







一、背景与动机
- 雾霾现象对图像的影响:雾霾天气会使得图像失去清晰度,增加图像的噪声,影响视觉理解和图像处理任务的性能。去雾(Dehazing)是图像处理中的一个重要任务。
- 传统方法的局限性:早期的去雾方法多依赖物理模型,如大气散射模型,或者使用图像增强技术,然而这些方法在处理复杂的场景时效果有限,且常常忽视了图像中的深层特征。
- 深度学习在图像去雾中的应用:近年来,卷积神经网络(CNN)在图像去雾中取得了显著进展,但CNN的局部感受野和参数共享限制了它在长距离依赖建模上的能力。
- 视觉变换器的优势:视觉变换器能够通过自注意力机制捕捉全局依赖,这使得它们在处理去雾任务时具有潜力。
二、模型架构与主要板块
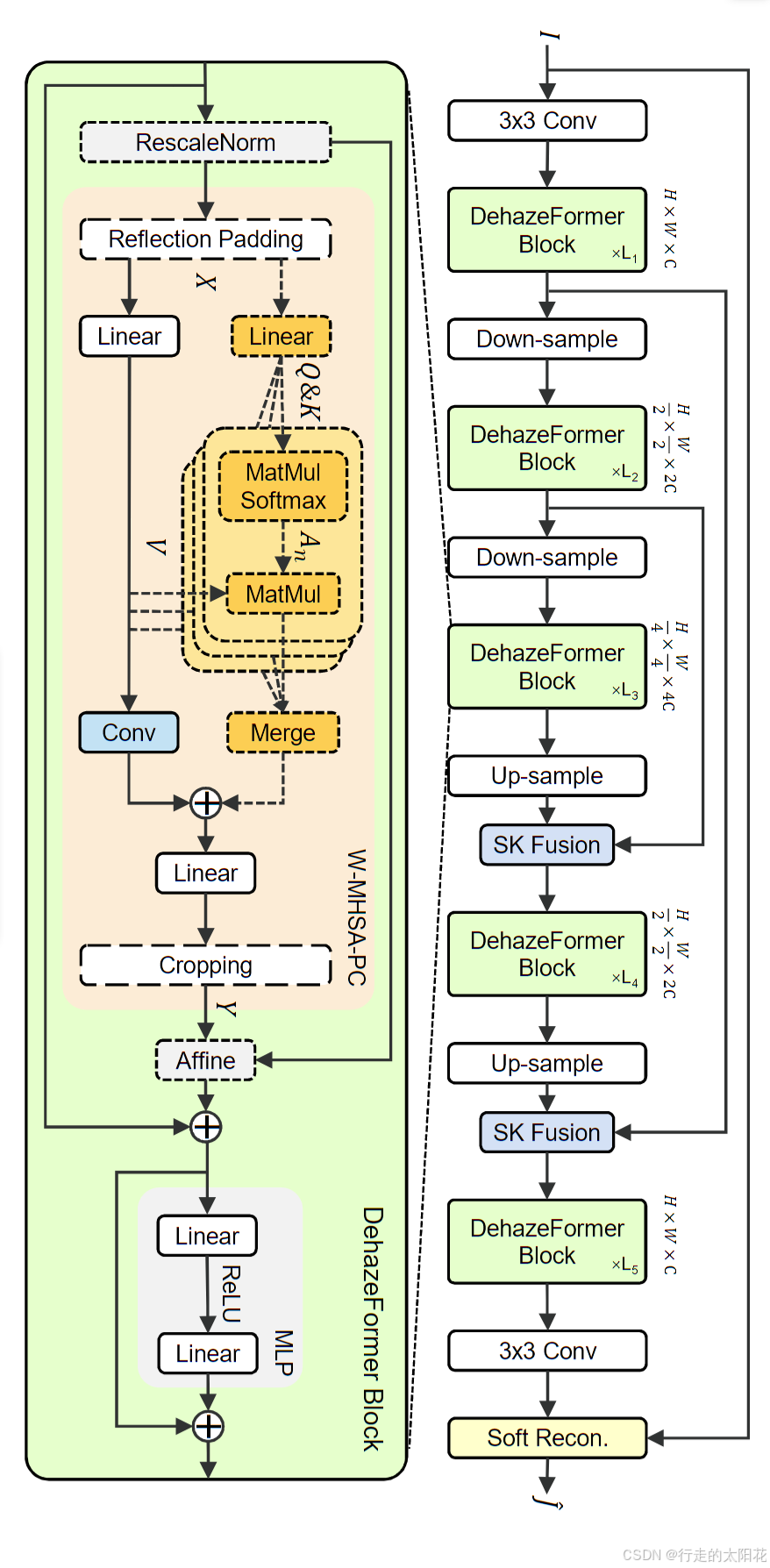
架构图如下图所示
1、改进版的层归一化(Revised LayerNorm, RLN)
公式
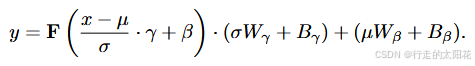
1.1 RLN 针对图像去雾任务进行了调整,主要体现在以下几点:
(1)针对图像特性设计:
- 图像的每个像素值会受到邻近像素和整体光照的影响,因此需要考虑整个图像区域的均值和标准差,而不仅仅是特征维度的数值。
- RLN 的归一化操作更适合处理二维图像特征(Height × Width × Channel),让归一化结果更贴合图像特性。
(2)动态调整归一化参数:
- RLN 通过两个小型的卷积网络(
meta1和meta2)对标准差和均值进行动态调整:meta1:根据标准差(std)生成动态缩放因子(rescale)。meta2:根据均值(mean)生成动态偏移量(rebias)。
- 动态调整的好处是,模型可以根据图像的局部特性(例如雾浓或雾淡的区域)灵活地改变归一化后的特征值。
(3)支持梯度分离(detach_grad):
- RLN 可以选择让
meta1和meta2的输入(std 和 mean)不参与梯度计算(detach_grad=True)。这样可以避免标准差或均值变化对训练过程带来的不稳定性。
1.2 RLN相对于LN的主要特点
(1)动态调整尺度和平移参数
- 传统LN:在标准化之后,使用固定的缩放因子(
gamma)和偏置项(beta)对特征进行重新缩放和平移。这两个参数是通过反向传播学习得到的,并在整个训练过程中保持不变。 - RLN:引入了额外的卷积层 (
meta1和meta2) 来动态计算每个样本的尺度和平移参数。具体来说,meta1根据输入的标准差生成尺度参数,而meta2则根据均值生成偏置项。这意味着RLN可以根据输入数据的具体分布来调整归一化的结果,从而更好地适应不同的输入模式。
(2)可选的梯度分离
- RLN 提供了一个名为
detach_grad的选项,允许用户选择是否将标准差和均值的计算从主梯度流中分离出来。如果启用了这个选项,则在计算rescale和rebias时会使用.detach()方法,这可以防止这些计算影响到上游梯度的传播,有助于稳定训练过程,特别是在某些复杂或不稳定的学习场景下。
(3)实现方式上的差异
- 传统LN 通常直接作用于张量的最后一维(即通道维度),并对所有样本和空间位置共享相同的统计信息(均值和方差)。
- RLN 在计算均值和标准差时考虑了所有维度(包括批量、高度和宽度),并且为每个样本单独计算这些统计量。此外,它还通过额外的卷积层生成个性化的尺度和平移参数,这使得RLN更加灵活和强大。
1.3 一个简单类比
可以把 RLN 理解为一个智能的“图像调色师”:
- 普通调色师(LayerNorm):对每张图像用固定比例(均值和标准差)调亮或调暗。
- 智能调色师(RLN):会先观察图像整体,然后根据每张图像的具体特点动态调整调色比例,做到“浓雾淡化、细节增强”。
1.4 效果对比展示

我们发现当使用LayerNorm作为激活函数时,可以清楚地看到重建图像中出现的块伪影。
该部分代码如下:
class RLN(nn.Module):
r"""Revised LayerNorm"""
def __init__(self, dim, eps=1e-5, detach_grad=False):
super(RLN, self).__init__()
self.eps = eps
self.detach_grad = detach_grad
