







💡💡💡本文改进:替换YOLOv10中的PSA进行二次创新,1)CoordAttention注意力替换 PSA中的多头自注意力模块MHSA注意力;2) CoordAttention直接替换 PSA;
💡💡💡SimAM是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积
改进1结构图:
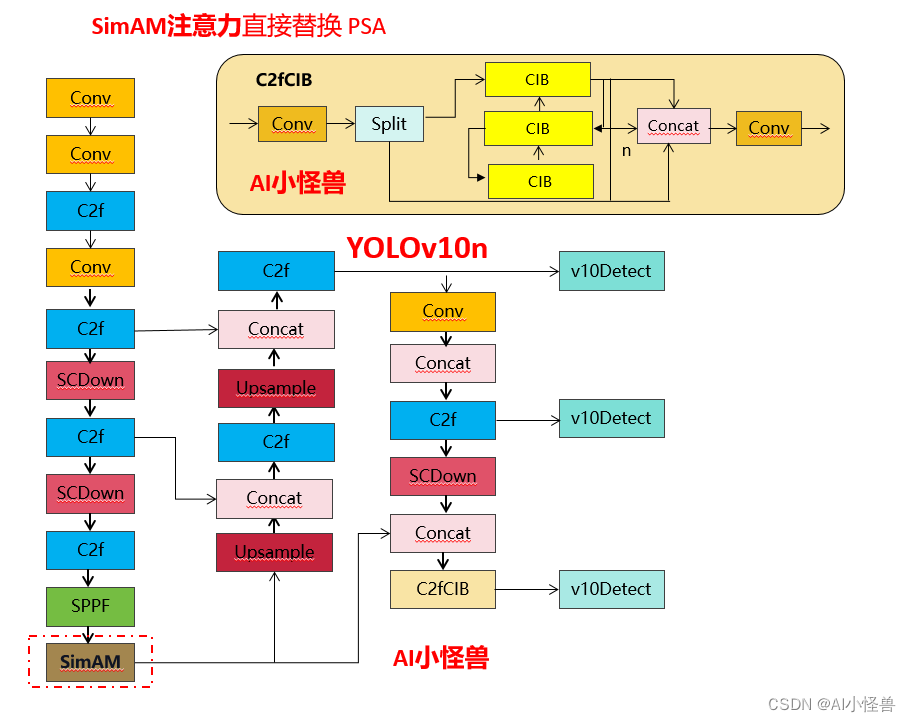
改进2结构图:
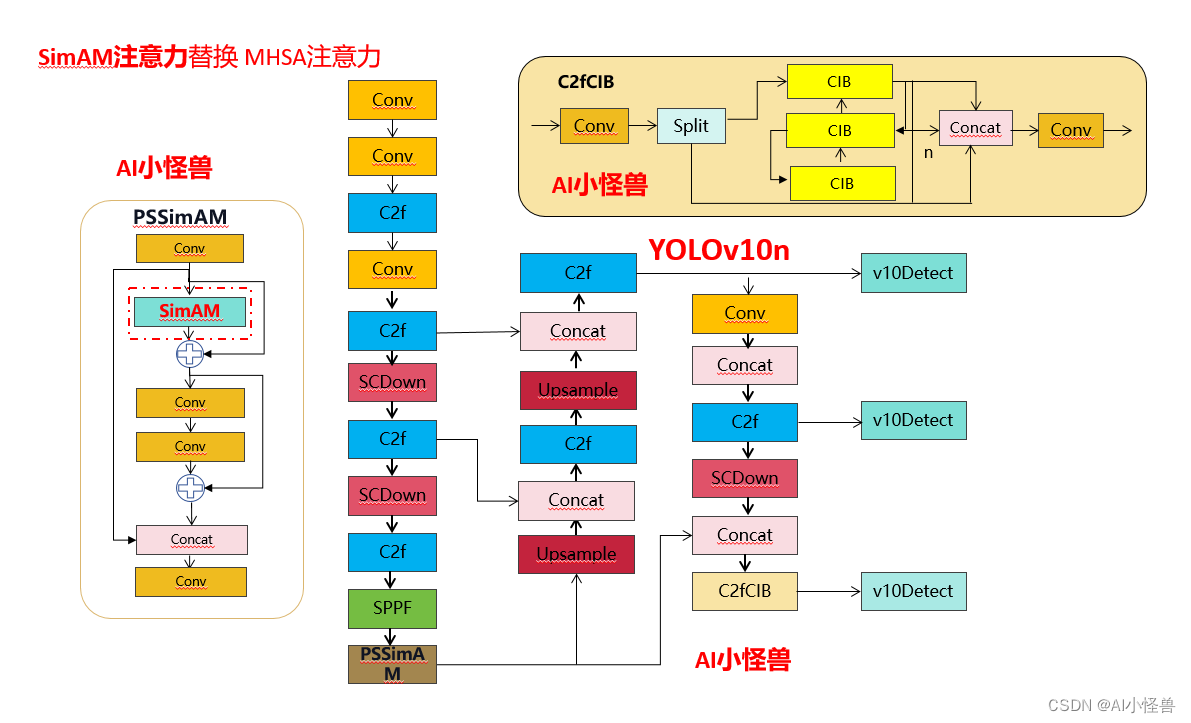
《YOLOv10魔术师专栏》将从以下各个方向进行创新:

