








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

1.项目背景
随着互联网技术的飞速发展,特别是大数据、人工智能等技术的不断成熟,互联网医疗平台已成为连接医患双方的重要桥梁。这些平台通过提供在线问诊、健康咨询、电子病历管理等服务,极大地提升了医疗服务的便捷性和效率。然而,互联网医疗平台在快速发展的同时,也面临着诸多挑战,如用户描述的模糊性、医生远程诊疗的困难性、以及医患之间沟通障碍等。
在这些挑战中,用户描述的模糊性尤为突出。由于患者对自身病情的理解有限,或受表达能力影响,他们提供的病情描述往往不够准确和详细,这给医生的远程诊疗带来了极大的困扰。为了提高诊疗的准确性和效率,优化患者的就诊体验,构建一个能够准确反映用户需求和特点的画像模型显得尤为重要。
用户画像作为一种有效勾画需求客户、准确联系用户诉求和创造方向的工具,已经在多个领域得到了广泛应用。它通过收集和分析用户的行为数据、偏好信息等,形成对用户群体的精准描述,从而为产品和服务的定制化提供有力支持。在互联网医疗领域,用户画像模型同样具有重要意义。它可以帮助平台更好地理解用户需求,优化服务流程,提升服务质量,最终实现医患双方的共赢。
基于此,本研究旨在利用文本挖掘技术,构建基于互联网医疗平台的用户画像模型。具体而言,本研究将以自闭症疾病问诊数据为例,通过Python爬虫技术获取好大夫在线医疗平台的问诊数据,并运用隐含狄利克雷分布(LDA)与Kmeans结合的模型对数据进行划分和降维聚类,实现用户群体的分类并构建出具有代表性的用户画像。
本研究的意义在于,通过构建用户画像模型,可以深入挖掘用户的问诊主题和需求特点,为平台优化问诊填写模板、提高用户填写疾病描述的准确性、提升问诊效率和患者满意度提供有力支持。同时,该研究也有助于推动互联网医疗平台向更加智能化、个性化的方向发展,为医患双方提供更加便捷、高效的医疗服务。
2.项目介绍
2.1文献来源
[1]吕艳华,王康龙,钟小云,等.基于文本挖掘的互联网医疗平台用户画像模型构建[J].医学信息学杂志,2024,45(06):7-12.