self.weight = nn.Parameter(torch.ones((1, dim, 1, 1)))
self.bias = nn.Parameter(torch.zeros((1, dim, 1, 1)))
self.meta1 = nn.Conv2d(1, dim, 1)
self.meta2 = nn.Conv2d(1, dim, 1)
trunc_normal_(self.meta1.weight, std=.02)
nn.init.constant_(self.meta1.bias, 1)
trunc_normal_(self.meta2.weight, std=.02)
nn.init.constant_(self.meta2.bias, 0)
def forward(self, input):
mean = torch.mean(input, dim=(1, 2, 3), keepdim=True) # keepdim=True操作后的输出张量会保留输入张量的维度
std = torch.sqrt((input - mean).pow(2).mean(dim=(1, 2, 3), keepdim=True) + self.eps)
normalized_input = (input - mean) / std
if self.detach_grad:
rescale, rebias = self.meta1(std.detach()), self.meta2(mean.detach())
else:
rescale, rebias = self.meta1(std), self.meta2(mean)
out = normalized_input * self.weight + self.bias
return out, rescale, rebias2、使用反射填充的窗口分区 (Shifted Window Partitioning with Reflection Padding)
论文中提出的一种新的技术,它结合了窗口划分(window partitioning)和反射填充(reflection padding),并在此基础上进行了“窗口平移”(shifted window)操作。为了理解它与传统填充窗口方法的区别,首先需要了解这两个概念。
2.1 窗口划分(Window Partitioning):
窗口划分通常是在图像处理中的一种常见策略,特别是在卷积操作中。它将图像划分为多个小的窗口,每个窗口都独立进行操作,通常用于局部特征的提取。在卷积神经网络(CNN)中,传统的卷积操作就是基于滑动窗口的方法。
2.2 反射填充(Reflection Padding):
在窗口划分过程中,当处理图像的边缘时,传统填充方法(如零填充、常数填充)可能会导致边缘的处理效果不理想。反射填充通过反射图像边缘的像素来填充图像的边界区域,可以更好地保持图像的边缘信息和平滑过渡。
2.3 Shifted Window Partitioning with Reflection Padding的概念:
论文提出的“Shifted Window Partitioning with Reflection Padding”技术结合了反射填充和窗口划分的优点,并进行了平移操作(shifted)。
-
窗口划分 + 反射填充:将图像分成多个小窗口并进行反射填充,在每个窗口内执行卷积或其他操作。反射填充保证了边缘部分的信息不会丢失,窗口划分则帮助模型处理局部区域的信息。
-
平移操作(Shifted Window):传统的窗口划分方法通常是固定的,即窗口按照一定的步长在图像上滑动。然而,“Shifted Window Partitioning”方法在每次划分窗口时,会对窗口进行一定的平移(shift),这可以通过不同的窗口位置来避免信息的丢失和冗余。
- 具体而言,Shifted Window的策略可以让模型捕获更多的上下文信息。通过平移窗口,窗口之间能够交叉重叠,确保更全面的特征提取,尤其在图像的细节和边缘部分。
2.4 与传统填充窗口的区别:
-
填充策略的不同:传统的窗口划分方法通常使用零填充(Zero Padding)或常数填充,这可能会在图像边缘产生不自然的效果。反射填充则避免了这一点,通过反射周围像素来填充边缘,使得图像边缘更加平滑自然。
-
