







YOLOV11目标检测注意力机制改进实例与创新改进专栏
目录
论文地址:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
1.完整代码获取
此注意力机制应用于目标检测有很好的效果,21年的文章,可以用于多种科研;
此专栏提供完整的改进后的YOLOv8项目文件,你也可以直接下载到本地,然后打开项目,修改数据集配置文件以及合适的网络yaml文件即可运行,操作很简单!订阅专栏的小伙伴可以私信博主,或者直接联系博主,加入YOLOv8改进交流群;
+Qq:1921873112
2.simAM注意力机制介绍
SimAM:ASimple,Parameter-Free Attention Module for Convolutional Neural Networks 注意力机制的详细信息:
SimAM(Similarity - Aware Activation Module)注意力机制是一种新颖的注意力机制。它受到神经科学中空域抑制现象的启发,通过度量神经元之间的线性可分性来确定其重要性。在工作过程中,先从输入图像中提取特征图,接着计算局部自相似性,然后基于此生成注意力权重,最后将注意力权重图与原始特征图相乘来增强重要特征、抑制无关特征。这种机制的优势在于它是轻量级且无参数的,能有效避免过拟合,还可以提升模型性能,通用性强,能很好地嵌入多种卷积神经网络架构用于不同的视觉任务,并且在处理有噪声和遮挡的图像时鲁棒性良好。
3. simAM具有优势:
一、轻量级和无参数特性
- 它不需要引入额外的可学习参数。这与许多其他注意力机制形成鲜明对比,那些机制往往会增加模型的参数量。例如在深度神经网络中,参数过多容易导致过拟合问题,而 SimAM 由于无额外参数,就很好地避免了这一情况,使得模型更加简洁高效。
