







算法评价指标
准确率
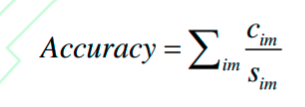
C i m C_{im} Cim正确预测的车道点数量 , S i m S_{im} Sim 真实标签中的车道点数量
当预测的与实际的车道线之间距离小于设定阈值时,认为该车道点预测正确
误检率
F
P
FP
FP
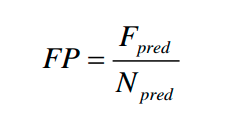
漏检率
F
N
FN
FN
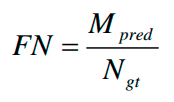
F
p
r
e
d
F_{pred}
Fpred为预测错误的车道线数量,
N
p
r
e
d
N_{pred}
Npred为预测的车道线总数量,
M
p
r
e
d
M_{pred}
Mpred 没有预测到但真实存在的车道线数量,
N
g
t
N_{gt}
Ngt 标签中所有的车道线数量
F 1 F_1 F1Score
是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。 F 1 F_1 F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
F
1
F_1
F1分数,又称平衡F分数(balanced F Score),它被定义为精确率和召回率的调和。

召回率(recall): 该类样本有多少被找出来了(召回了多少)
精确率(Precision): 你认为的该类样本,有多少猜对了(猜得精确性如何)
来源: https://www.zhihu.com/question/19645541张俊博
CULane用的是IoU


Dice 系数计算示例
dice_loss
参考链接: https://www.aiuai.cn/aifarm1159.html
dice_loss参考博客:https://zhuanlan.zhihu.com/p/269592183
Dice coefficient
dice loss 来自文章VNet(V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation),旨在应对语义分割中正负样本强烈不平衡的场景。dice loss 来自 dice coefficient,是一种用于评估两个样本的相似性的度量函数,取值范围在0到1之间,取值越大表示越相似。dice coefficient定义如下:

其中
∣
X
⋂
Y
∣
|X \bigcap Y|
∣X⋂Y∣是X和Y之间的交集,
∣
X
∣
|X |
∣X∣和
∣
Y
∣
|Y|
∣Y∣分表表示X和Y的元素的个数,分子乘2为了保证分母重复计算后取值范围在 [0,1]之间.
因此dice loss可以写为:因此dice loss可以写为:

语义分割问题而言,X - GT 分割图像, Y - Pred 分割图像.
Dice 系数计算示例
预测的分割图的 dice 系数计算,首先将 ∣ X ⋂ Y ∣ |X \bigcap Y| ∣X⋂Y∣近似为预测图与 GT 分割图之间的点乘,并将点乘的元素结果相加:
Pred 预测分割图与 GT 分割图的点乘:

逐元素相乘的结果元素的相加和:

关于 |X| 和 |Y| 的量化计算,可采用直接简单的元素相加;也有采用取元素平方求和的做法:

注:dice loss 比较适用于样本极度不均的情况,一般的情况下,使用 dice loss 会对反向传播造成不利的影响,容易使训练变得不稳定.

















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