2.2数据集介绍
本实验数据集来源于好大夫在线医疗平台,使用Python爬虫采集孤独症(自闭症)的问诊数据,包括患者性别、年龄、问诊内容等,共计爬取400页问诊数据,累计6000条数据。
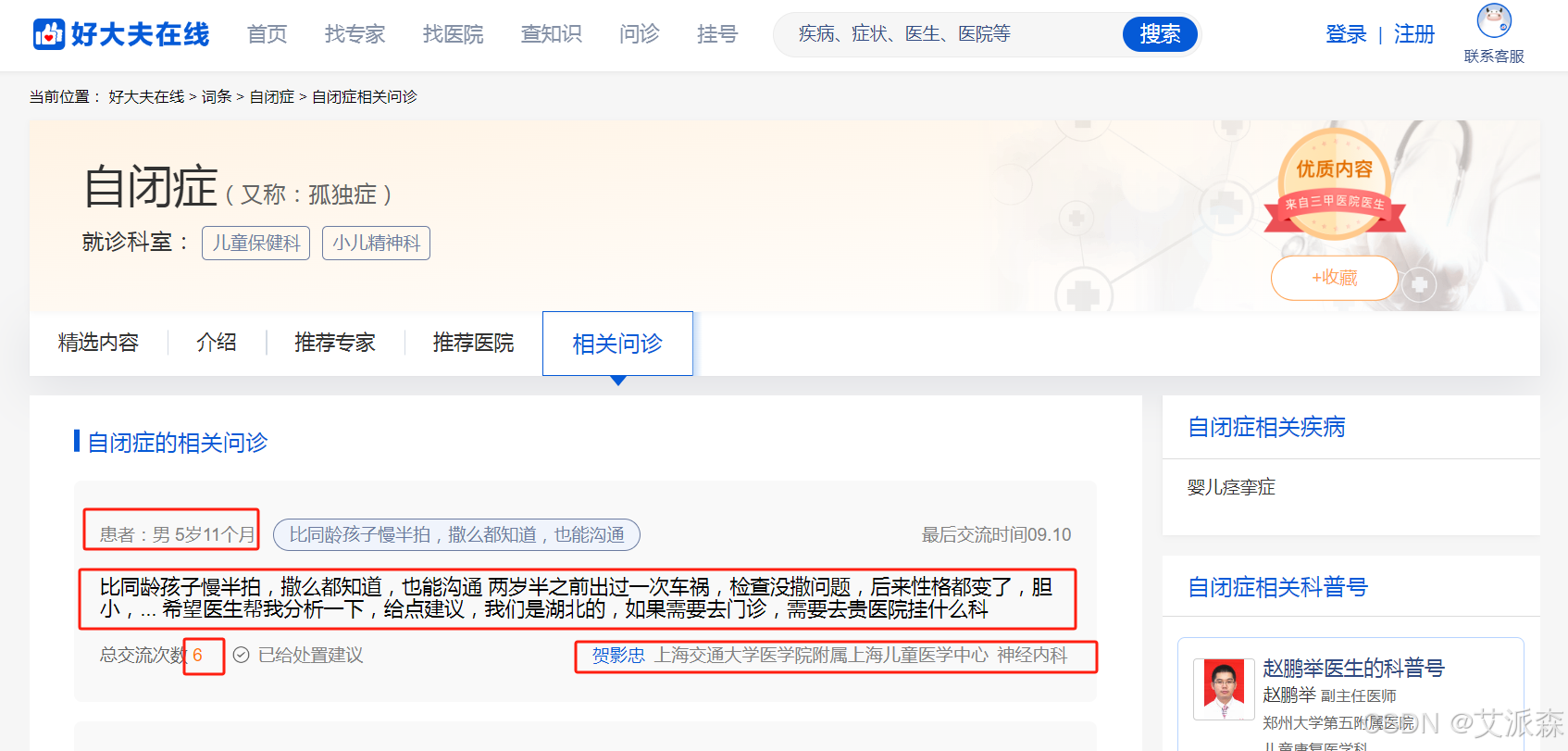

部分爬虫代码如下:(完整版请关注文末公主号后进q群领取)
import requests
from lxml import etree
import csv
import time
import random
def main(page):
cookies = {
'acw_tc': 'ddcc42ac17264803542016009e2feafef31e19332b0823318854f787b4',
'g': '46152_1726480354852',
'Hm_lvt_dfa5478034171cc641b1639b2a5b717d': '1726480356',
'HMACCOUNT': 'CE22B48046061130',
'g': 'HDF.84.66e60d45f038e',
'Hm_lpvt_dfa5478034171cc641b1639b2a5b717d': '1726480587',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
# 'cookie': 'acw_tc=ddcc42ac17264803542016009e2feafef31e19332b0823318854f787b4; g=46152_1726480354852; Hm_lvt_dfa5478034171cc641b1639b2a5b717d=1726480356; HMACCOUNT=CE22B48046061130; g=HDF.84.66e60d45f038e; Hm_lpvt_dfa5478034171cc641b1639b2a5b717d=1726480587',
'origin': 'https://www.haodf.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://www.haodf.com/citiao/jibing-zibizheng/bingcheng.html?p=4',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
