






今天给大家推荐一个深度学习发论文&模型涨点利器!Mamba+遥感!
曼巴(Mamba)结合遥感技术(Remote Sensing,简称RS)是一个新兴的研究领域,它利用了Mamba模型在处理序列数据时的高效率和全局建模能力,将其应用于遥感图像处理和分析中。
在最新的顶会论文中,就有许多论文涉及到了Mamba在遥感图像处理中的应用研究。这些创新方案不仅解决了传统遥感图像处理中存在的问题,还开辟了新的研究方向和应用领域。
我整理了最新10种“曼巴+遥感技术”的创新思路,以下放出部分,全部论文PDF版+解析工中号【沃的顶会】 回复 曼巴遥感 即可全部领取
CDMamba: Remote Sensing Image Change Detection with Mamba
本文提出了一种名为CDMamba的新模型,用于处理遥感图像的变化检测任务。该模型结合了Mamba架构的全局特征提取能力和卷积操作的局部细节增强能力,通过引入Scaled Residual ConvMamba (SRCM)模块和Adaptive Global Local Guided Fusion (AGLGF)块,有效解决了现有Mamba方法在密集预测任务中缺乏详细线索的问题,并通过多时相特征交互提升了变化检测的准确性。
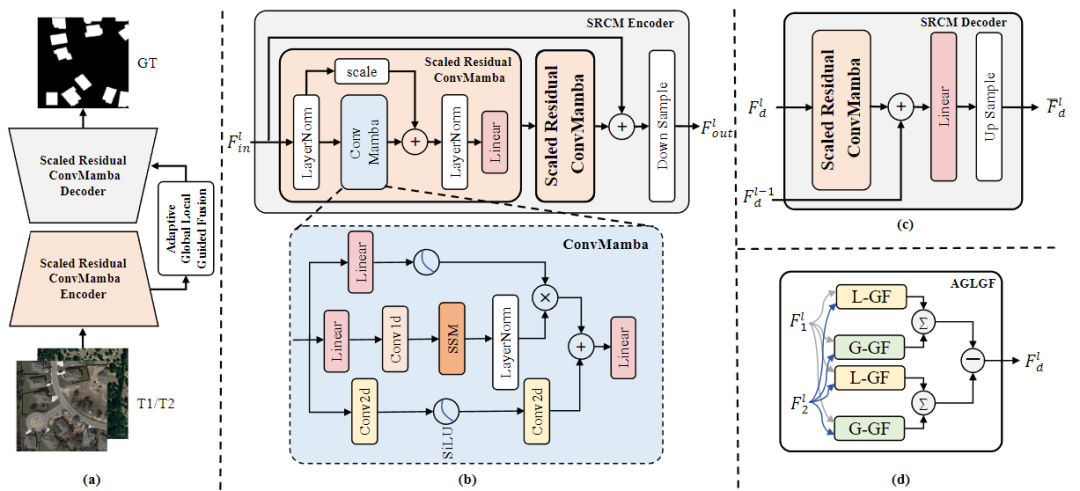
创新点
1.提出了CDMamba模型,有效结合了全局和局部信息,解决了Mamba在密集预测任务中缺乏局部线索的问题。
2.引入了Scaled Residual ConvMamba (SRCM)模块,利用Mamba的全局特征提取能力和卷积的局部细节增强能力,提升了细粒度检测的效果。
3.设计了Adaptive Global Local Guided Fusion (AGLGF)块,通过多时相特征交互,动态融合全局和局部特征,进一步增强了变化区域的区分性特征。
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
本文提出了一种新的框架CM-UNet,用于遥感图像的语义分割。CM-UNet结合了CNN编码器提取局部特征和Mamba解码器聚合全局信息的优势,通过引入CSMamba块和多尺度注意力聚合(MSAA)模块,有效地捕捉了大规模遥感图像的长距离依赖和多尺度全局上下文信息。实验结果表明,CM-UNet在多个基准数据集上优于现有方法。
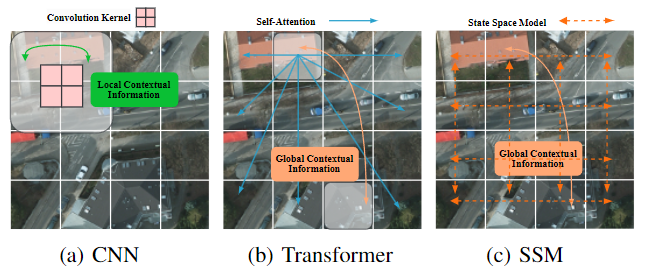
创新点
1.提出了基于Mamba架构的CM-UNet框架,能够高效整合局部和全局信息,适用于遥感图像语义分割。
2.设计了CSMamba块,将通道和空间注意力机制融入Mamba块中,增强了对全局上下文信息的提取。
3.引入了多尺度注意力聚合(MSAA)模块,通过跳跃连接辅助解码器,并采用多输出损失逐步监督语义分割过程。
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
本文提出了一种新的框架FMSR,结合了Vision State Space Model (Mamba)和频率选择模块(FSM),以解决现有遥感图像超分辨率(SR)方法在大规模遥感图像中受限的感受野和高计算复杂度问题。FMSR通过多级融合架构,利用频率选择模块、视觉状态空间模块(VSSM)和混合门模块(HGM),实现了有效的空间-频率融合,并通过可学习的缩放适配器重新校准多级特征,以实现更精确的特征融合。
实验结果表明,FMSR在AID、DOTA和DIOR基准上显著优于现有的Transformer-based方法HAT-L,同时大幅降低了内存消耗和计算复杂度。

