










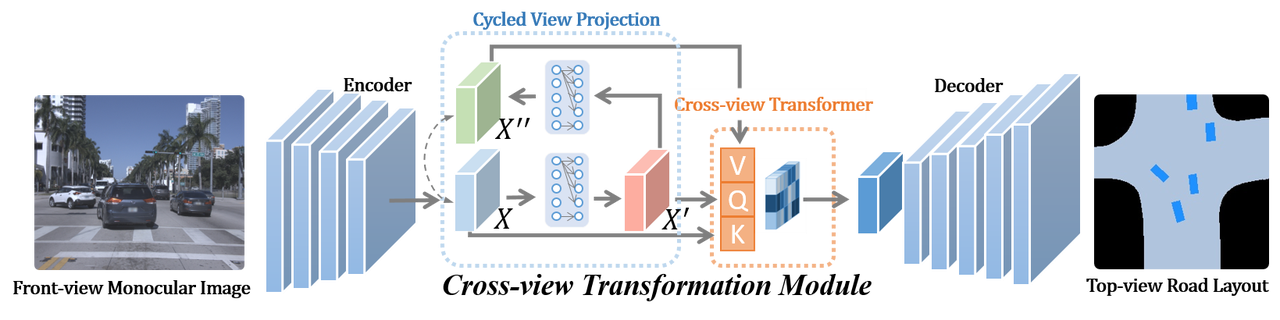
1. PYVA: Projecting Your View Attentively (CVPR 2021)
- 数据集:KITTI
- paper,github,35 FPS
- 输入:单张摄像头前向图
- 输出:road layout estimation and vehicle occupancy estimation
目标检测