二、性能提升方面
-
能够精准地聚焦于图像或者数据中的关键特征信息。在计算机视觉任务里,如像图像分类任务中,它可以帮助模型更好地分辨出不同类别的关键特征差异。以区分猫和狗的图像为例,SimAM 能突出猫的眼睛、耳朵等具有代表性的特征,同时抑制背景等无关信息,从而有效提高模型分类的准确性。
-
在目标检测任务中,它能够使模型更加关注目标物体的区域,增强对目标物体的特征表示,提高检测的精度和召回率。对于复杂场景下的小目标检测,这种优势更加明显,能够提升模型在这种具有挑战性任务中的表现。
-
在图像分割任务中,通过增强目标物体的特征并抑制非目标区域的特征,使分割边界更加清晰准确,从而提升分割质量。
三、通用性强
- 可以很方便地嵌入到各种现有的卷积神经网络(CNN)架构中。无论是经典的如 VGGNet、ResNet,还是一些新的网络架构,都能很好地与之结合。这意味着不需要对原有的网络结构进行大规模的改动,就能享受到 SimAM 带来的注意力优势,大大提高了其在不同模型和任务中的适用性。
四、鲁棒性良好
-
在面对含有噪声的图像时,SimAM 能够有效地筛选出真正的特征信息,降低噪声对模型的干扰。例如在有椒盐噪声或高斯噪声污染的图像中,它依然能够突出物体的主要特征,保证模型对图像内容的正确理解。
-
对于有部分遮挡的图像,也能够利用未被遮挡部分的特征信息,合理地分配注意力权重,从而使模型仍然可以对物体进行有效的识别和处理。
4. simAM网络结构图
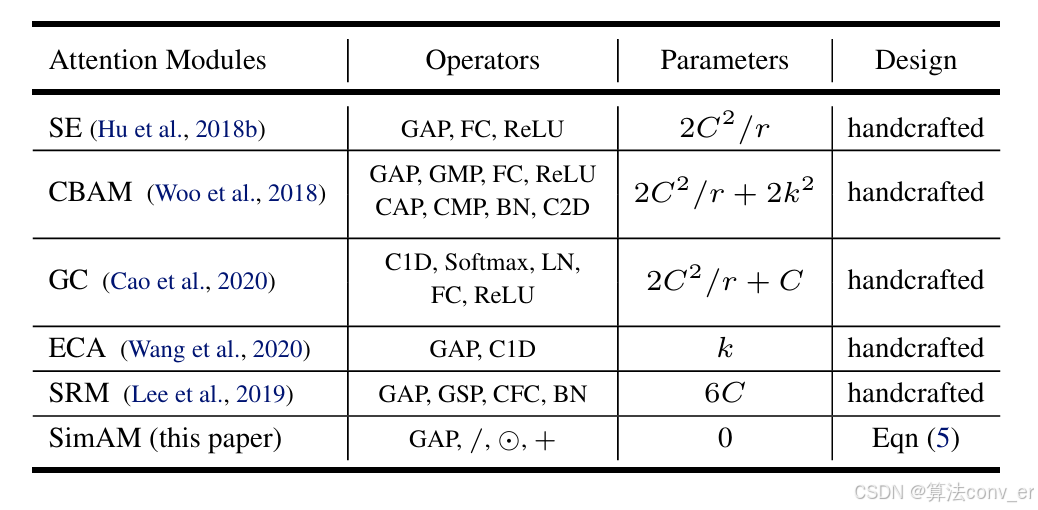

5. yolov8-simAM 的yaml文件
放置到backbone中,可以这样放置
也可以放置到检测头前面,进行特征融合,提高检测精度!两种yaml文件都有;
