







参考代码:CBAM.PyTorch
1. 概述
导读:这篇文章通过在卷积网络中加入Attention模块,使得网络的表达能力得到提升,进而提升网络的整体性能。文章的Attention模块是在卷积特征的channel于spatial两个维度上先后做Attention操作,之后得到增强之后的特征。并且这个Attention模块具有极佳的模块化性能能够很方便的集成到现有的网络中去,从而带来性能上的提升。
在文章中需要优化的特征图为
F
∈
R
C
∗
H
∗
W
F\in R^{C*H*W}
F∈RC∗H∗W,经过channel上的Attention为
M
c
∈
R
C
∗
1
∗
1
M_c\in R^{C*1*1}
Mc∈RC∗1∗1,spatial上的Attention操作之后得到
M
s
∈
R
1
∗
H
∗
W
M_s\in R^{1*H*W}
Ms∈R1∗H∗W,其计算过程见图1所示:
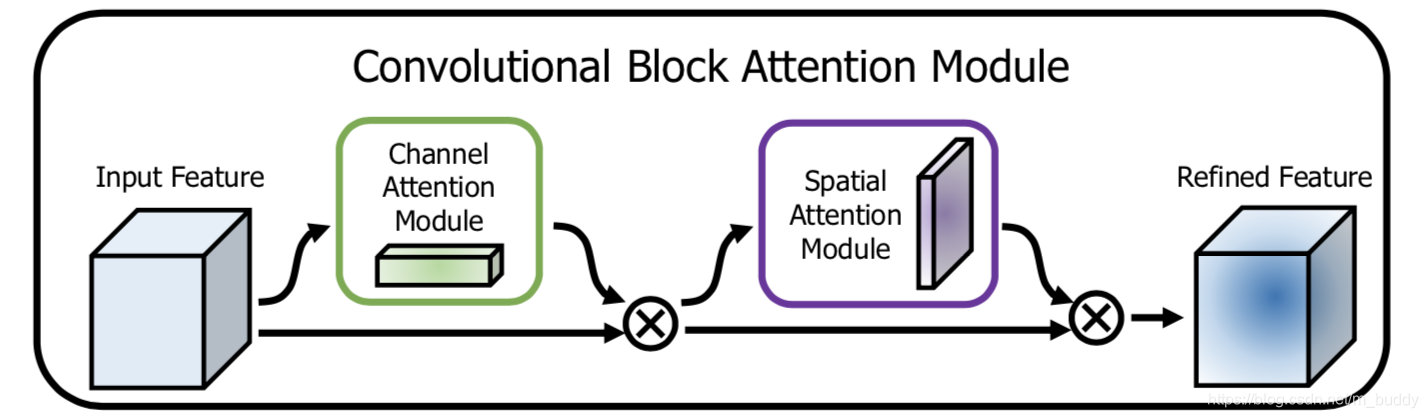
对应的数学表达为:
F
‘
=
M
c
(
F
)
⊗
F
F^{‘}=M_c(F)\otimes F
F‘=Mc(F)⊗F
F
‘
’
=
M
s
(
F
‘
)
⊗
F
‘
F^{‘’}=M_s(F^{‘})\otimes F^{‘}
F‘’=Ms(F‘)⊗F‘
2. 方法设计
