









💡💡💡本文内容:针对基基于YOLOv10的光伏板缺陷检测算法进行性能提升,加入各个创新点做验证性试验。
💡💡💡SPPF原创自研 | SPPF_attention,重新设计加入注意力机制,能够在不同尺度上更好的、更多的关注注意力特征信息,mAP50从原始的0.838提升至0.85。
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9、v10优化创新,涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

原创自研系列, 2024年计算机视觉顶会创新点
23年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
应用系列篇:
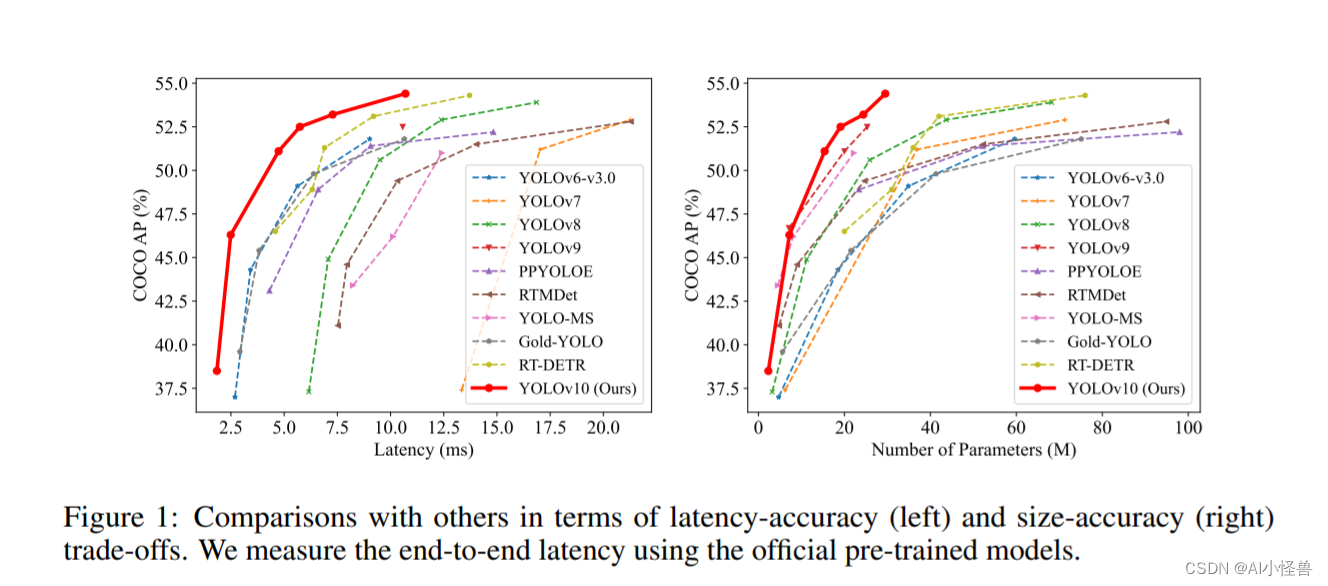
1.YOLOv10介绍