data = {
'nowPage': page,
'pageSize': '15',
'diseaseId': '18',
}
response = requests.post('https://www.haodf.com/ndisease/ajaxLoadMoreWenzhen', cookies=cookies, headers=headers, data=data)
html_text = response.json()['data']['list']
html_text = f'<ul>{html_text}</ul>'
tree = etree.HTML(html_text)
li_list = tree.xpath('//ul/li')
for li in li_list:
info1 = li.xpath('./a/div/span[1]/text()')[0]
sex = info1.split(' ')[0].split(':')[1]
age = info1.split(' ')[1]
text = li.xpath('./a/h3/text()')[0].replace('\n','')
talk_num = li.xpath('./div/div[1]/span[1]/span[1]/text()')[0]
doctor = li.xpath('./div/div[2]/a[1]/text()')[0]
hospital = li.xpath('./div/div[2]/a[2]/text()')[0]
department = li.xpath('./div/div[2]/a[3]/text()')[0]
print(sex,age,text,talk_num,doctor,hospital,department)3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载数据集
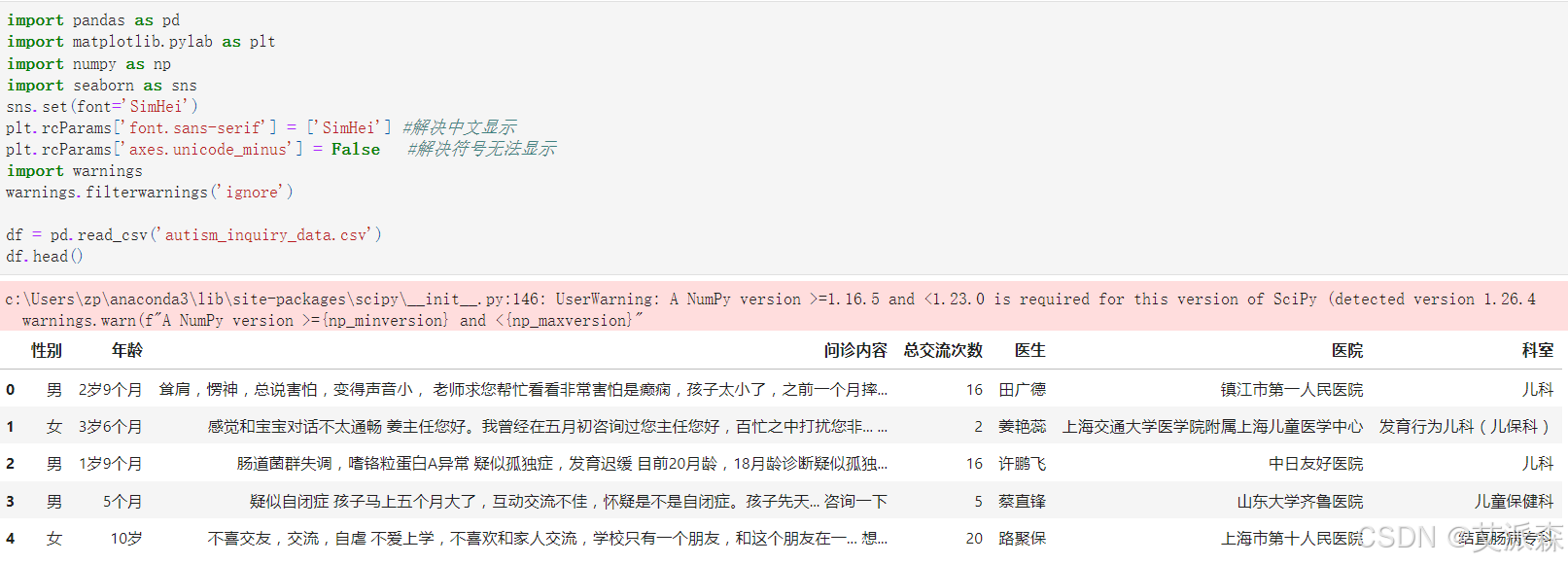
查看数据大小
查看数据基本信息
4.2数据预处理
统计数据缺失值情况

统计数据重复值情况
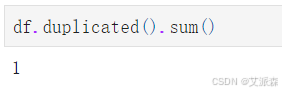
发现有一个重复数据,删除即可
![]()
处理年龄变量,这里自定义一个函数,基于患者年龄分为 6 个类别: 1 (0 ~ 3 岁)、 2 (4 ~ 6 岁)、 3 (7 ~ 9 岁)、 4 (10 ~ 14 岁)、 5 (15~ 19 岁)、 6 (20岁以上)

再次统计缺失值,因为上一步在处理年龄变量的时候将异常数据设置为空值
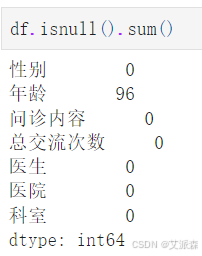
删除即可

最终还剩5903条有效数据
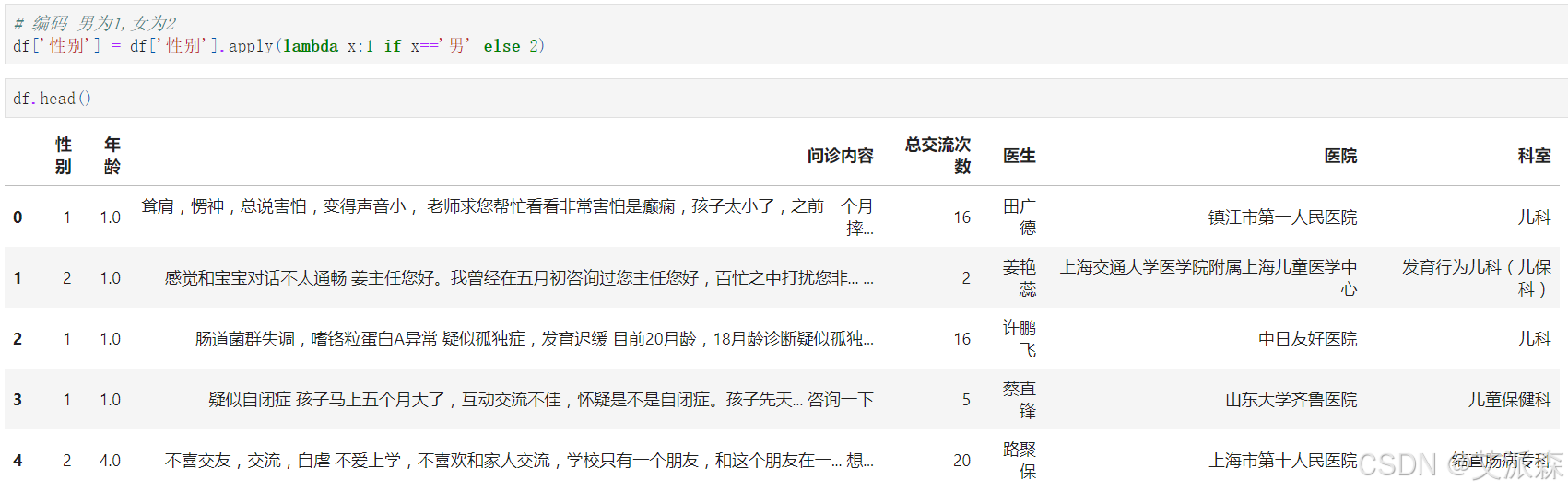
处理性别变量,性别分为两类: 1 (男)、 2 (女)。
4.3数据可视化
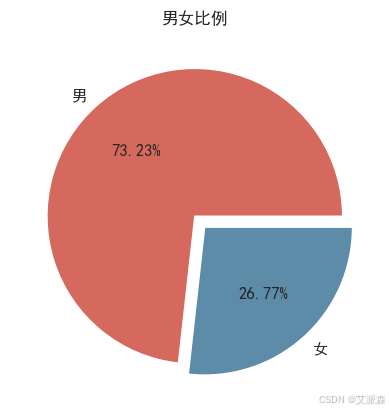
查看性别比例

查看年龄分布
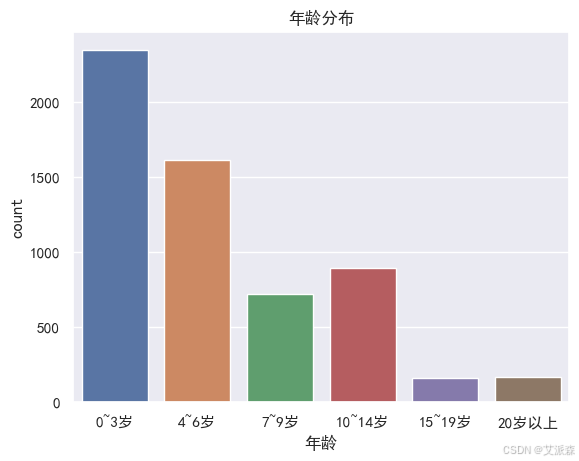
4.4LDA主题分析
首先自定义一个中文分词函数,在分词过程中剔除 “今天” “呢” “吗” 等无意义词汇, 将 “利培酮” “肠道菌群” “粪便移植” 等词添入字典提升分词准 确性。

调用函数进行分词
通常模型分类最优主题数根据困惑度大小决定, 但容易受噪声词汇干扰 , 因此采用主题一致性衡量主题数, 考虑主题中词汇之间相关性, 使主题质量评估更符合公众对主题的理解 。
做出主题一致性曲线
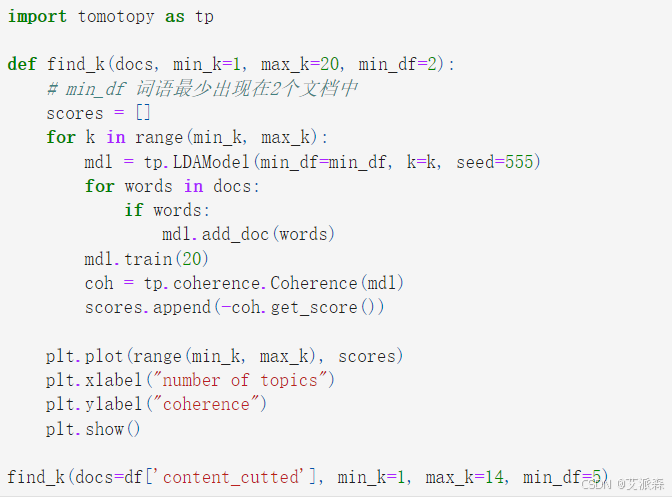
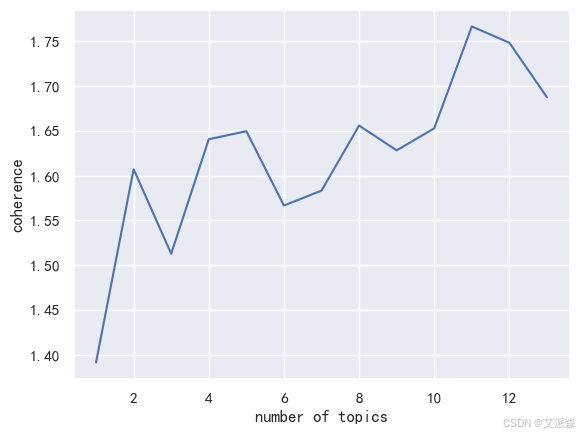
由上图可知,当主题数为 11 时, 一致性分数最大, 因此设定主题数为 11, 得出每个主题的主要内容。
