







 本文介绍了一种新型的点云Transformer架构FlatFormer,通过改进窗口注意力机制和组划分策略,实现在保持高精度的同时,比现有方法如SST和CenterPoint显著降低延迟,特别适合于资源受限的自动驾驶应用。
本文介绍了一种新型的点云Transformer架构FlatFormer,通过改进窗口注意力机制和组划分策略,实现在保持高精度的同时,比现有方法如SST和CenterPoint显著降低延迟,特别适合于资源受限的自动驾驶应用。
本文由麻省理工学院、上海交通大学、清华大学于2023年7月14日发表于Arxiv的<Computer Science>

论文:
代码:
Abstract:
Transformer,作为CNN的替代品,已在许多模态(例如,文本和图像)中证明其有效性。对于3D点云Transformer,现有研究主要集中在将它们的准确性推至最先进水平。然而,它们的延迟落后于稀疏卷积模型(3倍 slower),这阻碍了它们在资源受限、延迟敏感的应用中的使用(例如,自动驾驶)。这种低效性源于点云的稀疏和不规则性质,而Transformer是为了密集、规则的工作负载而设计的。
本文提出了FlatFormer,通过以空间邻近度为代价换取更好的计算规律来弥补这一延迟差距。作者首先对点云进行窗口排序,并将其分成大小相等的组,而不是形状相等的窗口。这样,可以有效地避免昂贵的结构化和填充开销。然后,在组内应用自注意力来提取局部特征,交替排序轴来收集不同方向的特征,并移动窗口以跨组交换特征。
FlatFormer在Waymo Open Dataset上实现了最先进的准确性,同时比(基于Transformer的)SST快4.6倍,比(稀疏卷积的)CenterPoint快1.4倍。这是第一个在边缘GPU上实现实时性能的点云Transformer,同时比稀疏卷积方法快,且在大规模基准测试上达到与大规模基准测试相当或甚至更好的准确性。
Introduction:
Transformer已成为自然语言处理(NLP)中的首选模型,作为许多成功的大语言模型(LLMs)的Backbone 。最近,其影响力进一步扩展到视觉领域,视觉Transformer(ViTs)已在许多视觉模态(例如,图像和视频)中展现出与卷积神经网络(CNNs)相当或甚至更好的性能。然而,3D点云尚未成为其中的一部分。
与图像和视频不同,3D点云固有地稀疏且不规则。大多数现有的点云模型基于3D稀疏卷积,它只在非零特征上计算卷积。它们需要专用的系统支持才能在并行硬件(例如,GPUs)上实现高利用率。
许多研究致力于点云 Transformer (PCTs),以探索它们作为稀疏卷积的替代品的潜力。全局点云 Transformer得益于自注意力的一致计算模式,但受到与点数平方成正比的计算成本(相对于点数)的严重影响。局部点云 Transformer将自注意力应用于定义在类似基于点模型的局部邻域,因此受到昂贵邻居收集的限制。这些方法仅适用于单个物体或部分室内扫描(少于4k个点)且无法有效地扩展到室外场景(超过30k个点)。
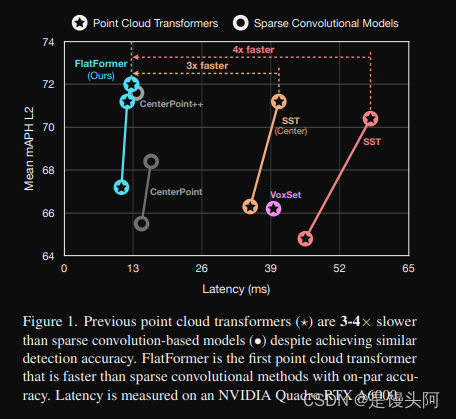
受到Swin Transformer的启发,窗口点云 Transformer在窗口 Level 计算自注意力,在大规模3D检测基准测试上实现了惊人的准确性。尽管这些窗口在空间上具有规律性,但由于稀疏性,它们的点数可能会有极大的不同(相差超过80倍)。这种严重的失衡导致冗余计算和低效的填充和分区开销。因此,窗口点云 Transformer 比稀疏卷积模型慢3倍(如图1所示),限制了它们在资源受限、延迟敏感场景(例如,自动驾驶,增强现实)中的应用。
本文引入了FlatFormer来缩小这一巨大的延迟差距。在构建基于窗口的点云 Transformer (window PCTs)的基础上,FlatFormer通过将3D点云分成“相等大小的组”而不是“相等形状的窗口”来换取更好的计算规律。在组内应用自注意力来提取局部特征,交替排序轴来收集不同方向的特征,并移动窗口以跨组交换特征。
得益于规则的计算模式,FlatFormer在Waymo Open Dataset上实现了最先进的准确性,同时比(基于Transformer的)SST快4.6倍,比(稀疏卷积的)CenterPoint快1.4倍。这是第一个在边缘GPU上实现实时性能的点云 Transformer ,同时比稀疏卷积方法快,且在大规模基准测试上达到与大规模基准测试相当或甚至更好的准确性。
到作者为止,FlatFormer是第一个在较低延迟下达到稀疏卷积方法相等或更好的准确性,同时比卷积神经网络(CNN)快得多的点云 Transformer 。它也是第一个在边缘GPU上实现实时性能的点云 Transformer 。在更好地支持 Transformer (例如,NVIDIA Hopper)的硬件支持下,点云 Transformer 将具有巨大的潜力成为3D深度学习中的首选模型。
Why are Point Cloud Transformers Slow?
