









一、简介
image2image-turbo作为一个使用CycleGAN形式进行训练的图生图Diffusion的网络,主要解决了两方面条件扩散模型的显存局限性:
1.由于迭代去噪过程而很慢的推理速度
2.依赖成对数据的模型微调
二、核心点
能够不使用配对的数据进行训练
其关键点在于能够使用对抗学习目标高效率适配预训练的文本条件的一步扩散模型到新的领域和任务,比如SD-Turbo
三、架构
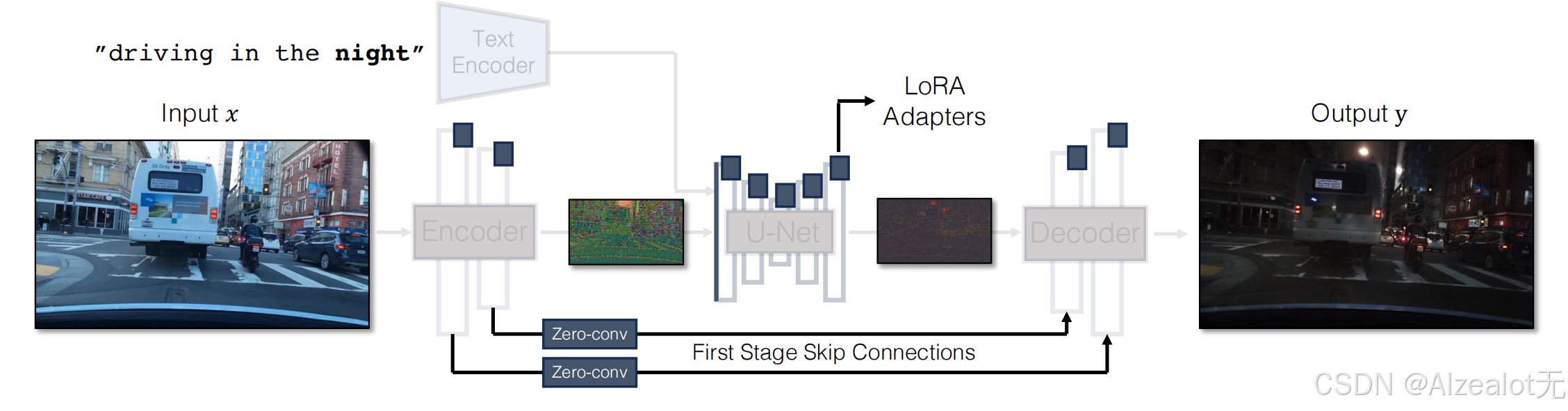
蓝色为可训练的部分,使用了Lora进行微调,这个生成器是作为GAN训练方式中的生成器进行训练的