【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
订阅者通过添加WX: AI_CV_0624,入群沟通,提供改进结构图等一系列定制化服务。
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 159 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8、Yolov9等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLOv10介绍

论文: https://arxiv.org/pdf/2405.14458
代码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成为实时目标检测领域的主导范例。研究人员已经探索了YOLOS的架构设计、优化目标、数据增强策略等,并取得了显著进展。然而,对用于后处理的非最大抑制(NMS)的依赖妨碍了YOLOS的端到端部署,并且影响了推理延迟。此外,YOLOS中各部件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的性能。这导致次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOS的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法带来了有竞争力的性能和低推理延迟。此外,我们还介绍了YOLOS的整体效率-精度驱动模型设计策略。我们从效率和精度两个角度对YOLOS的各个组件进行了全面优化,大大降低了计算开销,增强了性能。我们努力的成果是用于实时端到端对象检测的新一代YOLO系列,称为YOLOV10。广泛的实验表明,YOLOV10在各种模型规模上实现了最先进的性能和效率。例如,在COCO上的类似AP下,我们的YOLOV10-S比RT-DETR-R18快1.8倍,同时具有2.8倍更少的参数和FLOPS。与YOLOV9-C相比,YOLOV10-B在性能相同的情况下,延迟减少了46%,参数减少了25%。

1.1 C2fUIB介绍
为了解决这个问题,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计降低被证明是冗余的阶段复杂度。我们首先提出了一个紧凑的倒置块(CIB)结构,它采用廉价的深度可分离卷积进行空间混合,以及成本效益高的点对点卷积进行通道混合
C2fUIB只是用CIB结构替换了YOLOv8中 C2f的Bottleneck结构
实现代码ultralytics/nn/modules/block.py


1.2 PSA介绍
具体来说,我们在1×1卷积后将特征均匀地分为两部分。我们只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
实现代码ultralytics/nn/modules/block.py

1.3 SCDown
OLOs通常利用常规的3×3标准卷积,步长为2,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本O(9HWC^2)和参数数量O(18C^2)。相反,我们提议将空间缩减和通道增加操作解耦,以实现更高效的下采样。具体来说,我们首先利用点对点卷积来调整通道维度,然后利用深度可分离卷积进行空间下采样。这将计算成本降低到O(2HWC^2 + 9HWC),并将参数数量减少到O(2C^2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在减少延迟的同时保持了有竞争力的性能。
实现代码ultralytics/nn/modules/block.py
2. SimAM:无参Attention

论文: http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
SimAM(Simple Attention Mechanism)是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积。其网络结构如下:
输入序列 -> Embedding层 -> Dropout层 -> 多层SimAM层 -> 全连接层 -> Softmax层 -> 输出结果
其中,SimAM层由以下几个部分组成:
-
多头注意力层:输入序列经过多个线性映射后,分成多个头,每个头计算注意力权重。
-
残差连接层:将多头注意力层的输出与输入序列相加,保证信息不会丢失。
-
前向传递层:对残差连接层的输出进行线性变换和激活函数处理,再与残差连接层的输出相加。
-
归一化层:对前向传递层的输出进行层归一化处理,加速训练并提高模型性能。
通过多层SimAM层的堆叠,模型可以学习到输入序列中的长程依赖关系,并生成对应的输出序列。
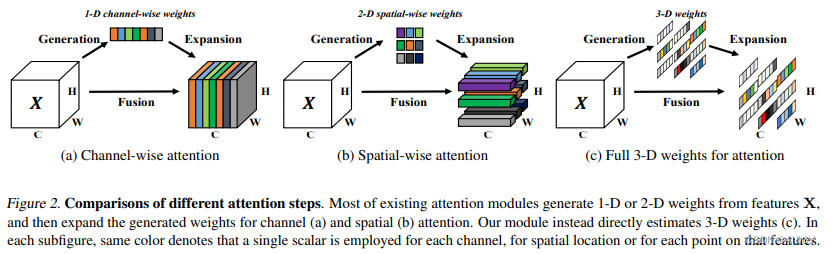
在不增加原始网络参数的情况下,为特征图推断三维注意力权重
1、提出优化能量函数以发掘每个神经元的重要性
2、针对能量函数推导出一种快速解析解,不超过10行代码即可实现。

