









目录
Cross-view Transformation Module
Cross-view Transformation Module
前言
Title:《Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation》
paper: here
GitHub: 未开源
20220813 V1:
算法创新点
-
使用前视相机图像去转换BEV视图;
-
提出 Cycled View Projection (CVP) 将 front-view 图像投影到BEV视图;
-
提出cross-view transformer(CVT) 去分割 vehicle 和road ,去提取vehicle 之间的空间关系;
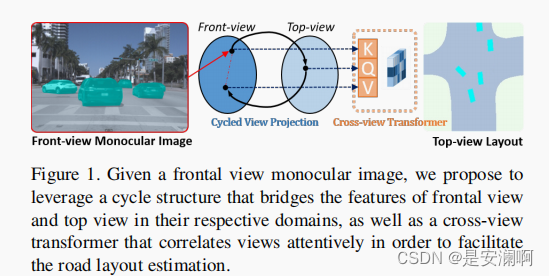
论文提出一个框架,这个框架在仅仅给出前视单目相机图片的情况下,在BEV视图中重建由道路布局和车辆组成形成的局部地图;同时提出cross-view transformation module,充分利用视图之间的相关性加强视图转换和场景的理解;设计了一个上下文感知鉴别器,通过车辆和道路的关系,进一步细化结果。
算法细节
Network Overview
网络的框架(Figure 2)主要是 GAN-based framework,输入是前视图像I,使用backbone为 ResNet 的网络提取图像特征, 之后cross-view transformation module 增强了视图投影的特性,之后通过decode得到了top-view的masks ;另一方面提出了context-aware discriminator(Figure 5),它通过道路的背景来区分车辆的mask;
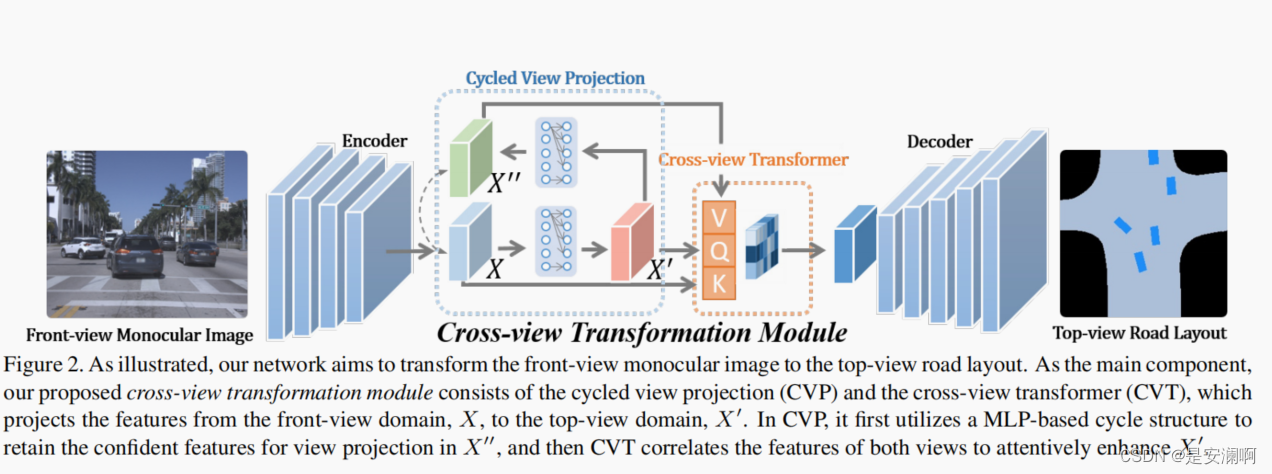
Cross-view Transformation Module
论文提出在两种视图(front-view and top-view)之间的patch-level correlation建模是很困难的一件事情,本论文提出使用Cross-view Transformation Module去增强 visual feature 用于 将特征从front-view 投影到top-view,模块的结构在Figure 2 中,模块包括两部分: cycled view projection and cross-view transformer.
Cycled View Projection (CVP)
使用一个MLP的结构(包含两个FC)将前视图像的feature 投影到top-view,这样的设计可以有比标准卷积操作能得到更多的信息,X是front-view 的feature,X‘ 是top-view的feature,因此,可以这样表示:
![]()
但是,这样转换是误差很大的,因此,使用cycled self-supervision scheme 去调整 view project,使用相同的MLP计算X’‘,可以表达为:
![]()
为了保证X‘’和X’的一致性,引入了cycle loss:

这个循环结构有两个好处:
cycle loss 可以提高feature 的表达性;
X‘’和X'的loss不能进一步减小时,说明X‘’保留了了最好的投影特征信息;
总结一下:X 是投影之前的feature,X‘是投影之后的feature,X’‘是保留和投影最相关信息的feature;Figure3 中可视化了不同阶段的feature。(可视化方式是选择typical channel,之后和输入图像对齐)

