个元素,每个元素有n个bit位,部分bit位可能会没有使用
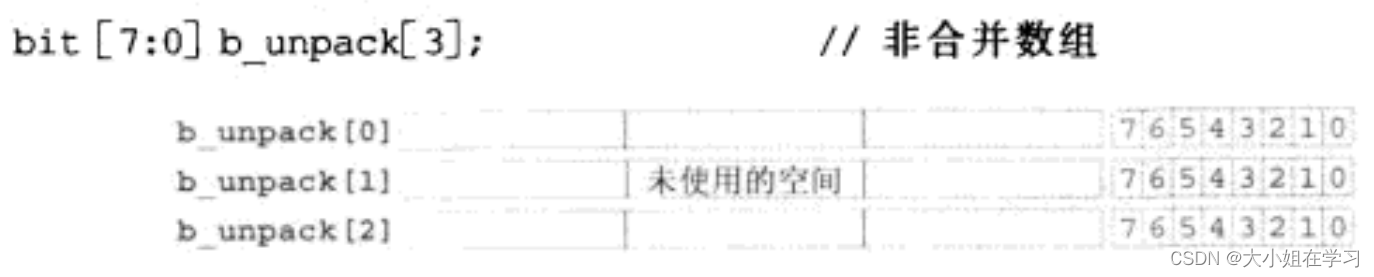
上述每个元素有32bit位,但是只用了8bit,会造成一定的浪费,注意这里32bit并不是规定的,具体要看仿真器系统,也可能是64bit。 -
合并+非合并混合数组:混合使用bit[3:0][7:0] Bytes[0:2],看完下面也许能更好的理解。
此外,初学的时候题主还容易混淆多维数组和合并数组,这里也介绍一下一维数组和多维数组。
一维数组:int arry[0:2],3个元素,每个元素是32bit。多维数组:int arry[0:1][0:2],类似于矩阵,这里是2行3列,每一个都有32bit(int类型是32bit)多维数组和合并数组的区别:多维数组int arry[0:1][0:2],合并数组bit[1:0][2:0] arrys。多维数组数据类型在前,变量名在后,数字在变量名右边且递增,合并数组是数据类型在前,变量名在后,数字大小在变量名左边且递减。所以什么时候用[0:1],什么时候用[1:0]是需要区分的,实际上多维数组就是一种非合并数组。
总结:硬件描述语言SV和软件语言的数组是有差异的,通俗来说,感觉SV更底层,在SV中你可能需要考虑位数的大小,因此会有上述的类型,大家需要细品。
②动态数组
声明:int[31:0]ad[];用new[]操作分配空间,注意区分new();
用于循环操作的函数:foreach和for,$size函数可以返回数组大小。
③数组队列
声明:int q[$];
函数:常规的队列相关函数push和pop:.push_back(item)、.push_front(item)、.pop_back(item)、.pop_front(item)
④关联数组
学过python的同学应该很好理解,我觉得类似于字典,哈希算法的键值对存储,给个图大家就能理解,目前来说日常用的不多,感兴趣的可以自己深入研究。

2.typedef自定义数据类型
typedef enum{} e1;//枚举类型
typedef struct {} s1;//结构体 :所占内存取决于所有元素所占内存之和
typedef union{} u1;//联合体 所占内存长度取决于最长的元素
区分结构体和联合体:联合体是内存中共享同一段存储空间来存储不同类型的数据,例如结构体可以用来存储学生的个人信息,每个学生的姓名、年龄和成绩都有自己的存储空间联合体可以用来存储老师或学生的身份信息,共享相同的内存空间。因此,在任何时刻,只能存储一个成员的值,比如老师的工号或学生的学号。
3.数据类型转换
- 静态强制类型转换:利用符号’,例如:int’(2.0)
- 动态强制类型转换:$cast(目的变量,原变量)
作为任务调用,赋值无效,会出现运行时错误;
作为函数调用,赋值成功返回1,否则返回0,不会出现运行错误。
4.动态和静态存储
主要分为动态存储和静态存储,在软件中也学过。
1)automatic动态存储,相当于局部变量;static静态存储,相当于全局变量。
2)一般定义在module,program,interface中的任务和函数默认静态,将任务函数声明为automatic则是动态的,除非特意声明某个变量是静态的,program定义为automatic,那么其中的任务很函数内的就是默认动态的,但是过程块之外的变量是静态的。
5.常用语句块和进程
介绍常见的过程块语句和fork join
-
过程块:function、task、always_comb、always_ff、aways_latch
控制流:break、continue、disable、return
事件控制
程序块:只允许使用initial块 -
fork join这是常见和常用的并发进程语句
并发执行:Fork join 父进程会等待子进程全部执行完 Fork join_any 父进程等待任一进程执行完 Fork join_none 父进程无需等待任何子进程进程控制
Disable fork 终止所有子进程; Wait fork 挂起进程直到所有子进程执行完成;
6.深拷贝和浅拷贝
深拷贝和浅拷贝在软件和硬件里都是一个重要理解点,特别是软件的八股文面试常问问题,CSDN中有许多的图解说明,这里就简单介绍一下博主认为主要的不同点。
- 赋值:指向同一个对象 p1 = new(); p2 = p1;
只复制句柄,相当于两个句柄指向同一个对象,永远都只有一个对象。 - 浅拷贝:
只拷贝了其中的变量,但是其中的子对象并未拷贝,只是产生了子对象的相同的两个名字 p1 = new(); p2 = new p1; - 深拷贝:
拷贝了对象的变量和其中的子对象,copy函数需要自定义的。
深拷贝和浅拷贝都是拷贝对象,而不是赋值那样复制句柄;但是浅拷贝的内部的子对象句柄指向同一个对象。
7.面向对象
面向对象的内容挺多的,由于软件基础所以理解起来不难,很多类似于c++,对于硬件的没有接触过的需要慢慢理解,这里就贴一些自己的笔记分享吧。
1)构造函数,必须调用构造函数才会为对象申请新的内存空间;构造函数可以自定;默认情况下
2)静态属性