令k=11训练lda主题模型


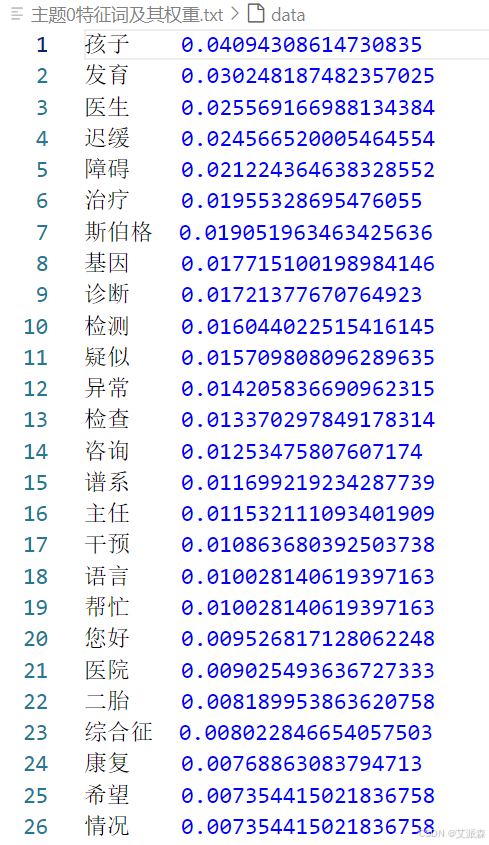
得到每个主题的特征词及其权重

<Basic Info>
| LDAModel (current version: 0.12.7)
| 5898 docs, 64809 words
| Total Vocabs: 8099, Used Vocabs: 1716
| Entropy of words: 6.32534
| Entropy of term-weighted words: 6.32534
| Removed Vocabs: <NA>
|
<Training Info>
| Iterations: 10, Burn-in steps: 0
| Optimization Interval: 10
| Log-likelihood per word: -7.38909
|
<Initial Parameters>
| tw: TermWeight.ONE
| min_cf: 0 (minimum collection frequency of words)
| min_df: 5 (minimum document frequency of words)
| rm_top: 0 (the number of top words to be removed)
| k: 11 (the number of topics between 1 ~ 32767)
| alpha: [0.1] (hyperparameter of Dirichlet distribution for document-topic, given as a single `float` in case of symmetric prior and as a list with length `k` of `float` in case of asymmetric prior.)
| eta: 0.01 (hyperparameter of Dirichlet distribution for topic-word)