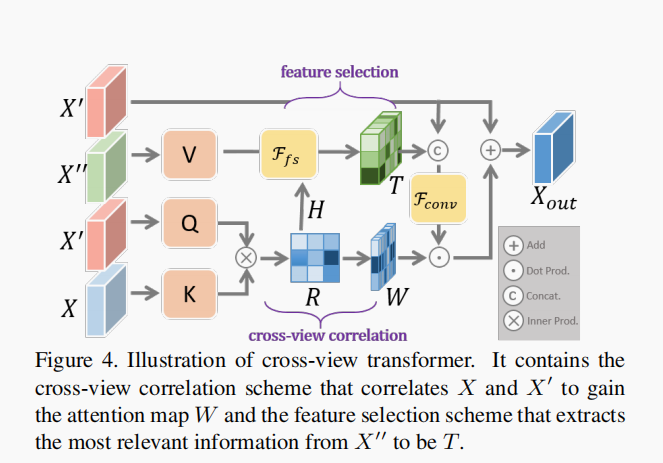
Cross-View Transformer (CVT)
CVT是用来做X 和X’的对应的,CVT可以简单的分为两部分:
cross-view correlation scheme:明确关联视图的feature,去生成注意力图W,实现X‘的增强;
feature selection scheme:从X’‘中提取最相关的信息;
其中:K=X,Q=X’,V=X‘’;三者的维度是一样的,X和X‘将会被flatten 成patch,每一个patch表示为:, h,w 是X的高和宽,相关性矩阵是R,
代表的是X’和X每一行的元素的相关性,被定义归一化的内积为:
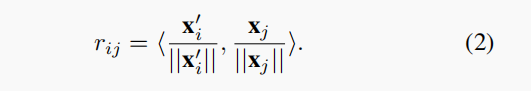
同时,定义了W,H,定义为:
![]()
![]()
是
的最大值,
是
最大值的索引值;
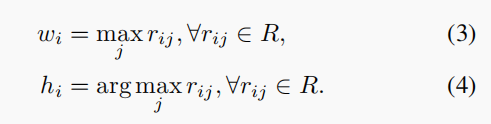
feature selection scheme
对X''和H进行处理,产生新的feature T,从X''中检索到最相关的特性:
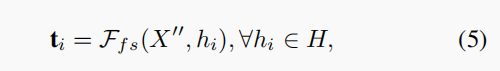
之后将feature map T reshape 成X‘ 的维度,之后进行concat,之后联合矩阵W进行dot prod,最后和X’ Add,得到:
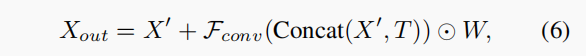
注:是
的卷积。
CVT的流程图Figure 4:
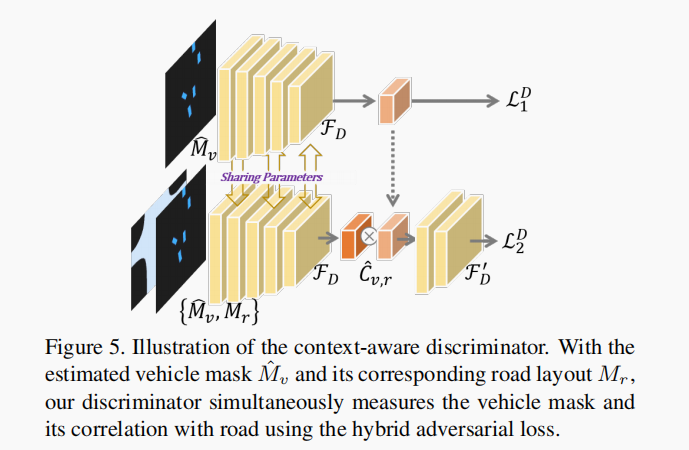
Context-aware Discriminator
以GAN网络作为base,通过vehicle 和 road 的上下文关系来进一步细化vehicle 的mask,构建的网络不仅可以区分vehicle mask和road mask,还能利用他们之间的相关性来加强区分。
是vehicle mask,
是 GT road 的mask,使用共享的CNN 提取
feature 和
和
进行concat之后的feature ,之后通过dot-product计算他们feature 之间的相关性,定义为:
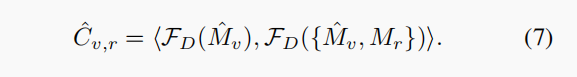
和
被送到网络
中进行前景目标识别;
和
被送到网络
中进行区分,对于这两个分类器,都使用了MLP和BN,使用hinge loss 去稳定训练,Loss 定义为:
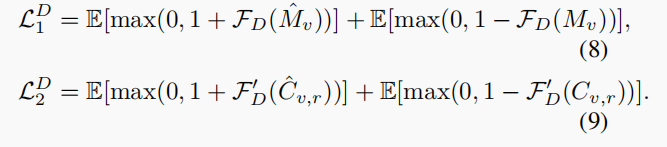
Context-aware Discriminator 不仅可以区分vehicle 和 GT,还能找到vehicle 的空间相关性。如Figuer 5:
Loss Function
总的Loss定义为:
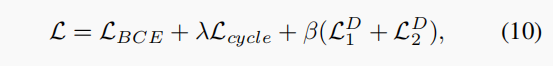
衡量: the synthetic semantic mask and the ground truth mask 的差距;
,
作为 balance weight 去平衡 cycle 和 adversarial 的损失;设置
=0.001 和
=1 。
















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









