






摘要:扩散模型在各类图像生成任务中已展现出卓越成效,但其性能常受限于在不同条件和噪声水平下对输入进行统一处理的方式。为克服这一局限,我们提出了一种创新方法,该方法充分利用了扩散过程的内在异质性。我们的方法——DiffMoE,引入了一个批次级别的全局令牌池,使专家在训练过程中能够访问全局令牌分布,从而促进专家行为的专门化。为充分挖掘扩散过程的潜力,DiffMoE还整合了一个容量预测器,该预测器能够根据噪声水平和样本复杂度动态分配计算资源。通过全面评估,DiffMoE在ImageNet基准测试中取得了扩散模型的最优性能,在保持激活参数为1倍的情况下,显著超越了参数激活量为3倍的密集架构以及现有的专家混合(Mixture of Experts, MoE)方法。我们方法的有效性不仅体现在类别条件生成任务上,还延伸至更具挑战性的任务,如文本到图像的生成,这证明了其在不同扩散模型应用中的广泛适用性。项目页面:DiffMoE,Huggingface链接:Paper page,论文链接:2503.14487
研究背景和目的
研究背景
近年来,扩散模型(Diffusion Models)在图像生成领域取得了显著的成功。它们通过逐步去噪过程,从高斯噪声中生成高质量的图像,展现了强大的生成能力。然而,尽管扩散模型在性能上不断提升,其计算效率和可扩展性仍然面临挑战。特别是在处理高分辨率图像时,扩散模型需要处理大量的输入令牌,导致计算成本急剧增加。此外,现有的扩散模型在处理不同条件和噪声水平的输入时,通常采用统一的处理方式,未能充分利用扩散过程的内在异质性。
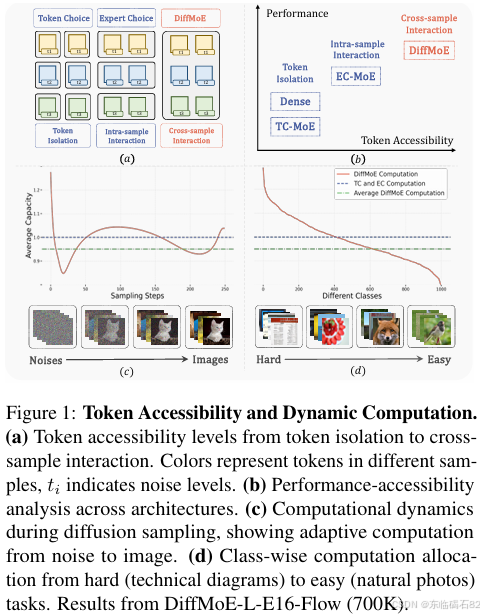
针对这些问题,研究者们开始探索如何提高扩散模型的计算效率和可扩展性。其中,一种有效的方法是引入专家混合(Mixture of Experts, MoE)架构。MoE架构通过引入多个专家网络,并根据输入的不同特点动态选择专家进行处理,从而在保持性能的同时减少计算开销。然而,现有的MoE方法在扩散模型中的应用仍存在诸多限制,如令牌访问受限、计算模式固定等,导致这些方法未能充分发挥其潜力。
研究目的
本研究旨在提出一种新颖的MoE架构——DiffMoE,以解决现有扩散模型在计算效率和可扩展性方面的挑战。DiffMoE通过引入批次级别的全局令牌池和容量预测器,使专家能够访问全局令牌分布,并根据噪声水平和样本复杂度动态分配计算资源。通过这种方法,DiffMoE能够在保持生成质量的同时,显著提高计算效率和可扩展性。此外,本研究还旨在验证DiffMoE在不同扩散模型应用中的广泛适用性,包括类别条件生成和文本到图像生成等任务。
研究方法
DiffMoE架构概述
DiffMoE架构的核心思想是在扩散模型的自注意力机制中引入MoE层。具体来说,DiffMoE将输入令牌展平为一个批次级别的全局令牌池,使每个专家能够访问整个批次中的令牌分布。在训练过程中,专家根据令牌的重要性动态选择令牌进行处理,从而促进专家行为的专门化。
为了充分利用扩散过程的内在异质性,DiffMoE还整合了一个容量预测器。该预测器能够根据噪声水平和样本复杂度动态分配计算资源。具体来说,容量预测器通过学习训练期间的令牌路由模式,为不同的专家和推理步骤分配不同的计算资源。在推理过程中,容量预测器根据当前的输入令牌和噪声水平,动态调整专家的计算容量,从而实现灵活的性能与计算权衡。
动态令牌选择
在DiffMoE中,动态令牌选择是实现高效计算的关键。通过引入全局令牌池和容量预测器,DiffMoE能够在训练过程中让专家访问全局令牌分布,并学习如何根据令牌的重要性动态选择令牌进行处理。在推理过程中,容量预测器根据当前的输入令牌和噪声水平,动态调整专家的计算容量,从而在不牺牲生成质量的情况下减少计算开销。