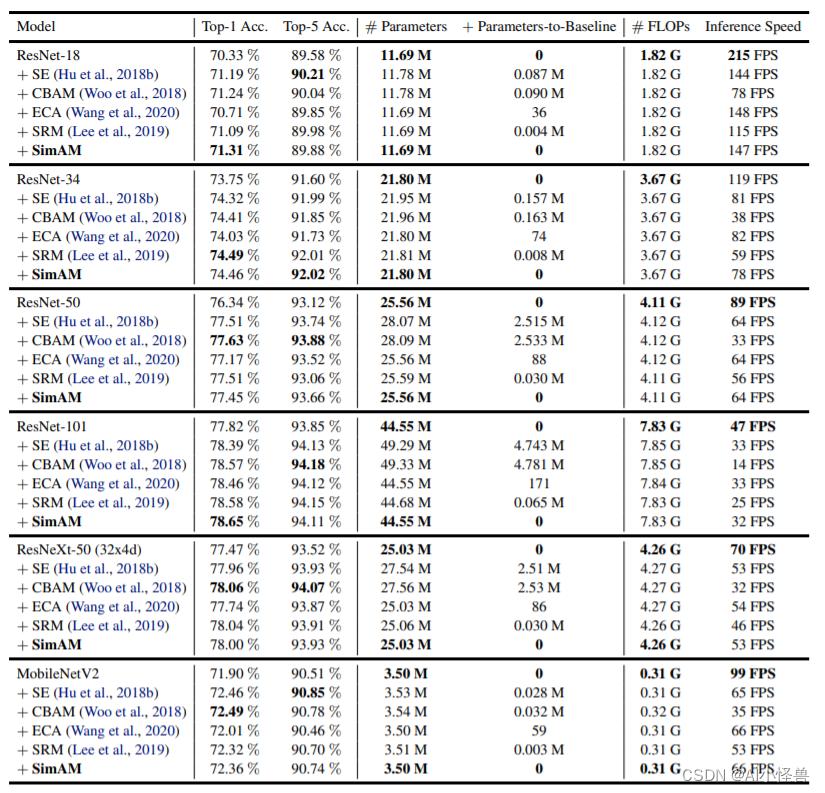
表格给出了ImageNet数据集上不同注意力机制的性能对比,从中可以看到:
- 所有注意力模块均可以提升基线模型的性能;
- 所提SimAM在ResNet18与ResNet101基线上取得了最佳性能提升;
- 对于ResNet34、ResNet50、ResNeXt50、MobileNetV2,所提SimAM仍可取得与其他注意力相当性能;
- 值得一提的是,所提SimAM并不会引入额外的参数;
- 在推理速度方面,所提SimAM与SE、ECA相当,优于CBAM、SRM。
3.SimAM如何加入到YOLOv10
3.1新建ultralytics/nn/attention/attention.py
###################### SimAM #### start by AI&CV ###############################
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv
class SimAM(torch.nn.Module):
def __init__(self,c1, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
class PSSimAM(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert (c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = SimAM(self.c)
self.ffn = nn.Sequential(
Conv(self.c, self.c * 2, 1),
Conv(self.c * 2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))
