







Local Search(局部搜索)
1. 英文复述 (English Restatement)
-
Definition
Local Search is a search technique that focuses on a single current state rather than exploring a tree of multiple paths. It uses an objective function (or evaluation function) and attempts to improve the current state by moving to a “neighboring” state with a better score. -
Key Idea
- Instead of recording or following an entire path from the initial state to the goal, local search only retains the current configuration.
- Moves are made to one of the neighbor states, i.e., states that can be reached by a small, local modification of the current state.
-
Advantages
- Very Low Memory Usage: Only the current state and some auxiliary info are stored.
- Scales to Large/Infinite Spaces: Systematic (tree-based) searches become infeasible for huge state spaces, whereas local search can handle them, though not guaranteed to find a globally optimal solution.
-
Completeness & Optimality
- Completeness: Most local search methods are incomplete; they may get stuck in local maxima, plateaus, or ridges. A “complete” local search would always reach a goal if one exists, but that is rare.
- Optimality: Local search rarely guarantees a global optimum. In theory, it may converge to suboptimal solutions. In practice, it often produces “good enough” solutions efficiently.
-
Example
- 8-Queens Problem: Instead of systematically building a path to place queens one by one, local search simply starts with a random arrangement of 8 queens and then iteratively tries to improve it (e.g., move a queen to reduce the number of conflicts).
2. 中文翻译 (Literal Chinese Translation)
-
定义
局部搜索是一种只关注单个当前状态的搜索技术,不需要像其他搜索算法那样维护从初始状态到目标状态的整条路径。它通常依赖一个目标函数(或评估函数),并尝试通过转移到“邻居”状态来改进当前解的分数。 -
核心思想
- 不记录或跟踪完整路径,仅仅保留当前配置。
- 移动时从当前状态向某个邻域状态转变,即对当前状态做一次“小范围修改”后得到的新状态。
-
优点
- 内存占用极少:只需要存储当前状态和一些辅助信息。
- 可应对超大或无限状态空间:系统化(基于树的)搜索在超大空间中常会失效,而局部搜索可以在这种环境下工作,尽管它并不一定能保证找到全局最优解。
-
完备性与最优性
- 完备性:大多数局部搜索算法是不完备的,可能困于局部最优、平台(plateaus)或凸起(ridges)等地形结构。真正的“完备”局部搜索比较少见。
- 最优性:局部搜索通常不保证全局最优解;理论上可能收敛到次优解。但是在实际应用中,它往往能在可接受的时间内给出“足够好”的可行解。
-
示例
- 8 皇后问题:与其系统地构造从无到有的完整摆放方案,不如先随机给定一个 8 皇后的排列,然后通过“局部调整”来减少皇后之间的冲突,逐步逼近正确解。
3. 中文通俗解释 (Chinese Plain Explanation)
想象你要解决一个“大海捞针”的问题,状态空间特别大,用常规的穷举或树搜索可能根本算不动。“局部搜索”就像带着一把放大镜,只关注你当前在哪里,尝试周围一点点的改变,看看能不能让结果更好。
- 例如,解决 8 皇后:先随便把皇后都摆好,然后每次挪动一个皇后,让冲突数变少。
- 这种方法记忆体开销特别小,因为只关注“现在这步棋如何”,不用储存从头到尾的历史记录。
- 它的缺点是,有时会被山峰(local maxima)或高原(plateaus)困住,找不到真正的全局最佳解。
- 但在实际应用里,局部搜索通常能在有限时间里给出还不错甚至很好的解。
4. 关键词 (Key Terms)
| 英文 | 中文 | 解释 |
|---|---|---|
| Local Search | 局部搜索 | 只存储当前状态并在其邻域中进行移动的搜索方式 |
| Current State | 当前状态 | 代表系统当前的配置,不记录路径 |
| Neighbor (State) | 邻居(状态) | 通过一次小范围修改从当前状态得到的状态 |
| Objective Function | 目标函数(或适应度函数) | 用来评估当前状态优劣的函数值(也可叫做 cost/fitness) |
| Local Maximum | 局部最大值 | 在局部范围内优于周围状态,但并非全局最优 |
| Plateau | 平台 | 一大片区域里的目标函数值相同,搜索无法判断朝哪个方向能变好 |
| Completeness | 完备性 | 算法是否能保证找到目标(如果存在的话) |
| Optimality | 最优性 | 算法是否能保证得到全局最优解 |
5. 英文记忆笔记 (English Memory Notes)
- Definition
- Maintains one current state; moves to neighbors only.
