









通用图像理解模型:图像分类、目标检测、图像分割
一文彻底搞懂多模态 - 多模态理解+视觉大模型+多模态检索_多模态大模型 图片理解-CSDN博客
视频理解中的三大基础领域:动作识别(Action Recognition)、时序动作定位(Temporal Action Localization)、视频Embedding
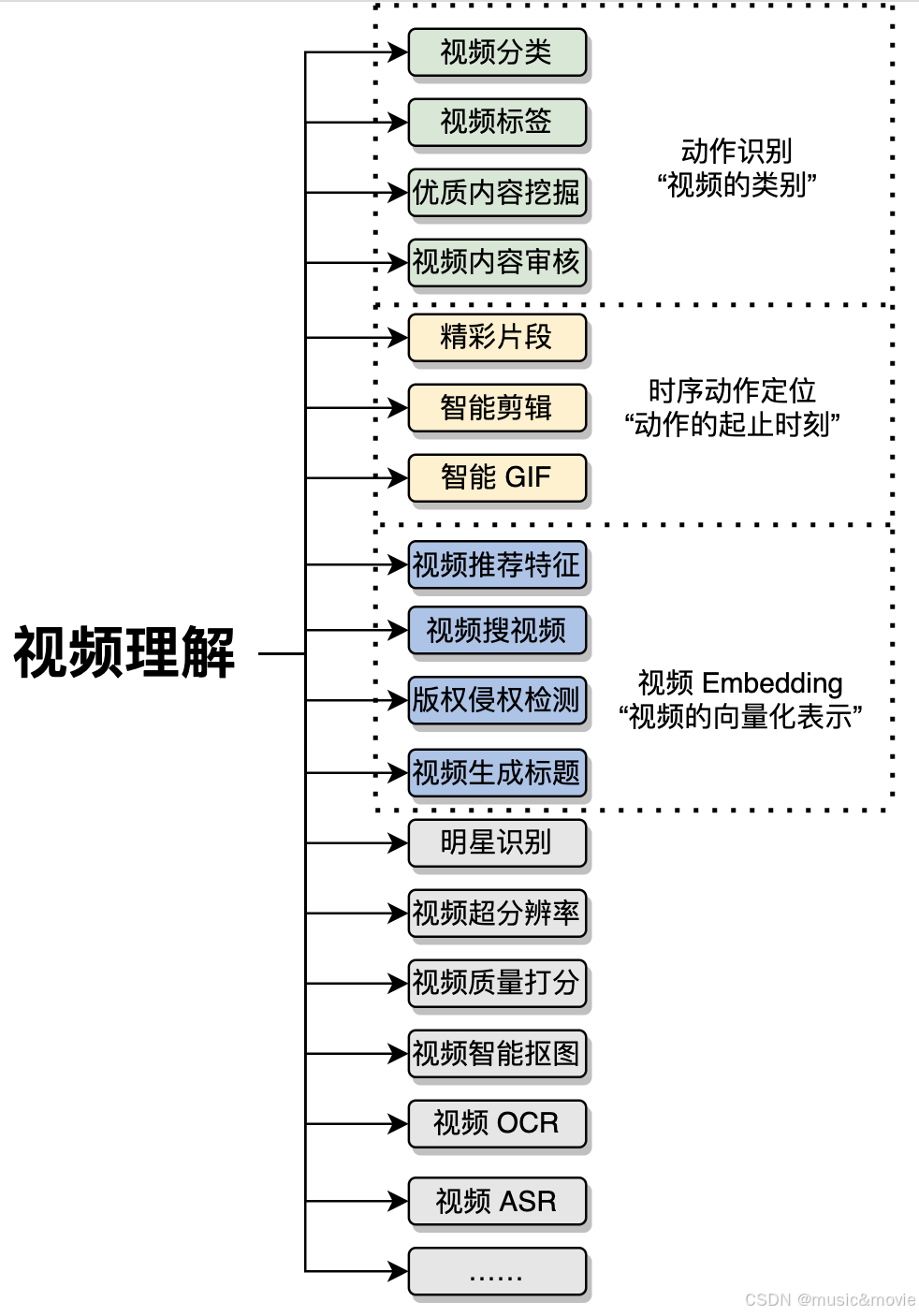
视频理解综述:动作识别、时序动作定位、视频Embedding(赠书)-腾讯云开发者社区-腾讯云
图像理解。图像理解任务涉及单张图像用于各种视觉推理任务,如图像标注和以图像为中心的问题回答。这些任务仅关注空间信息,包括对视觉上下文的粗略理解和对局部视觉细节的细致理解。
短视频理解。与仅涉及静态视觉数据的图像理解任务不同,短视频理解还结合了来自多个视觉帧的时间信息。除了空间推理,事件内的时间推理和跨帧的时空推理在短视频理解中发挥着至关重要的作用。
长视频理解。长视频通常持续数分钟甚至数小时,通常由多个事件组成,与短视频相比,包含更丰富的空间内容和时间变化。长视频理解不仅涉及空间和事件内的时间推理,还涉及事件间推理和来自不同视频事件的长期推理。

