







一、背景简介:图像去雾的“老大难”
现实世界中,雾霾天气对图像质量影响极大,不仅视觉效果差,还影响目标检测等下游任务。
传统图像去雾方法一般分为两类:
-
基于物理模型:如经典的暗通道先验(DCP)、BCCR等,这类方法通过手工设计的物理规律逆推还原清晰图像。但问题是:一旦遇到复杂场景,先验就失效了。
-
基于深度学习的有监督方法:如 DehazeFormer、C2PNet 等,依赖合成的有雾-无雾图像对训练神经网络,效果不错,但泛化能力差(合成的毕竟不是现实中的雾)。
于是,“无监督图像去雾”应运而生:不用成对的数据,用 CycleGAN 等结构从未配对的有雾图和清晰图中学习映射,典型如 D4、ODCR 等。但它们的表达能力还是不够强——于是本文来了。
二、核心创新:Diff-Dehazer 做了哪些事?
作者提出的 Diff-Dehazer 是一个结合了“扩散模型 + 无监督训练 + 多模态引导 + 物理先验”的新架构。它的核心创新有以下四点:
1. 引入 Stable Diffusion 模型作为 CycleGAN 的主干
利用预训练好的 Stable Diffusion Turbo (SD Turbo) 作为映射器,建立 hazy ↔ clear 的循环结构。用 LoRA 微调,保留大模型能力的同时避免训练开销过大。
2. 加入 物理先验指导(Physics-Aware Guidance, PAG)
引入经典方法(DCP + BCCR)生成传输图和大气光,计算物理重建损失,使得网络更符合真实物理规律,提升泛化性。
3. 融合 文本引导(Text-Aware Guidance, TAG)
用 BLIP-2 给输入图像生成描述(可自定义),通过文本提示(Prompt)控制去雾过程的语义方向。例如把“foggy street”→“clean street”。
特别之处:不仅使用正向提示,还通过Textual Inversion 学习雾的隐性特征,作为负向 prompt,二者配合进一步增强控制力。
4. 构建一个 现实无配对数据集
包含 6,519 张真实雾图 + 11,293 张清晰图,用于无监督训练,提升实验可信度和复现性。
三、方法细节简要拆解
1. 结构框架
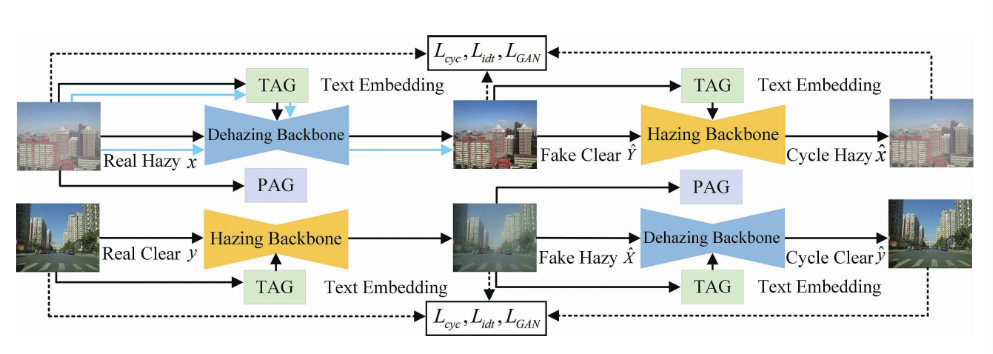
图一 模型框架图,黑色箭头表示训练过程,蓝色箭头表示测试过程
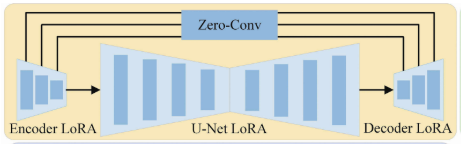
图二 框架的骨干网络
-
采用 CycleGAN 架构:雾图 → 清晰图 → 恢复为雾图(Cycle Consistency)
-
生成器:使用 LoRA 微调的 SD Turbo 模型(包含 VAE 编码器 + UNet + 解码器)