1.由于在一步模型中,噪声图会直接影响输出结构,因此将噪声和输入条件同时输入到适配器分支会造成矛盾的信息,尤其在非配对数据的形式中。因此,作者设计出直接将控制信息放入Unet的噪声编码器分支,使得网络能够直接适应新的控制
2.将Encoder、UNET和Decoder整合成一个单一的端到端可训练架构
3.在encoder和decoder之间通过零卷积进行跳连连接
四、训练以及实验细节
4.1非配对的训练
其损失函数与CycleGAN类似:
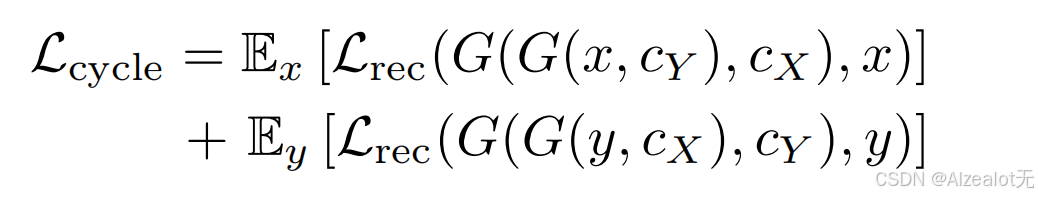
1.循环损失,图片迁移任务的一个循环,将两种风格的经过同一个生成器两次迁移回来,然后计算损失函数,具体的损失函数也就是rec是重建的缩写,是由L1和LPIPS两种损失函数的一个权重结合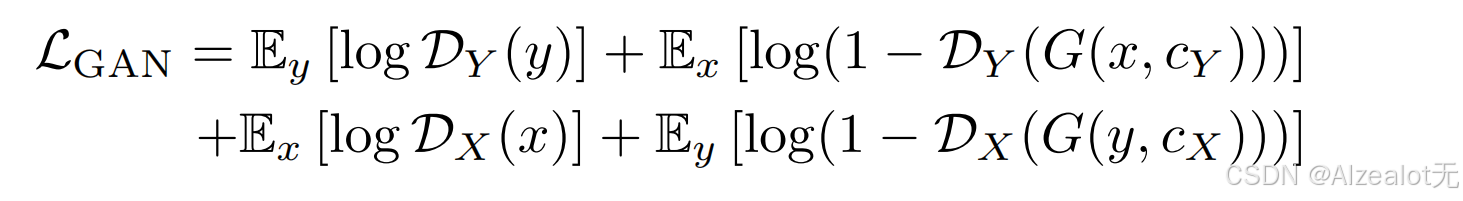
2.对抗损失
和GAN的类似,以此期待两种领域的迁移输出能够匹配相应的目标域。使用了两个对抗判别器,这两个判别器都是以CLIP为主干网络
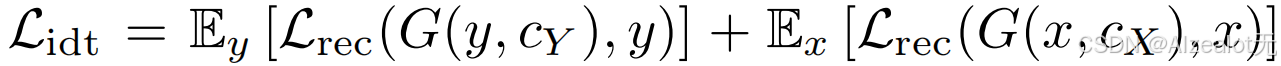
3.一致正则项,加入的通往源域prompt是让源域的图像能够经过生成器的翻译后更加接近自己
总体的损失函数:
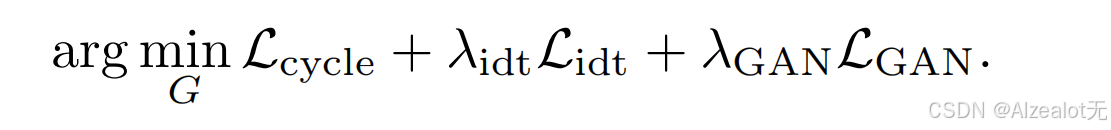
4.2 配对的训练

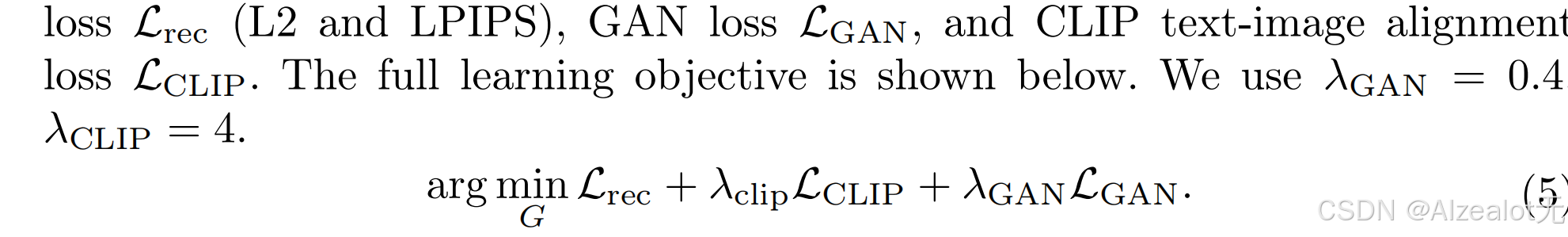
配对的数据的损失函数有所改变,博主很难得到目前方向中的可用配对数据,请读者有需求自行查看
五、局限性
1.无法决定指导的强度,因为其主干模型SD-Turbo没有使用不用分类器的指导,或许指导蒸馏是一种优化方案。
2.该模型不支持负面提示词,这种负面提示词能够减少一些错误
3.本模型使用循环一致性损失和高能力的生成器进行训练,占用很多内存。可以探索一边方法

















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









