







参考代码:StreamPETR
1. 概述
介绍:在BEV感知中时序信息融合会为下游感知任务带来不小性能提升,但是在单帧基础上引入时序信息必然会带来额外开销,因而迫切需要一种高性能且代价小的融合方案。现有的一些时序融合策略多是在BEV特征空间维度上完成的,并且对于一些DETR-based方案本身就没有显式构建BEV特征,如PETR,则BEV特征空间上的时序融合方法就不适用了。对此,这里基于PETR中DETR-based方案提出了一种使用query实现多桢object-centric的时序融合策略,也就是不在BEV特征或者图像特征维度实现时序融合,只是在query针对目标去做融合。由于感知的目标是可能存在运动的,则需要建立起帧间运动关系,这里可以使用目标的运动信息(间隔时间、速度、相机内外参数等)构建目标的运动感知模块(MLN,motion-aware layer normalization),这样就可以为场景中的运动目标进行处理。
之前工作中对于BEV特征融合的策略可以为下图中的左边两幅图:
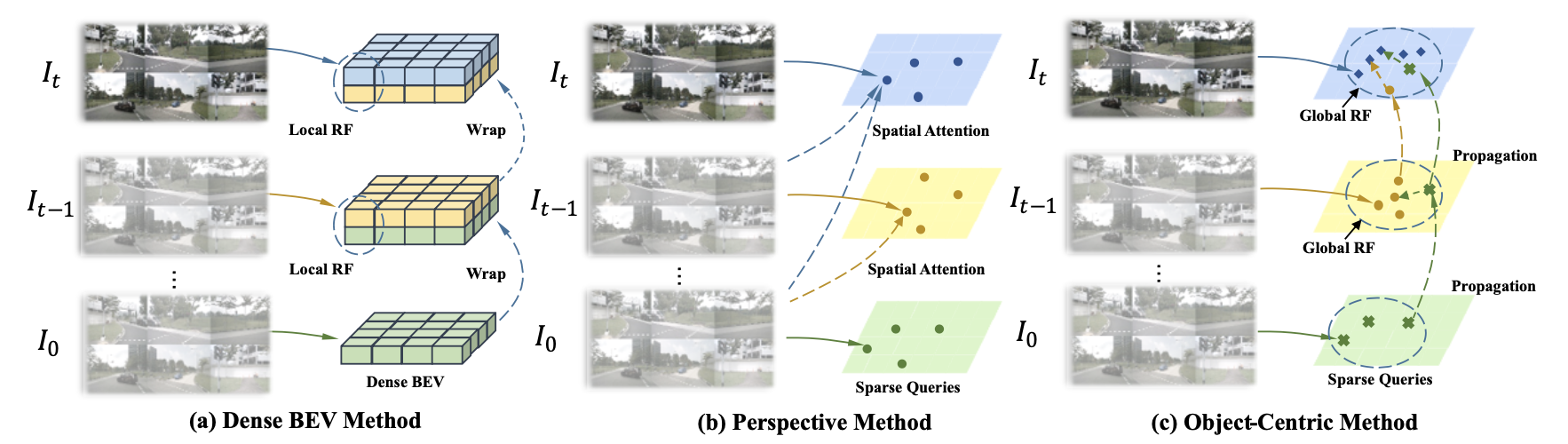
直接特征图上的时序关联:
这种类型的时序建模是直接操作于BEV空间上,如对不同时刻BEV特征在经过帧间pose对齐之后,通过一个网络直接融合,典型方法如BEVFusion:
F ˉ b e v t = φ ( F b e v t − 1 , F b e v t ) \bar{F}_{bev}^t=\varphi(F_{bev}^{t-1},F_{bev}^t) Fˉbevt=φ(Fbevt−1,Fbevt)
只用前面一帧的信息太少了,可以多利用之前帧的信息,典型方法是SOLOFusion:
F ˉ b e v t = φ ( F b e v t − k , … , F b e v t − 1 , F b e v t ) \bar{F}_{bev}^t=\varphi(F_{bev}^{t-k},\dots,F_{bev}^{t-1},F_{bev}^t) Fˉbev
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









