










含金量超高的长三角杯数学建模竞赛(保研,考研面试认可度超高),我们团队去年斩获电工杯国一下,国赛国二,2024年美赛O奖得主都在我们团队!!!
【2024年长三角数学建模竞赛】选题分析+A题B题C题完整思路+代码分享
优秀参考论文+写作模板+云顶科研工具箱(含单时间序列、回归分类、降维聚类一体、评价超级强大的数学建模工具箱)
 http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=y0oBdiKt7tAfoRw2lVglM25Yu9Jjfuqe&authKey=nPki%2BBMMsqAPBD%2BPWeefORHEce5su%2FBax%2B2dB0tmBG5HWHRRWlrOfz58osxb0g7v&noverify=0&group_code=910313900
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=y0oBdiKt7tAfoRw2lVglM25Yu9Jjfuqe&authKey=nPki%2BBMMsqAPBD%2BPWeefORHEce5su%2FBax%2B2dB0tmBG5HWHRRWlrOfz58osxb0g7v&noverify=0&group_code=910313900A题抢救落水手机
目前更新1-4问完整解题代码+18页保姆级建模文档全过程
第一个问题是针对在西湖游船上掉落到西湖里的华为 Mate 60 Pro 手机,研究该手机可能的掉落范围以及最优搜索策略。
建立坐标系:以游船为原点,建立笛卡尔坐标系,水平方向为x轴,垂直方向为y轴。
确定手机掉落位置:假设手机在掉落时具有初速度,根据抛体运动的规律,手机的掉落位置可以由以下公式计算得出:
x = v₀tcosθ
y = v₀tsinθ - 1/2gt²
其中,v₀为手机的初速度,θ为手机掉落的角度,g为重力加速度,t为手机掉落的时间。
确定手机掉落的时间:根据游船的速度和手机掉落的位置,可以计算出手机掉落的时间。假设游船的速度为v,手机掉落的位置为(x,y),则手机掉落的时间t可以由以下公式计算得出:
t = x/v
确定手机掉落的角度:手机掉落的角度θ可以由以下公式计算得出:
确定掉落范围:根据手机掉落的角度和水深,可以计算出手机掉落的水平距离和垂直距离,从而确定手机掉落的范围。假设水深为h,手机掉落的角度为θ,手机掉落的水平距离为d,垂直距离为h,则手机掉落的范围可以由以下公式计算得出:
最优搜索策略:根据手机掉落的范围,可以确定搜索的范围。最优的搜索策略应该是以游船为中心,向外以手机掉落的最大水平距离和垂直距离为半径画出一个圆,以该圆为搜索范围进行搜索。如果搜索范围内没有找到手机,则可以缩小搜索范围,以此类推,直到找到手机为止。
问题1:华为 Mate 60 Pro 手机可能的掉落范围
假设水中的掉落物品在水平方向上的运动速度为v,重力加速度为g,掉落的初始高度为h,水面高度为0,则手机掉落到水中所需的时间为t,可以用以下公式表示:
在此基础上,可以得出手机在x轴方向上的运动距离为: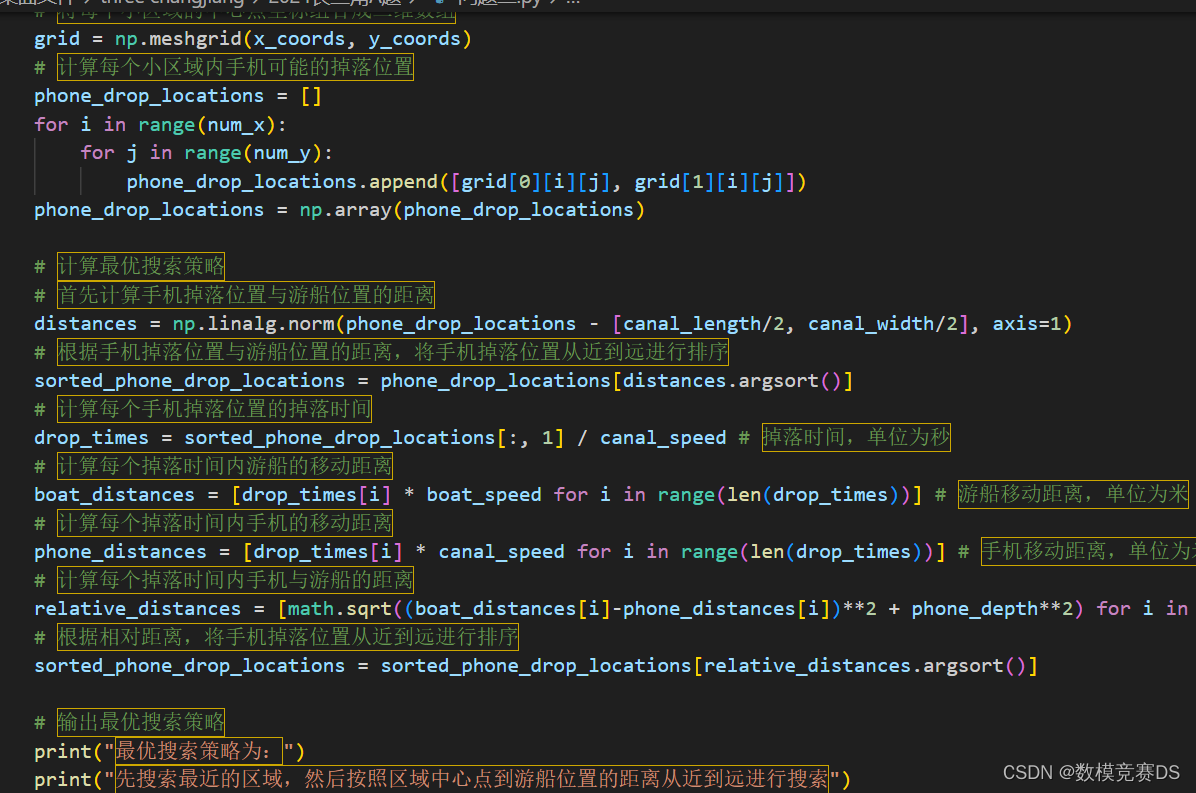
根据水平面上的速度等于手机在y轴方向上的初速度,可以得出:
B题人工智能范式的物理化学家
目前更新1-5问完整代码+15页保姆级完整思路建模文档
第一个问题是对题目所给数据进行预处理,明确处理数据的必要性和所采用的处理方法,并尝试通过分子id预测y2。
首先,对题目所给数据进行预处理的必要性在于:数据预处理是数据分析的基础,它可以帮助我们更好地理解数据,发现数据中的规律和特征,为后续建模和分析提供更好的数据基础。在本题中,我们需要对数据进行预处理的主要原因有以下几点:
数据量较大:原始数据集data.csv中有20万个分子的数据,每个分子有103个物理化学性质,这样的数据量对于人工分析来说是非常庞大的,因此需要通过预处理来提取有效的信息。