窗口划分的平移:传统的窗口划分方法通常是固定的,每个窗口独立操作,没有相邻窗口之间的交叉。Shifted Window Partitioning通过对窗口进行平移,确保了不同窗口之间的重叠,增强了信息的捕捉能力,尤其是在局部特征和细节提取方面。
-
边缘信息的保留:传统方法在边缘部分的特征提取可能较弱,特别是使用零填充时,边缘的有效信息可能丢失。反射填充通过确保边缘部分的平滑过渡,可以更好地保留边缘信息,使得去雾或其他视觉任务的表现更好。
-
全局和局部信息的平衡:通过Shifted Window Partitioning方法,模型能够在保持局部特征提取的同时,也能够获得更多全局上下文信息。这种平移窗口的策略可以帮助模型更好地处理复杂的图像,尤其是在去雾任务中。
2.5 这种方法的功能和作用:
- 细节恢复:通过反射填充和窗口平移,模型能够更好地恢复图像的细节,特别是在图像的边缘部分,从而提升去雾效果。
- 防止信息丢失:平移窗口能够确保不同区域的信息得到充分提取,而反射填充确保边缘信息不丢失,避免了传统零填充带来的信息丢失问题。
- 更好的全局和局部信息融合:平移窗口的设计使得模型能够有效融合全局信息与局部信息,从而在复杂的视觉任务中获得更强的表现。
该部分代码如下:
def check_size(self, x, shift=False):
_, _, h, w = x.size()
mod_pad_h = (self.window_size - h % self.window_size) % self.window_size
mod_pad_w = (self.window_size - w % self.window_size) % self.window_size
if shift: #额外填充,模拟平移窗口的效果
x = F.pad(x, (self.shift_size, (self.window_size - self.shift_size + mod_pad_w) % self.window_size,
self.shift_size, (self.window_size - self.shift_size + mod_pad_h) % self.window_size),
mode='reflect')
else: #只进行简单的边界填充
x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
return x3、具有并行卷积的W-MHSA (W-MHSA with Parallel Convolution)
该模型的一个重要创新,它结合了窗口多头自注意力(Window Multi-Head Self Attention, W-MHSA)和并行卷积(Parallel Convolution),并且通过这种设计提升了模型的去雾性能。
3.1 W-MHSA(Window Multi-Head Self Attention):
W-MHSA是一种自注意力机制,它是对传统自注意力(Self Attention)的改进,主要应用于视觉变换器(Vision Transformers,ViT)中。W-MHSA将图像分割成多个窗口(window),然后在每个窗口内独立地进行自注意力计算。
- 自注意力(Self Attention):传统的自注意力机制对整个图像的每个像素进行计算,以捕捉图像中所有像素之间的依赖关系。这虽然能够捕捉到全局的关系,但计算量非常大,尤其是在高分辨率图像上。
- 窗口化(Windowing):W-MHSA通过将图像分割成多个小窗口,在每个窗口内独立地进行自注意力计算,从而显著减少计算量。每个窗口内的像素之间进行关系建模,这样可以在局部区域内有效捕捉信息。
- 优点:这种方法减少了全局计算的复杂度,提高了效率,适用于大规模图像处理。
3.2 并行卷积(Parallel Convolution):
并行卷积是指将卷积操作与其他操作(如自注意力)并行处理,而不是将其串行执行。这样可以充分利用硬件资源,提高模型的计算效率。
- 在传统的卷积神经网络(CNN)中,卷积层通常是逐层执行的,这会带来一定的计算瓶颈。而并行卷积通过将多个卷积操作并行化,使得计算能够更高效地进行,减少了等待时间。
- 在图像去雾任务中,卷积操作能够有效提取局部特征,而与自注意力机制的结合可以增强模型对局部和全局信息的处理能力。
3.3 W-MHSA with Parallel Convolution 的组合:
空间聚合公式