-
跳跃连接保留细节信息,避免信息损失
2. TAG:文本引导如何做?
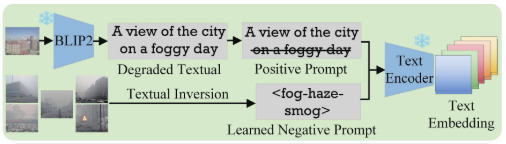
图三 文本感知指导图
-
使用 BLIP-2 对图像进行自动描述
-
删除如 haze/fog 词汇,作为正向 prompt
-
通过 Textual Inversion 训练雾的负向 prompt,进行对抗引导
-
正负 prompt 结合,用于图像/文本双模态的 classifier-free guidance
3. PAG:物理先验如何整合?
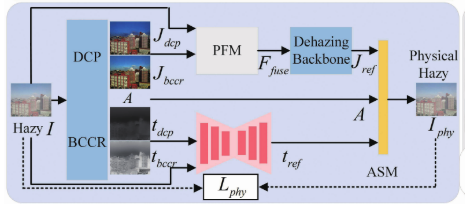
图四 物理先验指导图
-
利用 DCP 和 BCCR 生成两个清晰图,再通过 Perceptual Fusion Model (PFM) 进行融合
-
构建一个更可靠的清晰图
,通过大气散射模型
还原雾图
-
引入物理重建损失
四、实验结果一览
1. 数据集
-
训练集:从 RESIDE、ADE20K 等收集真实雾图和清晰图,构建无配对数据集
-
测试集:RTTS、Haze2020、OHAZE、NHAZE、Fattal 等多个真实数据集
2. 评估指标
-
无参考:FID、NIQE、MUSIQ、CLIPIQA
-
有参考:PSNR、SSIM、LPIPS、VSI
3. 结果总结
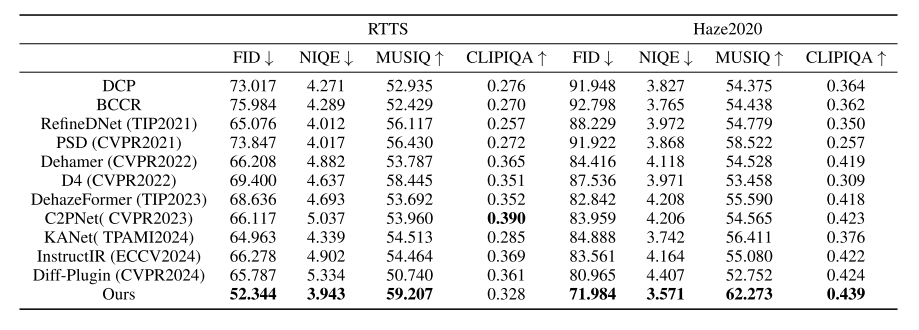
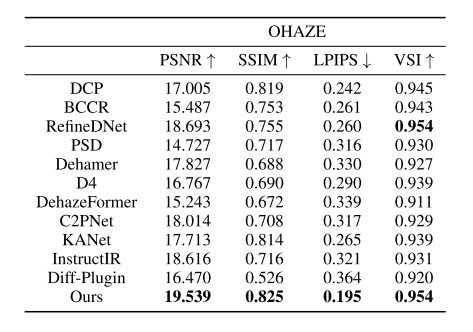
-
在 Haze2020、RTTS、OHAZE 等真实数据集上全面超越现有SOTA方法
-
和 D4、RefineDNet 等无监督方法相比效果更好
-
和 C2PNet、DehazeFormer 等有监督方法相比,在真实场景更稳定
-
ablation 实验证明 PAG 和 TAG 模块都显著提升性能
五、总结:为什么这篇论文值得关注?
无监督框架 + 扩散模型:首次将 Stable Diffusion 与无监督图像去雾深度融合
多模态引导:文本+图像联合建模,提供更强的语义控制
物理建模结合深度学习:补足了深度模型对真实雾场景的理解不足
效果实打实领先:无论主观视觉还是客观指标,都表现出色
六、论文的不足与未来方向
虽然本文提出的 Diff-Dehazer 在多个方面都有突破,但也存在一些不可忽视的不足之处:
1. 推理过程不够可控,存在“扩散模型的副作用”
由于扩散模型本身具有一定的生成随机性,尤其是在使用 classifier-free guidance 引导时,可能会生成与输入场景不完全一致的内容(例如纹理细节或结构轻微失真),尤其在雾非常浓重、内容模糊的图像中更容易出现偏差。
✅ 虽然作者引入了物理先验和正负 prompt 控制来缓解这个问题,但根源还在于扩散模型本身的泛化策略。
2. 网络整体偏复杂,训练和部署门槛较高
引入了 LoRA 微调、两阶段物理引导(DCP+BCCR)、多模态提示(文本)、图像融合(PFM)等多个模块,使得整个系统结构较复杂。
-
推理速度和部署成本相对高
-
微调过程对算力也有一定要求,可能不太适合轻量级场景或边缘设备部署
3. 对“文本引导”的可靠性仍存疑
虽然 BLIP-2 + prompt 构造的方式提升了语义表达能力,但:
-
自动生成的 caption 有时不准确,尤其在雾重/光线差/遮挡物多的图片中
-
文本引导更多起到锦上添花的作用,对结构信息帮助有限,对复杂结构保持不如 Transformer-based 去雾网络那样稳定
4. 缺乏对多个先验融合方式的对比实验
虽然作者提出使用 DCP 和 BCCR 再经过 PFM 融合,但没有和其他融合策略(比如 attention-based fusion、分区域加权)进行对比。缺乏这部分实验,略显仓促。
如果你觉得这篇解析有帮助,欢迎点赞、收藏、评论支持我呀!你的一点鼓励,就是我继续整理论文的最大动力!

















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