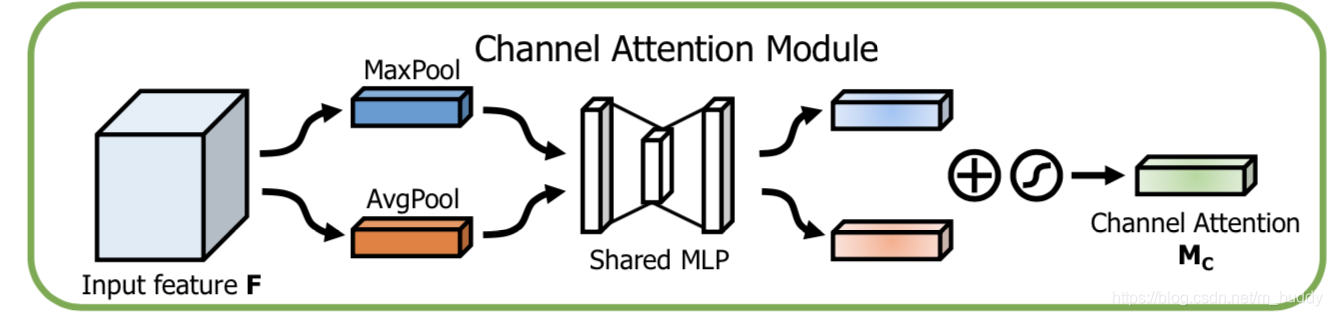
2.1 channel上的Attention
对于输入的特征图
F
F
F首先经过两个分支:channel维度的全局平均池化以及全局最大池化得到对应的特征向量
F
a
v
g
c
,
F
m
a
x
c
∈
R
C
∗
1
∗
1
F_{avg}^c,F_{max}^c\in R^{C*1*1}
Favgc,Fmaxc∈RC∗1∗1,之后经过映射得到对应的Attention向量
M
c
∈
R
C
∗
1
∗
1
M_c\in R^{C*1*1}
Mc∈RC∗1∗1。在这映射的过程中会经过多层感知机组成的网络和sigmoid激活函数,因而这个运算过程可以描述为:
M
c
(
F
)
=
σ
(
W
1
(
W
0
(
F
a
v
g
c
)
)
+
W
1
(
W
0
(
F
m
a
x
c
)
)
)
M_c(F)=\sigma(W_1(W_0(F_{avg}^c))+W_1(W_0(F_{max}^c)))
Mc(F)=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))
其对应的运算流程见下图所示:
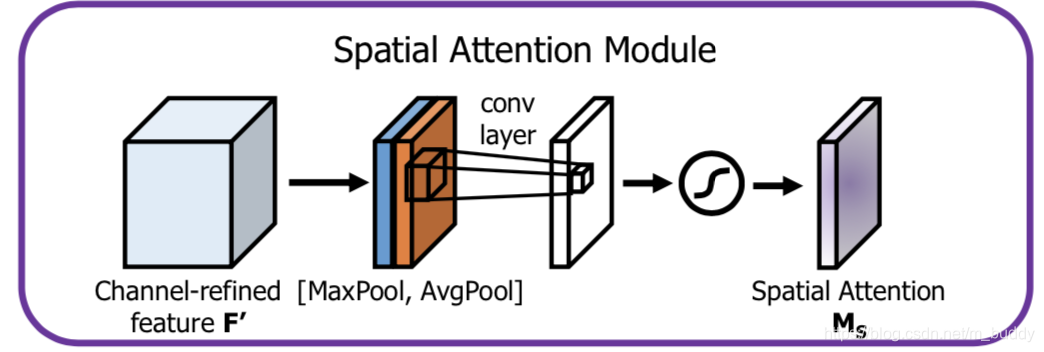
2.2 spatial上的Attention