| seed: 555 (random seed)
| trained in version 0.12.7
|
<Parameters>
| alpha (Dirichlet prior on the per-document topic distributions)
| [0.14759663 0.14284831 0.15131514 0.15687634 0.1418712 0.15016295
| 0.14765388 0.15163101 0.14869046 0.14630498 0.13527387]
| eta (Dirichlet prior on the per-topic word distribution)
| 0.01
|
<Topics>
| #0 (5967) : 孩子 发育 医生 迟缓 障碍
| #1 (5693) : 孩子 斯伯格 医生 焦虑 情绪
| #2 (5912) : 孩子 治疗 交流 说话 医生
| #3 (7354) : 发育 语言 迟缓 障碍 检查
| #4 (5417) : 孩子 情绪 说话 上学 治疗
| #5 (6126) : 孩子 语言 说话 宝宝 发育
| #6 (5804) : 孩子 情绪 医生 癫痫 发育
| #7 (6104) : 孩子 语言 发育 迟缓 不好
| #8 (5663) : 孩子 说话 宝宝 交流 一岁
| #9 (5517) : 孩子 情况 发育 喜欢 迟缓
| #10 (5252) : 孩子 障碍 谱系 语言 耐受
|
LDA主题可视化
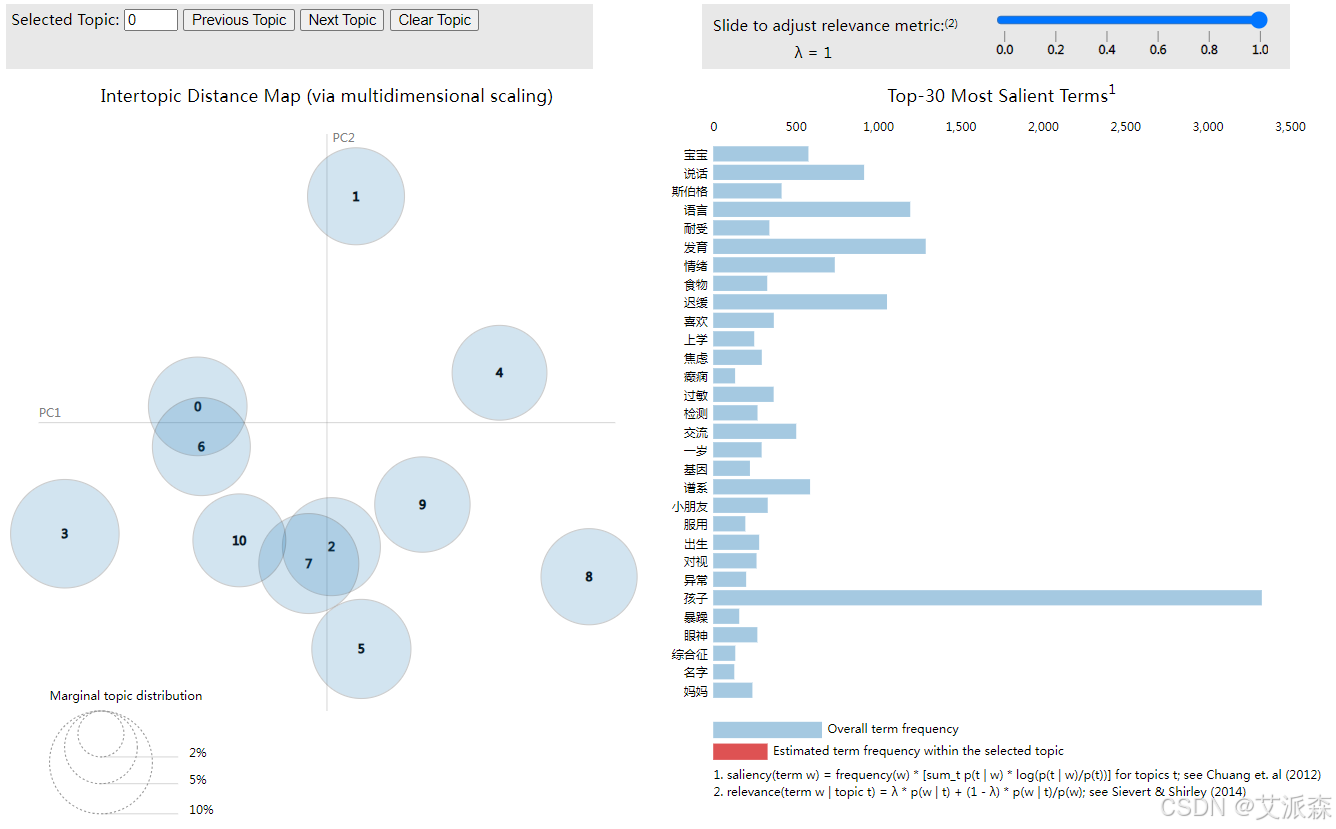
关于主题对应内容,大家可参考文献中的分析并结合自己的结果,得出主题对应内容
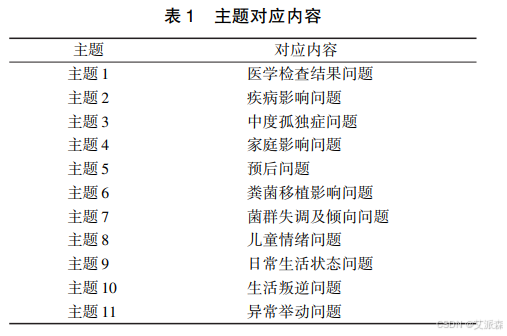
4.5Kmeas聚类
首先得出每个主题对应的标签
from gensim import corpora
data_set=[] #建立存储分词的列表
for i in range(len(df['content_cutted'].to_list())):