模型训练与评估
在训练过程中,DiffMoE采用教师-学生蒸馏(Teacher-Student Distillation)的方法。具体来说,我们首先训练一个全专家(Full-Expert)的扩散模型作为教师模型。然后,我们使用教师模型的输出来训练DiffMoE模型,通过最小化DiffMoE模型的输出与教师模型输出之间的差异来优化模型参数。
为了评估DiffMoE的性能,我们在ImageNet基准测试上进行了全面的实验。我们比较了DiffMoE与现有方法(包括密集架构和现有的MoE方法)在类别条件生成任务上的性能。此外,我们还验证了DiffMoE在文本到图像生成任务上的适用性。
研究结果
实验设置与基线模型
在实验设置中,我们采用了多种基线模型进行比较,包括密集架构(Dense Models)、令牌选择MoE(Token-Choice MoE, TC-MoE)和专家选择MoE(Expert-Choice MoE, EC-MoE)。为了公平比较,我们重新实现了TC-MoE和EC-MoE,并保持了与DiffMoE相同的激活计算量。
主要结果
在类别条件生成任务上,DiffMoE在ImageNet基准测试上取得了最优的性能。具体来说,DiffMoE-L-E16-Flow模型在FID分数上达到了14.41(无分类器自由引导),显著超越了密集架构和现有的MoE方法。此外,DiffMoE还展示了出色的参数效率和可扩展性。通过增加模型规模和专家数量,DiffMoE能够持续提高生成质量,同时保持较低的计算成本。
在文本到图像生成任务上,DiffMoE也展示了卓越的性能。与密集模型相比,DiffMoE在多个评估指标上均取得了显著的提升。特别是在没有监督微调(Supervised Fine-Tuning, SFT)的情况下,DiffMoE仍然能够生成高质量的图像。
动态计算分析
我们还对DiffMoE的动态计算特性进行了深入分析。实验结果表明,DiffMoE能够根据样本的复杂度和噪声水平动态调整计算资源。具体来说,对于复杂的样本和较低的噪声水平,DiffMoE会分配更多的计算资源进行处理;而对于简单的样本和较高的噪声水平,DiffMoE则会减少计算资源的分配。这种动态计算特性使得DiffMoE能够在保持生成质量的同时,显著降低计算成本。
研究局限
尽管DiffMoE在扩散模型的计算效率和可扩展性方面取得了显著的提升,但仍然存在一些局限性。首先,DiffMoE的训练过程相对复杂,需要引入额外的容量预测器和全局令牌池。这增加了模型的训练难度和计算成本。其次,DiffMoE的性能仍然受到专家数量和模型规模的影响。尽管通过增加专家数量和模型规模可以提高生成质量,但这也会增加计算成本。因此,如何在保持性能的同时进一步降低计算成本是未来研究的重要方向。
未来研究方向
针对上述研究局限,我们提出了以下几个未来研究方向:
- 优化训练过程:探索更高效的训练方法来降低DiffMoE的训练难度和计算成本。例如,可以采用预训练或知识蒸馏等技术来加速训练过程。
- 提高模型效率:进一步研究如何在保持性能的同时降低DiffMoE的计算成本。例如,可以采用量化、剪枝或低秩分解等技术来压缩模型参数和减少计算量。
- 拓展应用场景:将DiffMoE应用于更广泛的扩散模型应用场景中,如视频生成、音频生成等。通过探索DiffMoE在不同任务中的适用性,可以进一步验证其泛化能力和实用价值。
- 结合其他技术:将DiffMoE与其他先进技术相结合,如自监督学习、强化学习等。通过结合多种技术,可以进一步提高DiffMoE的性能和适用性。

















 4340
4340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