- Advantages
- Low memory: Only store the current state.
- Feasible in huge/infinite spaces.
- Shortcomings
- Usually incomplete: can get stuck in local maxima, ridges, or plateaus.
- Rarely optimal: no guarantee of global optimum.
- Applications
- 8-Queens, large optimization tasks (e.g., scheduling, traveling salesman approximations).
- Provides “good enough” solutions quickly when the full path is irrelevant.
Tip: Local search is a practical choice when the final configuration matters more than the path itself, and when state spaces are extremely large.
Hill-Climbing Search(爬山法搜索)
1. 英文复述 (English Restatement)
-
Definition
Hill-Climbing is a local search algorithm that iteratively moves from the current state to a neighboring state that maximizes (or at least improves) an evaluation function. It maintains no full path or search tree—only the current state and its objective value. -
Core Mechanism
- Loop: Evaluate all neighbors → pick the “best neighbor” → if it’s better than current, move there; otherwise, stop.
- “Going uphill” in the objective-function landscape, akin to climbing a hill.
-
Drawbacks
- Local Maxima: The algorithm might get stuck at a peak that is lower than the global maximum.
- Plateaus: Regions of flat objective values that provide no direction for improvement.
- Ridges / Shoulders: Slanted or narrow structures that are hard to climb using small steps.
-
Random-Restart Hill-Climbing (RRHC)
- To avoid being stuck at a local maximum or plateau, you can repeatedly restart from random initial states, keeping track of the best solution found.
- This doesn’t guarantee a global optimum but often yields a reasonably good solution.
-
Summary
Hill-Climbing is a greedy local search. It is simple and memory-efficient but can fail to find the global optimum due to local maxima or flat regions. Random restarts can mitigate some of these issues.
2. 中文翻译 (Literal Chinese Translation)
-
定义
爬山法(Hill-Climbing)是一种局部搜索算法,通过从当前状态转移到邻居状态中能让评估函数**最大化(或改进)**的那个状态来进行迭代。它不维护完整的搜索路径或树结构,仅存储当前状态及其目标函数值。 -
核心机制
- 循环:评估所有邻居 → 选出“最佳邻居” → 如果该邻居比当前状态好,则移动到邻居;否则停止。
- 类似于在目标函数的地形上“往上爬坡”,不断追求更高的值。
-
缺点
- 局部最大值:算法可能停留在比全局最大值更低的峰顶上。
- 高原:目标函数值相同的平坦区域,使得算法无从判断如何改进。
- 山脊 / 肩部:倾斜或狭窄的结构,单步移动难以有效爬升。
-
随机重启爬山法(Random-Restart Hill-Climbing, RRHC)
- 为避免困在局部最大值或高原,可以多次从随机初始状态开始运行爬山法,并记录最优解。
- 虽然不保证找到全局最优,但往往能得到一个相对较好的解。
-
小结
爬山法是一种贪心式的局部搜索。优点是简单、占用内存小,但易受局部极值或平台影响。使用随机重启可缓解部分问题。
3. 中文通俗解释 (Chinese Plain Explanation)
- 怎么做:每次都看看当前状态附近哪儿更“好”(评估值更高),就挪一步过去。
- 问题:可能爬到一座“小山顶”(局部最大)就以为到了终点,实际上山后面还有更高的山;或者遇到“一大片平地”(平台),看不到该往哪走。
- 对策:多次“重新开始”,从不同随机位置继续“爬山”,希望能碰上更高的山顶。
- 适用场景:只想快速找到一个还不错的解决方案,且不要求一定是全局最优,或状态空间比较大、内存有限时。
4. 关键词对照表 (Key Terms)
| 英文 | 中文 | 解释 |
|---|---|---|
| Hill-Climbing (Search) | 爬山法(搜索) | 反复从当前状态移动到更优邻居状态的贪心式局部搜索 |
| Neighbor (State) | 邻居(状态) | 与当前状态只差一个“小改动”的状态 |
| Local Maximum | 局部最大值 | 比周围状态高但非全局最优 |
| Plateau | 高原/平台 | 邻居状态的目标函数值都相同,无法判断如何改进 |
| Random-Restart Hill-Climbing | 随机重启爬山法 | 多次随机初始化以避免陷入局部极值或平台 |
| Global Maximum | 全局最大值 | 状态空间中最高点,对比局部最大值 |
| Shoulder / Ridge | 肩部 / 山脊 | 表面倾斜或狭窄且难以通过小步“爬”过去的区域 |
5. 英文记忆笔记 (English Memory Notes)
-
Algorithm:
- Loop: Evaluate neighbors → pick the highest-value neighbor → move or stop.