###################### SimAM #### end by AI&CV ###############################3.2 修改tasks.py
1)首先进行引用定义
from ultralytics.nn.attention.attention import *2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入SimAM,PSSimAM(切勿直接复制过去)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in {
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
RepNCSPELAN4,
ADown,
SPPELAN,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
PSA,SimAM,PSSimAM
SCDown,
C2fCIB
}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3, C2fCIB):
args.insert(2, n) # number of repeats
n = 1
3.3 yolov10n-SimAM.yaml
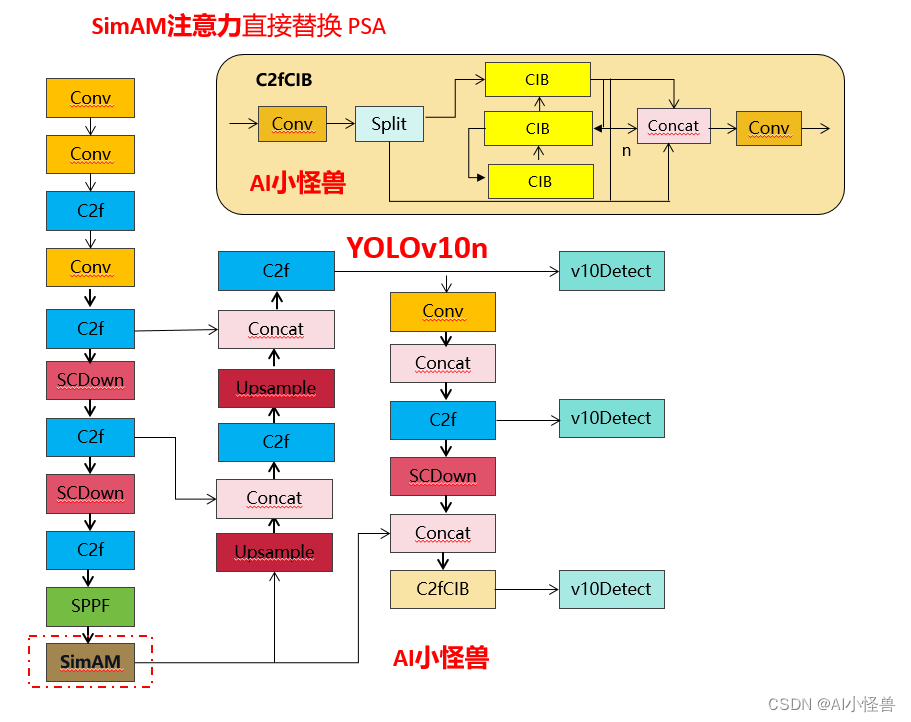
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, SimAM, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
3.4 yolov10n-PSSimAM.yaml
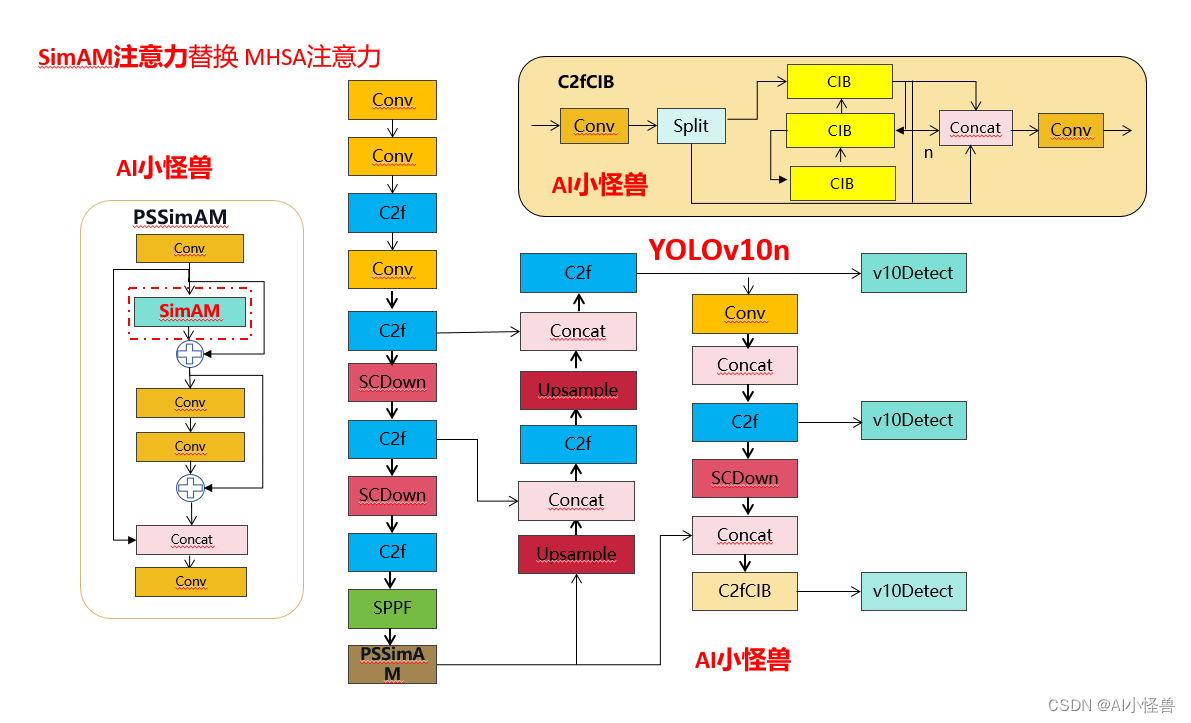
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSSimAM, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