论文原话:尽管点云 Transformer (PCTs)正在逐步赶上稀疏卷积检测器的准确性,但它们与最快的PCT(SST)和稀疏卷积CenterPoint之间的延迟仍存在3倍差距(图1)。在本节中剖析了PCTs效率的瓶颈,这为FlatFormer的设计奠定了坚实的基础。
Global PCTs
受到ViT的启发,点云上 Transformer 的最简单和直接的设计是全局PCTs,其中每个点都是一个标记。它们在整个点云上利用多头自注意力(MHSA)进行全局处理。虽然全局PCTs在小型3D物体上有效,但由于其
![]()
的复杂度,在扩展到大场景时表现不佳,其中N是标记数,D是通道数。
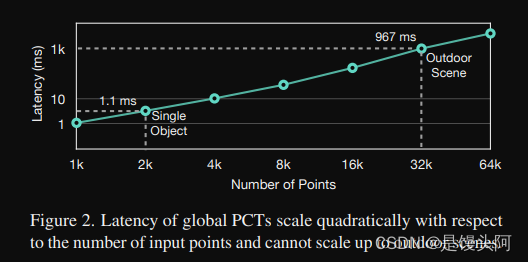
如图2所示,全局PCTs的运行时间随着输入点数增长而呈平方增长。例如,在32k输入点*的情况下,该模型在NVIDIA A6000 GPU上执行需要近一秒钟,比CenterPoint慢66倍。
Local PCTs
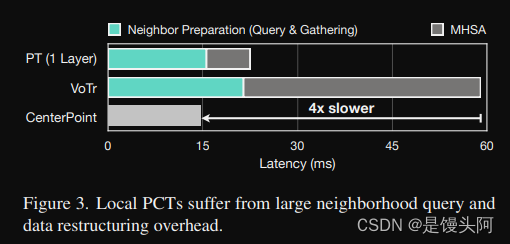
研究行人提出了局部PCTs来解决全局PCTs的可扩展性问题。它们将多头自注意力(MHSA)应用于每个点的邻居,而不是整个点云。因此,它们的计算复杂度为,
![]()
其中N是点数,K是每个点的邻居数,D是通道数。由于对于实际工作负载,N的范围在20k到100k之间,K小于64,因此它们的理论成本比全局PCTs低得多。
Window PCTs
Swin Transformers在各种视觉识别任务上的巨大成功催生了窗口PCTs的设计,其中,SST是代表性工作。它首先将点云投影到鸟瞰空间(BEV空间),然后将BEV空间划分为大小相等、非重叠的窗口,并在每个窗口内应用多头自注意力(MHSA)。与Swin Transformer类似,SST使用窗口平移来实现窗口间的信息交换。
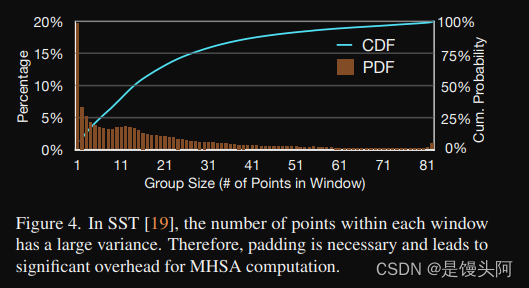
与图像不同,点云是稀疏且非均匀地分布在空间中的。因此,每个窗口内的点数不同,可以相差两个数量级(图4)。由于基本的MHSA Kernel 无法有效地支持可变序列长度,SST将大小相似的窗口分组,并将每个分组内的所有窗口都填充到该组内的最大值(图5)
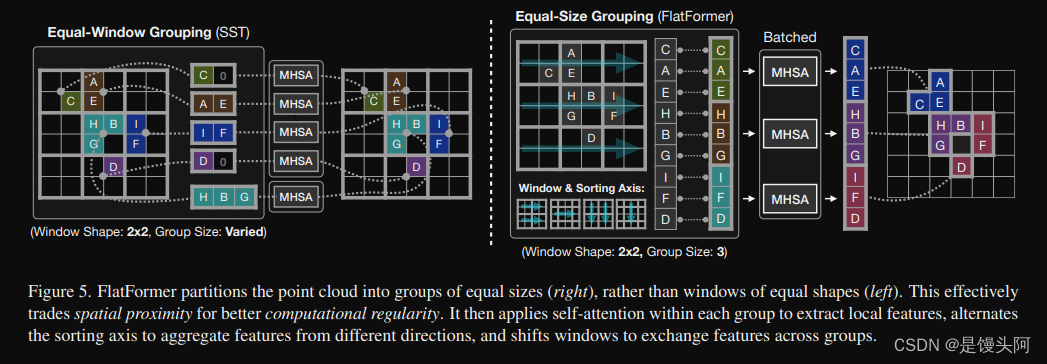
然后,在单独的每个分组内应用MHSA。在实际应用中,这种填充引入了1.7倍的计算开销。更糟糕的是,将点分成大小相等的窗口也引入了显著的延迟开销:在Waymo上,每个场景需要18毫秒,甚至比CenterPoint的总运行时间还要慢。总之,填充和分组的额外开销使得SST在硬件友好性方面比稀疏卷积方法差。
FlatFormer
在第3节中学到的所有经验教训,作者将设计作者的点云 Transformer 以实现可扩展性和高效性。