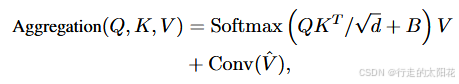
其中 V ∈ Rb×h×w×c 表示窗口划分之前的 V,Conv(·) 可以是 DWConv 或 ConvBlock (Conv-ReLU-Conv)。
在这篇论文中,W-MHSA with Parallel Convolution结合了窗口化的自注意力机制和并行卷积操作,从而兼顾了计算效率和特征提取能力。
- 窗口化自注意力减少了计算复杂度,通过在每个窗口内进行自注意力计算,提升了局部特征的提取能力。
- 并行卷积确保了卷积操作能够与自注意力机制并行运行,提高了计算效率。
- 并行计算的优势:这使得整个网络能够同时处理不同类型的特征(局部和全局),而不会因为计算瓶颈而导致性能下降。
3.4 与其他方法的比较:
- 传统的自注意力机制:传统的自注意力方法对图像的每个像素进行计算,导致计算量和内存消耗非常大。W-MHSA通过窗口化的方式减少了计算复杂度,使得处理大图像变得更加高效。
- 传统的卷积神经网络(CNN):传统的CNN通常依赖于卷积操作来提取局部特征,但缺乏捕捉全局信息的能力。W-MHSA结合了自注意力机制,能够在局部特征提取的基础上,同时捕捉全局信息,从而提高了模型的表现。
- 其他的视觉变换器(如ViT):传统的ViT方法通常将整个图像看作一个全局范围,计算所有像素之间的关系,而W-MHSA的窗口化设计减少了全局自注意力计算,从而提高了效率,尤其是在大分辨率图像的处理上。
该部分代码如下:
#是否使用窗口自注意力
if self.use_attn:
self.QK = nn.Conv2d(dim, dim * 2, 1)
self.attn = WindowAttention(dim, window_size, num_heads)
#是否使用卷积
if self.conv_type in ['Conv', 'DWConv']:
conv_out = self.conv(V)
out = self.proj(conv_out + attn_out) # 将卷积输出与注意力输出相加,更加丰富特征表示
else:
out = self.proj(attn_out)
4、SKFusion
用于图像处理和计算机视觉任务的深度学习方法,旨在通过选择不同尺寸的卷积核来融合信息,从而提高模型的表现力和灵活性。
4.1 SK Fusion的基本思想:
对于每个输入特征图,模型并不是只使用一个固定大小的卷积核,而是通过自适应地选择不同的卷积核来处理输入。这是通过引入一个选择机制来实现的,可以根据特定的输入信息来选择合适的卷积核尺寸,从而让网络能够更加灵活地学习不同尺度的特征。
SK Fusion 主要通过以下方式实现:
- 多个卷积核:在每一层卷积操作中使用多个不同尺度的卷积核(如 3x3、5x5、7x7 等),而不是固定使用单一大小的卷积核。
- 权重融合:每个卷积核有一个相应的权重,这些权重会根据输入的特征图自适应地调整。模型通过这些权重来决定每个卷积核对输出特征的贡献,最终通过加权平均来得到融合的输出。
- 选择机制:通过学习一个选择机制或计算特定输入的特征,网络可以决定哪些卷积核应该被优先使用。这一机制的实现通常借助于轻量级的操作,如1x1卷积。
4.2 SK Fusion 的优点:
- 多尺度特征提取:SK Fusion使得网络可以在不同的尺度上同时处理信息,从而更好地捕捉到不同粒度的特征。这对于处理具有多尺度或复杂背景的图像任务特别有帮助。
- 灵活性:通过选择合适的卷积核,SK Fusion可以使模型自动适应不同输入的特点,而不是依赖于固定的卷积核大小。
- 较少的计算开销:与其他方法相比,SK Fusion的计算量较小,因为它引入了较轻量的机制来进行选择和融合,而不需要额外的昂贵计算。
4.3 SK Fusion 与其他方法的比较:
(1)与特征拼接(Feature Concatenation)比较:
- 特征拼接:在传统的多尺度方法中,一个常见的做法是通过对不同尺寸的卷积核进行处理,然后将这些输出拼接(concatenate)在一起。这种方法可以有效地融合不同尺度的信息,但拼接后的特征图维度通常会增大,导致参数量增加,并且拼接后的信息可能需要额外的处理才能有效融合。
- SK Fusion:与直接拼接特征图不同,SK Fusion 不仅利用多个卷积核的输出,还通过学习机制对不同卷积核的输出进行加权融合。因此,它能根据输入自适应地选择最合适的卷积核进行融合,避免了拼接后增加的计算负担。
