







本笔记源于CDA-DSC课程,由常国珍老师主讲。该训练营第一期为风控主题,培训内容十分紧凑,非常好,推荐:CDA数据科学家训练营
——————————————————————————————————————————
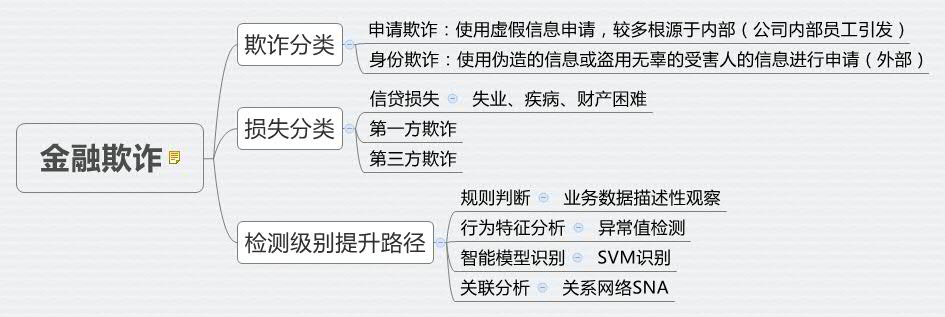
一、欺诈、损失定义与分类
1、欺诈分类
欺诈与客户虚假信息识别的案例较少,因为这些案例的数据源十分敏感,一般不会流入市场供大众参考。
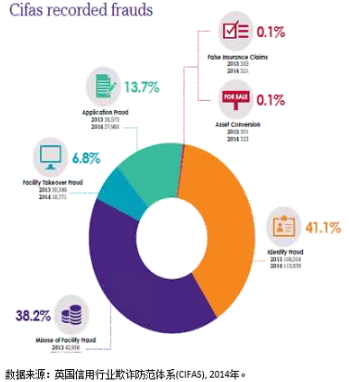
从英国信用行业欺诈防范体系中看出,绝大多数欺诈可以分为申请欺诈、身份欺诈。
申请欺诈:使用虚假信息申请,较多根源于内部(公司内部员工引发)
身份欺诈:使用伪造的信息或盗用无辜的受害人的信息进行申请(外部)
申请欺诈,一般不是模型问题,而是数据本身存在问题,譬如小城市大学生比例超级高,模型是做不出来的,只能从描述性看出来。中国的欺诈、评级原理不公开,因为一公开,造假的可能性越大,负担不起。
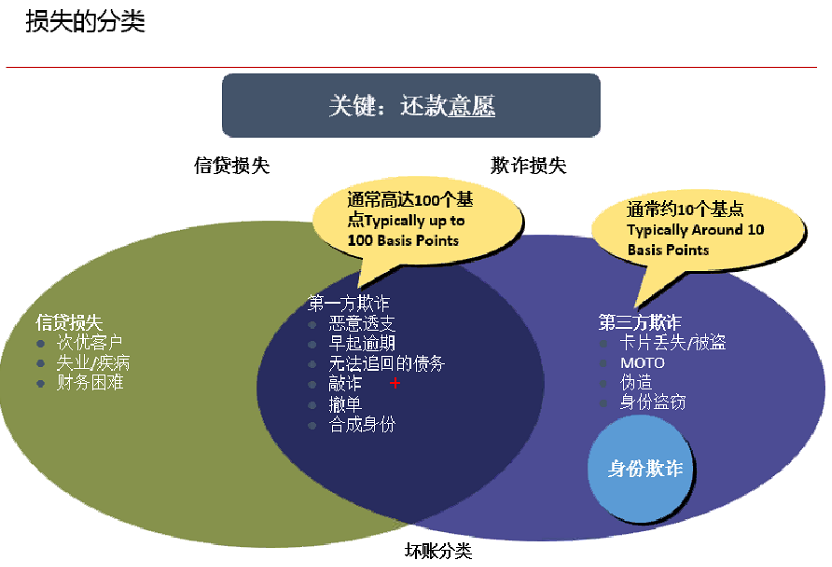
2、损失分类
——————————————————————————————————————————
二、欺诈防控体系