Overview
FlatFormer的基本构建模块是Flattened Window Attention (FWA)。如图5所示,FWA采用基于窗口的排序来平铺点云并将其划分为大小相等的组,而不是形状相等的窗口。这自然地解决了组大小不平衡问题并避免了填充和分组开销。
FWA然后在每个组内应用自注意力来提取局部特征,交替排序轴来聚合不同方向的特征,并将窗口移动来跨组交换特征。最后,作者提供了一种改进的FWA实现,进一步提高了其效率并最小化了开销。
Experiments
数据集。作者在Waymo Open Dataset(WOD)上进行了作者的实验,该数据集包含1150个LiDAR点云序列。每个序列包含200帧,由360度视野的LiDAR传感器以每秒10帧的速度收集。有四个前景类别,其中三个(车辆、行人和骑行者)用于检测指标评估。
指标。作者遵循Waymo的官方指标来计算所有方法的标准3D mAP和 Head 加权3D mAP(mAPH)。车辆、行人和骑行者三个类别中的匹配IoU阈值设置为默认值(0.7,0.5和0.5)。物体分为两个难度 Level ,小于五个激光点或标记为困难的物体被归类为 Level 2(L2),其他物体定义为 Level 1(L1)。作者在主论文中主要报告L2指标,并在附录中提供详细指标。
模型。基于FWA,作者提供了一个实现FlatFormer的3D检测版本。遵循PointPillars的设计,首先将点云进行0.32m * 0.32m的voxel化,并在每个voxel上使用MLP。然后,应用8个连续的FWA块,每个块使用交替的排序轴(例如,x或y)和窗口平移配置(例如,开或关)。所有FWA块的窗口形状为9*9,组大小为69。遵循SST,作者没有应用任何空间降采样,这对小物体有益。最后,应用常规BEV编码器和基于中心检测Head,如CenterPoint。
为了执行所有稀疏卷积检测器的3D编码器。对于基于 Transformer 的检测器,作者使用它们的官方实现来测量运行时间。所有在3D编码器之后的模块(例如,BEV编码器和检测Head)都使用TensorRT 8.4执行。作者将在前1000个样本上执行所有方法50次。作者报告平均延迟(排除异常值)。作者不包括数据加载和后处理时间。
结果。与Table 1中的结果类似,作者的FlatFormer在稀疏卷积和基于 Transformer 的检测器之间实现了稳定的性能改进,同时具有更好的效率。对于单帧模型,FlatFormer比SST,SST-Center和最近的VoxSet快4.2倍,3.3倍和3.7倍。它还与强大的稀疏卷积 Baseline 相比具有优势:比CenterPoint快1.4倍,具有1.7更高的L2 mAPH,并达到与PillarNet相当的性能。在两帧设置中,FlatFormer的性能优势更加明显。
