











简介
在多元时序预测任务中,Transformer-based模型由于其捕获长期依赖的能力而受到欢迎,研究者提出了非常多的相关模型,比如informer,AutoFormer,FEDFormer,Pyraformer等。
但是Transformer在NLP领域的成功并没有带入到时序领域,可能的原因是顺序无关的self-attention机制天然会导致一定程度时序信息的丢失。此外,时序数据中单个时间点的数据相关句子中单个word来说,提供的信息相对更少,且很容易从临近时间推断到,所以基于point-wise来建模会造成模型能力的浪费。PatchTST通过将时序分割成patch的方式来解决这个问题,但是PatchTST是基于channel independence的假设的,因此没有建模channel之间的关系。CrossFormer在此基础上学习了channel之间的关系。
多channel数据如果只是简单拼接会导致channel之间的噪声交互影响模型的学习,因此如何有效建模多channel之间的关系是一个重要的课题。另外,Transfromer-based模型训练更耗时和耗资源。
目前“MLP-Mixers"在计算机视觉领域取得了不弱于Transformer模型的效果,同时具有模型更轻量级和训练速度更快的优点。本文希望将MLP-Mixer模型引入到时序领域。
直接将MLP-Mixers使用到时序领域效果不佳,本文提出了TSMixer模型,TSMixer是patching-based,并且可以作为一个通用的backbone来用来学习时序的patch表征。
方法
多元时序预测

训练方法
两种:监督学习和自监督学习
监督学习
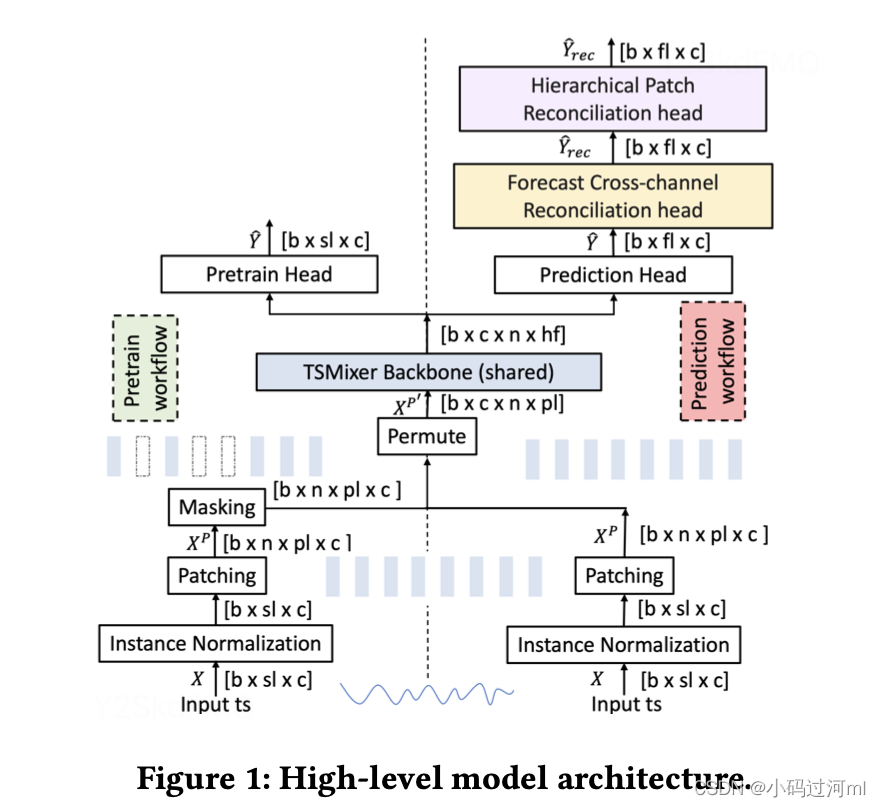
如图1右侧,经过normlization,patching,permutation,然后输入到TSMixer backbone中,然后Predition Head输出预测值\hat(y),然后可以用MSE来训练模型。
论文另外引入了两个在线预测校准head,通过这两个head,模型可以利用cross-channel信息和 patch-aggregation信息来进一步校准。
自监督学习
包含两个阶段,pre-train和fine-tune。pretrain阶段为一个masked time series modeling(MTSM)任务,随机将输入序列中的一个patch mask掉,然后来预测mask掉的值。
模型组件
Instance normalization
方法参考RevIN,减去期望,除以标准差。通过数据标准化缓解数据漂移的问题。
Patching
先patch,然后permute,patch可以是overlapping / non-overlapping。自监督学习中,patch时必须是non-overlapping。
TSMixer backbone