欺诈一般不用什么深入的模型进行拟合,比较看重分析员对业务的了解,从异常值就可以观测出欺诈行为轨迹。同时欺诈较多看重分类模型的召回与准确率两个指标。较多使用SVM来进行建模。
召回率,准确率,排序很准的模型排行:
1、SVM
2、随机森林、决策树
1、银行卡欺诈防控体系
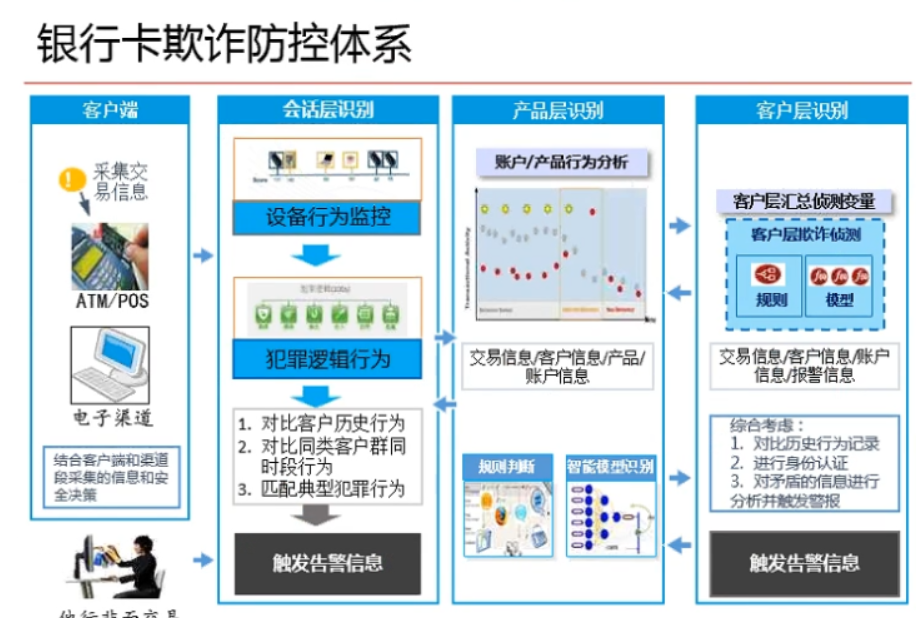
2、检测级别提升路径
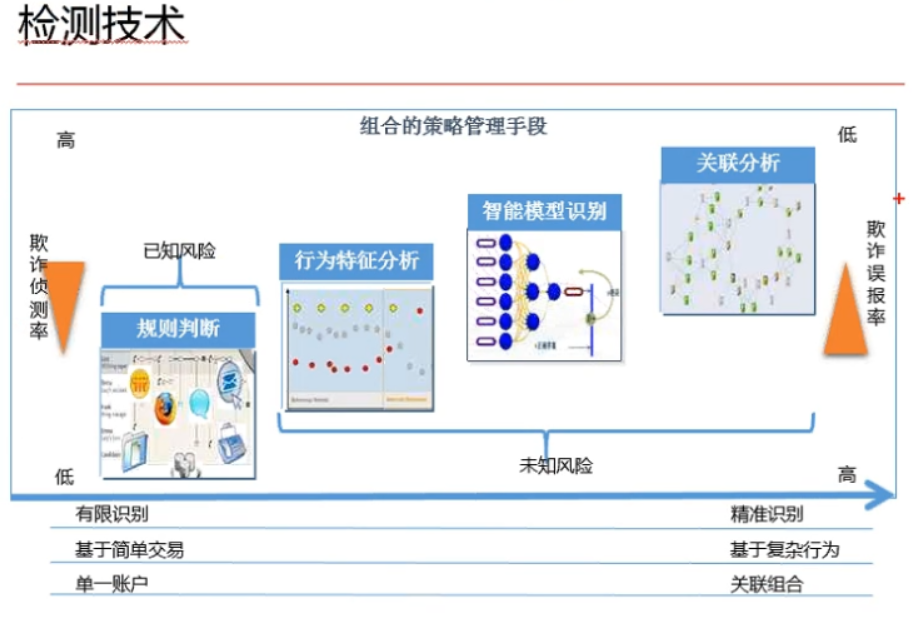
其中,规则判断,行为特征分析属于较为简单的分析方法,大多不需要通过建模,通过观测业务数据以及异常行为特征分析即可;
智能模型识别,会用SVM模型来进行识别;
关联分析(有组织的欺诈):社会网络的方法来探究(R语言︱SNA-社会关系网络 R语言实现专题(基础篇)(一))。
-----------------------------------
Logistics建模简述(logit值、sigmoid函数)
——————————————————————————————————
一、logit值的来源
逻辑回归一般将因变量二分类变量的0-1转变为频率[0,1],变成odds(优势比,[0,+∞]),然后log一下成为Logit值([-∞,+∞])