创新点
1.首次将State Space Model (Mamba)应用于遥感图像超分辨率任务,展示了其在大规模场景中的高效全局建模能力。
2.引入了频率选择模块(FSM),自适应地识别并选择快速傅里叶变换过程中最具信息量的频率信号,增强了高频信息的捕捉。
3.设计了混合门模块(HGM),结合CNN算子的局部偏差和空间变化坐标,增强了特征表示的局部性,提高了超分辨率性能。
RemoteDet-Mamba: A Hybrid Mamba-CNN Network for Multi-modal Object Detection in Remote Sensing Images
本文提出了一种名为RemoteDet-Mamba的多模态遥感目标检测网络,该网络结合了Siamese CNN和基于Mamba架构的跨模态融合模块(CFM)。通过四向选择性扫描融合策略,RemoteDet-Mamba能够同时学习单模态局部特征和跨模态全局特征,提升了小目标的可区分性和不同类别的区分度。
实验结果表明,RemoteDet-Mamba在DroneVehicle数据集上实现了比现有方法更高的检测精度,同时保持了较低的计算复杂度和参数量。
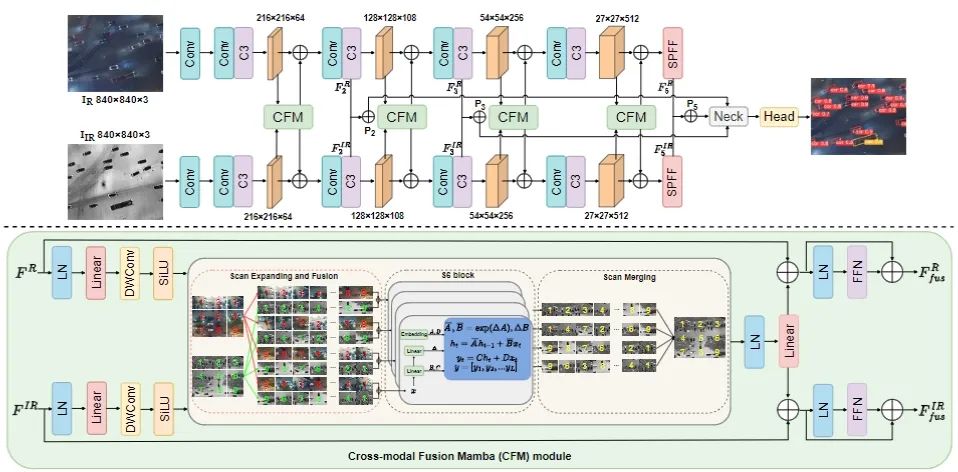
创新点
1.提出了RemoteDet-Mamba框架,首次将Mamba的选择性扫描2D机制应用于无人机多模态遥感目标检测。
2.设计了基于选择性扫描2D机制的跨模态融合模块(CFM),能够在补丁级别进行四向扫描,解耦密集分布的小目标并提取全局信息。
3.通过线性时间复杂度的扫描策略,有效捕捉长程依赖关系,提升小目标的检测性能。
4.相比现有的CNN和Transformer方法,RemoteDet-Mamba在保持高效的同时显著减少了计算负担和参数量。

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









