










目标检测终于摆脱数据依赖症了!ICCV 2025最新收录的一项研究,将小样本学习与目标检测深度融合,直接破解了现实场景中标注数据少、检测精度低的老大难问题,未来极可能成为工业、医疗等领域的落地关键。
大家都知道,传统目标检测要想准,得靠成千上万张标注图喂模型,比如工厂检测流水线的微小零件缺陷,要标注上百张不同角度的图片;医院做医学影像肿瘤检测,更是需要稀缺的标注病例数据,这些场景往往因为数据不足,导致模型根本没法用。而这次新研究恰好踩中了这个痛点,通过设计轻量化样本适配模块,让模型仅用20-30张标注样本,就能学会识别目标特征,像在肺癌早期CT检测中,精度比传统方法提高了18%,工厂零件缺陷检测的漏检率也降了近15%。
对做应用研究或想发顶会的同学来说,这个方向特别实用,既贴合产业真实需求,又有明确的技术创新点。
我整理了10篇相关的前沿论文,顶会/顶刊论文+部分官方代码打包免费送,全部论文PDF版+开源代码,工种号 沃的顶会 扫码回复 “小样本时序” 领取
SNIDA:Unlocking Few-Shot Object Detection with Non-linear Semantic Decoupling Augmentation
文章解析
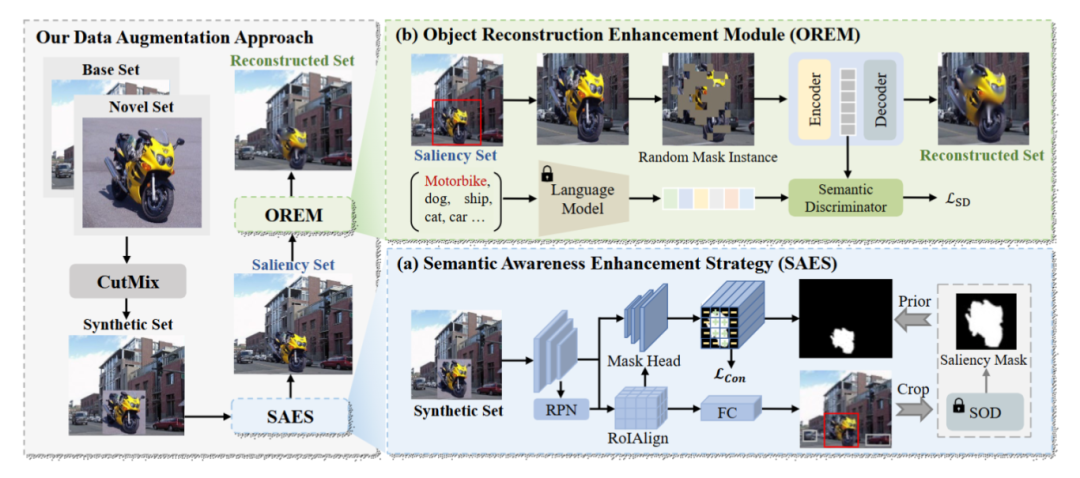
针对小样本目标检测数据不足问题,提出SNIDA方法,通过语义感知增强策略和目标重建模块解耦前景背景,生成多样数据,在PASCAL VOC和MS-COCO上性能显著提升。
创新点
提出语义解耦增强方法SNIDA,分离前景与背景并分别增强多样性,提升语义感知能力。
引入语义引导掩码自编码器的目标重建模块,以非线性方式生成多样实例,保留高层语义。
方法可嵌入现有微调方法,在不同数据集和样本设置下均提升检测性能。
研究方法
利用无监督语义分割提取实例掩码,将实例融合到不同背景,生成显著集增强语义感知。
通过掩码自编码器随机掩码前景补丁,结合语言嵌入引导,非线性重建实例以增加多样性。
结合CutMix生成合成集,与显著集、重建集在微调阶段共同使用,提升样本数量与质量。
研究结论
在PASCAL VOC和MS-COCO上,SNIDA大幅超越基线方法,在不同样本设置下均达先进水平。
语义解耦和非线性增强有效提升样本多样性与语义感知,缓解小样本过拟合问题。
方法计算负担主要在微调阶段,推理时无额外开销,兼具有效性与实用性。
Fine-Grained Prototypes Distillation for Few-Shot Object Detection
文章解析
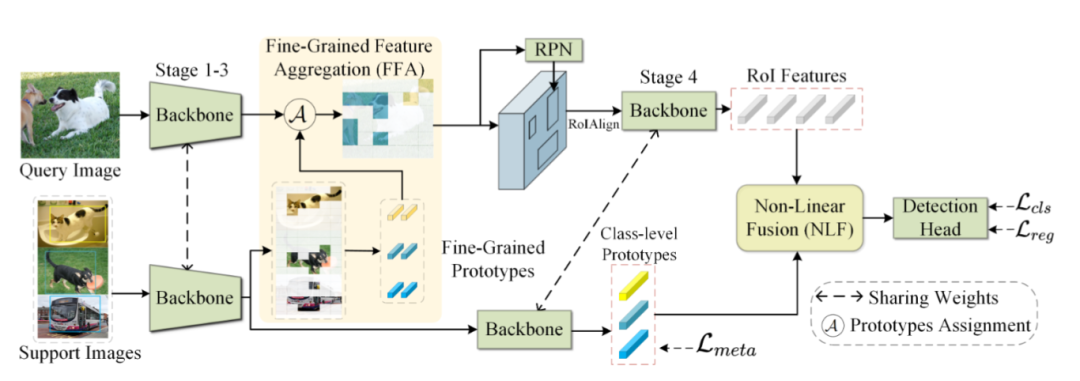
针对元学习小样本目标检测中类级原型缺乏细节信息的问题,提出细粒度特征聚合(FFA)模块,蒸馏支持特征为细粒度原型并与查询特征匹配。结合平衡类别无关采样(B-CAS)和非线性融合(NLF)模块,提升特征关系建模能力,在VOC和COCO上刷新SOTA。
创新点
利用特征查询蒸馏支持特征为细粒度原型,通过跨注意力匹配到查询特征图,强化局部细节建模。
在高层特征融合中平衡正负样本比例,避免随机采样导致的关键正样本被淹没。
通过元素乘、减法和拼接增强特征间非线性关系,兼容跨类别特征聚合。
研究方法
通过跨注意力机制从支持特征中蒸馏细粒度原型,基于亲和力矩阵将原型分配到查询特征图,增强前景区分能力。
底层用FFA处理细节特征,高层通过B-CAS选择正负原型对,结合NLF模块进行非线性交互,提升语义对齐精度。
测试阶段通过加权求和集成多样本原型,过滤不兼容特征,增强模型鲁棒性。
研究结论
在PASCAL VOC的10-shot场景下,FPD在三个分割集上分别达到68.4%、53.9%、62.9% AP50,超越VFA等方法。
FFA相比直接特征匹配提升3-5% AP,B-CAS与NLF联合使用使性能提升约10%,验证多模块互补性。
在MS COCO上,FPD以传统Faster R-CNN框架实现19.3% AP(30-shot),证明细粒度建模在复杂场景的有效性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