优势比就是:odds=P(y=1)/P(y=0)
logit值:logit=log(odds)
什么是sigmoid函数?
先定义了一个直觉的概念优势比 p/(1-p),p是true时的概率,1-p是false时的概率,对优势比取log,即t=log(p/(1-p))进行值域转换,转到所有实数域。然后反过来求p,最终即可得到sigmoid函数。

sigmoid函数的有趣特点是,自变量是负无穷到正无穷,应变量是0到1。越接近0变化越大。导函数是p(1-p),导函数很有趣。(参考:大话逻辑回归)
——————————————————————————————————
二、logit建模

利用logit=Y进行建模,得到Logit之后就可以根据其进行计算概率。Logit=经济学上的效用,效用是一个连续变量,logit模型相当于是效用建模。
所以一般来说,逻辑回归出来的系数都是logit值的系数,需要转化为概率值。简单的理解可以认为是:
输入是x,输出是y,中间有个临时变量是t。w和b是模型参数。h(t)是属于某个类别的概率,大于0.5认为属于这个类别,即y=1。 

简便起见,我们可以认为b始终和一个值为1的w相乘。于是我们把b放入w。模型简化为

这就是逻辑回归的公式,非常简单。
(参考: 大话逻辑回归 )——————————————————————————————————
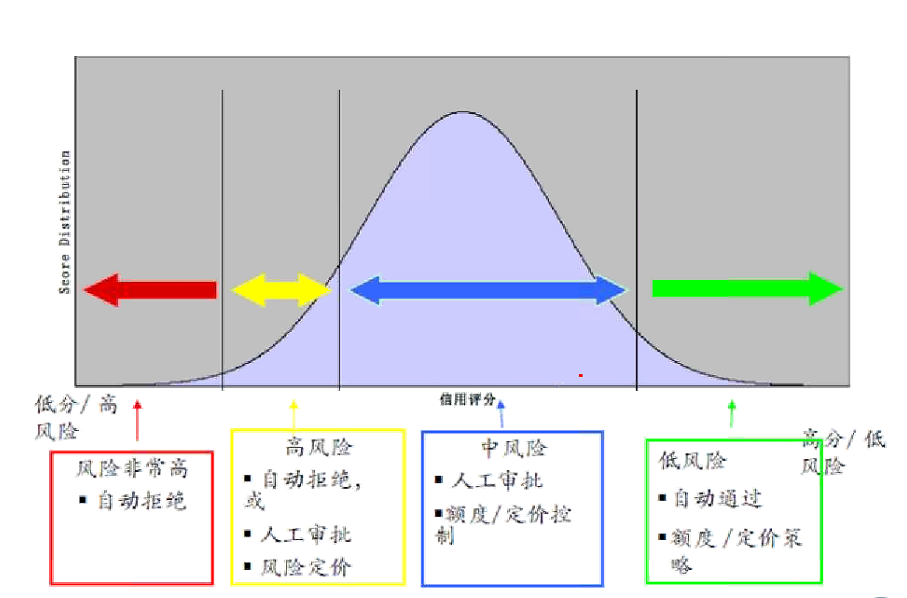
三、logit函数建模阀值设定
在风控模型汇总,logistics阀值的设置根据业务主来判断。一般高信用自动通过,中风险需要审查;风险较大的拒绝借贷。
——————————————————————————————————
四、R语言实现
1、逻辑回归
逻辑回归一般用glm函数中的binomial(link='logit')来建模。
- lg<-glm(y ~x1,family=binomial(link='logit'))
- summary(lg)
此时的回归系数的用途只有两个:正负号、显著性.回归系数代表每增加1个单位x,会增加logit值增加0.1个单位,并且正向影响。如果需要知道概率值需要重新计算。
2、逐步回归筛选变量——step
在逻辑回归之上,我们可以用逐步回归方法,对变量进行剔除。
- lg_ms<-step(lg,direction = "both")
- summary(lg_ms)
3、验证集预测——predict