论文使用了三种类型的backbone,结构如图2所示。
V-TSMixer (vanilla backbone)
CI-TSMixer (channel independent backbone)
IC-TSMixer (inter-channel backbone)
MLP Mixer layers
TSMixer 模型由多个mixer layer堆叠而成。每个mixer layer学习从3个角度来学习相关性。
1.patch之间,2.patch内部的不同特征之间,3.不同的channel之间。
只有IC-TSMixer 有第3个组件
Gated attention (GA) block.
时序数据中往往有大量的噪声或不重要的特征,通过在MLP层后添加GA层来扩大重要特征,缩小不重要特征。Attention计算方式:将输入最后一维softmax。
![]()
![]()

Model heads
结构如下图7


Forecast online reconciliation
基于时序数据的两个重要特征:时间序列数据的内在时间层次结构和跨通道依赖性。
我们观察到使用channel独立的backbone+跨channel的校准head,比使用其他channel-mixing方式效果更好。
![]()

![]()
实验
实验设置
数据集


Model Variants


Data & Model Configuration
Input Sequence length 𝑠𝑙 = 512, Patch length 𝑝𝑙 = 16, Stride 𝑠 = 8, Batch size 𝑏 = 8, Forecast sequence length 𝑓 𝑙 ∈ {96, 192, 336, 720}, Number of Mixer layers 𝑛𝑙=8,featurescaler𝑓𝑠=2,Hiddenfeaturesizeh𝑓 =𝑓𝑠∗𝑝𝑙(32), Expansion feature size 𝑒𝑓 = 𝑓𝑠 ∗ h𝑓 (64) and Dropout 𝑑𝑜 = 0.1.
实验结果
监督学习
Accuracy Improvements