- Only store current state + objective value.
-
Weaknesses:
- Stuck in local maxima.
- Plateaus: no clear direction.
- Ridges: narrow ascents are problematic.
-
Improvement:
- Random-Restart: Re-run hill-climbing from different random states, keep the best.
- No global optimality guaranteed, but can yield good results.
-
Use Cases:
- Quick solutions where memory is limited and perfect optimality is not mandatory.
Hint: Hill-Climbing = “Greedy Local Search.” Think of it as repeatedly picking the best immediate step upward in a mountainous landscape, but be aware of potential traps (local peaks, plateaus).
1. 核心关系
- Local search(局部搜索) 是一类搜索策略的总称,其特点是不维护完整路径,仅基于当前状态逐步优化,尝试找到最优解。
- Hill-Climbing search(爬山算法) 是局部搜索中的一种具体实现方法,属于贪心策略的局部搜索算法。
类比:
- Local search 像“所有在附近找更好解的算法”的统称(如“交通工具”)。
- Hill-Climbing 是其中一种具体工具(如“自行车”)。
2. 与图中搜索策略的对比
图中的 Uniformed search strategies(无信息搜索策略)(如BFS、DFS)与 Local search 有本质区别:
| 对比维度 | Uniformed Search(图中策略) | Local Search(包括爬山算法) |
|---|---|---|
| 目标 | 找到从起点到目标的完整路径 | 直接寻找最优解(不关心路径,只关注最终状态) |
| 内存使用 | 维护所有可能路径,内存消耗大 | 仅维护当前状态,内存消耗小 |
| 适用场景 | 路径规划、解空间较小的问题 | 优化问题(如函数极值、参数调优) |
| 是否保证最优解 | 某些策略(如BFS、Uniform-cost)保证最优 | 通常不保证全局最优(可能陷入局部最优) |
3. Hill-Climbing 的特点(以例子说明)
-
核心思想:从当前状态出发,不断向邻近的更好状态移动,直到无法改进。
-
例子:
假设你要找一座山的最高点(目标),但你被蒙住眼睛(无全局信息),只能通过脚踩地面判断坡度:- 每次向“上坡方向”走一步(贪心选择)。
- 直到四周都是下坡,则认为到达了山顶(可能是局部最高点,而非全局最高点)。
-
缺陷:容易陷入局部最优(如停在一个小山丘,而非真正的最高峰)。
4. 为什么图中未直接提到 Local Search?
图中的搜索策略(如BFS、DFS)属于 Systematic Search(系统化搜索),特点是遍历所有可能路径,适用于结构化问题(如迷宫、树状路径)。
而 Local search(如爬山算法)属于 Metaheuristic(元启发式),适用于解空间巨大或连续的问题(如机器学习参数优化、旅行商问题),两者属于不同的搜索范式。
总结
- Hill-Climbing 是 Local search 的子集,属于贪心型局部优化方法。
- Local search 与图中策略互补:
- 系统化搜索(BFS/DFS)保证解但效率低,适合小规模问题。
- 局部搜索(如爬山)效率高但不保证最优,适合大规模或复杂优化问题。
一句话记忆:
图中策略是“地毯式排查”,Hill-Climbing是“摸黑爬山”;前者找路径,后者直接找最优解。
Local Beam Search
英文复述 (English Summary)
Design & Mechanism
- Core Structure: Local Beam Search maintains k parallel current states (initially random), generating m successors per state (total m×k nodes) at each step.