道路分割

2. FIERY (ICCV 2021)
github
主页
数据集:NuScenes
输入:6个视角的相机图像+内参+外参
模型推断输出示意图:

3. HDMapNET( ICRA 2022)
暂时没有预训练好的模型,但可以可视化其如何如何处理标注

4. Lift, Splat, Shoot (ECCV 2020,NVIDIA)
模型推断结果的例子:


5. 一个比赛:nuScence 3D Camera-Only Detection
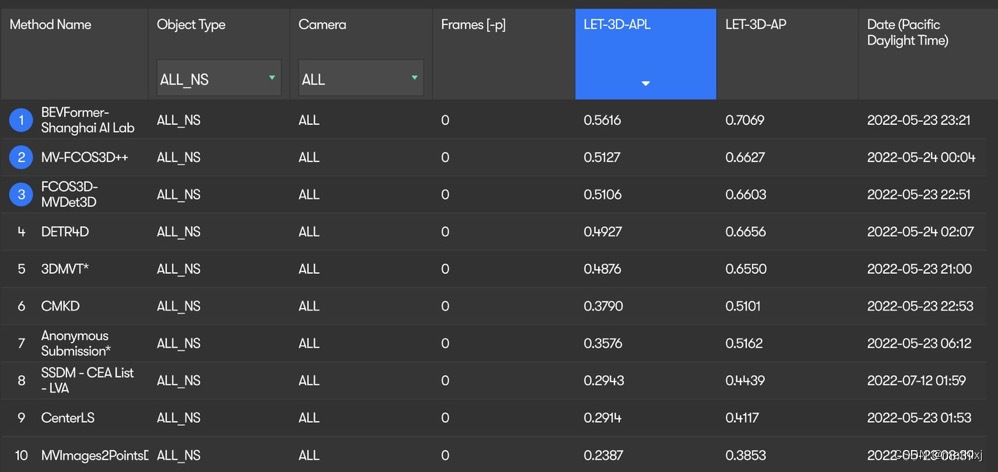
5.1 BEFormer: 基于Transformer的BEV编码器
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
-
paper,github,中文blog,中文论文,测速V100上,R101-DCN,input size 900X1600,大约2FPS
-
输入:多视角相机图像
-
输出:3D目标检测/语义分割
-
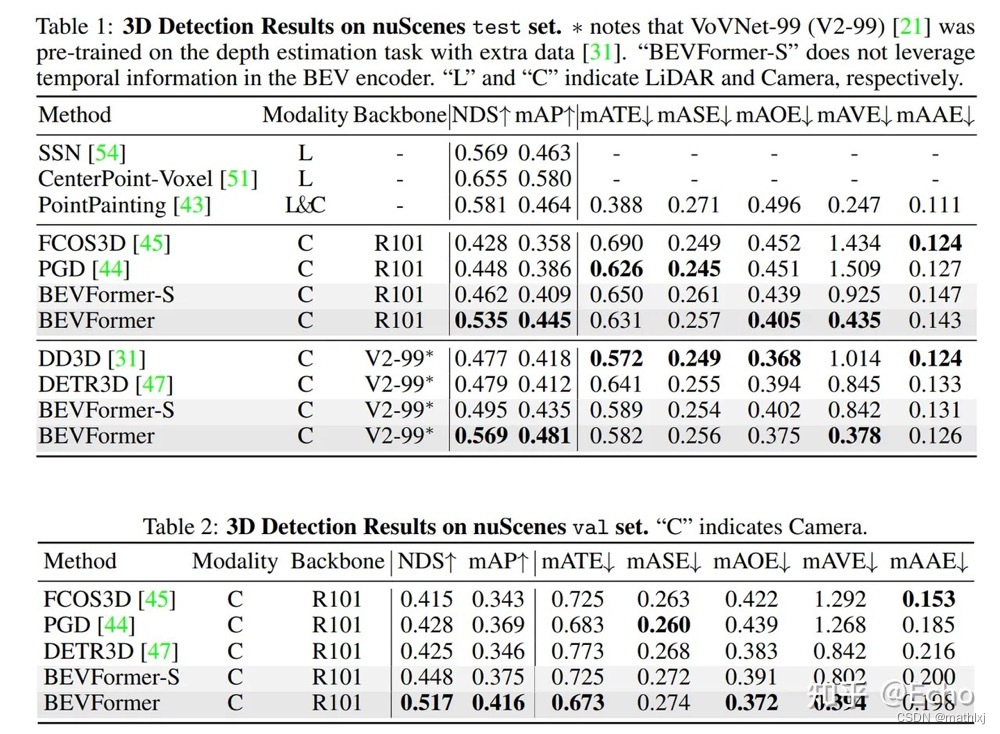
论文汇报的与带LiDAR方法对比:与基于lidar的基线性能相当; 对速度有很好的估计结果.
-
衡量标准:
- mAP:根据地平面上的中心距离计算,而非IoU上的3D IoU
- ATE: 平移
- ASE: 尺度
- AOE:方向
- AVE:速度
- AAE:属性
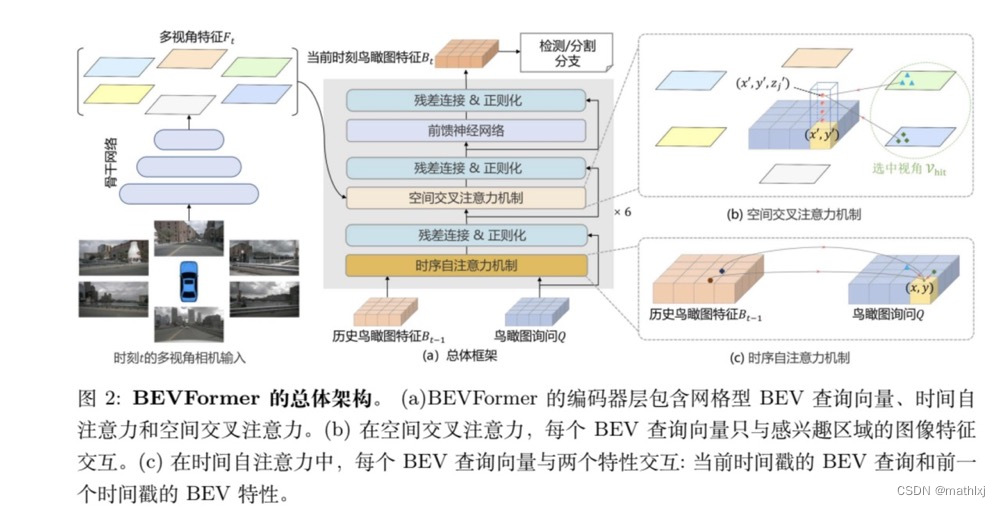
-
一些细节:
- 主干网络:ResNet-101 / VoVnet99
- BEV特征的中心默认对应自我车的位置
- 鸟瞰图询问query Q为一组网格形状的可学习参数,维度为HxWxC,H, W为BEV的高和宽,一一对应到BEV平面中的网格单元区域。大小为200x200,感知范围[-51.2m, 51.2m].
- 空间交叉注意力机制:
- 将BEV空间上的每个query向量提升到一个柱状查询向量
- 采样 N r e f N_{ref} Nref个3D参考点,将其投影到二维视图(需要知道相机投影矩阵),对于一个BEV query,只能命中部分视图。(这里的坐标系为以本车为原点的三维坐标系,根据BEV的坐标和分辨率获取真实的x,y, 通过锚点采样得到z)
- 将这些命中视图中的二维点作为参考点,围绕参考点从命中视图中抽取特征
- 对这些采样的特征进行加权求和,作为空间交叉注意力的输出.
- 时间注意力机制:融合t时刻的BEV query向量和t-1时刻的历史BEV特征
- BEV特征的应用:拿到的是HxWxC的通用的二维特征
- 对于3D检测任务,设计DETR的检测head,预测三维检测框和速度,无需NMS
- 对于地图分割,采用Panopic SegFormer作为地图分割头
5.2 其它名次的算法
- MV-FCOS3D++ 基于MMDetection3D,无具体的github代码
- FCOS3D-MVDet3D 基于MMDetection3D,无具体的github代码
- DETR4D :无任何描述
- DMVT*:无任何描述















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