静态变量被这个类的所有对象共享,但仅限于这个类,通过.或者::的方式访问
3)继承
允许子类override父类的methods
super关键字,父类成员被重载,那么再访问就必须用super,在new中使用super,super.new是执行的第一条语句。
4)$cast
作为任务调用时,会检查源对象类型和目的对象类型是否存在祖先关系,失配报错;作为函数调用时会做检查但是不匹配不报错
5)数据隐藏封装
local:仅对类内的方法可见,子类不可见
protected:具有本地属性,但是对继承子类可见
Const:全局常量(声明的时候直接赋值)和实例常量(在new中完成一次赋值)
6)块外声明extern
Extern virtual function 返回类型 函数名(参数);
Function 返回类型 类名::函数名(参数);
7)参数化的类
二、功能覆盖率模型
开始IC验证的小伙伴,应该会知道我们在验证的时候,用什么来保证自己是否验证充分呢?对的,就是覆盖率了,覆盖率分为代码覆盖率和功能覆盖率,一般我们都是要求代码覆盖率达到100%。
代码覆盖率分为block、expression、toggle等,这里不具体分析,一般覆盖率分析工具会自动计算这几部分,我们只需要分析没有覆盖的地方原因,可能是发现了设计的bug,也可能是无法覆盖需要exclude掉等等,总之一般项目最后需要达到100%,并且输出对应的文档写明覆盖率分析的过程和不能覆盖的原因。
另外就是功能覆盖率,功能覆盖率一般包括覆盖组和断言,主要是辅助保证功能点是否验证充分,比如说支持位宽8,16,32bit,那代码覆盖率可能位宽=8bit就能实现100%,但是我妹仍需要验证16和32bit是否能正常工作,这时候可以采用覆盖组是否都命中,还有就是比如时钟复位的检查,这是需要验证的,我们就可以采用断言,判断时钟频率是否符合或者复位前后是否按照要求复位成功等。功能覆盖率是进一步保证功能点都被验证充分,当然在这之前,功能点的提取需要验证师做到尽可能面面俱到。
接下来主要介绍功能覆盖率模型开发的一些语法
1.覆盖组covergroup
以下给一个一般的覆盖组代码示例,语法比较简单,很好理解,按照格式进行依葫芦画瓢就行。
代码如下(示例):
Covergroup memsys_cv @(posedge clk iff(!rst))
Option.per_instance = 1;//输出明细
Option.goal = 100;
Option.weight = 5;
Option.comment = "注释";
Option.auto_bin_max;覆盖率点自创建的最大容器数;
Option.at_least;覆盖率点击中门限
Name1 : Coverpoint a{
Bins b ={};
}//覆盖点定义
Name2: coverpoint b{
Bins c = {};
Bins d = {};
}
Cross a, b{
Ignore_bins c = binsof()intersect();//忽略仓,一般是不能实现或者不支持的需要排除,否则会降低功能覆盖率
Illegal_bins d = [];//非法仓,排除掉
}//交叉覆盖率定义
Endcovergroup
//实例化覆盖组
Memsys_cv Memsys_cv_inst = new();
Bind 接口 模块名 模块实例名(端口连接)
Bins 就是仓,击中仓就会提高覆盖率,需要保证所选的仓都击中,达到100%。
显示定义
Bins a = {};
Bins b[] = {};每一个都是一个仓,这是队列形
忽略仓ignore_bins
非法仓illega_bins
不关心wildcard bins b1 = {4'b???0};问好表示不关心的位数
2.断言assertion(SVA)
之前项目写断言和覆盖组的时候,就明显感觉csdn这方面的知识分享确实比软件少很多,因此也希望能多分享一些供大家互相学习。
断言分为即时断言和并行断言,通俗理解即时断言就是运行断言的位置这里断言,并行断言一般都是运行中会一直断言,一般在时钟上升沿被激活。断言首先是需要声明一个property属性,然后assert或者cover property进行断言,cover是只会断言一次,assert就是整个仿真过程都会一直断言,具体视情况选择,然后还要sequence可以简化property避免太长,对应的语法也比较简单。详细介绍可以参考博客:
SVA断言简明使用指南
常见的语法csdn还是有一些文章,这里分享以下断言传参的方式:码字太累了,过两天继续补充整理,敬请期待!
心得:断言的过程有一个心得就是很考验验证师的全面考虑,因为项目越复杂,随着激励的不断增加,那么跑回归的时候很可能出现断言报错,那么其实是有很多场景需要被disable掉,当时做项目也是不断调试。
总结
本文主要介绍了博主学习SV的一些重点知识和学习心得,包括SystemVerilog的一些语法还有功能覆盖率模型(覆盖组和断言)的开发,供大家互相参考和学习。















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