(2)与多尺度卷积(Multi-Scale Convolutions)比较:
- 多尺度卷积:在多尺度卷积中,网络通常会在不同的尺度上进行卷积操作(如使用不同大小的卷积核),然后将结果进行拼接或加权融合。然而,这种方法的计算量会随着卷积核尺寸和输入的增加而显著增加。
- SK Fusion:SK Fusion通过动态选择卷积核,减少了多尺度卷积中可能出现的计算冗余,同时能够更灵活地适应不同输入,减少不必要的计算开销。
该部分代码如下:
class SKFusion(nn.Module):
def __init__(self, dim, height=2, reduction=8):
super(SKFusion, self).__init__()
self.height = height
d = max(int(dim / reduction), 4)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(dim, d, 1, bias=False),
nn.ReLU(),
nn.Conv2d(d, dim * height, 1, bias=False)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, in_feats):
B, C, H, W = in_feats[0].shape
in_feats = torch.cat(in_feats, dim=1)
in_feats = in_feats.view(B, self.height, C, H, W)
feats_sum = torch.sum(in_feats, dim=1)
attn = self.mlp(self.avg_pool(feats_sum))
attn = self.softmax(attn.view(B, self.height, C, 1, 1))
out = torch.sum(in_feats * attn, dim=1)
return out
5、DehazeFormer block
5.1 DehazeFormer 概述
在代码中,DehazeFormer 类定义了整个去雾模型的结构。主要由 编码器-解码器 框架组成,配合 DehazeFormer Block(如框架图所示)来处理全局与局部特征。
5.2 模型的整体结构(Encoder-Decoder)
模型采用 编码器-解码器结构,其目的是:
- 编码器:逐步下采样输入图像,提取不同尺度的特征,减小空间分辨率的同时增加通道数。
- 解码器:逐步上采样特征图,恢复图像的空间分辨率,并融合跳跃连接(Skip Connection)传递的高分辨率特征。
整个模型的主要流程:
- 输入图像 I经过一个 3x3 卷积,生成初始特征 F。
- 编码器部分:
- 由多个 DehazeFormer Block 组成。
- 每次下采样(如
PatchEmbed)后,分辨率 H×W 减半,通道数增加。
- 解码器部分:
- 对特征图逐步上采样,并使用 SK Fusion 模块融合跳跃连接的高分辨率特征。
- 最终恢复到原始输入分辨率 H×W。
- 输出图像:
- 通过一个 3x3 卷积 和 Soft Reconstruction 生成去雾后的图像。
5.3 DehazeFormer Block 的设计
论文中的 DehazeFormer Block 是网络的核心模块,它结合了:
-
窗口多头自注意力机制 (W-MHSA-PC):
- 通过窗口划分,将特征图分割成小块,分别在每个小块内计算自注意力。
- 优势:减少计算复杂度,同时保持全局上下文建模的能力。
- 代码实现:使用
Linear映射生成 Q(Query)、K(Key) 和 V(Value),计算注意力权重 AAA,并与 V 相乘得到注意力输出。
-
卷积路径 (Conv):
- 在并行路径上进行卷积操作,补充局部感受野的信息,弥补注意力机制在捕获细节方面的不足。
-
融合与残差连接:
- 将自注意力路径与卷积路径的输出相加,进行融合。
- 添加残差连接,保持信息的流动,防止梯度消失。
-
MLP(多层感知机):
- 在通道维度上使用 Linear 映射 和 ReLU 激活 进一步处理特征。
该部分代码如下:
class DehazeFormer(nn.Module):