- Selection Strategy: If a goal state is found, terminate; otherwise, retain the top k successors from the combined m×k pool for the next iteration.
- Visualization: Illustrated via a binary tree, where each depth level represents expanding states and pruning non-optimal paths.
Key Properties
- Parallel Exploration: Avoids over-reliance on a single path (unlike Hill-Climbing).
- Memory Efficiency: Only tracks k states per iteration, unlike systematic searches (e.g., BFS/DFS) that store all paths.
- Risk of Premature Convergence: May discard globally optimal paths early if all k states cluster in a suboptimal region.
Example
- Traveling Salesman Problem (TSP):
- Use k=5 random routes.
- Generate all possible route variations (e.g., swapping two cities) for each route.
- Keep the 5 shortest routes and repeat until no improvement.
Applications
- Natural Language Processing: Generate diverse text candidates in machine translation.
- Combinatorial Optimization: Solve scheduling or resource allocation with multiple candidate solutions.
- Genetic Algorithms: Beam search parallels population-based evolution strategies.
中文翻译 (Chinese Translation)
设计与机制
- 核心结构:局部束搜索维护 k 个并行当前状态(初始随机生成),每一步为每个状态生成 m 个后继节点(总计 m×k 个节点)。
- 选择策略:若找到目标状态则终止;否则从 m×k 个节点中保留 最优的 k 个 进入下一轮迭代。
- 可视化:通过二叉树图示展示状态扩展和非最优路径剪枝。
核心性质
- 并行探索:避免依赖单一路径(对比爬山算法)。
- 内存高效:每轮仅追踪 k 个状态,优于存储全部路径的系统化搜索(如BFS/DFS)。
- 早熟收敛风险:若所有 k 个状态聚集于次优区域,可能丢弃全局最优解。
示例
- 旅行商问题(TSP):
- 初始生成 k=5 条随机路线。
- 为每条路线生成所有可能变体(如交换两个城市)。
- 保留最短的5条路线并重复,直到无法改进。
应用场景
- 自然语言处理:机器翻译中生成多样化文本候选。
- 组合优化:解决调度或资源分配问题。
- 遗传算法:束搜索与种群进化策略类似。
中文通俗解释 (Plain Chinese Explanation)
一句话总结:
局部束搜索像“团队分头探路”——派k个人随机出发,每走一步都让每个人尝试所有可能方向,然后集体投票选最好的k条路继续走。
生活例子:
- 情景:你在森林里迷路了,带着5条狗分头找出口。
- 初始化:5条狗随机朝不同方向跑(k=5)。
- 扩展:每条狗探索周围10条小路(m=10),共50条路径。
- 选择:从50条路中选5条离出口最近的,让狗继续探索。
- 终止:若有狗找到出口,成功;否则重复步骤2-3。
优缺点:
- 优点:人多力量大,避免“一个人走死胡同”;内存消耗小(只需记住5条路)。
- 缺点:如果5条狗一开始全往错误方向跑,可能永远找不到正确出口。
英文记忆笔记 (English Memory Notes)
Design
- k parallel states → Randomly initialized.
- Expand m successors per state → Total m×k candidates.
- Select top k → Prune non-optimal paths.
Properties
- ✅ Parallelism → Avoid local optima traps.
- ✅ Low memory → Only track k states.
- ❌ Risk of missing global optimum → Depends on initial states.
Example
- TSP: Keep top k shortest routes from m×k variations.
Applications
- NLP: Text generation with diversity.
- Scheduling: Optimize multiple candidate solutions.
Key Formula:
Next k states = Top k from (Current k × m successors)
总结记忆口诀:
- 英文:“k states, m kids, pick the best, avoid the rest.”