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, SimAM, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
6.simAM代码实现
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels = None,out_channels = None, e_lambda = 1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y) 7.simAM注意力机制添加方式
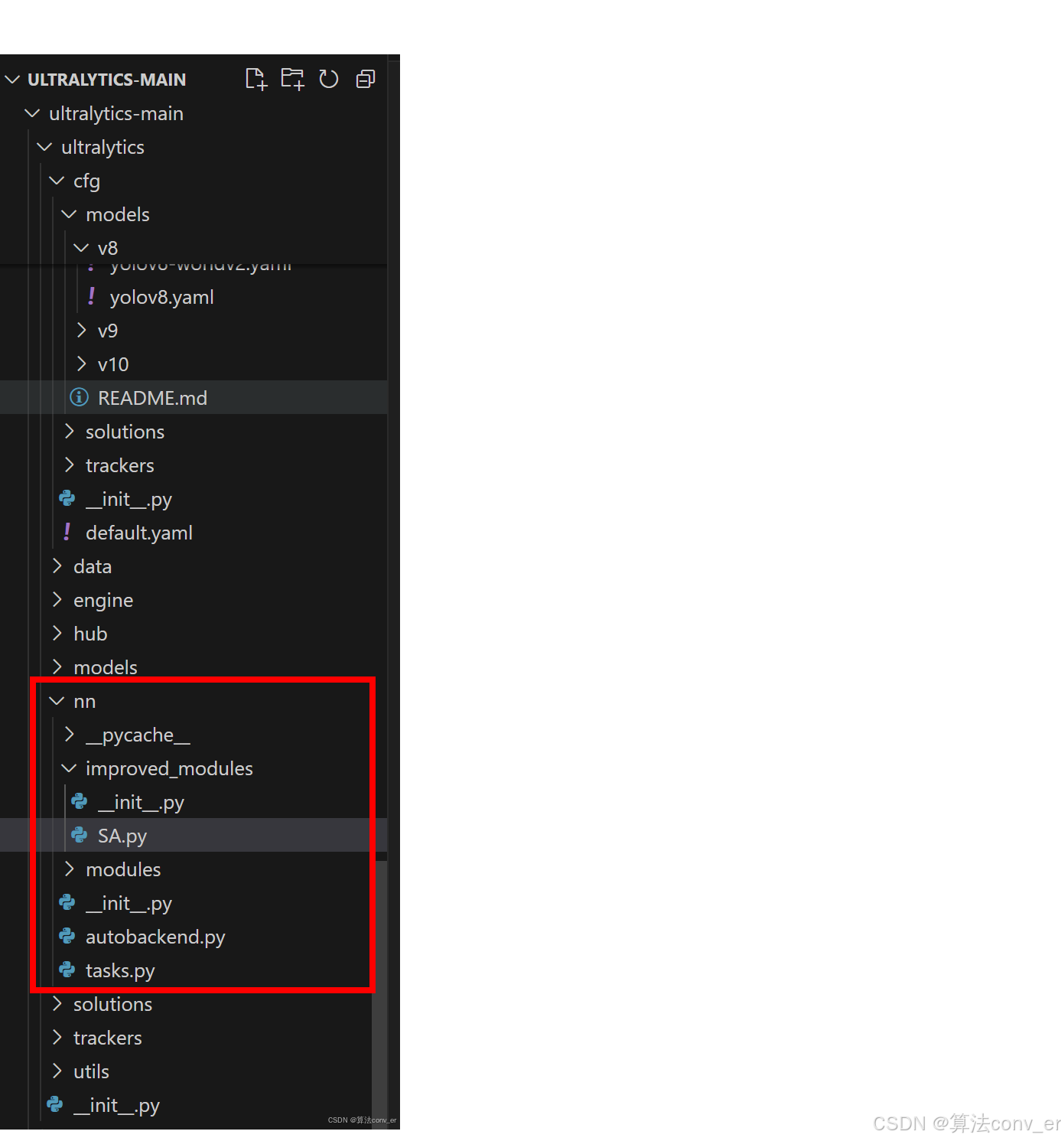
step1:找到ultralytics/nn文件夹下建立一个目录名字呢就是'improved_modules'文件夹,ranhou在这个文件夹下新建一个simAM.py文件(你自己想起什么名字都可以),如下图所示(这是我创建SA.py时的截图,操作是一样的):
step2:把simAM注意力的代码添加到simAM.py文件中;
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels = None,out_channels = None, e_lambda = 1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
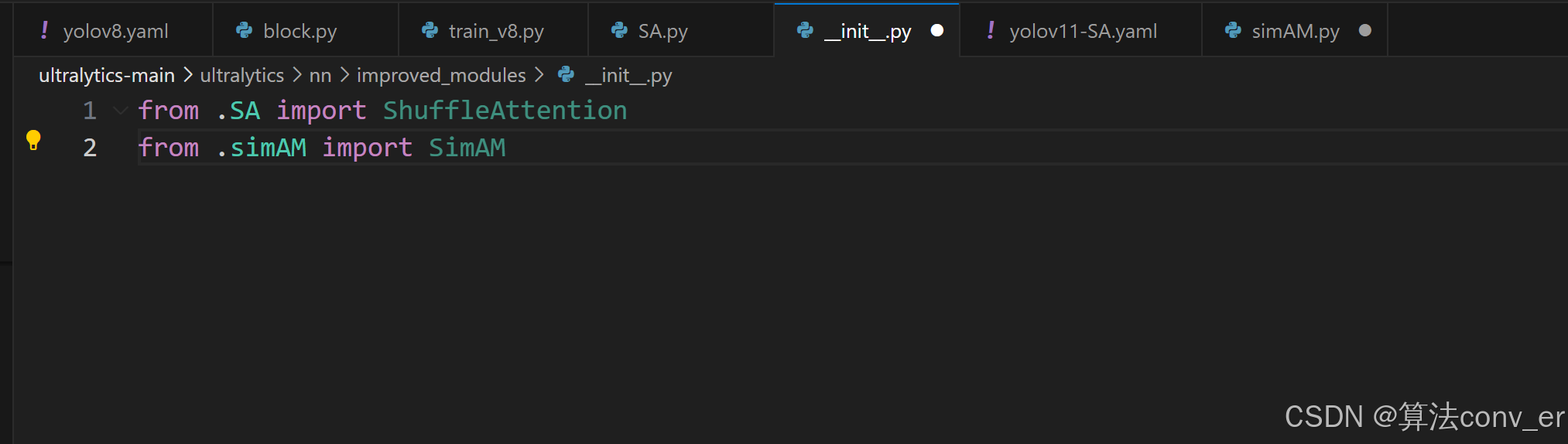
return x * self.activaton(y) step3:往创建的__init__.py函数中添加调用函数,如下所示;
step4:找到文件'ultralytics/nn/tasks.py'进行导入和注册新建的模块!
