







 本文探讨了在点云数据处理中,KD-Tree和np.where两种方法在执行半径最近邻搜索上的优劣,发现np.where在处理大量点云时具有更快的速度和更好的灵活性,特别是在速度和准确性要求高的情况下,推荐使用np.where进行球形领域搜索。
本文探讨了在点云数据处理中,KD-Tree和np.where两种方法在执行半径最近邻搜索上的优劣,发现np.where在处理大量点云时具有更快的速度和更好的灵活性,特别是在速度和准确性要求高的情况下,推荐使用np.where进行球形领域搜索。
一、KD-Tree球形领域搜索
# KD树处理
# ---------------------------------------读取点云--------------------------------------
pcd = o3d.io.read_point_cloud("res/bunny.pcd")
# --------------------------------------KDtree搜索--------------------------------------
pcd_tree = o3d.geometry.KDTreeFlann(pcd) # 建立KD树索引
# ---------------------------------------半径搜索---------------------------------------
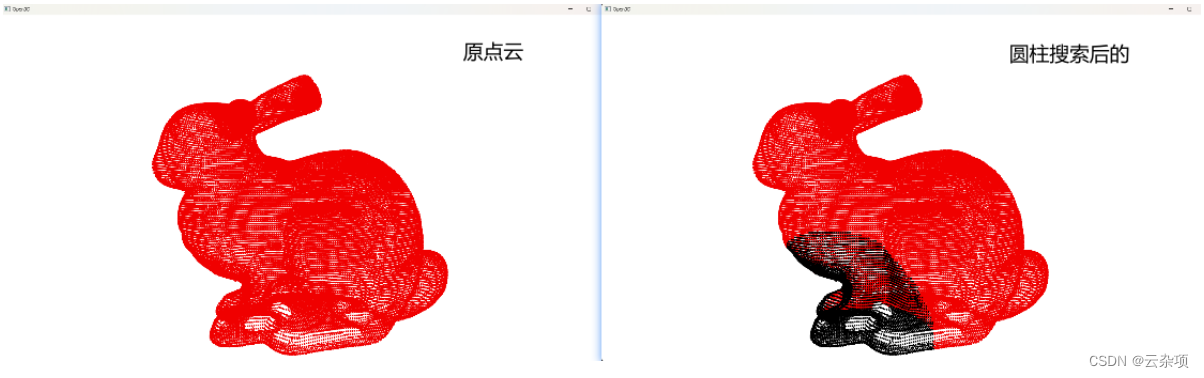
pcd.colors[150] = [0, 1, 0] # 给定查询点并渲染为绿色
[k1, idx1, _] = pcd_tree.search_radius_vector_3d(pcd.points[150], 0.05) # 半径搜索
np.asarray(pcd.colors)[idx1[1:], :] = [0, 0, 0] # 半径搜索结果并渲染为红色
o3d.visualization.draw_geometries([pcd])
原理
。。。
参数
pcd_tree: 这是一个构建在点云数据上的kd树对象,用于高效地进行最近邻搜索。search_radius_vector_3d: 这是kd树对象的一个方法,用于在3D空间中搜索指定半径内的最近邻点。pcd.points[150]: 这是点云数据中索引为150的点的位置,作为搜索的中心点。0.05: 这是搜索的半径,表示搜索中心点周围0.05个单位范围内的最近邻点。k1: 这是返回的最近邻点的数量。idx1: 这是返回的最近邻点的索引列表。
二、np.where球形领域搜索(推荐)
# np.where()处理
# ---------------------------------------读取点云--------------------------------------
pcd = o3d.io.read_point_cloud("res/bunny.pcd")
points = np.asarray(pcd.points)
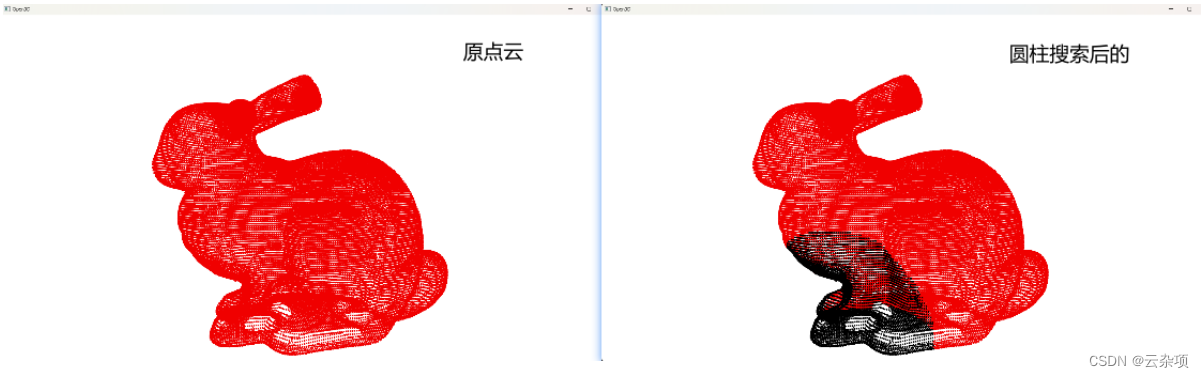
pcd.colors[150] = [0, 1, 0] # 给定查询点并渲染为绿色
center = points[150]
index = np.where(((points[:, 0] - center[0])**2 + (points[:, 1] - center[1])**2 + (points[:, 2] - center[2])**2) <= 0.05**2)[0]
np.asarray(pcd.colors)[index[1:], :] = [0, 0, 0] # 半径搜索结果并渲染为红色
o3d.visualization.draw_geometries([pcd])
原理
。。。
参数
points[:, 0],points[:, 1],points[:, 2]: 这些是点云数据中所有点的 x、y 和 z 坐标。:,0表示选择所有行中的第一个元素,即 x 坐标;:,1表示选择所有行中的第二个元素,即 y 坐标;:,2表示选择所有行中的第三个元素,即 z 坐标。center[0],center[1],center[2]: 这些是给定的中心点的 x、y 和 z 坐标。(points[:, 0] - center[0])**2 + (points[:, 1] - center[1])**2 + (points[:, 2] - center[2])**2: 这是计算每个点到给定中心点的距离的平方和。这里使用了欧式距离的平方。0.05**2: 这是距离的阈值的平方,即0.05的平方。这个阈值用于确定哪些点被认为是在指定半径范围内的点。np.where: 这是NumPy的条件筛选函数,用于返回满足条件的元素的索引。[0]: 这是为了从np.where返回的元组中提取第一个数组,其中包含满足条件的索引。
三、为什么推荐np.where()而不是kd-Tree
只从处理时间角度分析
| 方法/点云数目(点) | 35947 points. | 2001009 points. | 45590887 points. |
|---|---|---|---|
| kd树建立时间戳 | 0.024077 | 0.896488 | 19.859272 |
| np.where()处理时间戳 | 0.009681 | 0.148632 | 2.614453 |
随着点云数量的增加,KD-Tree的搜索时间迅速增加,远远超过了np.where()函数的处理时间。在处理点云项目时,速度和准确性优势变得至关重要,特别是考虑到点云数据量通常非常大。相比之下,np.where()函数在速度和灵活性方面远远超过了KD-Tree。因此,在处理点云数据时,选择np.where()通常是更明智的选择。
四、相关链接
numpy中的点云操作numpy中的点云操作-CSDN博客
















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