- 中文:“k个状态生m娃,择优录取继续查。”
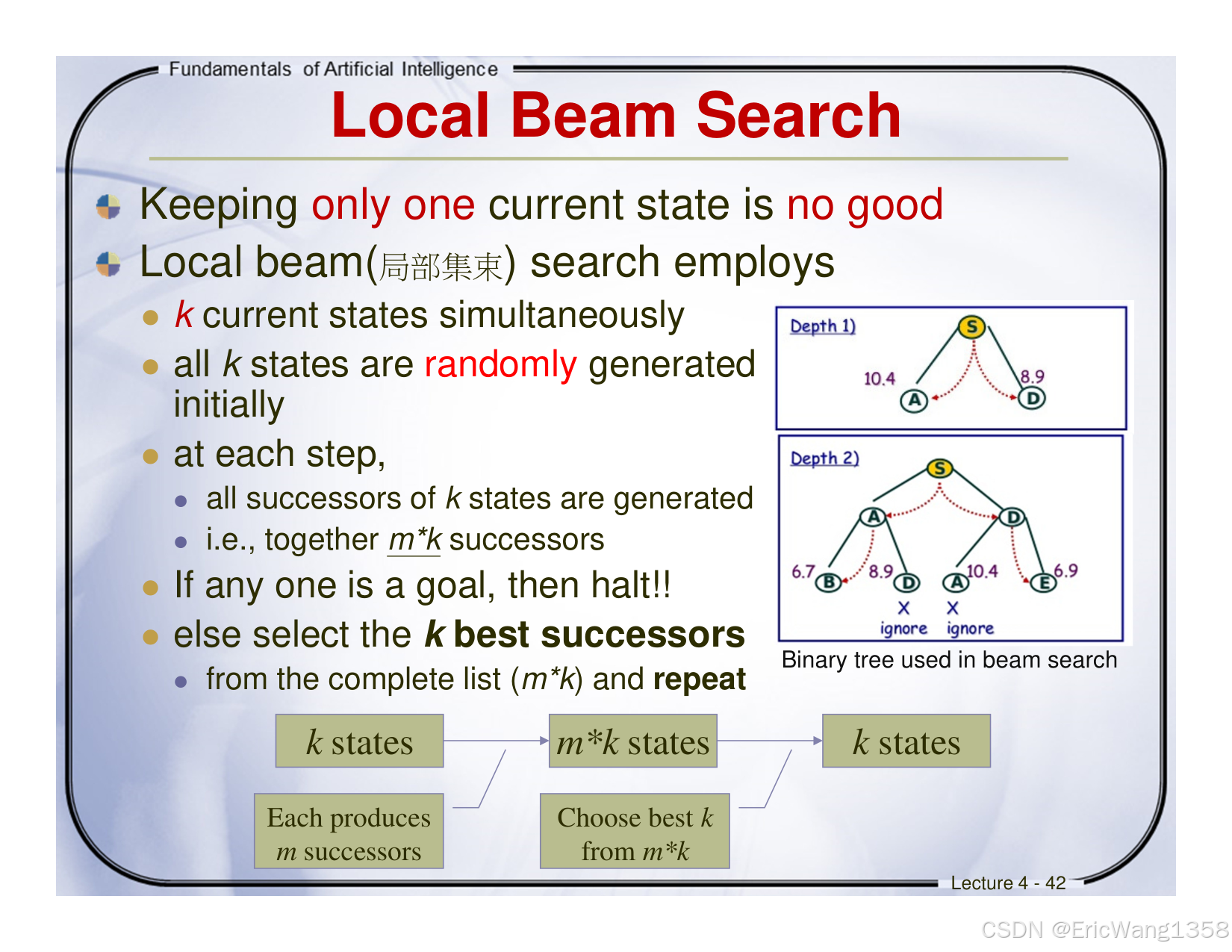
分步解释:什么是“随机k个”
根据图中的二叉树示例和文字描述,以下是通俗解释:
1. “随机k个”指的是什么?
- 定义:在算法开始时,随机生成k个不同的初始状态(即起点或候选解)。
- 目的:避免所有搜索集中在同一区域,增加找到全局最优解的概率。
类比:
假设你要在一片森林里找宝藏,但不知道宝藏的位置。
- 传统爬山算法:你一个人随机选一个方向开始找,可能困在局部区域。
- 局部束搜索:你雇佣了k个助手(如k=3),每个助手随机选一个方向出发,分开探索。
2. 图中的具体示例
根据图中文字和二叉树结构:
- 初始状态(Depth 1):随机生成k=2个状态(图中标注为A和D)。
- 这两个状态的位置:
- A和D可能代表不同的路径起点(如迷宫的不同入口)。
- 也可能代表同一问题中不同的候选解(如旅行商问题中的两条随机路线)。
例子(以数值为例):
- 初始随机生成两个状态A(代价10.4)和D(代价8.9)。
- 算法会同时探索A和D的后续路径,而非只选其中一个。
3. 为什么需要“随机生成”?