result=[]
seg_list = df['content_cutted'].to_list()[i].split()
for w in seg_list : #读取每一行分词
result.append(w)
data_set.append(result)
dictionary = corpora.Dictionary(data_set) # 构建词典
corpus = [dictionary.doc2bow(text) for text in data_set] #表示为第几个单词出现了几次
from gensim.models.ldamodel import LdaModel
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=11, passes = 30,random_state=1)
label_list = []
for i in lda.get_document_topics(corpus)[:]:
listj=[]
for j in i:
listj.append(j[1])
bz=listj.index(max(listj))
label_list.append(i[bz][0])
df['label'] = label_list
df.head()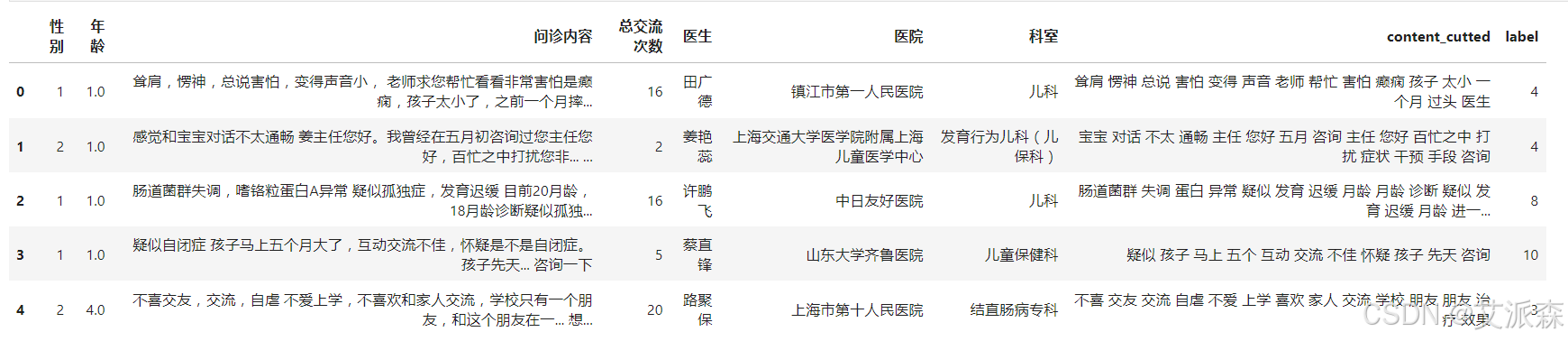
使用手肘法碎石图选定最优聚类数

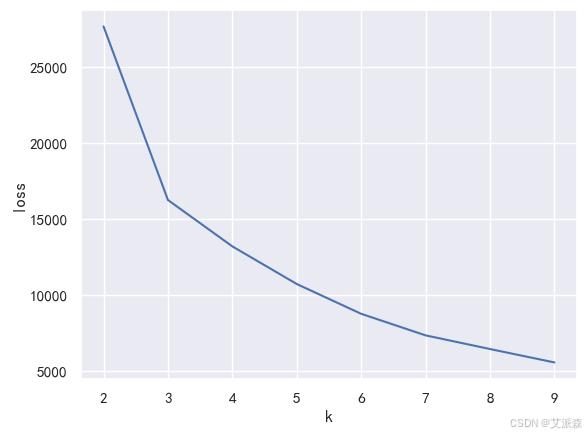
当 K > 3 时, SSE 的下降幅度放缓, 整图在此形成 “手肘” 状, 因此确定 K = 3 时 为最优聚类效果。
训练模型得出聚类标签

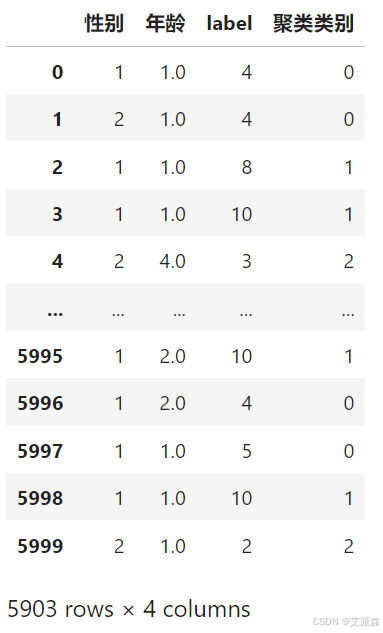
根据聚类结果,并使用词云图做出画像(词云图代码如需要请参考以前的文章)
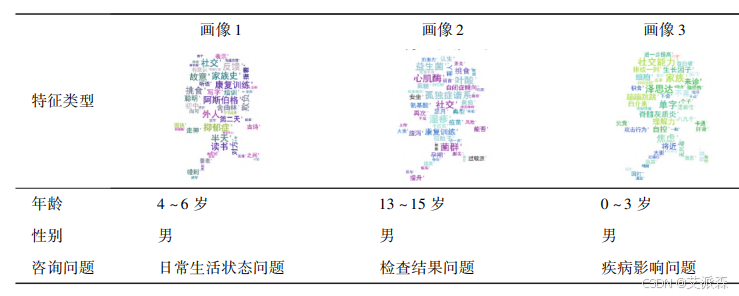
本次论文技术复现到这里结束! 复现的内容并不是很完整!如需源码或数据集请关注公主号【派森小木屋】!