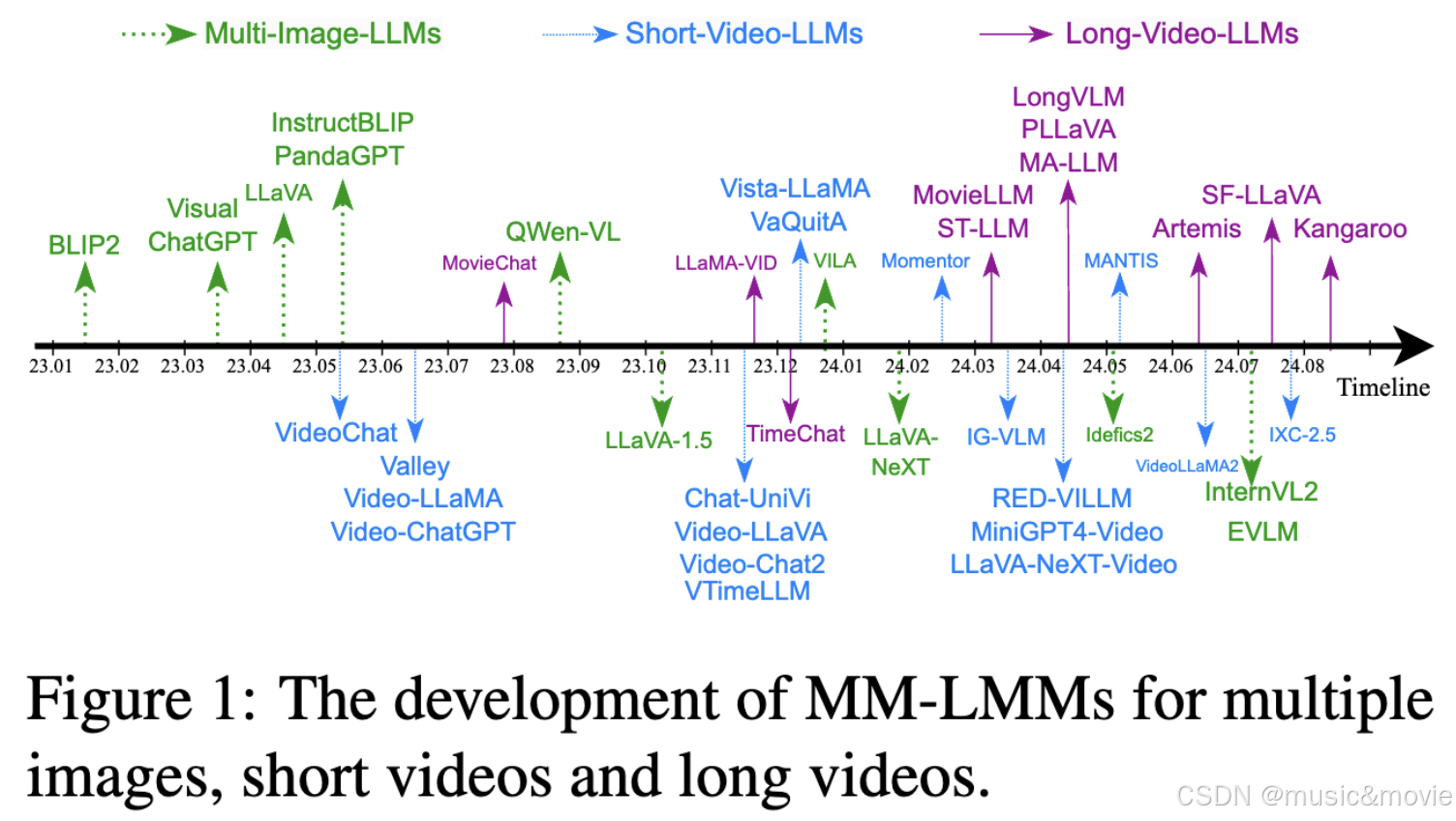
从秒级到小时级:TikTok等发布首篇面向长视频理解的多模态大语言模型全面综述_from seconds to hours: reviewing multimodal large -CSDN博客
参考:
CLIP模型和BLIP模型:
理解Cross Attention机制、CLIP模型、Q-Former机制和BLIP模型-CSDN博客
LLava:
【LLM多模态】LLava模型架构和训练过程 | CLIP模型_llava 训练-CSDN博客
LLaVA-1.5:强大的多模态大模型(包含论文代码详解)_llava 1.5 数据集-CSDN博客
一文读懂多模态大模型:LLaVA系列 | 从图像到视频的内容理解_llava模型-CSDN博客
GLM-4V:
【机器学习】GLM-4V:图片识别多模态大模型(MLLs)初探-CSDN博客
GLM-4V-Flash - 智谱 AI 推出的首个免费多模态模型API | AI工具集
Qwen-VL:
【中文视觉语言模型+本地部署 】23.08 阿里Qwen-VL:能对图片理解、定位物体、读取文字的视觉语言模型 (推理最低12G显存+)-CSDN博客
【机器学习】阿里Qwen-VL:基于FastAPI私有化部署你的第一个AI多模态大模型_qwenvl-CSDN博客
多模态大模型Qwen-VL和MiniCPM-Llama3-V-2_5初体验_qwenvl-CSDN博客
MLM之Qwen:Qwen2-VL的简介、安装和使用方法、案例应用之详细攻略_qwen2-vl使用-CSDN博客
qwenvl 以及qwenvl 2 模型架构理解_qwenvl与 qwen2vl的差别-CSDN博客
CogVLM:
CogVLM2:第二代视觉大模型,19B 即可比肩 GPT-4V-CSDN博客
智谱&清华联手打造:CogVLM2,全球顶尖开源视觉理解大模型!-CSDN博客
其他:

















 2104
2104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