- 避免初始偏见:如果所有k个状态都从同一个起点开始,可能错过其他区域的更优解。
- 探索多样性:随机分散的初始状态能覆盖解空间的不同区域,减少陷入局部最优的风险。
对比场景:
- 单一起点(如爬山算法):
若起点附近有局部最优解(小山丘),算法可能困在此处。 - 随机k个起点(束搜索):
即使部分状态陷入局部最优,其他状态仍可能在更优区域继续搜索。
4. 与“起点不一样”的关系
- 若问题有明确起点(如迷宫入口唯一):
“随机k个”指从该起点出发,生成k条不同的初始路径(例如随机走前几步)。 - 若问题无明确起点(如优化问题):
“随机k个”指在解空间中随机生成k个候选解(如随机参数组合)。
示例:
- 迷宫问题:
k=3,随机生成三种不同的初始路径(如先左转、先右转、先直行)。 - 函数优化:
k=5,随机生成五个不同的初始参数值组合。
通俗总结
- “随机k个” = 多个人分头找路:
算法开始时,随机派k个“探路者”从不同位置(或不同路径)出发,各自探索。 - 核心作用:
避免所有人挤在同一区域,提高找到全局最优解的概率。
英文记忆笔记
- Random k states = Initially generate k different candidates randomly.
- Purpose → Diversify exploration and avoid local optima.
- Example:
In TSP, start with k=3 random routes (e.g., A→B→C→D, D→C→A→B, B→A→D→C).
Key Formula:
Initialization: k = random_states()
一句话理解:
“随机k个”就像抽奖时多买几张不同号码的彩票——增加中奖(找到最优解)的机会! 🎟️
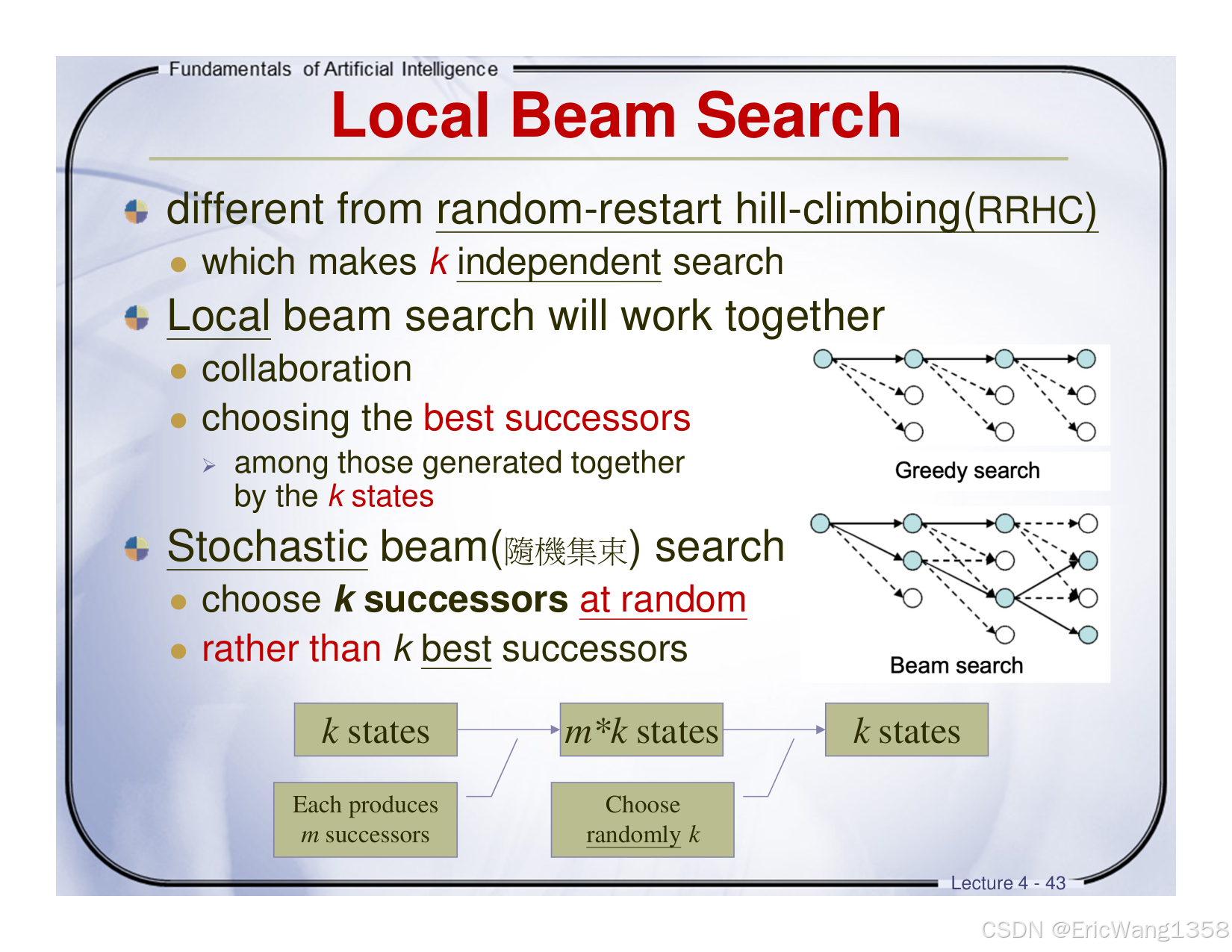
核心内容总结
根据图片内容,局部束搜索(Local Beam Search) 和 随机束搜索(Stochastic Beam Search) 是两种基于并行化的启发式搜索策略,核心区别在于选择后继状态的规则。以下是详细解析:
1. 局部束搜索(Local Beam Search)
核心机制
- 初始化:随机生成 k 个独立初始状态(如k=3条不同的路径)。
- 扩展:每个状态生成 m 个后继状态(如每条路径尝试3种改进方向),共生成 k×m 个候选状态。