数据存在缺失值:在实际的数据分析中,经常会遇到数据缺失的情况,而缺失值会影响后续的数据分析和建模结果。因此,需要对数据进行预处理来处理缺失值,以保证后续的分析和建模的准确性。
数据存在噪声:在实际的数据采集过程中,由于各种原因,数据中可能会存在一些噪声,这些噪声会影响后续的数据分析和建模结果。因此,需要对数据进行预处理来去除噪声,以提高后续分析和建模的准确性。
针对以上的原因,我们采用以下的处理方法对数据 进行预处理:
进行预处理:
数据清洗:首先,我们需要对数据进行清洗,去除数据中的缺失值和噪声。具体来说,我们可以通过填充缺失值或者删除缺失值的方式来处理缺失值,通过平滑或者滤波的方式来去除噪声。
数据变换:为了更好地理解数据,我们可以对数据进行变换,使得数据更加符合我们的分析需求。具体来说,我们可以对数据进行标准化、归一化、对数变换等,以便后续的分析和建模。
特征选择:在数据预处理的过程中,我们可以通过特征选择的方式来提取数据中的有效信息。具体来说,我们可以通过统计学方法、机器学习方法等来选择对预测结果有影响的特征指标,从而提高模型的预测精度。
针对本题中的y2指标,我们可以通过分子id来预测它的值。具体来说,我们可以通过构建一个回归模型来预测y2的值,其中分子id作为自变量,y2作为因变量。通过回归模型,我们可以得到分子id与y2之间的函数关系,从而实现对y2的预测。
在预测过程中,我们可以采用交叉验证的方法来评估模型的性能,从而选择最优的模型。具体来说,我们可以将数据集分为训练集和测试集,通过训练集来构建模型,然后通过测试集来评估模型的性能。在评估过程中,我们可以采用均方误差、平均绝对误差等指标来衡量模型的预测能力,从而选择最优的模型。
最后,我们可以将predict.csv中的分子id作为自变量,通过构建的最优模型来预测y2的值,并将预测结果填入附件submit.csv文件中。
首先,对于题目所给的数据,我们需要进行预处理的原因有以下几点:
数据中存在缺失值:通过查看原始数据集,我们发现部分分子的物理化学性质数据存在缺失值,这会影响我们建立预测模型的准确性,因此需要对缺失值进行处理。
数据中存在异常值:异常值是指与大部分数据明显不同的数据,它们可能是由于测量误差或其他因素引起的,这些异常值会影响模型的准确性,因此需要对异常值进行处理。
数据中存在量纲不一致的问题:原始数据中的物理化学性质指标具有不同的量纲,这会影响模型的训练和预测,因此需要对数据进行标准化处理。
针对以上问题,我们采用以下方法进行数据的预处理:
缺失值处理:对于缺失值,我们采用均值填充的方法进行处理,即用该指标的平均值来替换缺失值。
异常值处理:对于异常值,我们采用箱线图的方法进行识别和处理,即将超过上下四分位数1.5倍的数据视为异常值,然后用该指标的中位数来代替异常值。
数据标准化:我们采用Z-score标准化的方法对数据进行处理,即将每个指标的数据减去该指标的均值,再除以该指标的标准差。
接下来,我们尝试通过分子id预测y2。根据题目给出的数据,我们可以将分子id作为自变量,将y2作为因变量,建立一个简单的线性回归模型来预测y2,即:
其中,
为截距,
为斜率。通过最小二乘法可以求出模型的参数估计值,从而得到最终的预测模型。
最后,我们将predict.csv中的分子id代入上述模型,即可得到对应的y2预测值,并将预测结果填入在附件submit.csv文件中。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 读取数据集
data = pd.read_csv('data.csv')
# 数据预处理
# 删除id列
data = data.drop(['id'], axis=1)
# 将数据集分为训练集和测试集
train = data.iloc[:200000, :]
test = data.iloc[200000:, :]