在得到channel上的Attention特征图之后结下来就是对其进行spatial上的Attention操作。文中首先对特征图在channel维度上进行池化得到特征图
F
a
v
g
s
,
F
m
a
x
s
∈
R
C
∗
1
∗
1
F_{avg}^s,F_{max}^s\in R^{C*1*1}
Favgs,Fmaxs∈RC∗1∗1,再将其concat起来,最后得到特征图的维度是
M
s
(
F
)
∈
R
H
∗
W
M_s(F)\in R^{H*W}
Ms(F)∈RH∗W。因而文章在spatial上的Attention其流程见下图所示:
其对应的数学表达式为:
M
s
(
F
)
=
σ
(
C
o
n
v
7
∗
7
(
[
F
a
v
g
s
,
F
m
a
x
s
]
)
)
M_s(F)=\sigma(Conv_{7*7}([F_{avg}^s,F_{max}^s]))
Ms(F)=σ(Conv7∗7([Favgs,Fmaxs]))
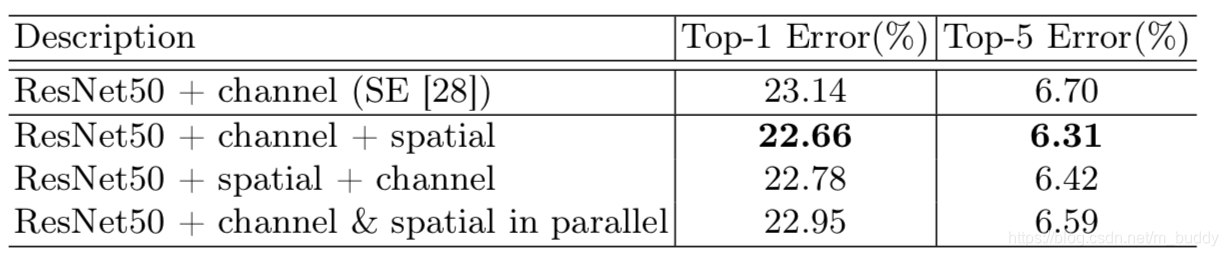
3.1 实验结果
性能比较:
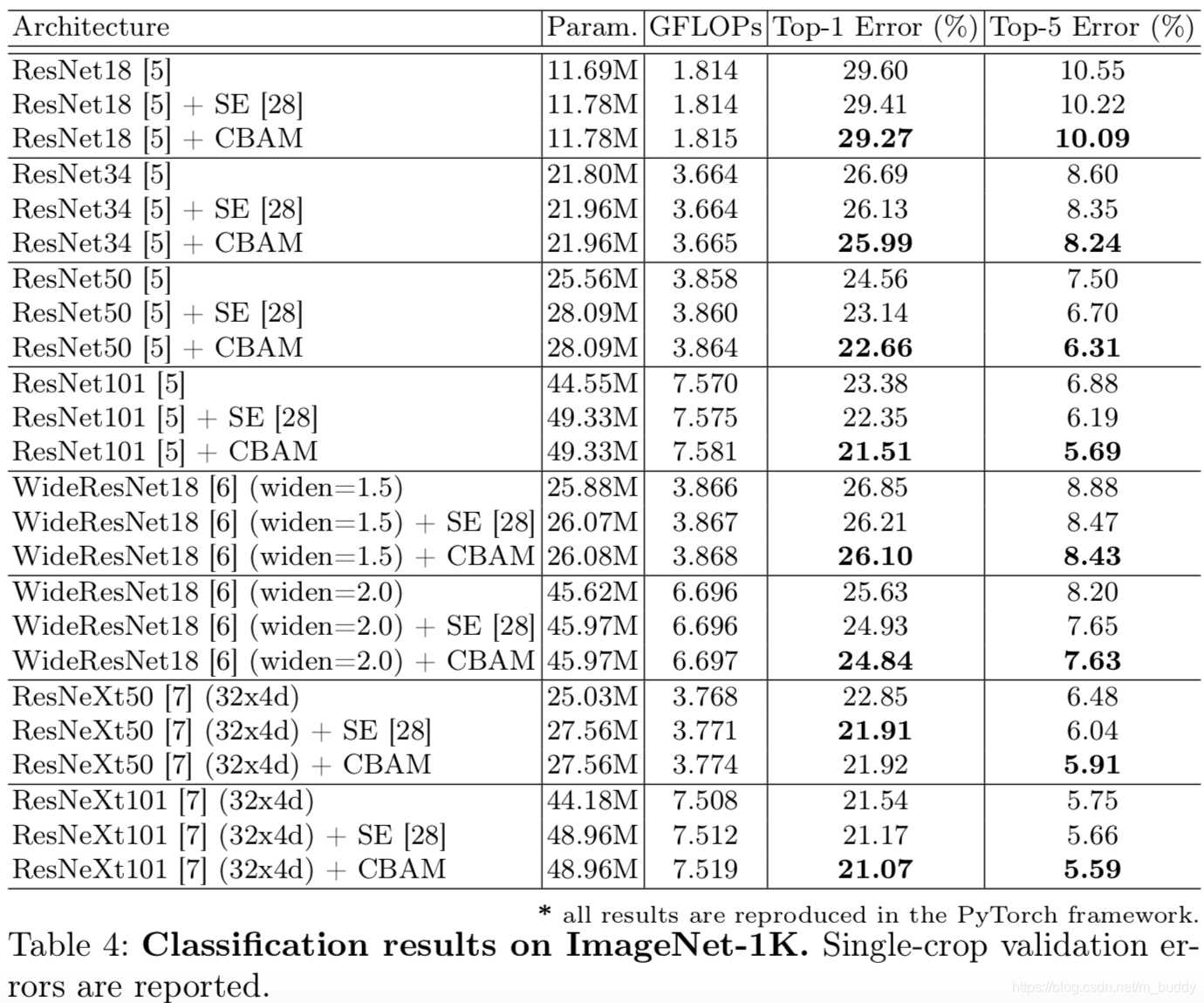
spatial和channel上排列组合对性能的影响:















 6047
6047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