- 选择:从所有候选状态中选出 最优的 k 个,作为下一轮迭代的起点。
- 终止:重复上述步骤,直到找到目标或无法改进。
关键特点
- 合作式搜索:k 个状态协同工作,共享候选池并筛选全局最优解。
- 贪心策略:始终保留当前最优的 k 个状态(类似“精英选拔”)。
- 对比 RRHC:不同于随机重启爬山法(RRHC)的多次独立搜索,束搜索通过并行协作提高效率。
示例(以路径规划为例):
- 初始3条路径(k=3)→ 每条生成2条新路径(m=2)→ 共6条候选 → 保留最短的3条继续。
2. 随机束搜索(Stochastic Beam Search)
核心机制
流程与局部束搜索相同,但选择规则不同:
- 不从候选池中选最优的 k 个,而是随机抽取 k 个(允许非最优状态保留)。
- 随机性增加了多样性,避免过早收敛到局部最优。
关键特点
- 探索与利用平衡:随机选择可能保留潜在优质解(类似遗传算法的“轮盘赌”策略)。
- 适用场景:当问题空间复杂、存在多个局部最优时,随机性有助于跳出局部陷阱。
示例(以函数优化为例):
- 候选池中有6个解 → 随机抽取3个(可能包含次优但多样性高的解)→ 继续迭代。
3. 与随机重启爬山法(RRHC)的对比
| 维度 | 局部束搜索 | 随机重启爬山法(RRHC) |
|---|---|---|
| 搜索方式 | 并行维护k个状态,协同生成候选池 | 串行执行多次独立爬山搜索(每次随机重启) |
| 内存效率 | 仅需保存k个状态 | 每次独立搜索需重新初始化,内存消耗更高 |
| 全局收敛性 | 更易找到全局最优(多状态协作) | 依赖重启次数,可能重复陷入局部最优 |
| 选择策略 | 贪心选优 或 随机抽取 | 每次独立爬山均为贪心策略 |
4. 流程图解析(示例)
根据图片中的流程:
- 初始 k 个状态(如k=2)→ 每个生成 m 个后继(如m=2)→ 总候选池为4个状态。
- 选择阶段:
- 局部束搜索:选2个最优状态(如代价最低的)。
- 随机束搜索:随机选2个状态(可能包含次优解)。
- 重复扩展和选择,直到终止。
通俗比喻:
- 局部束搜索像“高考择优录取”,只收分数最高的学生。
- 随机束搜索像“抽签录取”,保留多样性但可能漏掉尖子生。
应用场景
- 自然语言处理:机器翻译中生成多样化候选句子(束搜索)。
- 组合优化:旅行商问题(TSP)求解多组路线并择优。
- 机器人路径规划:并行探索多条路径,选择最短或最安全的。
通俗解释:为什么允许有k个起始点?