- train$lg_p<-predict(lg_ms, train)
- summary(train$lg_p)
predict的预测结果也同样是logit值,并不是概率,需要进行再计算
4、计算概率值
- 1/(1+exp(-1*train$lg_p))
5、模型验证的方法
作为排序类模型,可以用ROC曲线/AUC值、累积提升曲线、K-S曲线、洛伦兹曲线gini来验证(笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift))。
------------------------------------------------------------------------
信用风险建模中神经网络激活函数与感知器简述
——————————————————————————————————————————
一、信用风险建模中神经网络的应用
申请评分可以将神经网络+逻辑回归联合使用。
《公平信用报告法》制约,强调评分卡的可解释性。所以初始评分(申请评分)一般用回归,回归是解释力度最大的。
神经网络可用于银行行为评级以及不受该法制约监管的业务(P2P)。其次,神经也可以作为申请信用评分的金模型。
金模型的使用:一般会先做一个神经网络,让预测精度(AUC)达到最大时,再用逻辑回归。
建模大致流程:
一批训练集+测试集+一批字段——神经网络建模看AUC——如果额定的AUC在85%,没超过则返回重新筛选训练、测试集以及字段;
超过则,可以后续做逻辑回归。
——笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)——————————————————————————————————————————
二、激活函数
神经网络模型中,激活函数是神经网络非线性的根源。
1、sigmoid函数=Logit

其实就是逻辑回归的转化,神经网络=逻辑回归+变量的自动转化
如果激活函数是sigmoid的话,神经网络就是翻版的逻辑回归,只不过会自动转化(适合排序)
2、高斯型函数
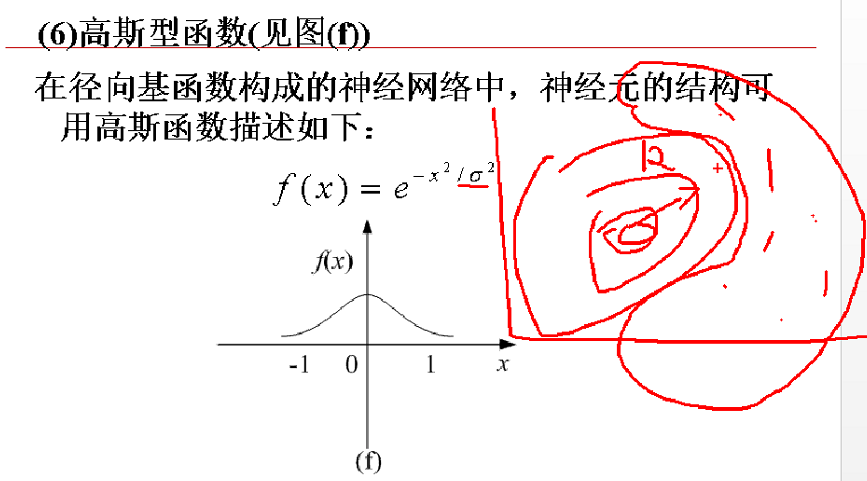
适合分类+聚类,识别类(欺诈行业很好,因为行为跟别人不一样,属于异常),在二维空间中就是等高线。
——————————————————————————————————————————
三、感知器
1、单感知器——无隐藏层