论文: https://arxiv.org/pdf/2405.14458
代码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成为实时目标检测领域的主导范例。研究人员已经探索了YOLOS的架构设计、优化目标、数据增强策略等,并取得了显著进展。然而,对用于后处理的非最大抑制(NMS)的依赖妨碍了YOLOS的端到端部署,并且影响了推理延迟。此外,YOLOS中各部件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的性能。这导致次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOS的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法带来了有竞争力的性能和低推理延迟。此外,我们还介绍了YOLOS的整体效率-精度驱动模型设计策略。我们从效率和精度两个角度对YOLOS的各个组件进行了全面优化,大大降低了计算开销,增强了性能。我们努力的成果是用于实时端到端对象检测的新一代YOLO系列,称为YOLOV10。广泛的实验表明,YOLOV10在各种模型规模上实现了最先进的性能和效率。例如,在COCO上的类似AP下,我们的YOLOV10-S比RT-DETR-R18快1.8倍,同时具有2.8倍更少的参数和FLOPS。与YOLOV9-C相比,YOLOV10-B在性能相同的情况下,延迟减少了46%,参数减少了25%。
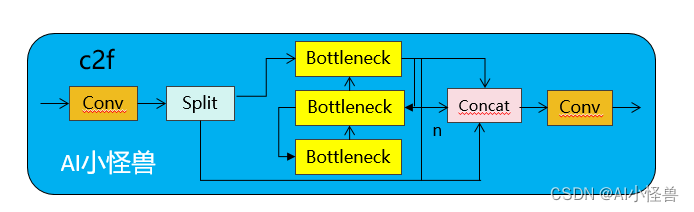
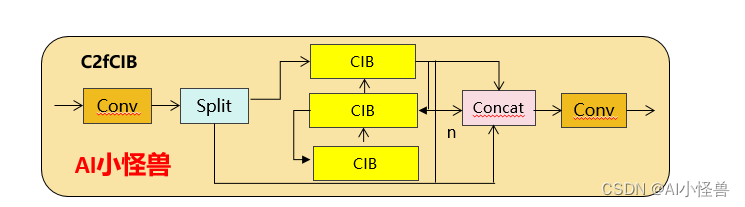
1.1 C2fUIB介绍
为了解决这个问题,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计降低被证明是冗余的阶段复杂度。我们首先提出了一个紧凑的倒置块(CIB)结构,它采用廉价的深度可分离卷积进行空间混合,以及成本效益高的点对点卷积进行通道混合
C2fUIB只是用CIB结构替换了YOLOv8中 C2f的Bottleneck结构
实现代码ultralytics/nn/modules/block.py
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
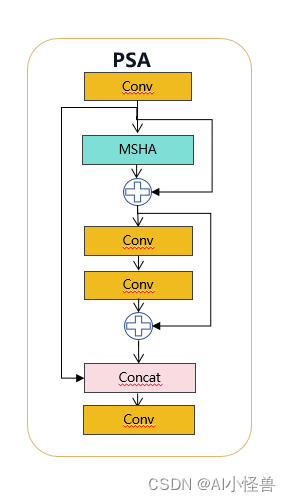
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))1.2 PSA介绍
具体来说,我们在1×1卷积后将特征均匀地分为两部分。我们只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
实现代码ultralytics/nn/modules/block.py
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))1.3 SCDown
OLOs通常利用常规的3×3标准卷积,步长为2,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本O(9HWC^2)和参数数量O(18C^2)。相反,我们提议将空间缩减和通道增加操作解耦,以实现更高效的下采样。具体来说,我们首先利用点对点卷积来调整通道维度,然后利用深度可分离卷积进行空间下采样。这将计算成本降低到O(2HWC^2 + 9HWC),并将参数数量减少到O(2C^2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在减少延迟的同时保持了有竞争力的性能。
实现代码ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))2.光伏板缺陷检测识别数据集介绍
光伏板缺陷检测数据集大小1920张,数据集共包含划痕、断栅与脏污三类缺陷。
细节图如下:


3.YOLOv10魔改提升精度
3.1原始结果
原始YOLOv10n结果如下:
原始mAP50为0.838
YOLOv10n summary (fused): 285 layers, 2695586 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:16<00:00, 1.13s/it]
all 480 528 0.829 0.773 0.838 0.424
Crack 480 180 0.832 0.778 0.806 0.424
Grid 480 180 0.833 0.828 0.86 0.433
Spot 480 168 0.822 0.712 0.848 0.416

3.2 SPPF原创自研 | SPPF_attention,重新设计加入注意力机制
原文链接: YOLOv10涨点改进:SPPF原创自研 | SPPF_attention,重新设计加入注意力机制,能够在不同尺度上更好的、更多的关注注意力特征信息_yolov10sppf改进-CSDN博客
💡💡💡本文原创自研创新改进:
优点:为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
如何优化:在此基础上加入注意力机制,能够在不同尺度上更好的、更多的获取特征信息,从而获取全局视角信息并减轻不同尺度大小所带来的影响
强烈推荐,适合直接使用,paper创新级别
💡💡💡 在多个数据集验证涨点,尤其对存在多个尺度的数据集、小目标数据集涨点明显
SPPF_attention改进结构图如下:

改进结果如下:
原始mAP50为0.838提升至0.847
YOLOv10n-SPPF_attention summary (fused): 294 layers, 3221924 parameters, 0 gradients, 8.4 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:20<00:00, 1.37s/it]
all 480 528 0.815 0.792 0.847 0.432
Crack 480 180 0.775 0.783 0.817 0.425
Grid 480 180 0.813 0.844 0.846 0.431
Spot 480 168 0.857 0.748 0.879 0.441 
4.系列篇
1)一种新颖的基于内容引导注意力(CGA)的混合融合助力缺陷检测
2)加入SPPF原创自研 | SPPF_attention,重新设计加入注意力机制提升缺陷检测能力
3) 一种基于YOLOv10的高精度光伏板缺陷检测算法(原创自研)
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!


















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