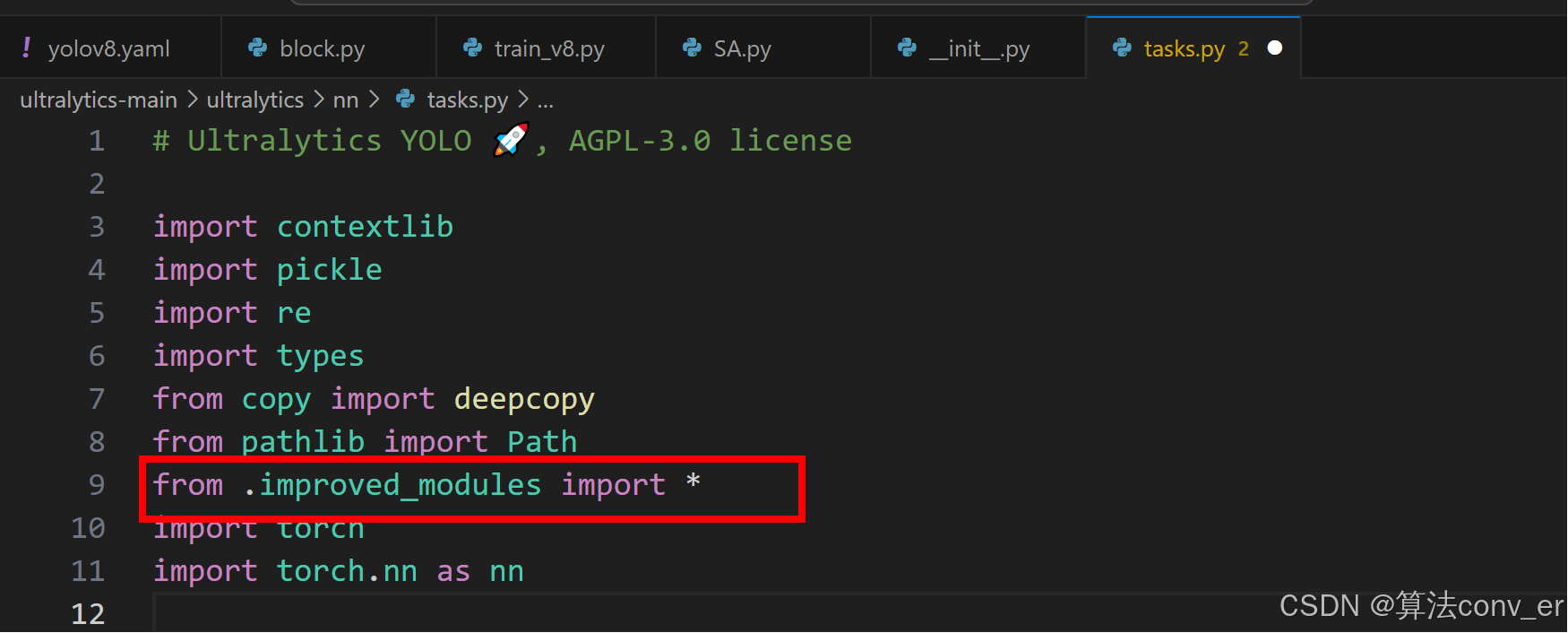
step5:找到'ultralytics/nn/tasks.py'文件中的'def parse_model(d, ch, verbose=True)方法,然后按照图片进行添加修改即可。