Delta规则,w就是权重。很重要
单层感知器,相当于只要了神经网络的输入层以及输出层,比较简单,所以感知器其实相当于线性回归,也叫做线性神经网络,没有隐藏层
2、多层感知器——加入隐藏层
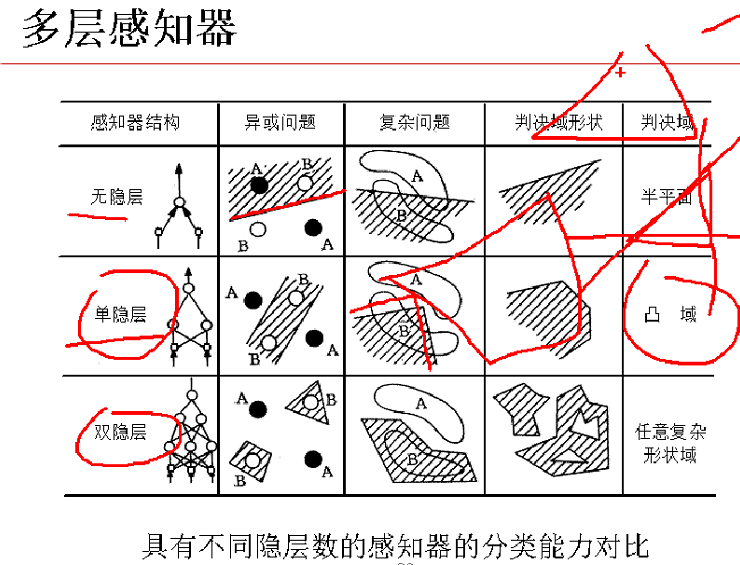
两个隐藏层可以做任何复杂形状域。隐藏层因为属于黑箱,隐藏层越多,会产生过拟合现象(泛化能力不强),并且模型稳健性较差,但是要是模型调试的好,也是一匹“黑马”。
回归出现的所有错误(多重共线性(需进行变量筛选)、缺失值),神经网络都会出现,因为当激活函数为sigmoid时,等同于逻辑回归。
3、BP神经网络——多层感知器
BP神经网络对数据有严格要求,需要做极差标准化。