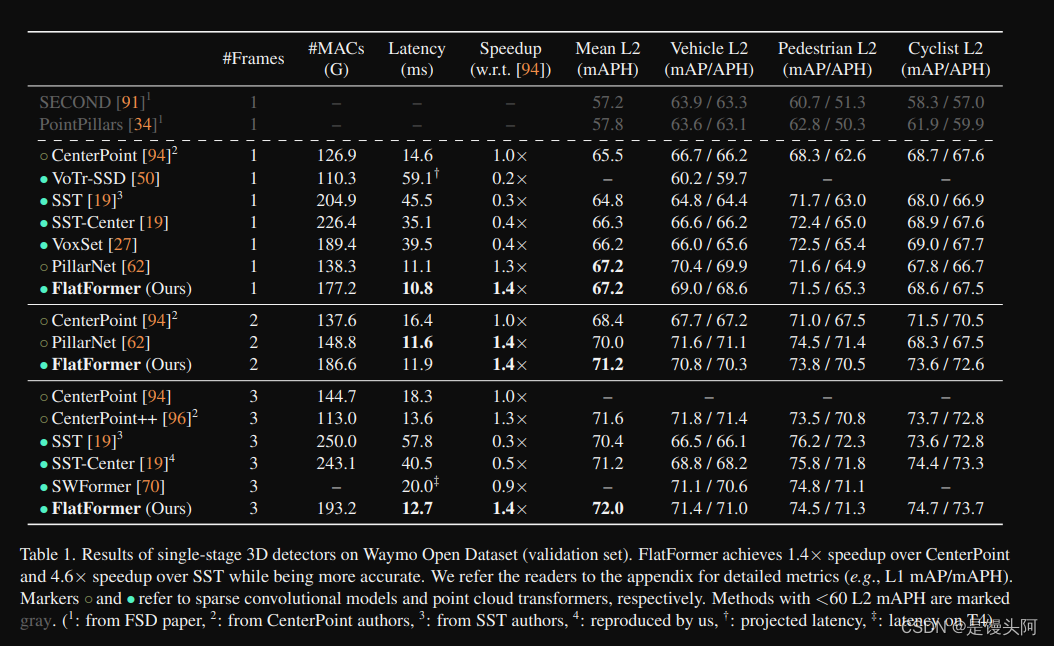
具体而言,FlatFormer比CenterPoint快1.4倍,具有2.8 L2 mAPH更高的准确性,并以类似的延迟超过PillarNet1.3 L2 mAPH。对于三输入帧,FlatFormer比SST和SST-Center分别快4.6倍和3.2倍。它还实现了更好的延迟-准确性权衡(比CenterPoint++快1.1倍,准确率提高0.4%)。
值得注意的是,尽管FlatFormer需要比CenterPoint++多1.7倍的MACs,但它仍然更快。这表明作者的设计比稀疏卷积 Baseline 更符合硬件需求。
部署。作者在NVIDIA Jetson AGX Orin上部署了作者的FlatFormer。这是资源受限的边缘GPU平台,广泛用于实际自动驾驶汽车。如图6所示,FlatFormer在16 FPS下运行,即1.2倍。
结果。所有现有高性能的两阶段检测器都是稀疏卷积的,而FlatFormer是唯一一种基于 Transformer 的实现,实现了最先进的准确性。与CenterFormer相比,FlatFormer在输入帧数方面的可扩展性更好。请注意,作者的论文主要关注优化3D Backbone 的延迟。然而,两阶段检测器通常在运行时由第二阶段瓶颈,这超出了作者的范围。作者期望FlatFormer的延迟可以受益于更高效的第二阶段设计。
Analysis
在本节中,作者提出了一些分析来验证作者设计选择的有效性。所有实验基于作者使用20%数据训练的单帧模型。
Conclusion
本文介绍了FlatFormer,用于弥合点云 Transformer 和稀疏卷积模型之间的巨大效率差距。它采用相等大小的组划分而不是相等窗口的组划分,以换取计算规律性。
FlatFormer在Waymo Open Dataset上实现了最先进的准确性,比之前的点云 Transformer 快4.6倍。作者希望FlatFormer可以激发未来研究设计高效且准确的点云 Transformer
写在最后:
此外,也欢迎大家加入我们的脑机接口群聊,本人每天会分享一些资料,主要是CNN、RNN,Transfomer等DL模型用于处理BCI生理数据,涉及到BCI数据的预处理,特征工程,建模(ML,DL都有),结果可视化(混淆,ACC、AUC、F1等值)一套完整的流程,助力大家使用深度学习处理BCI数据。最后也会不定时发一些数据集,涉及到运动想象MI、情感分类、疲劳、SSVEP、心电、EMG、血氧数据等等。欢迎加入,随时交流,我随时解答~



















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