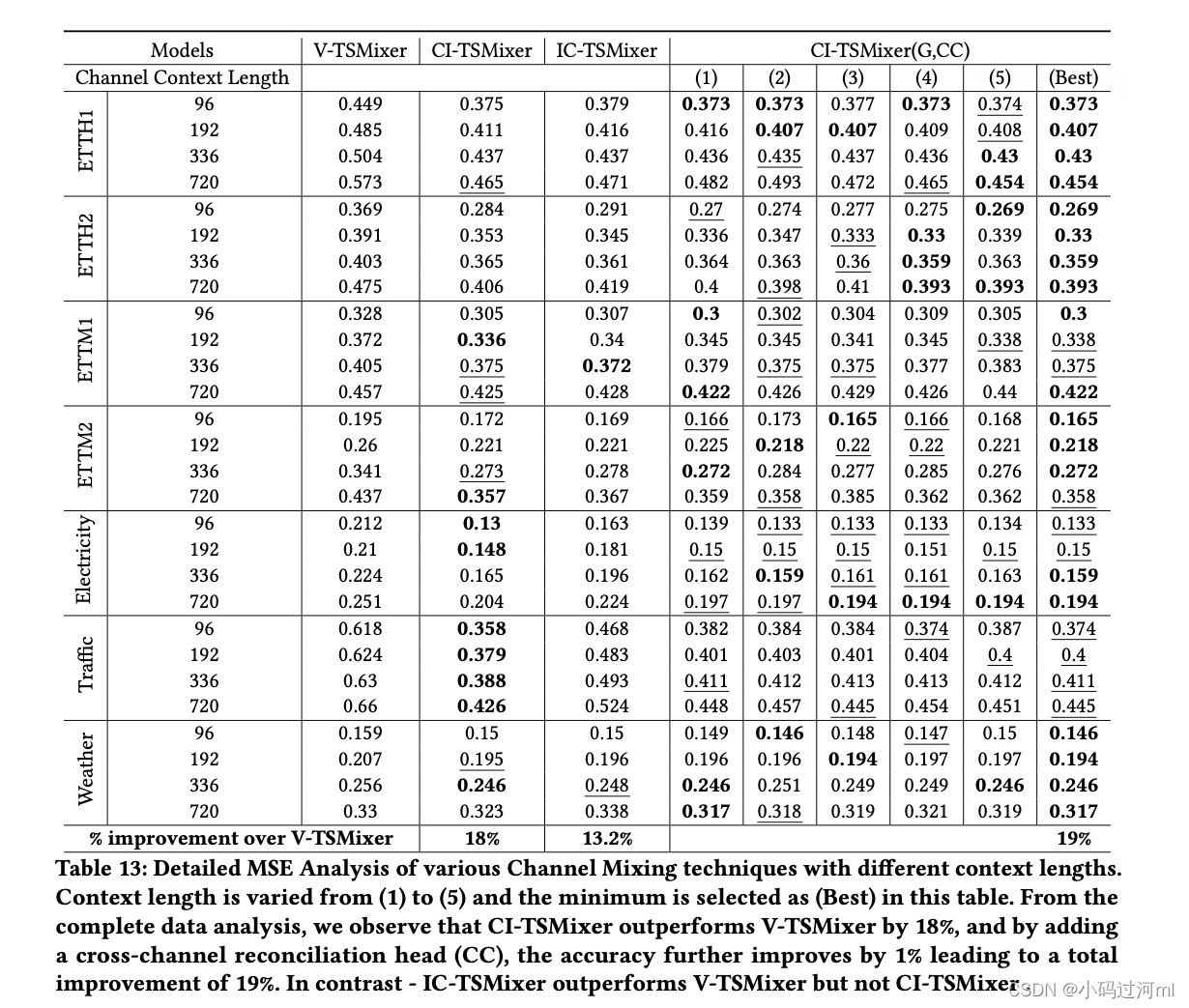
Computational Improvements


自监督学习
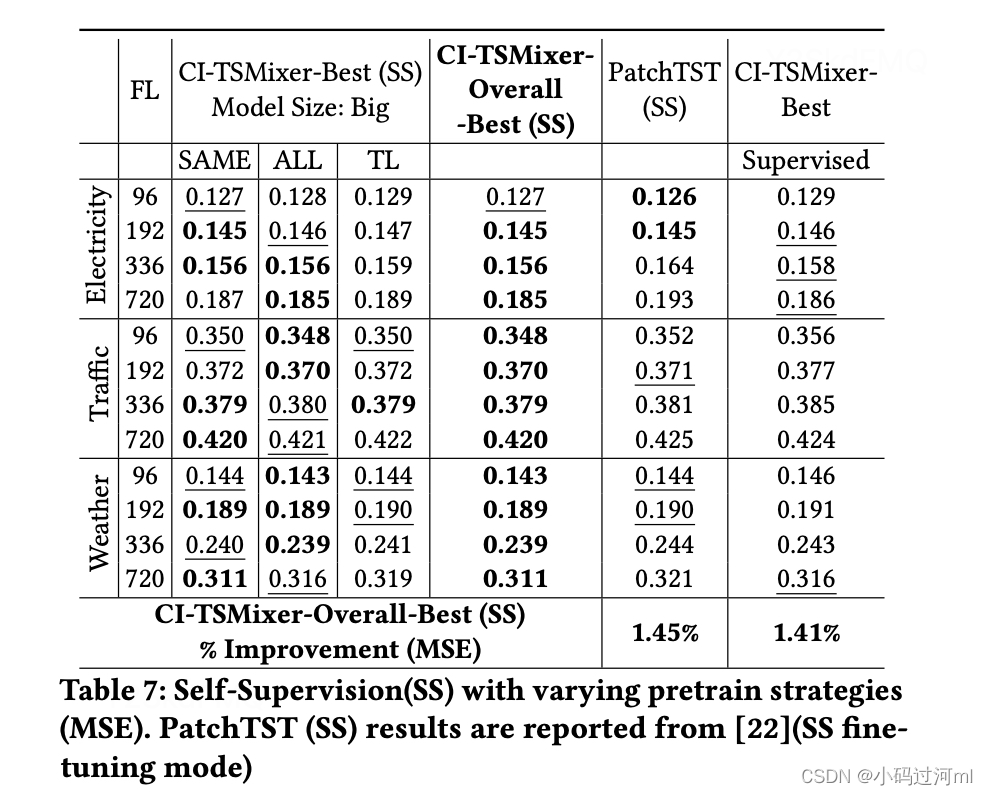
Accuracy Improvements

















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