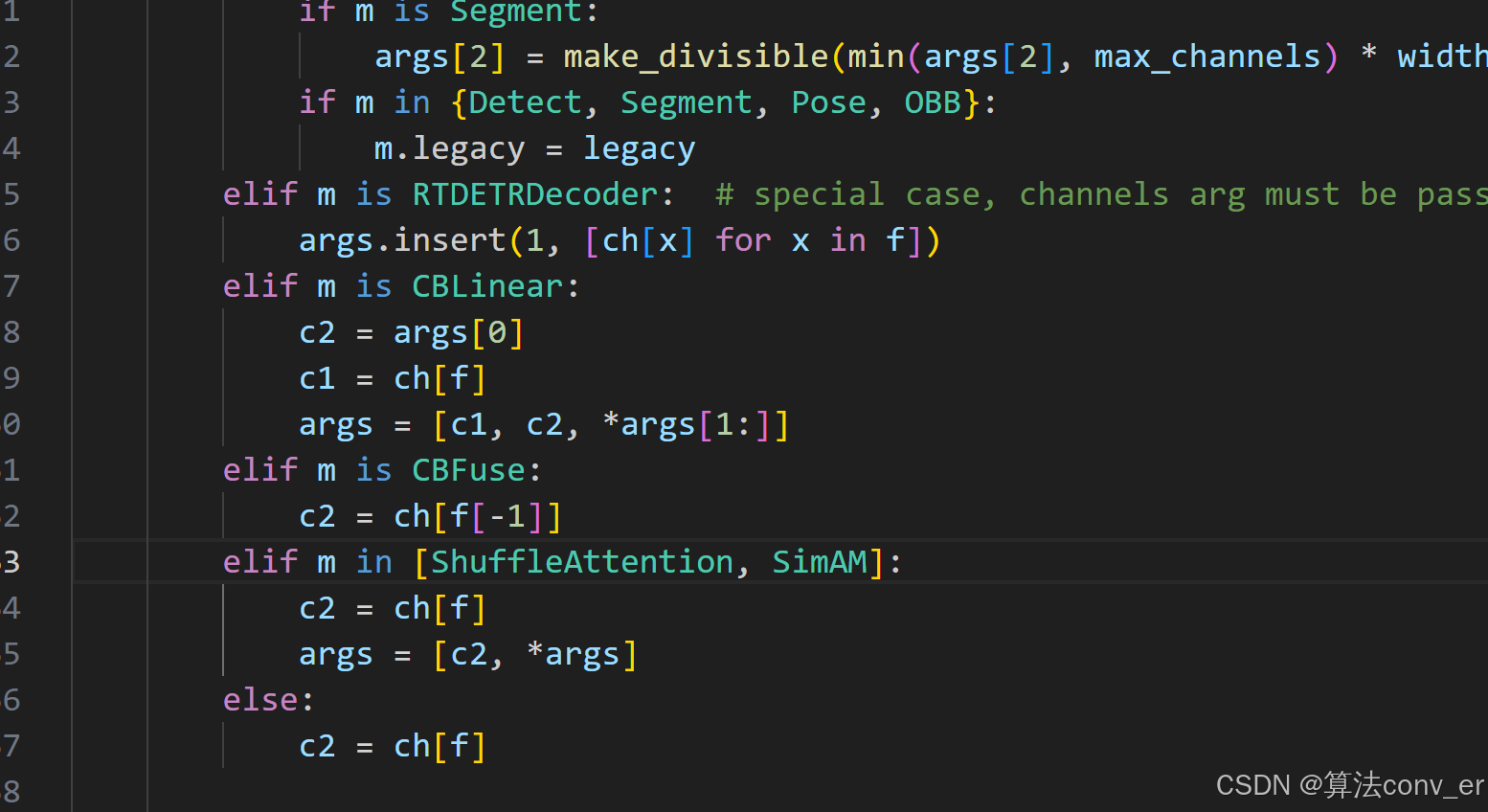
此篇博客到这里就告一段落了,后续我还会继续更新很多改进,大家感兴趣的可以关注我的专栏。

















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