△,小,就会摆动;大,乱跑;设置多少没有定论
——————————————————————————————————————————
四、BP神经网络-R语言实现——nnet包+AMORE包
BP神经网络需要对数据进行标准化,所以建模之间切记要进行标准化。
- library(nnet)
- help(package="nnet")
- model_nnet<-nnet(y~., linout = F,size = 24, decay = 0.01, maxit = 100,trace = F,data = train)
- #对分类数据预测需要加上y参数
- #decay就是eta权重的调节,默认为0
- #linout=F默认,线性回归;T代表逻辑回归(激活函数只有一个sigmoid)
- #size就是隐藏层的个数,若size=0就是单感知器模型
linout=F代表线性回归,T代表逻辑回归(激活函数为sigmod);
maxit代表最大循环迭代的次数,该值并不是越大越好,越大过拟合现象更严重,要调节在适当的数量。
size代表隐藏层大小,也跟迭代次数一样,层次越多过拟合现象加重,就会把训练集的很多噪声都拿来做建模,虽然训练集的精度高了,但是测试集的精度反而弱了,就是因为训练集噪声不适合于测试集的噪声。
BP神经网络调节模型精度AUC值的话:一般会选择调整maxit(最大迭代次数)+size(隐藏层大小)来调整最优精度。这里可以自编译一些函数来实现,CDA-DSC课程中就有一个自编译函数来进行选择。但是会耗费大量的运行速度。
AMORE包有待继续深入研究。
————————————————————————————
应用一:报错Error in nnet.default(x, y, w, entropy = TRUE, ...)
- Error in nnet.default(x, y, w, entropy = TRUE, ...) :
- too many (1209) weights
这个是因为隐藏层多了之后,运算不了,台式机不能运行那么多,所以要通过调整size的隐藏层个数来看效果如何。
————————————————————————————
支持向量机SVM在金融风险欺诈中应用简述
欺诈一般不用什么深入的模型进行拟合,比较看重分析员对业务的了解,从异常值就可以观测出欺诈行为轨迹。同时欺诈较多看重分类模型的召回与准确率两个指标。较多使用SVM来进行建模。
召回率,准确率,排序很准的模型排行:
1、SVM
2、随机森林、决策树
其中SVM可以像逻辑回归做概率,但是这个概率是点到超平面之间的距离与最长距离之比。概率原理不是特别直接有效,而且解释力度不强。
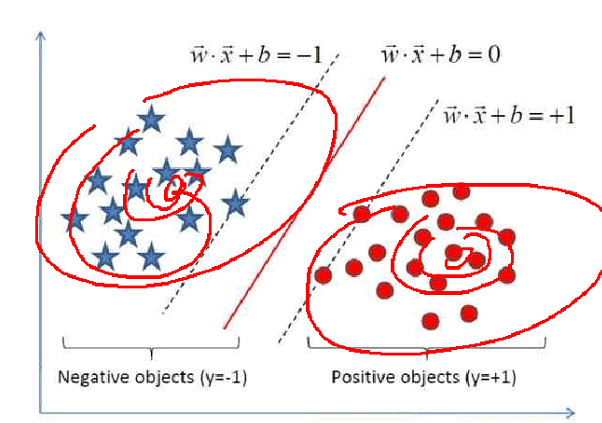
一、SVM线性可分与不可分
1、线性可分与不可分

线性可分指的就是直线(如左图),用了一条直线来进行划分,实心圆与空心圆,用直线来分类;不可分就是曲线分类,准确性比较高。大部分情况都是线性不可分
不可分的情况有两种处理方式:
(1)容错的话,直接用线性,设置容错个数,错了就错了
(2)不容错,做惩罚函数,做多项式转化,变为线性的问题
如果惩罚过多,会造成过拟合的问题,泛化能力不足
二、核函数
SVM的核函数与神经网络的激活函数一致,不同的场景会用到不同的核函数。
其中RBF函数(高斯核函数),较多应用在异常值处理。
————————————————————————————
风控模型中变量粗筛(随机森林party包)+细筛(woe包)
本内容来源于CDA-DSC课程内容,原内容为《第16讲 汽车金融信用违约预测模型案例》。
建立违约预测模型的过程中,变量的筛选尤为重要。需要经历多次的筛选,在课程案例中通过了随机森林进行变量的粗筛,通过WOE转化+决策树模型进行变量细筛。
一、变量粗筛——随机森林模型
与randomForest包不同之处在于,party可以处理缺失值,而这个包可以。
- library(party)
- #与randomForest包不同之处在于,party可以处理缺失值,而这个包可以
- set.seed(42)
- crf<-cforest(y~.,control = cforest_unbiased(mtry = 2, ntree = 50), data=step2_1)
- varimpt<-data.frame(varimp(crf))
mtry代表在每一棵树的每个节点处随机抽取mtry 个特征,通过计算每个特征蕴含的信息量,特征中选择一个最具有分类能力的特征进行节点分裂。
varimp代表重要性函数。( R语言︱决策树族——随机森林算法)
二、R语言实现WOE转化+变量细筛
R语言中有一个woe包,可以实现WOE转化的同时,通过WOE值进行y~x的决策树建立,应用决策树的重要性来进行变量细筛。
woe包需要从github中下载得到:
- #library(devtools)
- #install_github("riv","tomasgreif")
- library(woe)
- IV<-iv.mult(step2_2,"y",TRUE) #原理是以Y作为被解释变量,其他作为解释变量,建立决策树模型
- iv.plot.summary(IV)
summary(step2_3)
————————————————————————————

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