源代码
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('autism_inquiry_data.csv')
df.head()
df.shape
df.info()
df.isnull().sum()
df.duplicated().sum()
df.drop_duplicates(inplace=True)
# 自定义一个处理年龄变量的函数
def dispose_age(x):
try:
if x[1] == '个':
return 1 # 0-3岁返回1
elif x[1] == '岁':
if 0 < int(x[0]) < 4:
return 1 # 0-3岁返回1
elif 4 <= int(x[0]) < 7:
return 2 # 4-6岁返回2
elif 7<= int(x[0]) < 10:
return 3 # 7-9岁返回3
elif x[2] == '岁':
if 10<= int(x[:2]) <15:
return 4 # 10-14岁返回4
elif 15<= int(x[:2]) <20:
return 5 # 15-19岁返回5
elif 20<= int(x[:2]):
return 6 # 20岁以上返回6
except:
return None # 不满足的异常数据设置为空值
df['年龄'] = df['年龄'].apply(dispose_age)
df['年龄']
df.isnull().sum()
df.dropna(inplace=True)
df.shape
# 编码 男为1,女为2
df['性别'] = df['性别'].apply(lambda x:1 if x=='男' else 2)
df.head()
y = df['性别'].value_counts().values.tolist()
plt.pie(y,
labels=['男','女'], # 设置饼图标签
colors=["#d5695d", "#5d8ca8"], # 设置饼图颜色
explode=(0, 0.1), # 第二部分突出显示,值越大,距离中心越远
autopct='%.2f%%', # 格式化输出百分比
)
plt.title("男女比例")
plt.show()
sns.countplot(data=df,x='年龄')
plt.xticks(range(6),['0~3岁','4~6岁','7~9岁','10~14岁','15~19岁','20岁以上'])
plt.title('年龄分布')
plt.show()
import re
import jieba
# 自定义分词函数
def chinese_word_cut(mytext):
jieba.load_userdict('dic.txt') # 这里你可以添加jieba库识别不了的新词,避免将一些新词拆开,例如将 “利培酮” “肠道菌群” “粪便移植” 等词添入字典提升分词准确性。
jieba.initialize()
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
# 中文分词
df["content_cutted"] = df['问诊内容'].apply(chinese_word_cut)
df.head()
import tomotopy as tp
def find_k(docs, min_k=1, max_k=20, min_df=2):
# min_df 词语最少出现在2个文档中
scores = []
for k in range(min_k, max_k):
mdl = tp.LDAModel(min_df=min_df, k=k, seed=555)
for words in docs:
if words:
mdl.add_doc(words)
mdl.train(20)
coh = tp.coherence.Coherence(mdl)
scores.append(-coh.get_score())
plt.plot(range(min_k, max_k), scores)
plt.xlabel("number of topics")
plt.ylabel("coherence")
plt.show()
find_k(docs=df['content_cutted'], min_k=1, max_k=14, min_df=5)
import tomotopy as tp
# 初始化LDA
mdl = tp.LDAModel(k=11, min_df=5, seed=555)
for words in df['content_cutted']:
#确认words 是 非空词语列表
if words:
mdl.add_doc(words=words.split())
#训 练
mdl.train()
# 查看每个topic feature words
wordcloud_words = []
for k in range(mdl.k):
with open(f'主题{k}特征词及其权重.txt','w',encoding='utf-8')as f:
print('Top 20 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=25))
for item in mdl.get_topic_words(k, top_n=50): # 将主题的前50个特征词及其权重进行保存
f.write(str(item[0]))
f.write('\t')
f.write(str(item[1]))
f.write('\n')
# 查看话题模型信息
mdl.summary()
import pyLDAvis
import numpy as np
# 在notebook显示
pyLDAvis.enable_notebook()
# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freq
prepared_data = pyLDAvis.prepare(
topic_term_dists,
doc_topic_dists,
doc_lengths,
vocab,
term_frequency,
start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始
sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)
# 可视化结果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis.html')
# notebook中显示
pyLDAvis.display(prepared_data)
from gensim import corpora
data_set=[] #建立存储分词的列表
for i in range(len(df['content_cutted'].to_list())):
result=[]
seg_list = df['content_cutted'].to_list()[i].split()
for w in seg_list : #读取每一行分词
result.append(w)
data_set.append(result)
dictionary = corpora.Dictionary(data_set) # 构建词典
corpus = [dictionary.doc2bow(text) for text in data_set] #表示为第几个单词出现了几次
from gensim.models.ldamodel import LdaModel
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=11, passes = 30,random_state=1)
label_list = []
for i in lda.get_document_topics(corpus)[:]:
listj=[]
for j in i:
listj.append(j[1])
bz=listj.index(max(listj))
label_list.append(i[bz][0])
df['label'] = label_list
df.head()
from sklearn.cluster import KMeans
new_df = df[['性别','年龄','label']]
# 肘部法则
loss = []
for i in range(2,10):
model = KMeans(n_clusters=i).fit(new_df)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
k=3
kmodel=KMeans(n_clusters=k)#创建聚类模型
kmodel.fit(new_df)#训练模型
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r=pd.concat([r2,r1],axis=1)
r.columns=list(new_df.columns)+[u'聚类数量']
r3=pd.Series(kmodel.labels_,index=new_df.index)#类别标记
r=pd.concat([new_df,r3],axis=1)#数据合并
r.columns=list(new_df.columns)+[u'聚类类别']
r
r.groupby(by=['聚类类别','性别'])['性别'].count()
r.groupby(by=['聚类类别','年龄'])['性别'].count()
r.groupby(by=['聚类类别','label'])['性别'].count()
资料获取,更多粉丝福利,关注下方公众号获取



















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