你的疑问非常合理!在传统路径问题(如迷宫寻路)中,确实只有一个物理起点,但局部束搜索(Local Beam Search) 的应用场景和设计逻辑与传统路径搜索不同。以下是分步解释:
1. 核心区别:优化问题 vs. 路径问题
-
传统路径问题(如BFS/A*):
- 固定起点:例如迷宫入口,目标是找到从入口到出口的单条最短路径。
- 搜索方式:系统化遍历所有可能路径(如逐层扩展)。
-
优化问题(如局部束搜索):
- 无固定起点:目标是找到全局最优解(如最短路线、最佳参数组合等),而非固定起点到终点的路径。
- 搜索方式:随机生成多个候选解(即“k个起始点”),并行优化。
一句话总结:
局部束搜索的“k个起始点”不是物理位置,而是多个随机生成的候选解。
2. 为什么需要k个起始点?
问题场景:
假设你要解决旅行商问题(TSP),即找到访问所有城市的最短路线。
- 传统路径搜索(如BFS):从某一城市出发,穷举所有路线,但计算量爆炸(城市数稍大即不可行)。
- 局部束搜索:
- 随机生成k条初始路线(如k=5条随机排列的路线)。
- 每条路线作为“起始点”,各自尝试优化(如交换两城市顺序)。
- 保留优化后最好的k条路线,重复直到收敛。
优势:
- 避免局部最优:即使部分路线陷入局部最优,其他路线可能继续优化。
- 高效探索:多路线并行,比单一路线搜索更快找到全局最优解。
3. 图中的“k个起始点”如何理解?
根据图片中的示例:
- k个起始点 = 随机生成的k个候选解(如k=2条初始路线)。
- 每个起始点生成m个后继 = 对每条路线进行m次改进尝试(如交换城市、反转路径等)。
- 最终选择k个后继 = 保留改进后最好的k条路线(或随机选k条)。
类比生活场景:
- 你想找到从家到公司的最快路线,但不确定哪条路好走。
- 传统方法:每天固定走一条路,慢慢试错。
- 束搜索方法:
- 雇5个朋友(k=5),每人随机选一条路出发(起始点不同)。
- 每个朋友尝试绕道或换小路(生成后继路径)。
- 每天结束后,选5条最快到达的路线,第二天继续优化。
4. 为什么图片中说“不同于随机重启爬山法(RRHC)”?
-
随机重启爬山法(RRHC):
- 单线程搜索:每次随机生成一个起点,独立优化到局部最优后,重启新搜索。
- 缺点:多次独立搜索可能重复陷入同一局部最优。
-
局部束搜索:
- 多线程协作:k个候选解共享信息(如合并优化结果),协作寻找全局最优。
- 优点:通过并行和协作,更高效避免局部最优。
示例对比:
- RRHC:5个人各自独立找路,互不交流,可能重复找到同一拥堵路线。
- 束搜索:5个人每天共享最快路线,集体优化,更快找到全局最优解。
总结
| 概念 | 传统路径问题(BFS/A*) | 局部束搜索(优化问题) |
|---|---|---|
| 起点 | 固定物理起点(如迷宫入口) | 多个随机生成的候选解(如随机路线) |
| 目标 | 单条最短路径 | 全局最优解(如最短路线、最佳参数) |
| 核心逻辑 | 系统化遍历所有可能路径 | 并行优化多个候选解 |
关键结论:
- 局部束搜索的“k个起始点”本质是多个随机初始解,用于解决无固定起点的全局优化问题。
- 它的优势在于通过并行协作平衡探索(多样化尝试) 和 利用(优化当前最佳解)。

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