def __init__(self, in_chans=3, out_chans=4, window_size=8, # out_chans=4是因为还要输出额外的信息,比如alpha通道
embed_dims=[24, 48, 96, 48, 24],
mlp_ratios=[2., 4., 4., 2., 2.],
depths=[16, 16, 16, 8, 8],
num_heads=[2, 4, 6, 1, 1],
attn_ratio=[1 / 4, 1 / 2, 3 / 4, 0, 0],
conv_type=['DWConv', 'DWConv', 'DWConv', 'DWConv', 'DWConv'],
norm_layer=[RLN, RLN, RLN, RLN, RLN]):
super(DehazeFormer, self).__init__()
# setting
self.patch_size = 4
self.window_size = window_size
self.mlp_ratios = mlp_ratios
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=1, in_chans=in_chans, embed_dim=embed_dims[0], kernel_size=3)
# backbone
self.layer1 = BasicLayer(network_depth=sum(depths), dim=embed_dims[0], depth=depths[0],
num_heads=num_heads[0], mlp_ratio=mlp_ratios[0],
norm_layer=norm_layer[0], window_size=window_size,
attn_ratio=attn_ratio[0], attn_loc='last', conv_type=conv_type[0])
#下采样
self.patch_merge1 = PatchEmbed(
patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.skip1 = nn.Conv2d(embed_dims[0], embed_dims[0], 1)
self.layer2 = BasicLayer(network_depth=sum(depths), dim=embed_dims[1], depth=depths[1],
num_heads=num_heads[1], mlp_ratio=mlp_ratios[1],
norm_layer=norm_layer[1], window_size=window_size,
attn_ratio=attn_ratio[1], attn_loc='last', conv_type=conv_type[1])
self.patch_merge2 = PatchEmbed(
patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.skip2 = nn.Conv2d(embed_dims[1], embed_dims[1], 1)
self.layer3 = BasicLayer(network_depth=sum(depths), dim=embed_dims[2], depth=depths[2],
num_heads=num_heads[2], mlp_ratio=mlp_ratios[2],
norm_layer=norm_layer[2], window_size=window_size,
attn_ratio=attn_ratio[2], attn_loc='last', conv_type=conv_type[2])
self.patch_split1 = PatchUnEmbed(
patch_size=2, out_chans=embed_dims[3], embed_dim=embed_dims[2])
assert embed_dims[1] == embed_dims[3]
self.fusion1 = SKFusion(embed_dims[3])