# 将y2作为目标变量,其他变量作为特征变量
X_train = train.drop(['y2'], axis=1)
y_train = train['y2']
X_test = test.drop(['y2'], axis=1)
# 建立线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
# 预测y2
y_pred = lr.predict(X_test)
# 将预测结果填入submit.csv文件
submit = pd.read_csv('submit.csv')
submit['y2'] = y_pred
submit.to_csv('submit.csv', index=False)C题汽车需求预测问题
2024长三角数学建模C题初步思路
后续代码思路持续更新...
针对文件中提到的第四届长三角高校数学建模竞赛赛道C的问题,我们可以按照以下思路来解决:
### 问题 1:点预测需求量
1. **数据整理**:首先整理“历史配件订单表”中的数据,确保数据的准确性和完整性。
2. **探索性数据分析**:对每个配件的历史需求量进行描述性统计分析,了解其需求分布、季节性等特征。
3. **模型选择**:根据数据特点选择合适的预测模型,如ARIMA、季节性分解的时间序列预测(STL)、指数平滑法(ETS)等。
4. **模型训练与验证**:使用历史数据训练模型,并通过交叉验证等方法评估模型的性能。
5. **预测未来需求量**:使用训练好的模型预测2023年8月1日至2023年8月31日的需求量。
6. **准确率评价**:使用1-wmape和1-smape等指标评价预测准确率,并进行历史回测以验证模型的稳健性。
7. **结果展示**:将预测结果以表格形式展示,并提供模型评价的详细说明。
### 问题 2:区间预测需求量
1. **区间预测方法选择**:了解和选择合适的区间预测方法,如置信区间估计、蒙特卡洛模拟等。
2. **基本假设确定**:明确在建模过程中的基本假设,如需求的独立性、同分布性等。
3. **模型调整**:根据选择的区间预测方法调整模型,以生成未来需求量的分布。
4. **分位数预测**:计算10%、30%、70%和90%的分位数预测值。
5. **准确率评价**:讨论如何评估区间预测的准确率,可能需要构建新的评估指标或方法。
6. **结果展示与讨论**:将预测结果以表格形式展示,并讨论预测的不确定性和可能的风险。
### 问题 3:时间序列分类与精准预测
1. **时间序列特征分析**:分析每个配件需求时间序列的特征,如趋势、季节性、周期性等。
2. **分类方法选择**:根据时间序列的特征选择合适的分类方法,如聚类分析、分类回归树(CART)等。
3. **时间序列分类**:将时间序列分为不同的类别,每一类具有相似的特征。
4. **类别特征研究**:研究每一类时间序列的特征,并分析这些特征对预测准确性的影响。
5. **精准预测策略**:根据类别特征,制定精准的预测策略,可能包括不同的模型选择、参数调整等。
6. **模型验证与优化**:对每一类时间序列使用相应的预测策略,并验证其效果。
7. **结果展示**:展示分类结果和每一类预测策略的效果,并讨论如何综合这些策略以提高整体预测的准确性。
### 综合建议:
- 在整个建模过程中,注意模型的可解释性和实际应用的可行性。
- 对于预测模型的选择,可以考虑多种模型的组合使用,如集成方法,以提高预测的准确性和稳健性。
- 在进行区间预测时,注意区分不同置信水平下的预测策略和风险评估。
- 在分类和精准预测中,考虑使用机器学习方法,如随机森林、支持向量机等,以发现更复杂的关系和模式。
- 确保所有的预测结果都有详细的文档记录,包括模型的选择、参数的设置、预测的假设等,以便于结果的复现和验证。

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