self.layer4 = BasicLayer(network_depth=sum(depths), dim=embed_dims[3], depth=depths[3],
num_heads=num_heads[3], mlp_ratio=mlp_ratios[3],
norm_layer=norm_layer[3], window_size=window_size,
attn_ratio=attn_ratio[3], attn_loc='last', conv_type=conv_type[3])
self.patch_split2 = PatchUnEmbed(
patch_size=2, out_chans=embed_dims[4], embed_dim=embed_dims[3])
assert embed_dims[0] == embed_dims[4]
self.fusion2 = SKFusion(embed_dims[4])
self.layer5 = BasicLayer(network_depth=sum(depths), dim=embed_dims[4], depth=depths[4],
num_heads=num_heads[4], mlp_ratio=mlp_ratios[4],
norm_layer=norm_layer[4], window_size=window_size,
attn_ratio=attn_ratio[4], attn_loc='last', conv_type=conv_type[4])
# merge non-overlapping patches into image
self.patch_unembed = PatchUnEmbed(
patch_size=1, out_chans=out_chans, embed_dim=embed_dims[4], kernel_size=3)
def check_image_size(self, x):
# NOTE: for I2I test
_, _, h, w = x.size()
mod_pad_h = (self.patch_size - h % self.patch_size) % self.patch_size
mod_pad_w = (self.patch_size - w % self.patch_size) % self.patch_size
x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
return x
def forward_features(self, x):
x = self.patch_embed(x)
x = self.layer1(x)
skip1 = x
x = self.patch_merge1(x)
x = self.layer2(x)
skip2 = x
x = self.patch_merge2(x)
x = self.layer3(x)
x = self.patch_split1(x)
x = self.fusion1([x, self.skip2(skip2)]) + x
x = self.layer4(x)
x = self.patch_split2(x)
x = self.fusion2([x, self.skip1(skip1)]) + x
x = self.layer5(x)
x = self.patch_unembed(x)
return x
def forward(self, x):
H, W = x.shape[2:]
x = self.check_image_size(x)
feat = self.forward_features(x)
K, B = torch.split(feat, (1, 3), dim=1)
x = K * x - B + x
x = x[:, :, :H, :W]
return x总结
通过对这些创新点或改进点的详细分析,我们可以看到 DehazeFormer 不仅在去雾效果上取得了显著提升,还在模型设计的整体架构和计算效率上做出了诸多创新。其引入的视觉变换器结构和端到端训练机制,为去雾任务提供了新的解决方案,推动了该领域的发展。希望大家在看完这篇文章之后能更加理解 DehazeFormer 模型!

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









